

文章目录
- 1.源码包下载、明确依赖版本
- 2.安装python依赖
- 3.运行demo
- 本博客源码仓库地址:gitlab,本篇博客对应01分支
- python版本为3.10.x
什么是PandasAI?一句话总结的话,PandasAI就是一个结合了Pandas和AI的开源工具,更详细地说,PandasAI 是一款强大的Python库,它使得用户能够以自然语言轻松向各类数据源(如CSV、XLSX、PostgreSQL、MySQL、BigQuery、Databricks及Snowflake等)提出问题。该库借助生成式人工智能技术,助力用户实现对数据的深度探索、清洗与分析工作。
不仅如此,PandasAI 还提供了丰富的可视化功能,可通过图表形式展示数据;同时,它能有效处理缺失值问题以净化数据集,并通过特征生成进一步提升数据质量。因此,无论是对于数据科学家还是数据分析师而言,PandasAI 都是一款全方位的数据处理工具。
官方文档:https://docs.pandas-ai.com/en/latest/
github仓库:https://github.com/Sinaptik-AI/pandas-ai
-
特点:提升效率,节省开发人员的时间和精力
自然语言查询:以自然语言向数据提问。
数据可视化:生成图形和图表以可视化数据。
数据清理:通过解决缺失值来清理数据集。
特征生成:通过特征生成提高数据质量。
数据连接器:连接到各种数据源,如 CSV、XLSX、PostgreSQL、MySQL、BigQuery、Databrick、Snowflake 等。
-
工作原理简述:
PandasAI 使用生成式 AI 模型来理解和解释自然语言查询,并将其转换为 python 代码和 SQL 查询。然后,它使用代码与数据进行交互,并将结果返回给用户。
要想使用PandasAI,首先需要把demo跑起来,下面我将演示整个过程的详细步骤。
1.源码包下载、明确依赖版本
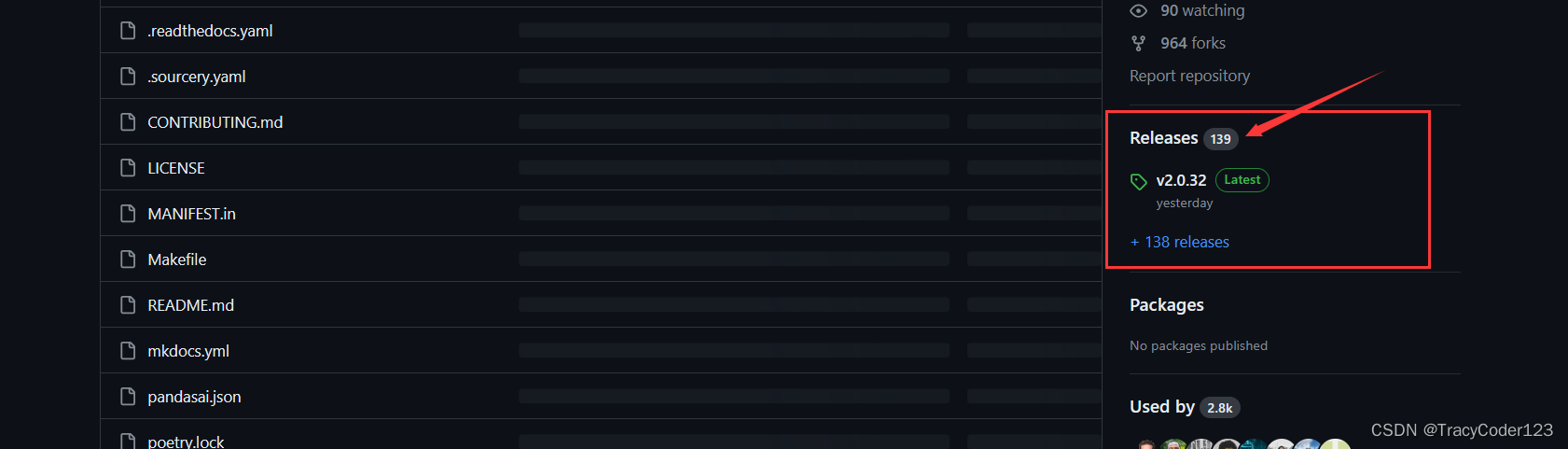
