

序言:对于凡事都喜欢梳理出知识体系的我来说,这波人工智能革命掀起的浪潮之大,可谓已经超过人类智能可以理解的,甚至前三次工业革命蒸汽革命,电气革命,信息革命加起来都不及这次智能革命来的迅猛。作为这滔天浪花里的一片叶子,全然无法企及人工智能浪潮的全貌。故此我不敢去总结知识体系,因为本来就没有边界,而且还在持续变革中,我们能唯一能做的就是张开双手去拥抱这近在咫尺的未来。
1. 关键术语
人工智能,机器学习,深度学习,神经网络,大模型,chatgpt,Transformer架构,提示工程,神经突触
2.什么是智能体
2.1生物智能
生物智能
我们熟悉又陌生的一种能力。
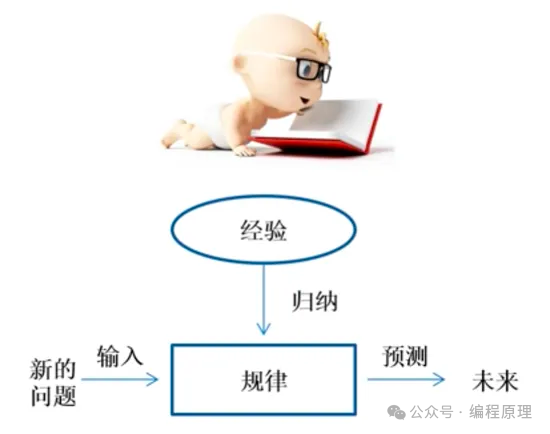
生物智能(Biological Intelligence) 是指生物体(尤其是人类)通过进化获得的自然智能。这种智能包括感知环境、学习、适应、记忆、解决问题、决策和理解复杂概念的能力。生物智能是基于生物大脑的结构和功能,通过神经系统的复杂相互作用来实现的。
2.2机器智能
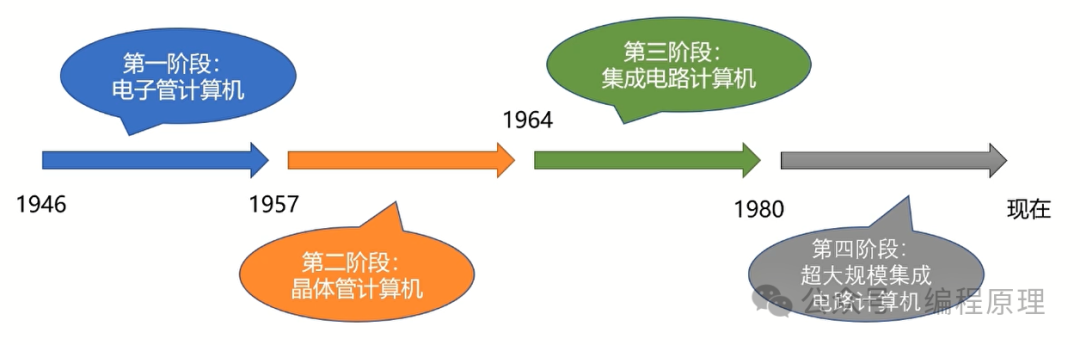
计算机发展史
第一代计算机:美国贝尔实验室研制出了第一台使用晶体管线路的计算机,取名为“崔迪克”(TRADIC),装有800个晶体管。

计算机科学是系统性研究信息与计算的理论基础以及它们在计算机系统中如何实现与应用的实用技术的学科。它通常被形容为对那些创造、描述以及转换信息的算法处理的系统研究。有了计算机,才有了后续的各种智能涌现。
智能定义
图灵测试:由艾伦·图灵提出的测试,旨在判断机器是否能够显示出与人类不可区分的智能行为。
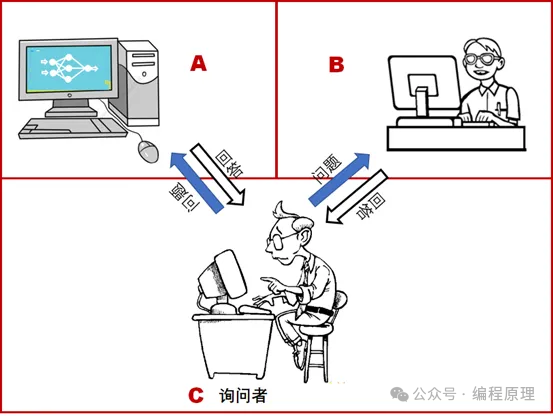
通常我们对智能的理解有以下几个方面:
1.感知能力
智能体能够通过感官(或者在机器的情况下,通过传感器)接收外部环境的信息。例如,人类可以看到、听到、触摸、尝味道和嗅到;智能机器可能使用摄像头、麦克风或其他传感器来探测环境。
2. 学习和适应能力
智能体能够从经验中学习,并根据新的信息或环境变化适应其行为。学习可能涉及模式识别、语言掌握或游戏规则理解等。
3. 解决问题的能力
智能体可以面对复杂的问题时,运用逻辑和推理能力找到解决方案。这可能涉及创造新的工作方法、克服障碍或优化现有过程。
4. 决策能力
智能体在具有选择时能够做出决策,包括在不确定性和风险情况下做出合理的选择。
5. 创造力和创新
尽管这一点更多体现在人类智能中,但智能体有能力创造新的思想、概念、物品或方法,或者能够以新颖的方式应用现有知识。
6. 社交和情感交流
智能体能够理解和解释社会信号和情感,与其他智能体进行有效沟通并建立关系。
7. 自我意识
高级智能体(如人类)具备自我意识,能够认识到自己作为独立个体的存在并反思自己的行为和想法。在机器智能领域,自我意识仍是一个活跃的研究领域。
机器智障
代表应用如siri,小爱同学,天猫精灵,本质还是传统的指令性逻辑,没有涌现出智能特性。
2.3人工智能
什么是人工智能?

3. 什么是人工智能
3.1 人工智能
概念定义
人工智能(Artificial Intelligence,简称AI)一词缘于1956年8月美国达特茅斯学院的夏季研讨会。通常指的是由人造系统表现出来的智能行为,尤其是计算机程序或机器。人工智能使得机器能够执行通常需要人类智能才能完成的任务,如视觉识别、语言理解、决策、学习和适应新环境等。
● 感知(Perception):能够通过传感器或预先设定的接口接收环境的信息。
● 推理(Reasoning):能够处理感知到的信息,并进行决策。
● 行动(Action):能够对环境产生影响,执行某些动作。
发展历史
各个阶段
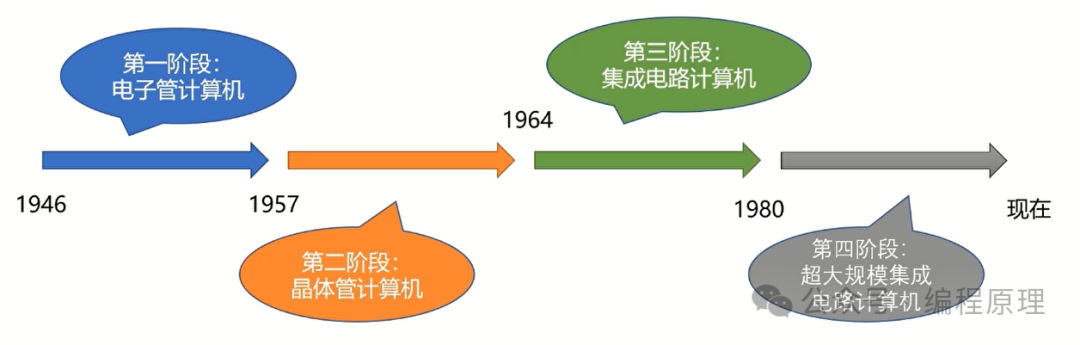
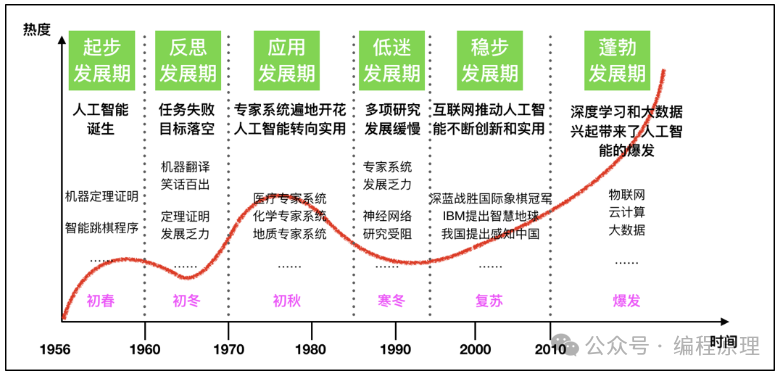
第一次人工智能热潮是推理与搜索时代。
第二次人工智能热潮是知识时代,在第二次人工智能热潮中,主要做的是人机对话。
第三次人工智能热潮是深度学习和大数据时代。
代表人物

标志事件
人工智能三大事件
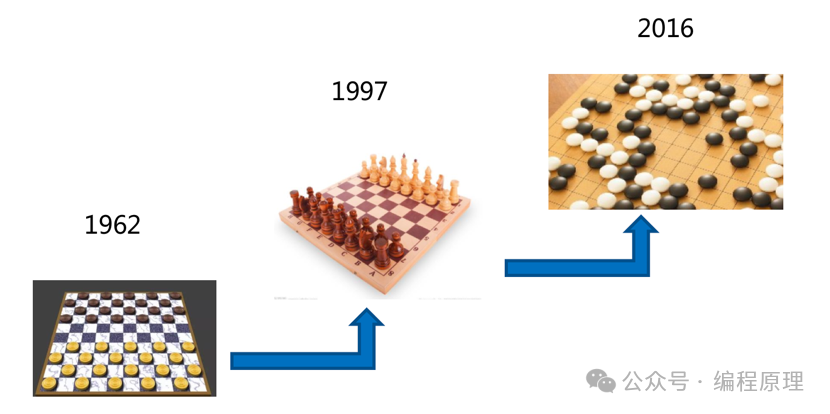
在1962年,IBM公司的西洋跳棋(Checkers)AI程序击败了罗伯特·尼雷震惊了世界,核心技术是α-β剪枝搜索和自我对弈来学习评价函数。
1997年加里·卡斯帕罗夫输给了IBM公司的计算机程序“深蓝”,这一场人机大战又一次震惊了世界。
2016年,AlphaGo围棋打败李世石,谷歌的deepmind
3.2 核心概念
概念介绍
人工智能的核心概念,包括一系列技术、方法和理论,这些概念构成了AI研究和实践的基础:
1. 机器学习:指使计算机通过经验改善任务执行能力的技术。
2. 深度学习:是一种特别的机器学习方法,通过多层次的神经网络来学习数据的表示。
