

文章目录
- 摘要
- 第一章 背景与意义
- 1.1 背景
- 1.1.1 家庭暴力发展现状
- 1.1.2 家庭暴力的危害
- 1.2 意义与目的
- 第二章 关键技术与方法
- 2.1 文本模态特征提取法
- 2.2 视频模态特征提取法
- 2.3 音频模态特征提取法
- 2.4 注意力机制(Attention)
- 2.5 多头注意力机制(Multi-Attention)
- 2.6 Transformer
- 第三章 系统的设计与实现
- 3.1 文本特征提取
- 3.2 音频特征提取
- 3.3 视频特征提取
- 3.4 深度学习算法实现
- 3.4.1 特征编码
- 3.4.2 特征融合
- 3.4.3 结果预测
- 3.5 深度学习算法训练
- 3.6 深度学习算法性能测试
- 3.7 系统测试
- 第四章 总结
以下链接包含本文相关资源:
完整报告链接:https://download.csdn.net/download/m0_48932261/89432061
数据集下载链接:https://download.csdn.net/download/m0_48932261/89421590?spm=1001.2014.3001.5501
摘要
家庭暴力在现今社会屡见不鲜,成为威胁社会和谐与稳定的重要问题之一。家庭暴力不仅包括身体上的虐待,还涉及情感、心理和经济上的虐待,给受害者尤其是女性和儿童带来深远的负面影响。有效预防和处理家庭暴力事件,及时感知和理解伴侣的情感显得尤为重要。为了帮助社会稳定,提高居民生活幸福指数,本系统选取了CMU-MOSI、IEMOCAP数据集,利用Transformer、Adam优化器等多种深度学习算法,构建起情感检测系统。用户可以将信息输入到情感检测系统中,系统能够帮助识别检测对象的情感状态,提供预警,保护受害者的权益,并避免矛盾的进一步激化。本系统选取了MOSi、IEMOCAP数据集,并利用transformer技术构建了一个情绪检测系统。MOSi、IEMOCAP数据集是一个多模态情感分析数据集,包含视频、音频和文本三种模式的数据,非常适合用于情感分析和情绪检测研究。其多样性和丰富性,使其成为情感检测系统开发的理想选择。通过构建和应用情感检测系统,可以在家庭暴力问题发生前提供预警,减少暴力事件的发生频率和严重程度。该系统不仅有助于保护受害者的权益,改善家庭关系,还有助于构建一个更加和谐和安全的社会环境。利用MOSi、IEMOCAP数据集和transformer技术构建情感检测系统,是应对家庭暴力问题的一项重要创新和实践,能够在保护家庭暴力受害者、预防暴力事件方面发挥重要作用,推动社会和谐和进步。
第一章 背景与意义
1.1 背景
家庭暴力是一个普遍存在的社会问题,它不仅侵蚀着个体的尊严和权利,也对社会的道德和法律秩序构成挑战。深入了解家庭暴力的发展现状、认识其严重危害,并明确预防和干预项目的意义与目的,对于构建和谐社会至关重要。
1.1.1 家庭暴力发展现状
家庭暴力作为一种严重的社会问题,其发生率在全球范围内一直居高不下。尽管各国政府、国际组织和民间社会已经采取了包括立法、教育、公共宣传和支持服务在内的多种措施来应对和减少家庭暴力事件,但这一问题仍然普遍存在。家庭暴力的隐蔽性和复杂性,加之受文化、宗教和社会观念的影响,使得许多案例难以被及时发现和处理,从而成为一个难以根除的社会顽疾。在中国,家庭暴力问题同样严峻。根据全国妇联的数据显示,约有四分之一的女性在其一生中遭受过不同程度的家庭暴力。这一数字揭示了家庭暴力的普遍性和严重性。妇女和儿童作为家庭暴力的主要受害者,常常因为缺乏求助渠道、担心报复、经济依赖或对家庭完整性的考虑而选择沉默或忍受。
1.1.2 家庭暴力的危害
家庭暴力的危害性是广泛而深远的,它的影响不仅限于受害者个体,还会波及整个家庭系统,乃至更广泛的社会层面。受害者遭受的身体伤害往往是显而易见的,但家庭暴力所带来的心理创伤却可能是隐蔽而持久的。受害者可能会经历深刻的心理痛苦,包括羞耻、内疚、无助感和持续的恐惧,这些感受可能会长期影响他们的心理健康和社会功能。长期的心理创伤可能导致受害者出现焦虑、抑郁、自我价值感低下。对于儿童而言,家庭暴力的环境会对他们的心理健康和成长发展产生极为不利的影响。目睹或经历暴力的儿童可能会出现学习障碍、行为问题、情感障碍和人际关系困难,这些影响可能会伴随他们进入成年期。家庭暴力还可能导致一系列社会功能障碍,如影响受害者的工作表现和社交活动,限制他们的社会参与度,进而影响他们的经济状况和社会地位。
1.2 意义与目的
本项目通过构建和应用情感检测系统,旨在成为预防家庭暴力的第一道防线。该系统利用MOSi、IEMOCAP数据集和前沿的Transformer技术,能够深入分析家庭成员的情感状态,及时捕捉到潜在的冲突信号。通过提前预警,我们不仅可以减少家庭暴力的发生频率,还能降低其严重程度,从而避免对受害者造成不可逆转的伤害。本项目的意义不仅在于技术层面的创新,更在于它对促进社会正义、保护人权、维护社会秩序的深远影响。通过这一系统,我们期望能够为每一个家庭带来和平与安宁,为社会带来和谐与进步。
