


📝个人主页:哈__
期待您的关注

目录
一、HashMap中的变量
1.默认容量
2.最大容量
3.负载因子
4.列表树化的阈值
5.红黑树转列表的阈值
6.树化时的最小数组容量
7.元素数组(存放我们插入的数据)
8.数组的大小(并非容量,而是实际放了多少个数据结点到table数组中)
9.Node结点
10.扩容阈值
二、HashMap的put方法
三、resize方法
在Java中,HashMap结构是被经常使用的,在面试当中也是经常会被问到的。这篇文章我给大家分享一下我对于HashMap结构源码的理解。
HashMap的存储与一般的数组不同,HashMap的每一个元素存储的并不是一个值,而是一个引用类型的Node结点,这也就意味着这个Node结点有被扩充的可能,因为这个Node结点可以是一个链表的Head结点,也可以是一棵树的根节点。
HashMap的存储数组叫做table,也可以称作“桶”,试想这样的一个场景:我们在一排放了3个桶,同时我们有4个苹果,如果我们要把所有的苹果放到桶当中,那么必然有一个桶中 的苹果个数>=2。
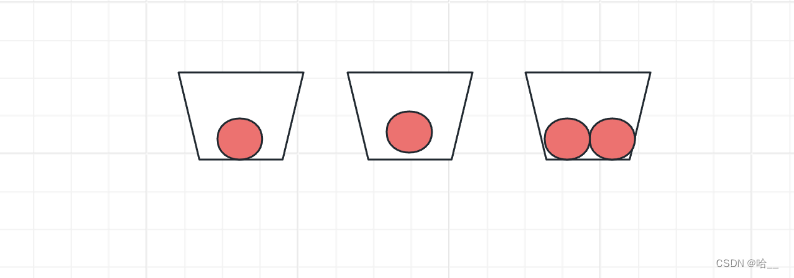
这种情况在我们的HashMap中也会出现,我们的HashMap结构是把很多的数据存放到一个容量达不到元素个数的数组当中,就如同桶和苹果一样。
因此我们的HashMap结果会出现上图所示的一种冲突,我们成为散列冲突,也叫做Hash冲突 。
出现冲突不要怕,解决冲突就是了,我们的一个桶当中可以放两个苹果,自然HashMap的table数组的一个位置也可以存放两个元素。
问题来了,我们现在假设有16个桶,同时间断性的向桶中放苹果,而且还要能够方便我们后续去拿苹果和寻找苹果,那我们这16个桶还够用吗?我们这样子直接把苹果放进桶里,还能够方便我们后续找苹果吗?
行了,解决吧,现在假设你是一位苹果管理员,你该怎么优化一下?你看看这样子行不行,不就是放苹果、找苹果嘛,既然让我来管理,那我希望把苹果平均放到桶当中,每次我放的位置尽量不要和之前的苹果放的位置有冲突,如果桶多的话,你也不能一个一个桶去看吧,所以,我们定义了一个算法,我根据这个苹果的生产ID序列号去寻找对应的桶放进去,如同取余放置一样。这是个不错的思路。但序列号都是有规律的,这样会影响我们的放置,我们希望是一个很随机的结果,因此我们给这个序列号随机变动几个位置后在选择桶。在HashMap中,这样的序列号叫做hashCode值,经过一个扰动函数后,我们的到的扰动的值叫做hash。
如何存放的问题解决了,但苹果一旦多了还是会产生冲突,一个桶里放8个我还能找得到,但是一个桶里放20个,30个苹果,那我就找不到那个序列号的苹果了。
二叉树我们都学过,倘若我们把桶内的苹果以二叉树的方式进行存储,那这样我们在查找的时候是不是就省了很多时间呢?因此HashMap中的table内的一个元素列表长度>8的时候,进行树化操作。但也不是非要进行树化的,毕竟树化也要浪费很多资源。当我们的桶的数量>> 16); }
h.hashCode = 1101 0111 1011 1100 0101 1011 1011 1010
h.hashCode >>>16 = 0000 0000 0000 0000 1101 0111 1011 1100
我们取这两个值的与结果,这样我们的hashcode的高位也能扰动我们放的位置。并非单纯的低位和n-1去进行与运算了。
三、resize方法
在上边的代码中有个resize方法的调用,这个方法主要的目的是扩容table。这个resize方法看起来还是非常的恐怖哈。
resize方法解释了为什么数组的容量一定是二的整数倍。
final Node[] resize() {
//记录一下之前的table
Node[] oldTab = table;
//算一下之前table的容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//记录一下之前table的扩容阈值
int oldThr = threshold;
//把新的容量和扩容阈值定义出来
int newCap, newThr = 0;
//如果已经进行过初始化了
if (oldCap > 0) {
//如果我们之前的空间大小已经达到了最大容量 -- 很少出现
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//否则的话 我们新的容量等于旧的容量*2 位移运算
else if ((newCap = oldCap = DEFAULT_INITIAL_CAPACITY)
//新的扩容阈值也*2
newThr = oldThr 0) // initial capacity was placed in threshold
newCap = oldThr;
// 这个else重要啊,如果我们没有进行过初始化,那我们就把新容量定位16 新的扩容阈值定为12
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果新的扩容阈值等于0 我们要进行处理等于新的容量×负载因子
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap
我们分析一下下边的代码。写了注释的直接看看就好,关于树的我不说了,只说链表。
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
//如果我们之前的table不为空的话我们要进行一下元素迁移
if (oldTab != null) {
for (int j = 0; j
什么是高链表和低链表。在之前我们说到过元素是如何定位的,靠的是hash和数组容量-1的与操作。但如果我们数组容量不减1呢?因为我们的数组容量是2的整数倍,如果不减1,那么就说明只有一个位置为1,其他的全为0(假设容量是16)。
h.hashCode = 1101 0111 1011 1100 0101 1011 1011 1010
n = 0000 0000 0000 0000 0000 0000 0001 0000
如同上方的例子,这个元素到底分到哪里,就看这个元素的hash值的倒数第五位,如果是1,就在高链表,如果是0就在低链表。我们通过这样的方式来把元素分到低链表或者高链表当中。
for循环的最后把我们这个临时的低链表和高链表放到我们新的table中。
最后将新的table返回。