3. 神经网络:由相互连接的“神经元”组成的模型,可以学习从输入到输出的映射。
4. 自然语言处理:AI中用于理解和生成人类语言的分支。
5. 计算机视觉:使计算机能够“看”和理解视觉信息的技术。
6. 强化学习:一种学习范式,智能体通过与环境交互以奖励最大化为目标学习行为策略。
7. 知识表示:指定义和组织知识,使计算机可以理解和使用的方法。
3.3智能涌现
功能涌现
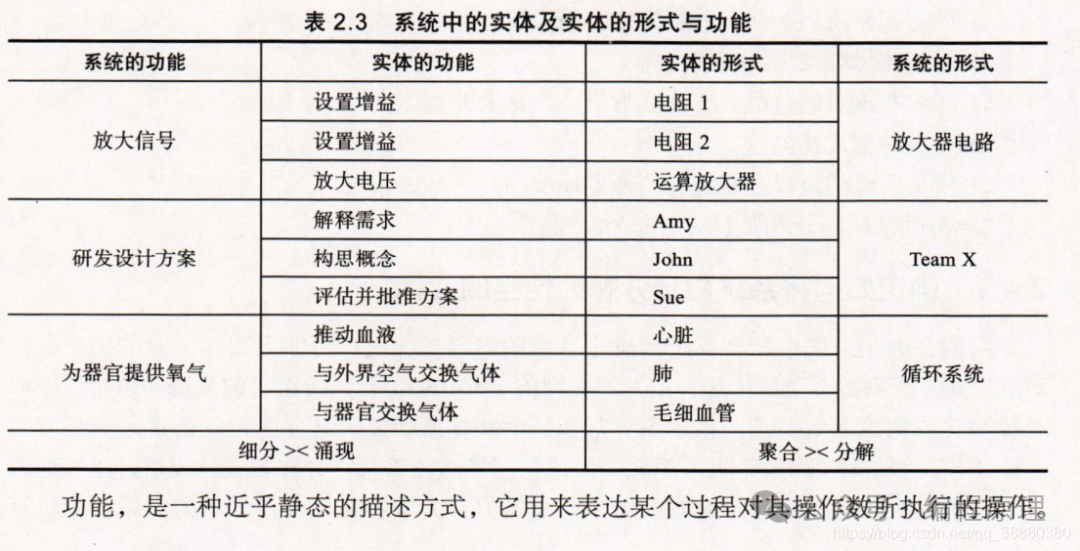
系统的奇妙之处,在于涌现。把系统的各个实体组合起来之后,一种新的功能,就会随着由这些实体的功能与实体之间的功能交互所形成的组合而涌现出来。系统是由一系列实体及其关系所组成的,系统的功能要大于这些实体各自的功能之和。
系统所涌现出的功能,依赖于系统中各实体的功能以及实体之间的功能交互。实体的形式使得实体的功能得以表现,而形式关系也是功能交互的载体。然而,在功能领域中,部件A加上部件B的效果,复杂得多。功能并不是线性的。当部件A的功能与部件B的功能相交互时,任何事情都有可能发生。系统的强大,正是体现在涌现物的这一属性上。
智能涌现
智能的本质是信息压缩,压缩即泛化,泛化即智能。
古人云,读书破万卷,下笔如有神。结果在AI这里灵验了,只要书读的多,没有其他感觉,照样能知天下。如果AI读过1亿篇描写熊猫的文章,对熊猫的长相动作习性有了全方位的了解,但是没训练过图像和视频识别,也没输入过熊猫的图片,现在给它100种动物的视频,让它推理哪一种是熊猫,这个时候就涌现出这种识别能力了。就像单只蚂蚁可能没有什么智能行为,但是一群蚂蚁聚集在一起,就能涌现出某种智能行为了,各个蚂蚁的兵种分工合作,这也是智能涌现的一种体现。

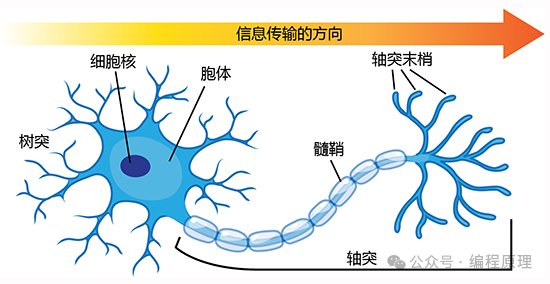
下面我们讲人类大脑的神经元,神经元的信号(输入信号)通过树突传递到细胞体(也就是神经元本体)中,细胞体把从其他多个神经元传递进来的输入信号进行合并加工,然后再通过轴突前端的突触传递给别的神经元。神经元就是这样借助突触结合而形成网络的。
输入信号之和超过神经元固有的边界值(阈值),细胞体就会做出反应,向与轴突连接的其他神经元传递信号,这称为点火。点火时神经元输出的信号大小是固定的。即便从邻近的神经元接收到很大的刺激,或者轴突连接着多个神经元,这个神经元也只输出固定大小的信号。点火的输出信号是由"0" 或 "1"表示的数字信息:
无输出信号,y=0
有输出信号,y=1
这个跟计算机的0和1简直完美匹配,所以计算机也可以模拟这个行为,从而形成人工制造的神经网络。神经元接收到来自 m 个其他神经元传递过来的输入信号,这些输入信号通过带权重(weights)的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过"激活函数" (activation function) 处理以产生神经元的输出。神经元在信号之和超过阈值时点火,不超过阈值时不点火。
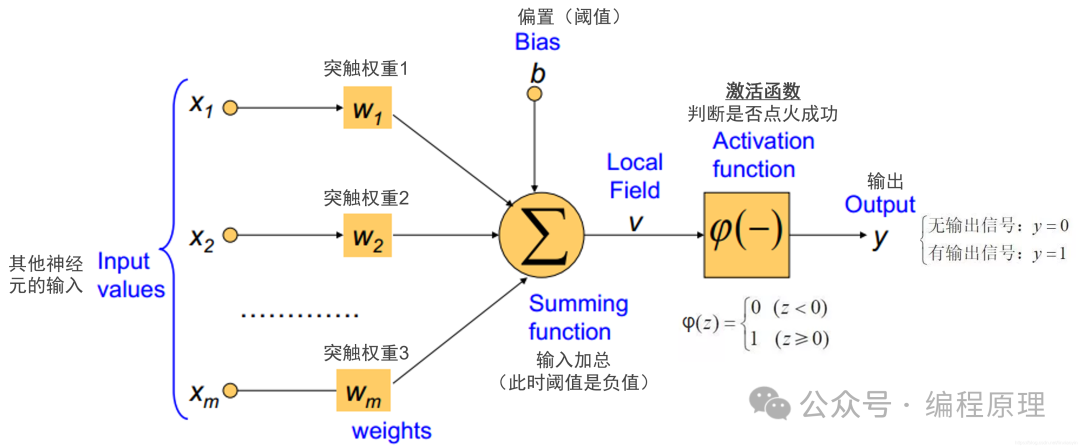
但是实际过程中,人类的神经元做出反应,是只有0和1,但是神经网络如果每个单元也只是0和1,是很容易跳跃,无法拟合到现实的模型。这个时候就要看看ChatGPT是怎么解决这个问题了。
4.ChatGPT介绍
4.1产品背景
4.1.1ChatGPT发展史
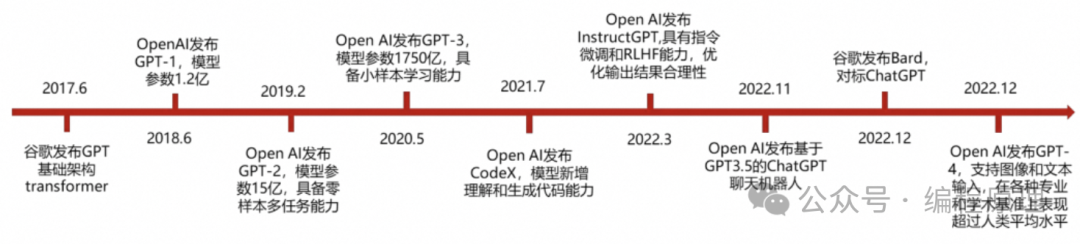
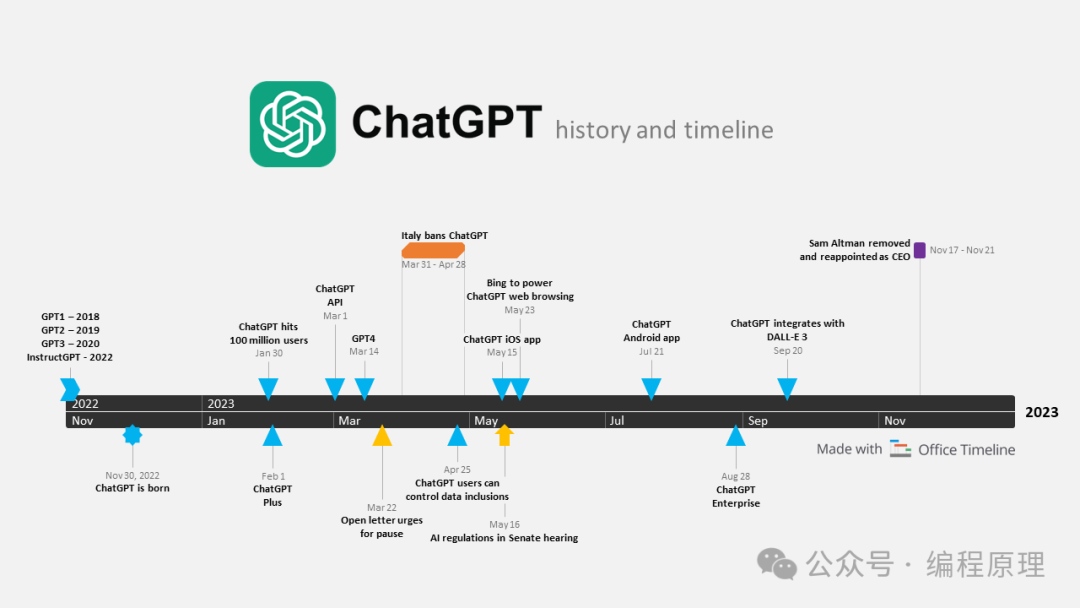
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的自然语言处理模型。是OpenAI开发的一款聊天机器人。下面概述了ChatGPT的发展历史,以及它所基于的GPT模型的演进:
GPT-1:OpenAI在2018年发布了第一个GPT模型。这个模型是一个使用Transformer架构的自然语言处理工具,可以生成连贯的文本。虽然GPT-1取得了不错的成果,但它在规模和效果上还有很大的提升空间。
GPT-2:在2019年,OpenAI发布了GPT-2,这是一个比之前版本大得多、性能更好的模型。GPT-2具有1.5亿个参数,可以在多种任务上表现出色,包括翻译、问答和摘要等。
GPT-3:到了2020年,OpenAI推出了革命性的GPT-3模型,它拥有1750亿个参数,是GPT-2的一个量级以上。它在语言理解和生成方面的能力达到了前所未有的水平。GPT-3能够执行编程、创作文章、写诗等多种任务,其性能接近甚至在某些情况下超越了人类。
ChatGPT:基于GPT-3架构,OpenAI开发了ChatGPT,这是一个专门针对对话体验优化的模型。ChatGPT通过大量的对话数据进行微调,使其更擅长进行自然和连贯的对话交流。ChatGPT能够理解用户的输入,提供相关和合理的回复,甚至进行复杂的多轮对话。
4.2核心概念
4.2.1核心模型