第二章 关键技术与方法
2.1 文本模态特征提取法
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种预训练语言模型,它在自然语言处理(NLP)任务中取得了显著的成果。BERT的核心优势在于其双向训练机制,这使得模型在处理每个词汇时都能考虑到整个句子的上下文信息,从而更精准地理解语言的细微差别。
2.2 视频模态特征提取法
OpenFace 2.0 由卡内基梅隆大学开发的先进开源工具包,专门用于面部行为分析。OpenFace 2.0集成了一系列尖端功能,包括高精度面部标记点检测、实时头部姿态估计、面部动作单元识别,以及眼动估计。这些功能使得工具包在情感分析、用户身份验证和社交媒体行为分析等多个领域具有广泛的应用潜力。
2.3 音频模态特征提取法
Librosa是一个专为音乐和音频分析设计的Python库,它为音乐信息检索(MIR)领域提供了一套全面而强大的工具集。该库特别适合于音乐探索性数据分析,并且已经变得在音乐学、音频信号处理和机器学习等学科领域中不可或缺。Librosa的核心能力在于其对音频信号的处理和音乐特征的提取。
2.4 注意力机制(Attention)
注意力机制是深度学习中模拟人类选择性关注的一种技术,它允许模型在处理序列数据时,动态地聚焦于输入中最为相关的部分。这种机制首次在神经机器翻译中得到应用,并迅速成为自然语言处理及其他领域的核心技术。注意力机制的核心优势在于其选择性聚焦能力,它通过计算输入序列中每个元素与当前任务的相关性,生成一组权重,指导模型集中处理最重要的信息。
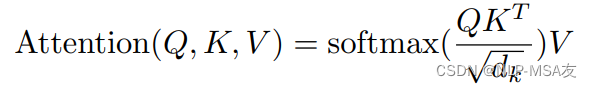
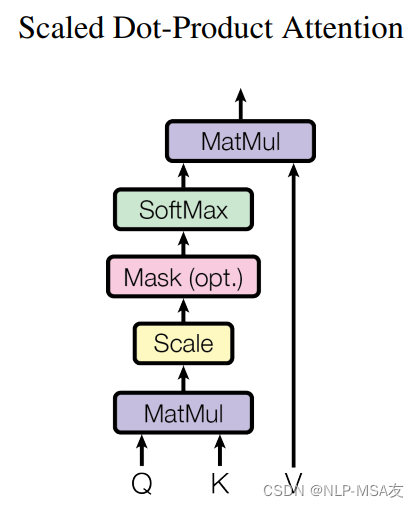
其中,Q、K、V代表模态输入,dk代表问题规模。具体的点积操作如下图结构图所示:
2.5 多头注意力机制(Multi-Attention)
多头注意力机制是深度学习领域中一种创新且强大的技术,尤其在变换器(Transformer)模型架构中发挥着核心作用。这种机制的先进之处在于其能够并行地处理信息的多个子空间表示,从而在不同层面上捕捉输入数据的丰富特征。在自然语言处理(NLP)任务中,如机器翻译、文本摘要、情感分析等,多头注意力机制使模型能够同时集中于文本序列中的多个位置,关注不同词语的多个上下文维度。公式如下所示:

其中Concat代表拼接操作,W是可学习的权重,i表示第i个头(多层注意力机制中的第i层)。网络结构图如下图所示。
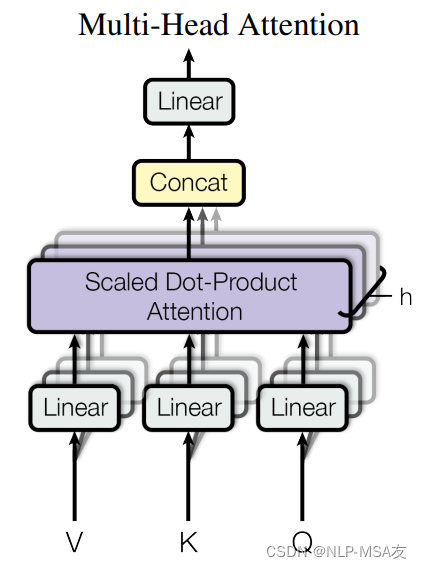
此外,多头注意力机制的一个关键优势是其能够处理长距离依赖问题。在自然语言中,词语之间可能存在跨越长距离的依赖关系,传统的循环神经网络(RNN)在处理这种依赖时可能会遇到困难,而多头注意力机制通过自注意力(Self-Attention)层能够直接捕捉这些远距离的联系。在实践中,多头注意力机制的灵活性和强大能力使其成为构建高性能NLP模型的基础。它不仅提高了模型对复杂语言现象的理解,还为开发更精准的语言处理应用提供了可能。随着研究的不断深入,多头注意力机制在Transformer模型中的应用也在不断扩展,推动了自然语言理解技术的进步。
2.6 Transformer
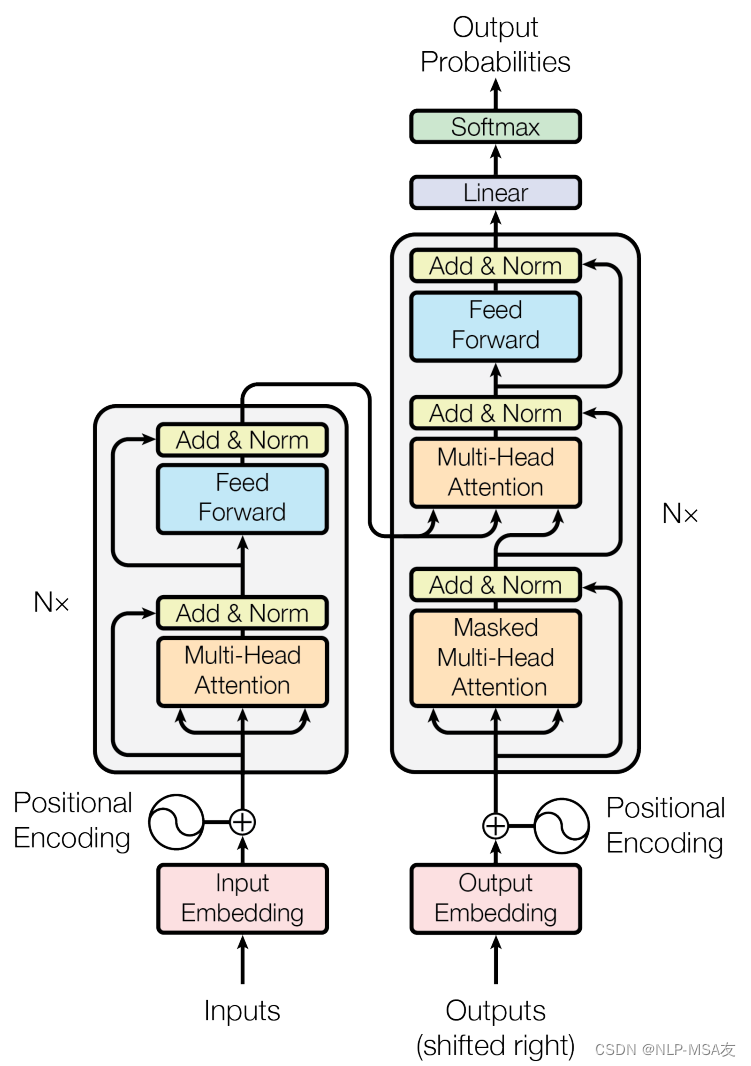
Transformer是一种革命性的神经网络架构,它在自然语言处理(NLP)领域引发了一场变革。这种模型完全基于注意力机制,摒弃了传统的循环神经网络(RNN)结构,使得模型能够并行处理序列数据,极大地提高了训练效率。Transformer的核心是自注意力(Self-Attention)机制,它允许模型在每个位置独立地计算注意力,从而捕捉序列内部的长距离依赖关系。此外,Transformer还引入了多头注意力,通过多个注意力头并行工作,学习输入数据的不同表示子空间,增强了模型对信息的整合能力。在编码器-解码器架构中,Transformer能够有效地处理序列到序列的任务,如机器翻译、文本摘要和问答系统等。它的灵活性、强大的表示能力和卓越的性能使其成为当前NLP领域的主流模型之一。随着研究的不断深入,Transformer已经被扩展到各种变体和应用,如BERT、GPT和T5等,进一步推动了自然语言理解技术的发展。Transformer的网络结构如下图所示:
第三章 系统的设计与实现