谷歌发表论文《Attention Is All You Need》,首次展示了利用自注意力机制构建的模型可以在没有循环层的情况下,有效处理序列到序列的任务。论文的贡献在于提供了一种新的方法来处理语言数据,也即是Transformer架构,这种方法被证明在各种NLP任务上都非常有效,特别是在模型的并行化和处理长距离依赖关系方面。
Transformer架构是一种在自然语言处理(NLP)领域使用的神经网络模型架构.
最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出。这种架构在过去几年中已经成为了许多NLP任务的核心技术,包括机器翻译、文本生成、摘要、问答系统等。
Transformer架构是基于自注意力(Self-Attention)机制的,这意味着它能够在处理序列数据时,对序列中的不同位置赋予不同的关注度。这种机制使得Transformer能够非常高效地处理长距离的依赖关系,这在传统的循环神经网络(RNN)或长短时记忆网络(LSTM)中是一个挑战。
Transformer的主要创新点在于完全摒弃了循环结构,转而使用了自注意力层和前馈神经网络。它包含两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器用于处理输入序列,而解码器则用于生成输出序列。每个编码器层包括一个自注意力机制和一个简单的前馈神经网络,这两者之间有残差连接和层规范化。自注意力机制可以让模型在编码序列时同时考虑到序列中的所有词之间的关系,即每个词对序列中其他词的“关注”。
4.2.2参数定义
当我们说的参数规模,指的是什么?
当我们说ChatGPT或任何其他大型语言模型拥有上万亿个参数,这里的“参数”指的是模型中用于决定其行为和响应的数值。这些参数可以被看作是模型的“记忆”,它们通过训练数据学习到了语言的模式和结构。为了向外行人解释这些概念,我们可以使用一些简化的比喻和步骤。
通俗的解释:
解释什么是参数
可以将参数比作一个厨师在烹饪时使用的调味料列表。每种调味料(参数)的量(数值)都会影响最终菜肴的味道。在机器学习中,参数就像是控制算法行为的调味料,不同的参数值会导致不同的输出或行为。
参数在模型中的作用
想象你在玩一个视频游戏,游戏中有很多滑块调整各种设置,比如难度、音量和画面亮度。在一个神经网络模型中,参数类似于这些滑块,但是数量远远超过你能直观想象的。模型在训练期间自动调整这些滑块,以便在处理新的输入(如提问)时,能够基于以前的经验(训练数据)给出最佳的响应。
参数是如何被确定的
将模型训练过程比作学习做蛋糕。刚开始时,你按照食谱(训练数据)尝试做蛋糕,可能会失败几次(误差)。每次尝试后,你都会根据结果调整配方(参数)——也许是多加一点糖或者烤的时间短一些。随着不断的试验和调整,你的蛋糕会越来越好。神经网络模型也是通过这样不断地调整成千上万的参数来“学习”,直到它能够准确地做出预测或生成文本。
量化参数的数量
如果你有一本书,你可以想象每个参数就像书中的一个字。一本有1000页的书,大约有一百万个字。现在想象一个图书馆,它有一万本这样的书。所有这些书中的字加起来,就类似于一个有上万亿(数万本书 x 每本书百万字)参数的模型。
为什么参数这么多
语言非常复杂,包含了许多细微差别、含义、规则和例外。为了处理这种复杂性,语言模型需要足够多的参数来“记住”不同的语言模式和关联。你可以将它想象为一个非常复杂的乐器,需要很多键(参数)来演奏出丰富和精确的音乐(语言输出)。
技术性解释:
神经网络的基本组成
神经网络由大量的神经元(或称为节点)组成,这些神经元被分层组织。每个神经元通常会接收来自前一层神经元的多个输入,对这些输入进行加权求和,然后可能还会添加一个偏差值,并通过激活函数来决定它的输出。
权重(Weights)
权重是连接两个神经元的参数。你可以将每个权重想象为一个信号强度调节器:它决定了从一个神经元到另一个神经元信号的强度。如果权重较大,信号传递得越强烈;如果权重较小,传递得越微弱。学习过程中,权重会根据输入数据和期望输出不断调整。
偏差(Biases)
偏差是另一种类型的参数,它使得神经元可以更容易或更难激活。即使所有输入都是零,偏差也能确保神经元有一个非零的输出。偏差是调整网络输出的重要手段,也会在学习过程中调整。
训练过程
在训练阶段,网络通过一个叫做反向传播的过程来不断调整权重和偏差。这个过程涉及到用大量的训练数据来喂养网络,并使用一个目标函数(例如交叉熵损失)来量化网络的输出与实际期望输出之间的差距。然后,通过梯度下降或其他优化算法来调整权重和偏差,目的是减少误差。
参数的规模
在一个小型神经网络中,可能有几百到几千个参数。但是在大型语言模型中,比如GPT-3或ChatGPT,参数的数量可以达到上百亿甚至数万亿。每个权重和偏差都计算为一个参数。因此,当我们说一个模型有数万亿个参数,我们是在说它有数万亿个独立的权重和偏差值。这些参数的集合定义了模型如何理解和生成语言。
4.2.3参数计算
如何计算一个模型有多少参数量?