在本次系统开发过程中,首先的关键步骤是获取源数据集。本文对数据集进行深入分析,并执行特征提取,以确保数据的完整性和一致性。数据处理阶段完成后,本文转向PyCharm集成开发环境,开始设计机器学习算法模型。通过利用处理后的数据集对模型进行系统训练,本文进一步通过一系列测试来评估不同模型的性能。经过细致的比较和验证,本文最终选定了表现最佳的模型,并将其应用于实际使用场景,以确保系统能够提供高效、准确的解决方案。
3.1 文本特征提取
采用预训练的bert模型对输入的文本进行特征提取,将特征变成向量表示。首先导入一些必要的三方库,BertTokenizer 和 BertModel 是使用 Hugging Face 的 transformers 库中的类,它们分别用于BERT模型的文本分词和模型加载。
首先是文本分词器初始化,得到一个 BertTokenizer 对象,他使用一个基于12层Transformer、没有使用大小写敏感的词汇编码的BERT模型。随后,加载一个预训练的 BertModel。BertModel 是 transformers 库中用于获取BERT模型表示的类。加载模型后,可以使用它来获取句子或文档的嵌入表示,这些嵌入可以用于下游的NLP任务,如文本分类、命名实体识别等。具体代码如下:
import csv import torch from transformers import BertTokenizer, BertModel import pickle import numpy as np tokenizer = BertTokenizer.from_pretrained('../bert-base-uncased') model = BertModel.from_pretrained('../bert-base-uncased')随后, 设计一个文本编码函数TextEmbedding(tokenizer, model, text),它负责将输入文本转换为BERT模型的嵌入表示,这一过程对于后续的自然语言处理任务至关重要。该函数接受三个参数:tokenizer、model 和 text。其中,tokenizer 是用于文本分词和编码的BertTokenizer实例,model 是加载了预训练权重的BertModel实例,而 text 是待处理的原始文本字符串。
函数的工作流程如下:首先,利用 tokenizer 对输入文本进行分词和编码,确保文本格式与BERT模型的输入要求相匹配。在分词过程中,特殊标记(如序列开始和结束标记)被添加到文本中,以提供模型所需的上下文信息。之后,将编码后的文本输入到BERT模型中,获取模型最后一层的隐藏状态。这些隐藏状态包含了文本的丰富语义信息,能够捕捉到词汇、短语乃至整个句子的深层含义。最后,函数将模型输出的最后隐藏状态张量进行压缩,移除单维度,然后转换为NumPy数组格式,以便于进一步的分析和处理。这个嵌入表示可以作为多种NLP任务的输入,如文本相似性比较、情感分析或文档分类等。代码实现如下:
def TextEmbedding(tokenizer, model, text): input_ids = torch.tensor([tokenizer.encode(text, add_special_tokens=True)]) with torch.no_grad(): last_hidden_states = model(input_ids)[0] return last_hidden_states.squeeze().numpy()3.2 音频特征提取
本文使用Librosa进行音频特征的提取,方法流程是遍历指定文件夹内的所有音频文件,从中提取有用的音频特征,并最终将这些特征保存到一个字典中,以便于后续的分析和处理。
首先,导入所需的库:librosa 用于音频分析,numpy 用于数值操作,os 用于文件路径操作,pickle 用于对象序列化。随后,定义了包含音频文件的文件夹路径 filepath,并使用 os.listdir() 函数获取该路径下的所有文件名,存储在列表 files 中。随后,打印出文件的数量以确认音频文件列表的大小。代码如下:
import librosa import numpy as np import os import pickle filepath = "./your/path" files = os.listdir(filepath) audio_dict = {} a= 0之后,在循环中,对于每个文件,本文使用 librosa.load 函数加载音频数据并提取了以下音频特征:过零率(zero_crossing_rate),反映了信号在单位时间内过零的次数,是音频信号的一种基本特征。
梅尔频率倒谱系数(mfcc),广泛用于语音和音频识别中,能够反映音频信号的频谱特性。
色度特征(chroma_cqt),基于恒定Q变换(CQT)的色度特征,能够提供音频信号的音色信息。