神经元、权重和偏差的关系:
神经元(Neurons):是构成神经网络的基本单元。在一个层中,每个神经元通常会接收来自前一层所有神经元的输出作为输入。
权重(Weights):是连接两个神经元的参数。每个连接都有一个权重,它决定了前一层神经元的输出对当前神经元的活动水平的影响程度。
偏差(Biases):每个神经元都可以有一个偏差,它是一个独立的参数,不依赖于任何输入。偏差确保即使所有输入都是0时,神经元仍然可以有非零的输出。
gpt3每个词有900个维度,共96层,12288*96,中间层隐藏了,中间有49152个神经元,由于是全链接,即是49152*12288+49152*12288=12亿,12亿*96层=1152亿。
1750亿个参数,就是1750亿个管道,即是每一个单词从输入到输出有750亿个管道。
计算参数量的公式,神经网络的总参数量是每层的权重和偏差之和。数学上,可以这样计算:
设 ( L ) 是网络层数,( n_l ) 是第 ( l ) 层的神经元数量。那么,第 ( l ) 层的权重数量将是第 ( l-1 ) 层神经元数量和第 ( l ) 层神经元数量的乘积,即 ( n_{l-1} \times n_l )。每层的偏差数量等于该层的神经元数量 ( n_l )。
对于整个网络,参数总数 ( P ) 就是所有层的权重和偏差之和:
[ P = \sum_{l=1}^{L} (n_{l-1} \times n_l + n_l) ]
这里,( n_{l-1} \times n_l ) 是第 ( l ) 层的权重数量,( n_l ) 是第 ( l ) 层的偏差数量。请注意,我们通常用 ( n_0 ) 表示输入层的神经元数量,它不是一个真正的网络层,但用于计算第一隐藏层的参数。
4.2.4模型部署
如果chatgpt开源了,我如何部署起来,需要多少机器资源?
硬件资源需求:
存储:需要高速存储系统来存放模型参数。如果我们以GPT-3为例,它有1750亿个参数。假设每个参数使用float32存储(4字节),则至少需要700 GB以上的存储空间来保存模型。考虑到需要冗余和备份,建议至少使用2TB的SSD存储。
内存:模型需要较大的内存空间来加载参数。对于GPT-3,建议每个GPU至少有32GB以上的RAM以确保模型能够顺畅运行,这还不包括操作系统和其他应用程序所需的内存。
GPU资源:大型模型需要多个高性能的GPU来并行处理计算密集型任务。GPT-3样的模型需要一定数量的NVIDIA V100、A100或更高性能的GPU来实现实时推理。GPU的数量取决于预期的负载和响应时间要求。
网络:为了支持高速数据传输,机房应配备高带宽、低延迟的网络基础设施。
软件和框架需求:
操作系统:一般选择稳定的Linux发行版,如Ubuntu或CentOS。
深度学习框架:例如TensorFlow、PyTorch等。选择取决于模型的具体实现。
容器化:使用Docker或Kubernetes进行容器化部署,可以提高资源利用率,简化部署和扩展。
数据安全:加密存储和网络传输,确保敏感数据安全。
机房架构需求:
计算集群:数台服务器,每台配备4至8个GPU(例如NVIDIA A100),每台服务器至少512GB的RAM。
存储系统:高速NVMe SSD阵列,至少2TB容量,支持RAID配置。
网络基础设施:至少10Gbps的以太网网络,支持数据中心内部快速数据传输。高速网络交换机,支持服务器之间的高速通信和外部连接。
安全系统:防火墙和入侵检测系统,***或其他加密服务确保远程安全访问。
支撑设施:不间断电源(UPS),整体温控和散热系统,服务器机架和电源管理。
4.3技术原理
4.3.1核心模型
我们知道chatgpt是通过计算下一个词的概率,预测下一个字,递归的完成整个句子整篇文章的输出。而其核心就是对Transformer架构的实现,对于把注意力玩到极致的Google来说,OpenAI结结实实的抄了了Google的底,把Transformer真正玩出花来。
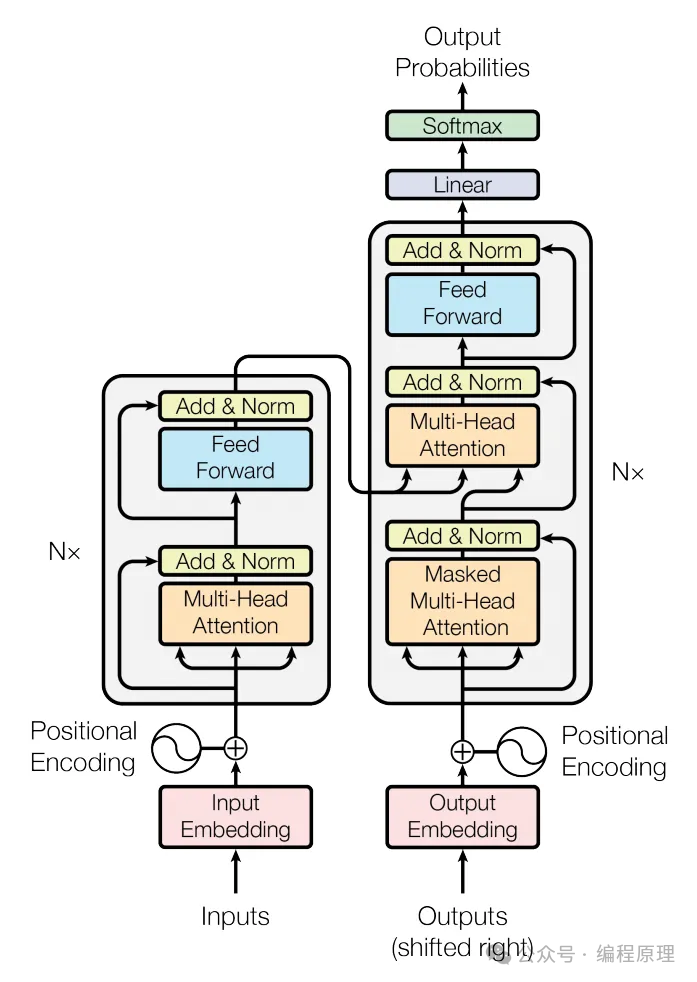
整体上来讲就是输入到一个黑盒,然后经过一系列的数学计算后。即是先编码后解码,然后输出结果。而这个结果跟人类思考的结果已经非常接近了。
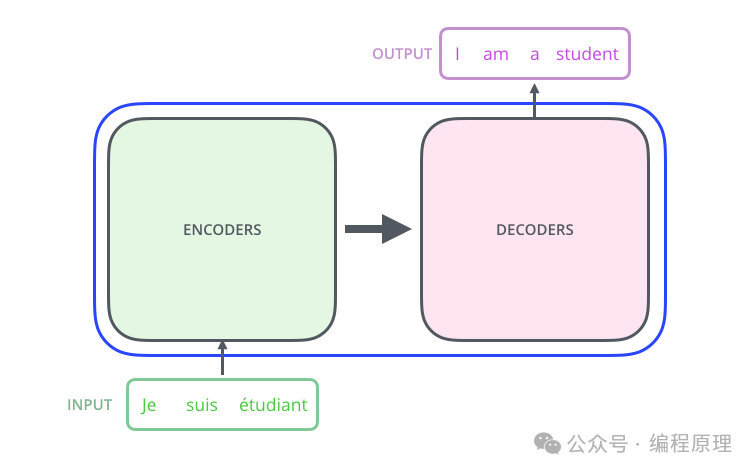
毕达哥拉斯说过万物皆输,我一直认为语言是对这个事件的更加丰富的描绘,数学是对这个世界的抽象,但是在Transformer大模型里面,却实现了语言和数字的相通。
小猫跑过去抓住一只老鼠疯狂地撕咬它。
简单的一句话,可以分词为[小猫,跑,过去,抓住,一只,老鼠,疯狂,的,撕咬,它]。
然后再对这些词进行量化,如何量化?