这些特征被合并并转置,然后存储在 audio_dict 字典中,其中文件名(不包含扩展名)作为键,特征向量作为值。
通过这种方式,高效地从音频文件中提取关键特征,为音频分析、分类或其他机器学习任务提供了丰富的数据源。
3.3 视频特征提取
为了从视频文件中提取图像和音频特征,本文引入了CatchPIC_Audio_FromVideo_camera(filepath,savepath) 函数。首先,该函数接受两个参数:filepath 指定了视频文件所在的目录,而 savepath 用于指定保存提取特征的文件路径。
接着,使用 os.listdir() 函数列出 filepath 目录中的所有文件。在遍历每个文件的过程中,首先构造了文件的完整路径,然后切换当前工作目录到 OpenFace 工具的安装路径,并构造了一个命令 cmd 用于执行 OpenFace 的 FeatureExtraction 功能。通过 run_cmd() 函数执行该命令,从视频中提取特征。
执行完成后,切换回父目录,并打印当前工作目录以确认路径正确。随后,读取由 OpenFace 生成的 CSV 文件,该文件包含了视频帧的特征。具体代码实现如下:
def CatchPIC_Audio_FromVideo_camera(filepath,savepath): files = os.listdir(filepath) delete_files_in_folder('path\to\OpenFace_2.0.0_win_x64\processed') for file in files: file_name, file_extension = os.path.splitext(os.path.basename(file)) os.chdir('path\to\OpenFace_2.0.0_win_x64') cmd = 'FeatureExtraction.exe -f "' + filepath + '\\' + file run_cmd(cmd) current_dir = os.getcwd() parent_dir = os.path.dirname(current_dir) os.chdir(parent_dir) current_dir = os.getcwd() print(current_dir) print("视频获取成功") df = pd.read_csv('path\to\OpenFace_2.0.0_win_x64\processed\\' + file_name + '.csv', header=None,skiprows=1,nrows=100)通过CatchPIC_Audio_FromVideo_camera(filepath,savepath) 函数,能够自动化地从视频文件中提取图像和音频特征,为进一步的分析和处理提供了便利。这一过程不仅提高了特征提取的效率,也保证了数据处理的一致性和准确性。
3.4 深度学习算法实现
深度学习算法的主要流程为特征编码、特征融合与结果预测。
3.4.1 特征编码
特征编码部分采用了深度学习中的多头注意力机制(Multihead Attention),以及随后的前馈网络(Feed-Forward Network),用于有效地处理视觉(visual)、音频(audio)和文本(text)三种不同类型的输入数据。以下是对特征编码过程的详细解释:
多头注意力机制:对于每种类型的输入数据,本文首先使用多头注意力机制来编码特征。通过multihead_attention函数实现,其中queries、keys和values参数均设置为相应类型的输入数据。这里,我们设置了4个注意力头(num_heads=4),以及0.2的dropout比率(dropout_rate=0.2),以避免过拟合。training=True表示当前是在训练模式下,causality=False表示这是一个非因果注意力机制,即注意力可以覆盖整个序列。
前馈网络:在多头注意力机制之后,本文使用一个前馈网络ff函数进一步处理编码后的特征。这个前馈网络包含两个全连接层,第一层的单元数是注意力维度的4倍(num_units=[4 * self.config.att_dim]),第二层则恢复为原始的注意力维度(self.config.att_dim)。这种设计有助于在注意力机制的基础上进一步提取和转换特征表示。
特征维度的匹配:通过前馈网络,我们确保了特征编码后的数据能够保持与原始输入数据相同的维度,这对于后续的模型训练和处理流程是必要的。代码如下所示:
with tf.variable_scope('vv', reuse=tf.AUTO_REUSE): enc_vv = multihead_attention(queries=visual, keys=visual, values=visual, num_heads=4, dropout_rate=0.2, training=True, causality=False) enc_vv = ff(enc_vv, num_units=[4 * self.config.att_dim, self.config.att_dim]) with tf.variable_scope('aa', reuse=tf.AUTO_REUSE): enc_aa = multihead_attention(queries=audio, keys=audio, values=audio, num_heads=4, dropout_rate=0.2, training=True, causality=False) enc_aa = ff(enc_aa, num_units=[4 * self.config.att_dim, self.config.att_dim]) with tf.variable_scope('tt', reuse=tf.AUTO_REUSE): enc_tt = multihead_attention(queries=text, keys=text, values=text, num_heads=4, dropout_rate=0.2, training=True, causality=False) enc_tt = ff(enc_tt, num_units=[4 * self.config.att_dim, self.config.att_dim])通过这种特征编码方法,我们能够为不同类型的输入数据生成丰富且具有区分性的特征表示,这对于后续的模型训练和预测任务至关重要。这种编码方式不仅提高了模型对数据的理解能力,也为处理多模态数据提供了一种有效的技术手段。
3.4.2 特征融合
在本项目的深度学习模型中,特征融合和模态间交互影响是通过精心设计的多头注意力机制和前馈网络来实现的。首先,本文分别对视觉(visual)和音频(audio)特征进行编码,使其受到文本(text)特征的影响。
本文将视觉特征作为查询(queries)输入,而将文本特征同时作为键(keys)和值(values)输入,通过多头注意力机制,允许模型在视觉特征中寻找与文本特征相关的信息。这个过程通过设置num_heads=4来实现,意味着同时进行4个不同的注意力计算,增强了模型捕获不同方面信息的能力。随后,我们设置dropout_rate=0.2以避免过拟合,training=True指示当前处于模型训练阶段,而causality=False表明这是一个非因果注意力机制,允许模型在处理序列时不受时间顺序限制。
紧接着,本文通过一个前馈网络ff对注意力机制的输出进行进一步的特征变换,其中 num_units=[4 * self.att_dim, self.att_dim] 定义了前馈网络的单元数,这有助于模型在保持原始特征维度的同时,进一步提取和转换特征表示。
类似地本文对音频特征执行相同的操作,确保音频特征也能与文本特征进行有效的交互,增强模型对音频信息的理解。代码实现如下:
with tf.variable_scope('enc_TinfuluenceV', reuse=tf.AUTO_REUSE): enc_TinfuluenceV = multihead_attention(queries=enc_vv, # 32 * 300 * 300 keys=enc_tt, values=enc_tt, num_heads=4, dropout_rate=0.2, training=True, causality=False) enc_TinfuluenceV = ff(enc_TinfuluenceV, num_units=[4 * self.att_dim, self.att_dim]) # 32 * 300 * 300 with tf.variable_scope('enc_TinfuluenceA', reuse=tf.AUTO_REUSE): enc_TinfuluenceA = multihead_attention(queries=enc_aa, # 32 * 300 * 300 keys=enc_tt, values=enc_tt, num_heads=4, dropout_rate=0.2, training=True, causality=False) enc_TinfuluenceA = ff(enc_TinfuluenceA, num_units=[4 * self.att_dim, self.att_dim]) # 32 * 300 * 300 enc_vv_new = tf.convert_to_tensor(enc_TinfuluenceV) enc_aa_new = tf.convert_to_tensor(enc_TinfuluenceA) enc_vv_new = tf.squeeze(enc_vv_new,1) enc_aa_new = tf.squeeze(enc_aa_new,1) enc_tt_new = enc_tt这种设计允许模型在不同模态之间进行信息的整合和融合,通过多头注意力机制和前馈网络的结合,提高了模型对多模态数据的表达能力。最终,我们得到了编码后的视觉和音频特征,它们不仅包含了原始模态的信息,还融入了文本特征的影响,为后续的模型训练和预测任务提供了更加丰富和综合的特征表示。