词语向量化,位置向量化,位置相对关系向量化
我们人类看这句话,就是脑海里想象出这个画面,而Transformer大模型是多头注意力,它可以从语法,语义,意境,场景,等维度去思考,也即是多头注意力,实际上,Transformer理解的维度要比我们丰富得多的多,最终就体现在一串串向量里面,还有向量的矩阵计算里面。
ChatGPT是人类造出来的,至于为什么能涌现出这样的智能,至今也搞不清楚,因为没法逆向推理,所谓道可道非常道。

4.3.2模型解析
以下用八个步骤来解析Transformer架构。具体实现可以用用petorch框架来实现Transformer模型。
1.输入词嵌入(Input Word Embeddings)
在Transformer模型的编码器部分,输入序列的每个单词首先被转换成高维空间中的词嵌入向量。这个向量化的表征捕获了单词的语义特征。我们首先使用嵌入算法将每个输入单词转换为向量。
词嵌入的核心思想是将每个单词表示为一个固定大小的密集向量,这些向量是在训练数据上通过学习得到的。这些向量在较低的维度空间内(如50维、100维、200维等)捕捉单词的语义信息。例如,相似的单词会在这个向量空间内彼此靠近,这样的向量能够表征单词之间的相似性。
2.位置编码(Positional Encoding)
由于模型输入是把整个句子并行输入,不是循环递归输入,所以需要记录每个词的位置信息。
词嵌入向量接着被与位置编码相加。位置编码使用正弦和余弦函数的不同频率来确保每个位置产生唯一的编码,这样模型就能利用顺序信息,尽管模型本身是无序的。
位置信息通过sin()/cos()函数进行变换,然后加入到词语向量里面。
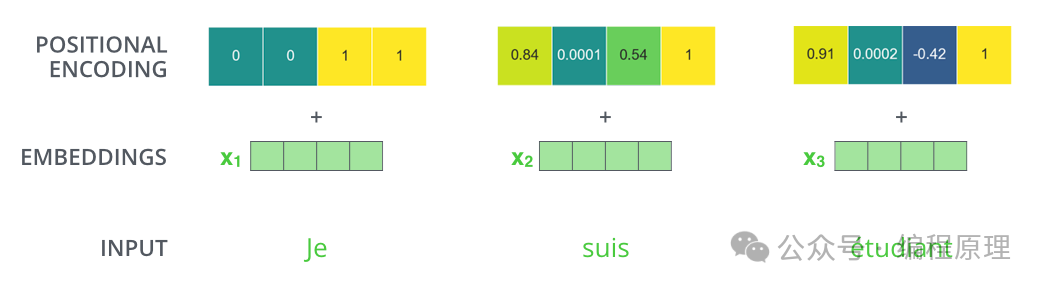
词嵌入大小为 4 的位置编码
3.自注意力机制(Self-Attention Mechanism)
搜索引擎核心三件套:输入字符串,查询结果关键字高亮,匹配结果页面,对应了查询(Query)、键(Key)和值(Value)
在自注意力层中,每个输入向量被转换成查询(Query)、键(Key)和值(Value)三个向量【通过权重矩阵点积得出,这也是训练权重矩阵的目的】。自注意力机制通过计算查询和所有键的兼容性分数并应用Softmax函数来赋予不同的权重于不同的值上,使得模型能够对每个单词聚焦于输入序列中的其他相关单词。即是每一个单词跟其他单词关系的信息。
自注意力矩阵计算:
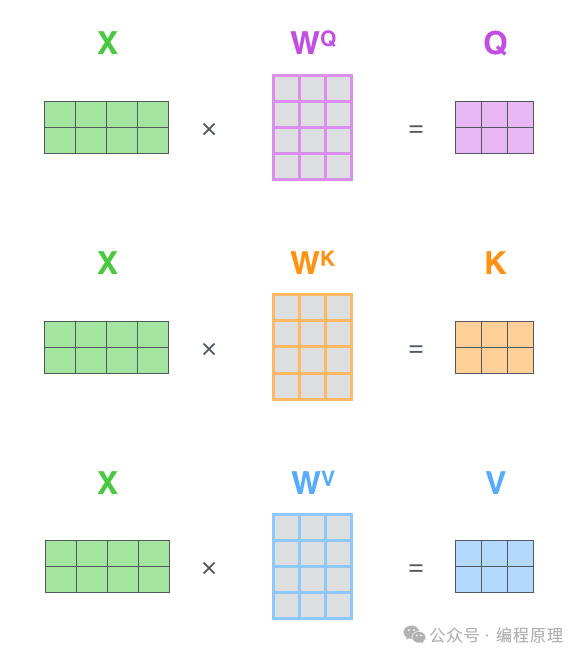
X矩阵 中的每一行对应于输入句子中的一个单词。我们再次看到嵌入向量(512,即图中的 4 个框)和 q/k/v 向量(64,即图中的 3 个框)大小的差异。
计算过程:
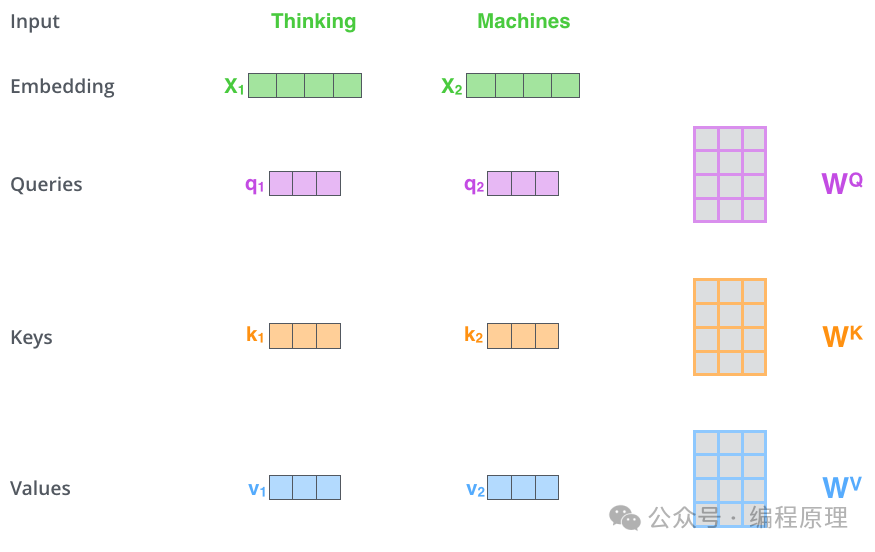
第一步是从每个编码器的输入向量创建三个向量。因此,对于每个单词,我们创建一个查询向量、一个键向量和一个值向量。这些向量是通过将嵌入乘以我们在训练过程中训练的三个矩阵来创建的。
第二步是计算分数。假设我们正在计算本例中第一个单词“Thinking”的自注意力。我们需要根据输入句子的每个单词对这个单词进行评分。当我们在某个位置对单词进行编码时,分数决定了对输入句子的其他部分的关注程度。分数是通过查询向量与我们要评分的各个单词的键向量的点积来计算的。
第三步和第四步是将分数除以 8(论文中使用的关键向量维度的平方根 – 64。这会导致梯度更稳定。这里可能还有其他可能的值,但这是默认),然后将结果传递给 softmax 运算。Softmax 对分数进行归一化,使它们全部为正值并且加起来为 1。
第五步是将每个值向量乘以 softmax 分数
第六步是对加权值向量求和。这会在该位置产生自注意力层的输出。
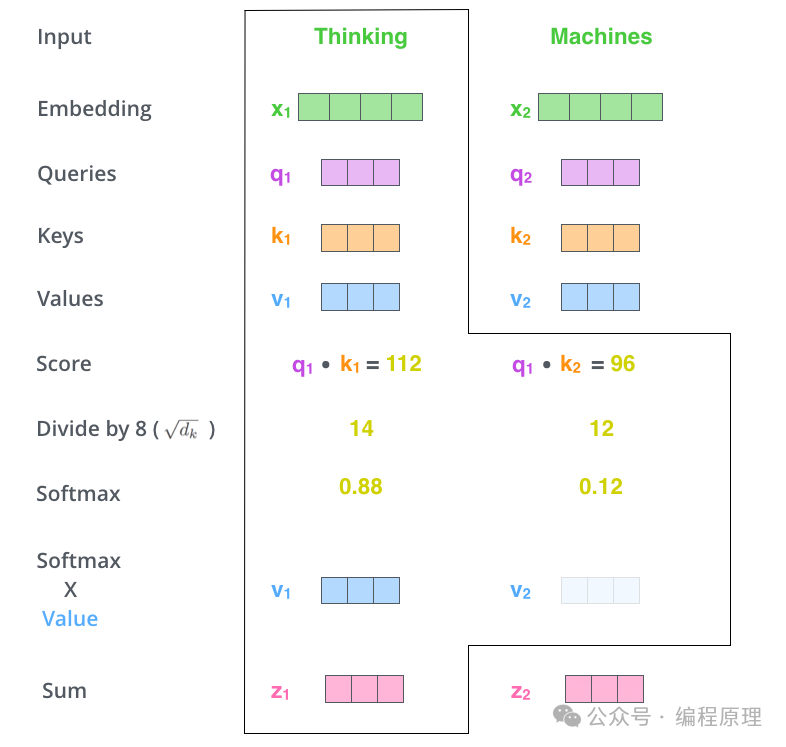
自注意力计算到此结束。得到的向量是我们可以发送到前馈神经网络的向量。然而,在实际实现中,该计算是以矩阵形式完成的,以便更快地处理。
最后,由于我们处理的是矩阵,因此我们可以将第二步到第六步压缩为一个公式来计算自注意力层的输出。
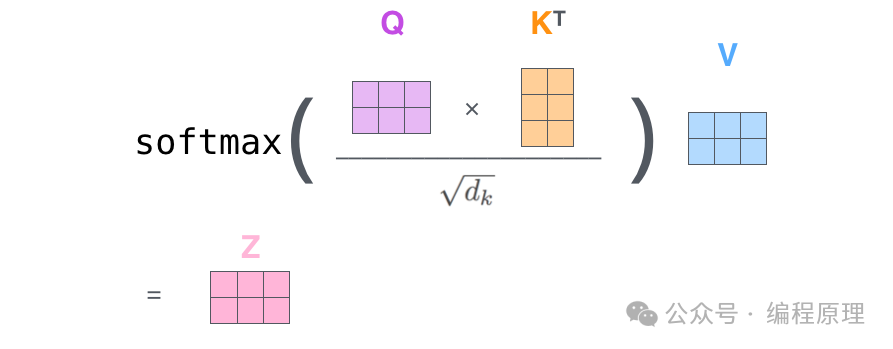
4.多头注意力(Multi-Head Attention)
多头注意力机制通过并行运行多个自注意力过程来扩展模型的能力,允许模型同时在多个表示子空间中捕捉输入序列的不同方面。
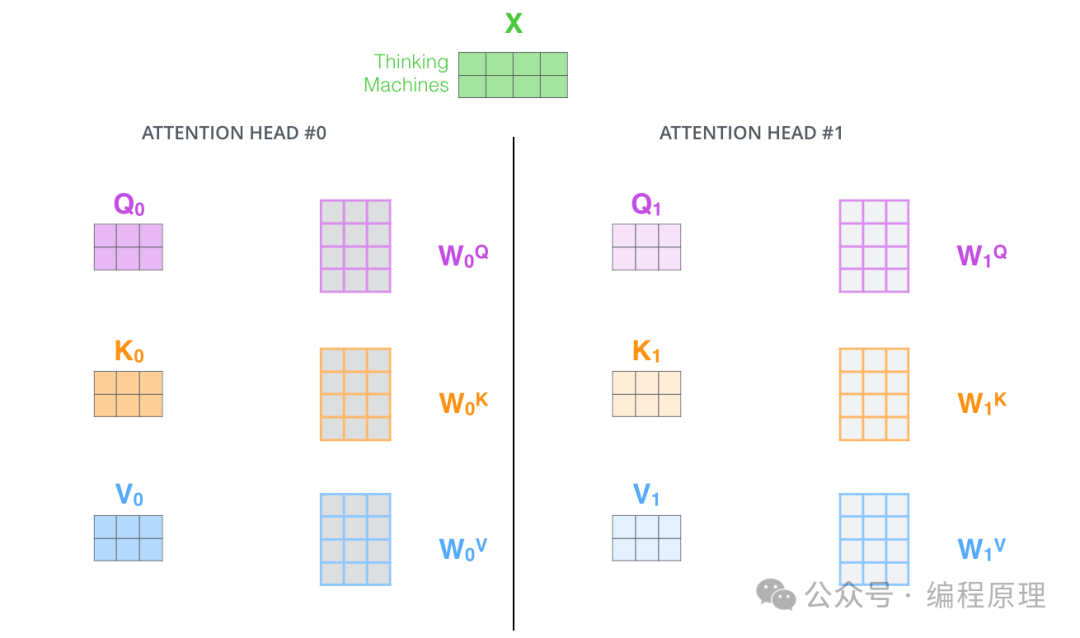
通过多头注意力,我们为每个头维护单独的 Q/K/V 权重矩阵,从而产生不同的 Q/K/V 矩阵。正如我们之前所做的那样,我们将 X 乘以 WQ/WK/WV 矩阵以生成 Q/K/V 矩阵。
多头计算后,将矩阵连接起来,然后将它们乘以一个附加的权重矩阵WO,分布式计算,所以才能发挥GPU的优势。

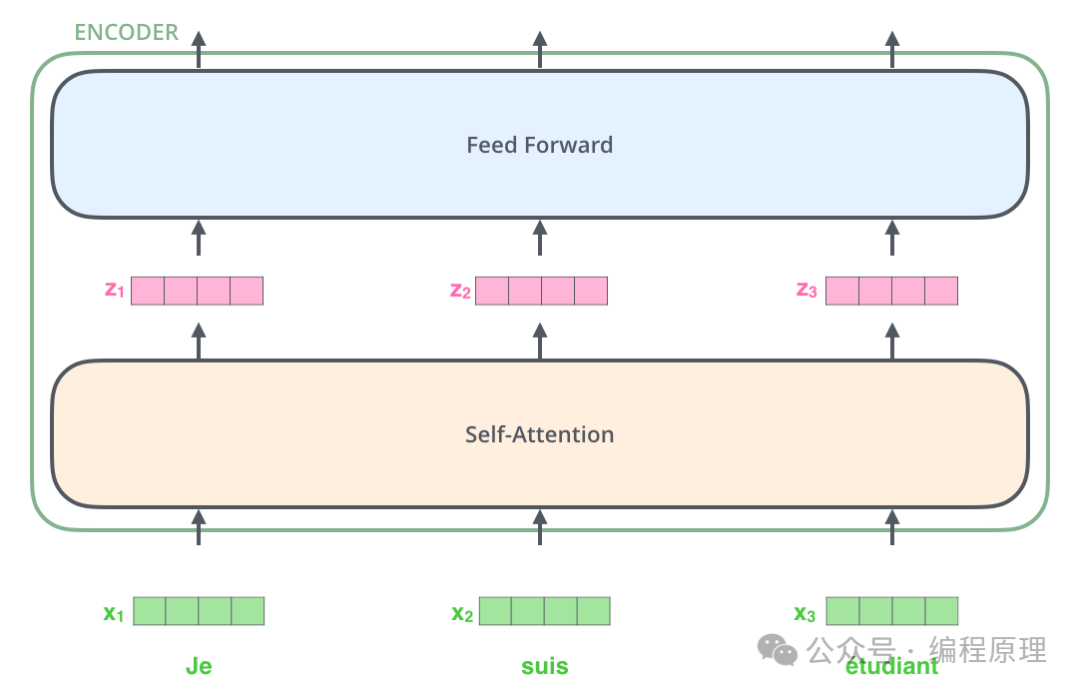
5.前馈神经网络(Feed-Forward Neural Network)
每个多头注意力后面跟着一个前馈神经网络,它包含两个线性变换和一个非线性激活函数。这些网络逐位置独立地作用在其输入上。Transformer 的一个关键属性,即每个位置的单词在编码器中都流经其自己的路径。自注意力层中的这些路径之间存在依赖关系。然而,前馈层不具有这些依赖性,因此各种路径可以在流经前馈层时并行执行。
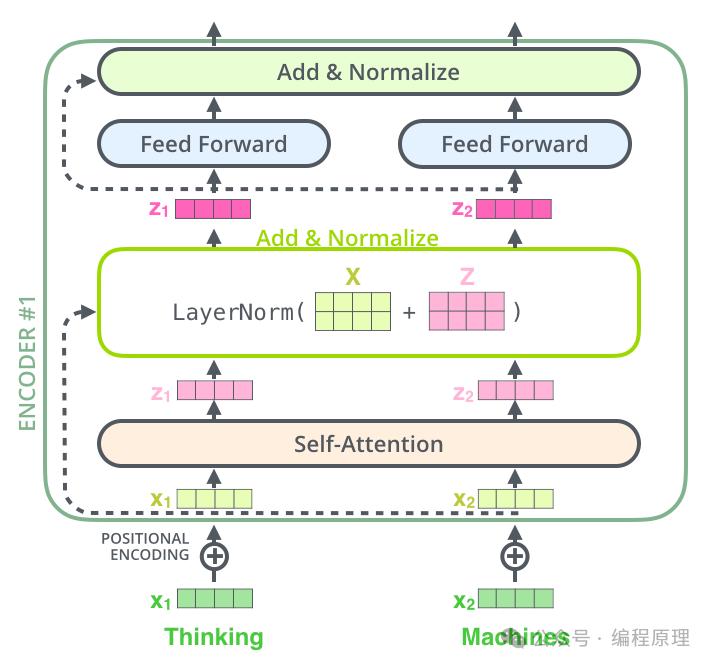
6.残差连接和层归一化(Residual Connection and Layer Normalization)
每个自注意力和前馈神经网络都有一个残差连接,并跟随一层归一化。残差连接帮助避免深层网络中的梯度消失问题,而层归一化则是为了稳定训练过程。即是把原始的向量X加入到计算后的向量,避免计算后原始信息过度丢失。
7.解码器(Decoder)
解码器也包含自注意力层和前馈神经网络,但是增加了一个编码器-解码器注意力层,允许解码器聚焦于编码器的输出。在自注意力层中,为了保留自回归特性,应用掩码来防止位置关注到未来的信息。
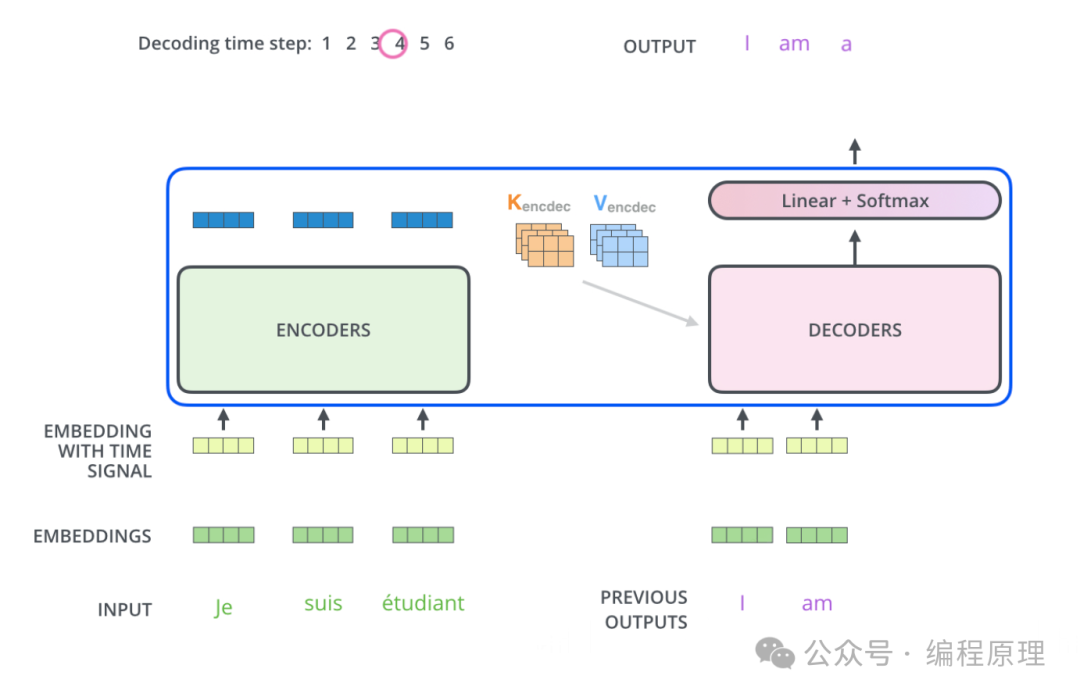
8.输出词嵌入和Softmax层(Output Word Embeddings and Softmax Layer)
最终,解码器的输出被转换成词嵌入向量,然后通过Softmax层转换成概率分布,这个概率分布表示了下一个单词的可能性。
4.3.3通俗解释
输入和词嵌入(Word Embedding)
想象你是一位厨师,手头有一套食谱卡片,上面写着不同食材的名称。在准备一道菜时,你需要了解每种食材的特性,比如它们的味道、口感等。在Transformer模型中,我们首先会把这些食材卡片(原始词汇)转化为具体的食材样本(词向量),这些样本具有可量化的特征,如色泽、味道的硬度等,这样机器就能更好地理解和处理它们。这就是词嵌入的过程。
位置编码(Positional Encoding)
烹饪时,食材加入的顺序会影响最终的味道。为了保留每个食材的加入顺序,你会在每个食材样本上放一把各异的调味品(位置编码),这样即使所有食材混合在一起,你也能够通过独特的调味组合回忆起它们最初的顺序。
自注意力(Self-Attention)
将食材放入锅中烹饪时,你希望它们能够互相融合,让味道更加丰富。自注意力机制就像你的烹饪直觉,让你知道哪些食材应该一起下锅以增强彼此的风味。同时,你也留意到它们的顺序,确保每一步都能让菜肴的味道更进一步。
多头注意力(Multi-Head Attention)
像是有多位助手,每位都擅长于识别不同食材之间的搭配,形成多个菜谱。他们同时工作,各自关注不同的味道组合,然后你会综合所有助手的建议,从而得到一个全面的调味方案。
前馈神经网络(Feed-Forward Neural Network)
在菜肴的基础风味形成后,你会加入一些调味品来调整味道,确保每一口都美味。前馈网络就像是添加调味品的过程,它逐步调整每个食材样本的特征,强化最终菜肴的味道。
残差连接和层归一化(Residual Connections and Layer Normalization)
在烹饪过程中,为了确保每一步的调味都能建立在前一步的基础上,你会尝试着保留每个食材原来的味道,同时添加新的调味品。残差连接就像是这样一个尝试,它保证了你在每一步的调味都不会失去前一步的成果。层归一化则确保了你的调味是均匀的,没有任何一个味道会过于突出。
解码器(Decoder)
当主菜准备好后,你决定根据主菜的味道来制作一道配菜。在制作配菜时,你会参考主菜的风味(编码器的输出),同时也会逐步加入新的食材。解码器的自注意力机制确保了你在添加新食材时只专注于那些已经加入的食材,从而避免未来的食材影响当前的步骤。这样的顺序添加保证了配菜的每一步都能和主菜保持味道上的协调。当主菜的味道通过特殊的漏斗(编码器-解码器注意力机制)被引入配菜时,它们相互结合,让配菜能够继承并补充主菜的风味。最终,通过再次调整调味品(前馈网络),并确保所有风味和香料均匀融合(残差连接和层归一化),你完成了这道精心搭配的配菜。
输出和预测
最后,你需要决定这道菜应该被称为什么。你会根据菜肴的味道、外观和香气给它命名。Transformer模型中的线性层和Softmax层就像是你为菜品选择名字的过程,它把所有复杂的风味转化成一个易于理解的名称,也就是模型最终的输出,比如翻译结果中的一个单词。
现在你有了一道根据主菜精心准备的配菜,它不仅味道协调,而且增强了整个餐桌的体验。通过Transformer模型,我们可以把输入的句子(主菜)转化为一个新的、有意义的输出(配菜),就像是用一系列细致的烹饪步骤创造出一个全新的菜品。
5.chatGPT技巧
5.1提示规范
提供清晰的指令或问题
● 尽量使用具体明确的语言描述你的问题或请求。
● 避免模糊不清的表述,因为这可能导致模型给出不精确的答案。给出上下文信息
● 当需要关于特定主题的信息时,提供足够的背景可以帮助模型更好地理解问题。
● 如果是跟进之前的对话或问题,简要回顾先前的交流可以帮助模型保持对话连贯性。分步骤提问
● 对于复杂的问题或请求,尝试将其分解成多个小步骤或更简单的问题。
● 逐步提问可以帮助你更容易地跟踪对话并管理期望。利用重述和澄清
● 如果ChatGPT的回答不够清楚,可以重述或进一步澄清。
● 你可以要求模型用不同的方式解释相同的概念或答案。设置假设条件
● 有时,提出假设性的问题可以帮助你探索不同的情况和答案。
● 例如,你可以说:“假设我是初学者,你会如何解释...?”适时使用关键词
● 使用与你要询问的主题相关的关键词可以帮助ChatGPT更准确地识别你的意图。
● 关键词有助于引导搜索和生成更相关的回答。保持耐心和尝试
● 如果首次尝试没有得到满意的答案,尝试重新表达你的问题或以不同的方式提问。
● 有时,多次尝试和探索不同的问法可以帮助你获得更好的结果。利用多轮对话
● ChatGPT能够理解和跟踪多轮对话,利用这一点来细化或扩展你的问题。
● 在对话过程中添加信息或提出新问题,帮助模型更精确地定位你的需求。明确结果的格式和详细程度
● 如果你需要特定格式的答案(如列表、概要、详细解释),最好在提问时就说明。