3.4.3 结果预测
为了指导模型训练,本文引入了决策融合方式。在多模态特征的解码阶段,我们使用SigmoidAtt函数对不同模态的特征编码进行解码,生成对应的输出。这些输出随后通过密集连接层和线性变换,生成最终的预测结果output_res_vv、output_res_aa和 output_res_tt。
为了评估模型的性能,本文使用tf.one_hot将标签self.label转换为独热编码格式ouput_label,以便于与预测结果进行比较。预测结果通过与标签的比较,可以进一步计算模型的分类性能。代码实现如下:
outputs_en_vv = SigmoidAtt(enc_vv_new, Wr_wqv, Wm_wqv, Wu_wqv) outputs_en_aa = SigmoidAtt(enc_aa_new, Wr_wqa, Wm_wqa, Wu_wqa) outputs_en_tt = SigmoidAtt(enc_tt, Wr_wqt, Wm_wqt, Wu_wqt) ouput_label = tf.one_hot(self.label, self.config.class_num) temp_new_vv = outputs_en_vv temp_new_vv = tf.layers.dense(temp_new_vv, self.config.att_dim, use_bias=False) output_res_vv = tf.add(tf.matmul(temp_new_vv, W_l), b_l) temp_new_aa = outputs_en_aa temp_new_aa = tf.layers.dense(temp_new_aa, self.config.att_dim, use_bias=False) output_res_aa = tf.add(tf.matmul(temp_new_aa, W_l), b_l) temp_new_tt = outputs_en_tt temp_new_tt = tf.layers.dense(temp_new_tt, self.config.att_dim, use_bias=False) output_res_tt = tf.add(tf.matmul(temp_new_tt, W_l), b_l) with tf.variable_scope('vatWei', reuse=tf.AUTO_REUSE): Wv = tf.get_variable('Wv', shape=[1]) Wa = tf.get_variable('Wa', shape=[1]) Wt = tf.get_variable('Wt', shape=[1]) output_res_vv = tf.multiply(output_res_vv, Wv) output_res_aa = tf.multiply(output_res_aa, Wa) output_res_tt = tf.multiply(output_res_tt, Wt) output_res = tf.add(output_res_vv, tf.add(output_res_aa, output_res_tt)) self.prob = tf.nn.softmax(output_res) with tf.name_scope('loss'): loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=output_res, labels=ouput_label)) self.loss = loss self.l2_loss = tf.contrib.layers.apply_regularization(regularizer=tf.contrib.layers.l2_regularizer(0.0001), weights_list=[W_l, b_l]) self.total_loss = self.loss + self.l2_loss通过这种设计,我们不仅能够训练模型以最小化预测误差,还能够通过正则化技术提高模型的泛化能力。这种综合的方法为多模态学习任务提供了一种有效的技术手段,有助于提高模型在复杂数据集上的性能。
3.5 深度学习算法训练