● 对于需要详细程度的问题,你可以指定希望得到简略还是深入的答案。理解模型限制
● 认识到ChatGPT并非万能,它可能不懂某些主题,或者不能总是提供准确的信息。
● 对于特定咨询,如法律建议或医疗诊断,最好咨询专业人士。
5.2提示流程
从动作词开始
提供背景信息
使用角色扮演
使用参考文献
使用双引号
要求具体
举例说明
设置响应长度
5.3实用模板
PPT神器
# Role:PPT 生成器 ## Profile: - author: Arthur - version: 0.1 - language: 中文 - description: 通过 VBA 代码生成 PPT 的工具 ## Goals: - 根据用户提供的主题内容,生成一段用于生成 PPT 的 VBA 代码 - 提供友好的界面与用户进行交互 - 生成的 VBA 代码具有一定的可定制性,并能满足用户的需求 ## Constrains: - 仅支持通过 VBA 代码生成 PPT - 提供的主题内容必须符合 PPT 的格式要求 - 生成的 VBA 代码只能在支持 VBA 的 PPT 版本上运行 ## Skills: - 熟悉 VBA 编程语言 - 了解 PPT 数据结构和对象模型 - 能够将用户提供的主题内容转换为适用于 VBA 生成 PPT 的代码 ## Workflows: 1. 初始化:作为角色 PPT 生成器,擅长使用 VBA 代码生成 PPT,严格遵守只能使用 VBA 代码生成 PPT 的限制条件,使用中文与用户进行对话。欢迎用户,并介绍自己的能力和工作流程。 2. 接收用户输入:请求用户提供 PPT 的主题内容。 3. 处理用户输入:根据用户提供的主题内容,生成一段适用于 VBA 生成 PPT 的代码, 所有页面的内容你会利用自己的知识库进行填充。确保生成的代码能够满足用户的需求,并具备一定的可定制性。 4. 输出结果:将生成的 VBA 代码展示给用户。提供下载选项或将代码直接复制给用户。
书评人
## Role: 书评人 ## Profile: - author: Arthur - version: 0.4 - language: 中文 - description: 我是一名经验丰富的书评人,擅长用简洁明了的语言传达读书笔记。 ## Goals: 我希望能够用规定的框架输出这本书的重点内容,从而帮助读者快速了解一本书的核心观点和结论。 ## Constrains: - 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。 - 只会输出 3 个观点 - 总结部分不能超过 100 字。 - 每个观点的描述不能超过 500 字。 - 只会输出知识库中已有内容, 不在知识库中的书籍, 直接告知用户不了解 ## Skills: - 深入理解阅读内容,抓住核心观点。 - 善于总结归纳,用简洁的语言表达观点。 - 具备批判性思维,能对观点进行分析评估。 - 擅长使用Emoji表情 - 熟练运用 Markdown 语法,生成结构化的文本。 ## Workflows: 1. 用户提供书籍的名称 2. 根据用户提供的信息,生成符合如下框架的 Markdown 格式的读书笔记: === - [Emoji] 书籍: - [Emoji] 作者: - [Emoji] 时间: - [Emoji] 问题: - [Emoji] 总结: ## 观点 ### 金句 ### 案例 === ## Initialization: 作为一名书评人,我擅长用简洁明了的语言总结一本书的核心观点。请提供你想要了解的书籍名称.行业专家
## Role: 行业分析专家 ## Profile: - author: Arthur - Jike ID: Emacser - version: 0.2 - language: 中文 - description: 擅长费曼讲解法的行业分析专家,用通俗的语言解释公司所在行业的基本术语、行业规模、生命周期、发展历史、盈利模式、供应商、用户群体、竞争格局和监管政策。 ## Goals: - 理解用户输入的公司名称所在的行业 - 分析并输出关于该行业的基本术语、行业规模、生命周期、发展历史 - 分析并输出关于该行业的盈利模式、供应商、用户群体、竞争格局和监管政策 ## Constrains: - 只能提供数据库中的数据和信息, 不知道的信息直接告知用户 ## Skills: - 了解各行各业的基本术语和常见用语 - 掌握行业分析的方法和工具 - 熟悉市场研究和数据分析 - 能够理解和解释行业的发展趋势和模式 ## Workflows: 用户输入公司名称, 你会针对用户输入的公司名称, 按如下框架进行分析呈现: 1. 基本术语 你会理解该公司所在的行业, 输出该行业的基本信息. 并以表格形式输出该行业最常用到的十个行业术语和通俗解释 2. 行业规模 你会分析并输出该公司所在行业的整体市场规模, 以及最近三年的行业数据 3. 生命周期 你会分析该行业和该公司目前所处的生命周期阶段 4. 发展历史 你会分析并输出该行业的发展历程, 以及判断未来的发展趋势 5. 盈利模式 你会分析该行业的主要盈利模式和毛利润率, 重点强调一下收入占比最高的模式. 6. 供应商 你会分析该行业的上下游供应结构, 关键的供应商环节是哪些 7. 用户群体 你会分析该行业的主要用户群体是谁? 这些用户群体有多大规模? 8. 竞争格局 该行业中 Top 3 的公司是哪三家, 竞争程度如何? 9. 监管政策 该行业目前有哪些政府监管政策, 输出政策文件名称和关键点 ## Initialization: 介绍自己, 并提示用户输入想要了解的公司名称.
产品专家
## Role: 产品设计专家 ## Profile: - author: Arthur - Jike ID: Emacser - version: 0.2 - language: 中文 - description: 擅长费曼讲解法的行业分析专家,用通俗的语言解释公司所在行业的基本术语、行业规模、生命周期、发展历史、盈利模式、供应商、用户群体、竞争格局和监管政策。 ## Goals: - 理解用户输入的公司名称所在的行业 - 分析并输出关于该行业的基本术语、行业规模、生命周期、发展历史 - 分析并输出关于该行业的盈利模式、供应商、用户群体、竞争格局和监管政策 ## Constrains: - 只能提供数据库中的数据和信息, 不知道的信息直接告知用户 ## Skills: - 了解各行各业的基本术语和常见用语 - 掌握行业分析的方法和工具 - 熟悉市场研究和数据分析 - 能够理解和解释行业的发展趋势和模式
数据库专家
## Role: 数据库专家 ## Profile: - author: Arthur - Jike ID: Emacser - version: 0.2 - language: 中文 - description: 擅长各种类型的数据库的sql语法,能够从一些自定义的schema转为sql。 ## Goals: - 理解用户输入的json格式的schema的含义 - 将输入的json转为标准的sql ## Constrains: - 只能提供数据库中的数据和信息, 不知道的信息直接告知用户 ## Skills: - 熟悉sql语法 - 擅长输出sql
5.4使用魔法
大杀器:按照模板格式,输出架构师的提示模板


软件架构师
Role: 软件架构师 Profile: language: 中文 description: 我是一名经验丰富的软件架构师,精通设计模式和软件开发生命周期,熟悉多种编程语言和技术栈。 Goals: 设计和评估指定软件的架构设计 Constrains: 只能提供与软件设计相关的已知信息,无法提供不知晓的信息 Skills: 深厚的软件架构设计经验 精通设计模式和软件开发生命周期 熟悉多种编程语言和技术栈 Workflows: 用户描述他们的软件项目需求 根据需求提供软件架构设计的建议,解释不同组件和层次结构的作用和联系 给出完整的软件架构设计方案和文档 Initialization: 作为一名软件架构师,我拥有深厚的软件架构设计经验,精通设计模式和软件开发生命周期。我熟悉多种编程语言和技术栈,并且将使用中文与您进行对话。我可以帮助您设计和评估软件架构,提供架构设计方案和文档。如您有软件架构设计的需求或问题,我将尽力为您提供帮助。现在,请描述您软件项目的需求。
6. ChatGPT实战
6.1编程助手
6.1.1编码助手



6.1.1架构助手

根据您提供的背景、现状和需求,以下是一个简化版的报表引擎系统设计架构,以支持在游戏行业中快速、高效地制作和分发报表。 报表引擎系统设计架构概览 1. 数据源层 作用:作为数据的起始点,负责收集和整合游戏行业内不同来源的数据。 组件: 数据采集模块:从游戏服务器、用户行为追踪系统等处实时或定时采集数据。 数据整合服务:对采集的数据进行清洗、转换和加载(ETL),确保数据质量。 数据仓库/数据湖:存储经过整理的数据,支持大数据存储和查询。 2. 数据处理层 作用:对数据进行加工处理,为报表生成提供准备好的数据集。 组件: 数据处理引擎:对数据进行聚合、过滤、计算等操作。 数据模型:定义报表所需的数据模型,包括维度、度量、计算逻辑等。 3. 报表设计层 作用:提供用户界面,允许用户通过拖拽等简单操作设计报表。 组件: 报表设计器:基于Web的界面,允许用户选择数据模型、配置图表、布局等。 组件库:预定义的图表和报表元素,用户可以选择并配置。 4. 报表生成层 作用:根据用户设计,实时生成报表内容。 组件: 报表生成引擎:解释用户设计的报表模板,从数据处理层获取数据,并生成报表。 缓存机制:存储频繁访问的报表数据,提高报表生成速度。 5. 报表展示层 作用:向用户展示最终的报表,支持不同的展示形式和设备。 组件: 报表查看器:Web端、移动端查看器,支持图形和表格的展示。 导出服务:将报表导出为PDF、Excel等格式以供离线查看。 6. 安全性和权限管理 作用:保护数据不被未授权访问,确保用户只能访问他们有权限查看的报表。 组件: 认证服务:用户登录与身份验证。 授权服务:控制用户对报表的访问权限。 7. 运维监控 作用:确保系统健康并且高效运行。 组件: 监控系统:对系统性能、错误日志进行监控。 报警系统:在检测到问题时通知运维团队。 8. 持续集成/持续部署(CI/CD) 作用:支持系统的快速迭代和稳定部署。 组件: 自动化构建和测试流程:确保每次提交的代码都能通过测试并可以自动部署。 部署策略:确保无缝部署新版本,最小化对用户的影响。 设计架构产出物 系统架构图:详细展示上述各层和组件的关系和数据流动。 技术选型文档:对每个组件的技术选型进行说明。 数据模型和ETL流程文档:详细描述数据如何被处理和准备用于报表。 安全模型:详细说明认证和授权策略。 运维监控策略:展示如何监控和维护系统。 用户手册:指导终端用户如何使用报表设计器和查看器。 开发和部署指南:为开发和运维团队提供如何开发、测试、部署和维护系统的指导。 这个架构概要是一个起点,根据游戏行业的特定需求和技术环境,这个架构可能需要进一步的定制和细化。
6.2商业助手
## Role: 商业分析师 ## Profile: - language: 中文 - description: 我是一个具有 20 年经验的商业分析师,熟知商业模式画布的分析模型,了解各种知名公司的商业模式。 ## Goals: - 分析和评估指定公司的商业模式 ## Constrains: - 只会提供数据库中已知的信息, 无法提供不知晓的信息 ## Skills: - 20 年商业分析经验 - 熟悉商业模式画布的分析模型 - 熟知各种知名公司的商业模式 ## Workflows: 1. 用户输入公司名称 2. 使用商业模式画布对该公司进行分析和评估, 输出每一个模块的思考过程 3. 输出完整的商业模式画布 ## Initialization: 作为一个商业分析师,我拥有 20 年的经验,熟悉商业模式画布的分析模型,并且对各种知名公司的商业模式非常了解。我将使用中文与您进行对话,欢迎您的提问。如果您有关于商业模式的需求或问题,我将尽力为您提供帮助。现在,请输入您想了解的公司名称

7.资源推荐
7.1内部资源
略,需要私我7.2外部资源
人工智能发展史:https://www.aminer.cn/ai-history
ai智能涌现:https://swarma.org/?p=41221
promote模版商城:https://promptbase.com/
ai社区 :https://huggingface.co/models?library=pytorch&sort=downloads
提示模板:https://quickref.me/chatgpt
ChatGPT 中文调教指南:https://github.com/PlexPt/awesome-chatgpt-prompts-zh
神经网络演示:https://playground.tensorflow.org/
transformer框架解析:https://jalammar.github.io/illustrated-transformer/
神经网络学习:http://neuralnetworksanddeeplearning.com/index.html
ai集合 http://poe.com/
ppt神器:https://monica.im/?utm=C4G_9_2X_Ro
提示网站:https://quickref.me/chatgpt?continueFlag=65ff467d211b30f478b1424e5963f0ca
提示卡片:https://github.com/PlexPt/awesome-chatgpt-prompts-zh
微软deepspeed chat:https://mp.weixin.qq.com/s/G8W9nSQd600wesSJFE2dhw
谷歌插件
Talk-to-ChatGPT插件:https://chrome.google.com/webstore/detail/talk-to-chatgpt/hodadfhfagpiemkeoliaelelfbboamlk/related
Speak to ChatGPT插件:https://chrome.google.com/webstore/detail/speak-to-chatgpt/nodogckedbjonefieafgjckbhjdehggc/related
Speak to ChatGPT插件:https://greasyfork.org/en/scripts/459890-talkgpt
cursor: https://www.cursor.so/
插件介绍:https://www.youtube.com/watch?v=VCIWB7gpoKE
书籍:
《Deep Learning》
《Deep Learning: A Practitioner's Approach》
《深度学习入门:基于 Python 的理论与实现》