本文在训练深度学习模型的过程中,采用了一些核心的机器学习技术。首先,模型参数是通过Xavier初始化来设定的,这有助于在训练初期避免梯度消失或爆炸的问题。训练中使用的优化算法是Adam,它是一种非常流行的自适应学习率优化算法,能够根据参数的梯度自适应调整学习率。
损失函数的设计也很关键,自定义了一个损失函数来指导模型的训练。在每个训练周期,模型通过前向传播计算输出和损失,然后反向传播算法根据损失来更新模型的权重。
为了防止模型过拟合,本文还引入了L2正则化,这是一种常见的正则化技术,通过惩罚大的权重值来促使模型学习到更加简单的表示。此外,定期保存模型的检查点惯不仅有助于监控训练过程,还可以在模型出现意外时恢复到之前的状态。代码实现如下:
def train(sess, setting): with sess.as_default(): dataset = Dataset() initializer = tf.contrib.layers.xavier_initializer() with tf.variable_scope('model', reuse=None, initializer=initializer): m = MM(is_training=FLAGS.train) optimizer = tf.train.AdamOptimizer(setting.learning_rate) global_step = tf.Variable(0, name='global_step', trainable=False) train_op = optimizer.minimize(m.total_loss, global_step=global_step) sess.run(tf.initialize_all_variables()) saver = tf.train.Saver(max_to_keep=None) for epoch in range(setting.epoch_num): for i in range(int(len(traindata['L']) / setting.batch_size)): cur_batch = dataset.nextBatch(traindata, testdata, FLAGS.train) feed_dict = {} feed_dict[m.visual] = cur_batch['V'] feed_dict[m.audio] = cur_batch['A'] feed_dict[m.text] = cur_batch['T'] feed_dict[m.label] = cur_batch['L'] temp, step, loss_ = sess.run([train_op, global_step, m.total_loss], feed_dict) if step >= 10 and step % 10 == 0: time_str = datetime.datetime.now().isoformat() tempstr = "{}: step {}, Loss {:g}".format(time_str, step, loss_) print(tempstr) path = saver.save(sess, './model1/MT_ATT_model', global_step=step)3.6 深度学习算法性能测试
在本项目中,模型的评估和测试过程是通过一系列函数来实现的。evaluation 函数负责计算预测结果和真实标签的 F1 分数和准确率,这两个指标是衡量模型性能的关键。test 函数是测试过程中的核心,它首先加载数据集,然后定义了模型的 TensorFlow 变量作用域,并初始化了模型实例 mtest。随后加载之前训练过程中保存的最佳模型检查点。测试过程中,我们尝试恢复一系列定期保存的模型状态,并在每个模型状态上执行测试集的预测。
在测试循环中,对于测试数据集的每个批次,本文提取预测概率,并将预测结果与真实标签进行比较。通过 evaluation 函数计算每次预测的 F1 分数和准确率,并将结果累积起来。本文还跟踪最佳模型的状态,即在测试过程中获得最高准确率的模型编号。
最终,test 函数打印出最佳模型的迭代次数以及相应的最佳的准确率。这个过程不仅验证了模型的性能,还帮助人们理解模型在不同训练阶段的表现,为进一步的模型优化和调整提供了依据。代码实现如下:
def evaluation(y_pred, y_true): f1_s = f1_score(y_true, y_pred, average='macro') accuracy_s = accuracy_score(y_true, y_pred) return f1_s, accuracy_s def is_equal(a, b): flag = 1 for i in range(len(a)): if a[i] != b[i]: flag = 0 break return flag def test(sess, setting): dataset = Dataset() with sess.as_default(): with tf.variable_scope('model'): mtest = MM(is_training=FLAGS.train) saver = tf.train.Saver() testlist = range(50, 10000, 10) best_model_iter = -1 best_model_acc = -1 all_acc = [] for model_iter in testlist: try:saver.restore(sess, './model1/MT_ATT_model-' + str(model_iter)) except Exception:continue total_pred = [] total_y = [] for i in range(int(len(testdata['L']) / setting.batch_size)): cur_batch = dataset.nextBatch(traindata, testdata, FLAGS.train) feed_dict = {} feed_dict[mtest.visual] = cur_batch['V'] feed_dict[mtest.audio] = cur_batch['A'] feed_dict[mtest.text] = cur_batch['T'] feed_dict[mtest.label] = cur_batch['L'] prob = sess.run([mtest.prob], feed_dict) for j in range(len(prob[0])): total_pred.append(np.argmax(prob[0][j], -1)) for item in cur_batch['L']: total_y.append(item) f1, accuracy = evaluation(total_pred, total_y) all_acc.append(accuracy) if accuracy > best_model_acc: best_model_acc = accuracy print('最好的模型编号', best_model_iter) print('最好的准确率', best_model_acc)通过这种系统化的测试方法,我们能够全面评估模型的泛化能力,并确保所选模型在实际应用中的有效性和可靠性。
3.7 系统测试
在本系统开发中,我们实现了一个简洁直观的用户交互流程。用户仅需输入数字 “1” 即可轻松启动检测过程。一旦用户做出选择,系统便立即在后台激活算法模型,开始一系列复杂的训练和运算任务。这包括对数据集的预处理、特征的提取,以及模型的参数优化。

随着模型运算的完成,系统将对所有用户进行测试,并生成详细的测试报告。这份报告不仅展示了模型预测的结果,还与实际的真实结果进行了对比,以便进行准确评估。系统将自动计算并展示模型的准确率,这一指标反映了模型预测的准确性和可靠性。
在系统测试阶段,特别关注源数据集中的第一条数据。本文假设这是当前用户的有效数据,并将其作为模型初步测试和验证的基础。这种做法有助于快速评估模型对新数据的适应性和预测能力。其中数字与情感的对应关系如下:
emo_dict = { '0': '快乐', '1': '生气', '2': '悲伤', '3': '中性', '4': '挫折', '5': '兴奋', '6': '惊讶' }
整个过程的设计旨在确保用户能够轻松获取检测结果,同时对模型的性能有一个清晰的认识。这种透明度和即时反馈机制不仅增强了用户的信任感,也为系统开发者提供了宝贵的数据,以便进行持续的优化和改进。
第四章 总结
在本项目中,开发了一个深度学习模型,专注于家庭暴力背景下的情感分析。这个系统通过先进的技术手段,能够提前识别情感变化,帮助预防潜在的家庭冲突。我们利用了BERT等预训练语言模型来提取文本特征,并结合了多头注意力机制和Transformer架构的优势,以提高模型对情感状态的识别能力。项目的核心是一个情感检测系统,它能够分析家庭成员之间的交流信息,识别出潜在的负面情绪和冲突信号。系统通过实时监控和分析家庭内部的沟通模式,能够在家庭暴力问题发生前提供预警,帮助预防和减少暴力事件的发生。在开发过程中,使用了CMU-MOSI等多模态情感分析数据集进行训练和测试,这使得模型能够从文本中提取情感相关的特征,并对可能的情感冲突进行评估。此外,系统的用户界面设计简洁直观,确保了易用性和可访问性。