- 进入PandasAI的github仓库https://github.com/Sinaptik-AI/pandas-ai,点击页面上的Releases:
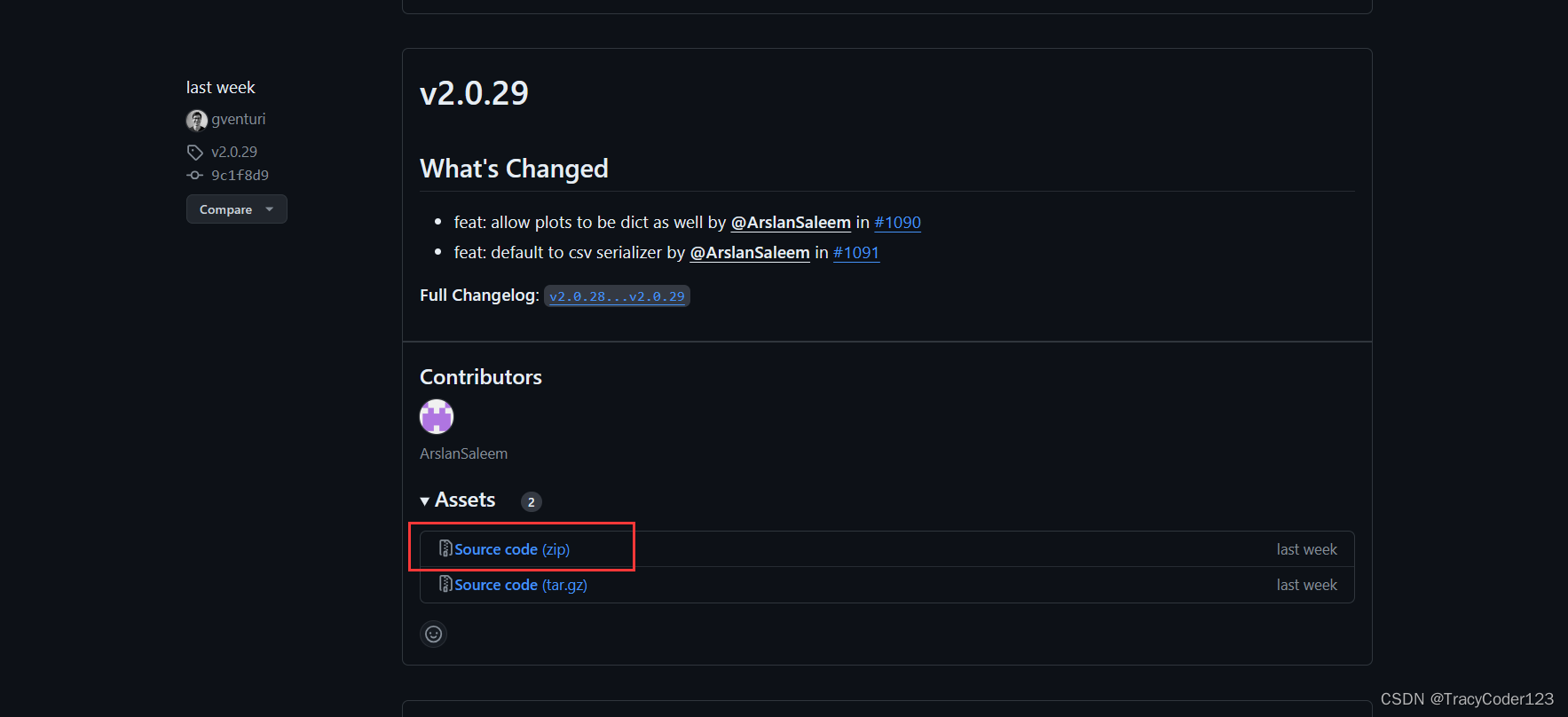
- 选择版本,我选择的是v2.0.29,下载source code.zip:
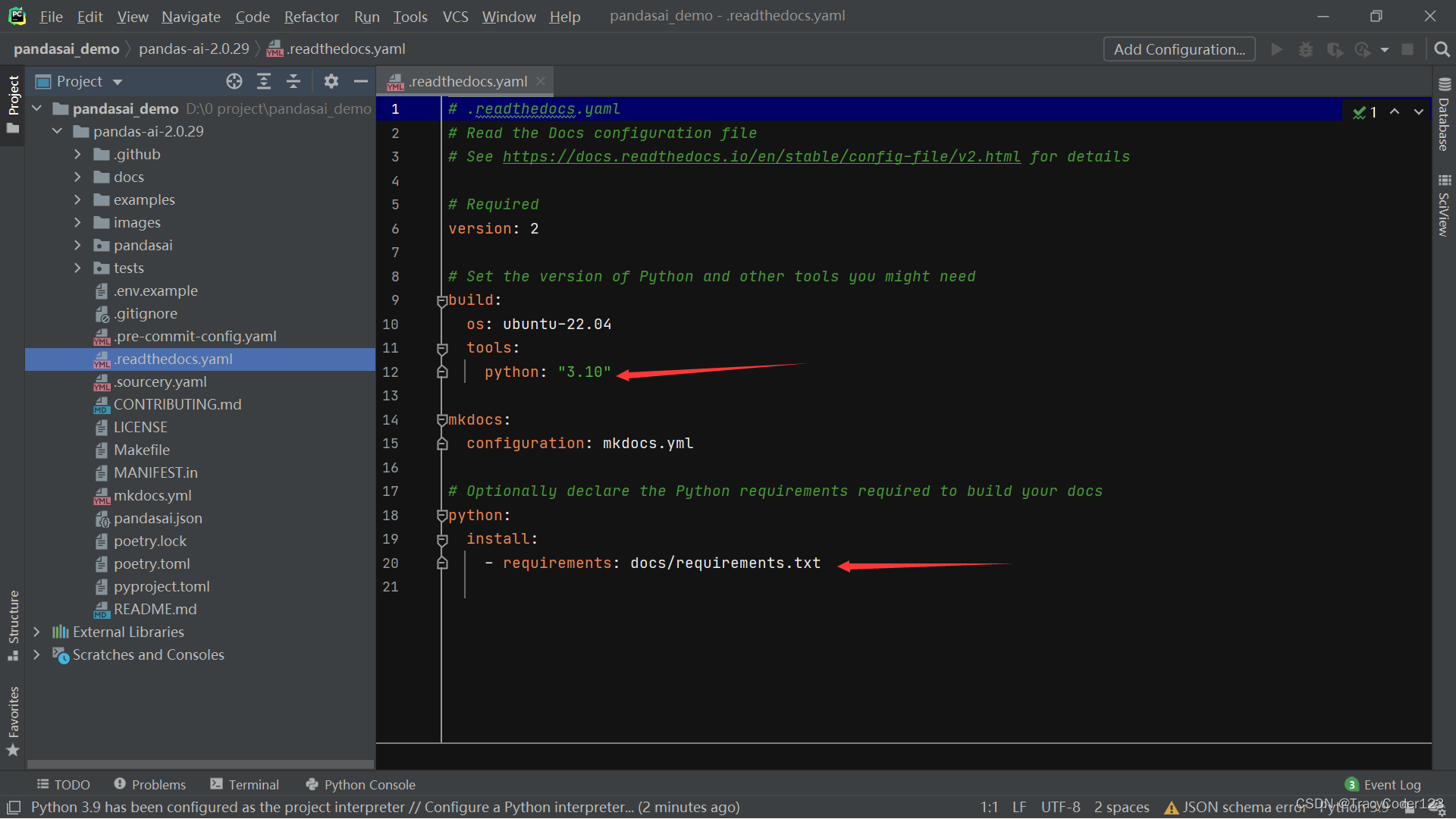
- 然后,我将下载的源码包放到了我的项目文件夹根目录下并解压了,查看pandas-ai-2.0.29文件夹下的.readthedocs.yaml文件,里面有关于python版本和依赖安装文件的说明:python版本为3.10,requirements文件为pandas-ai-2.0.29/docs/requirements.txt
2.安装python依赖
- 为了更便于管理环境,我创建了一个conda虚拟环境:
conda create -n pandasai python=3.10
- 然后进入环境:
conda activate pandasai
- 在项目根目录下安装requirement文件依赖:
pip install -r ./pandas-ai-2.0.29/docs/requirements.txt
- 另外还需要安装pandasai这个依赖:
pip install pandasai==2.0.29
到这里环境就安装好了。
3.运行demo
官网提供的demo有bug(使用BambooLLM大语言模型会报错,但是使用OpenAI不会),已经有其他人遇到了和我一样的问题,并给该开源作者提了issue,但是目前这个bug还没有修复,因此需要修改一下demo的代码。
- 首先我生成了一个包含23条数据的csv数据集(dataset.csv,存放在了pandas-ai-2.0.29/examples/data目录中),用于测试PandasAI是否可以成功地运行:
countries,gdp United States,10001 Canada,10002 Mexico,10003 Guatemala,10004 Belize,10005 El Salvador,10006 Honduras,10007 Panama,10008 Bahamas,10009 Cuba,10011 Jamaica,10012 Haiti,10013 Dominican Republic,10014 Costa Rica,10015 Saint Kitts and Nevis,10016 Antigua and Barbuda,10017 Dominica,10018 Saint Lucia,10019 Saint Vincent and the Grenadines,10021 Barbados,10022 Grenada,10023 Trinidad and Tobago,10024 Nicaragua,10025
- 然后,我修改了pandas-ai-2.0.29/examples目录下的from_csv.py的代码:
"""Example of using PandasAI with a pandas dataframe""" from pandasai import SmartDataframe from pandasai.llm import OpenAI from pandasai.helpers.openai_info import get_openai_callback llm = OpenAI(api_token="你的OpenAI Token") df = SmartDataframe("./data/data.csv", config={"llm": llm, "conversational": False}) with get_openai_callback() as cb: response = df.chat("Calculate the sum of the gdp of north american countries") print(response) print(cb)- 进入examples目录:
cd pandas-ai-2.0.29\examples
- 运行from_csv.py:
注意,调用OpenAI需要开代理,否则会报网络异常
python from_csv.py
执行成功:
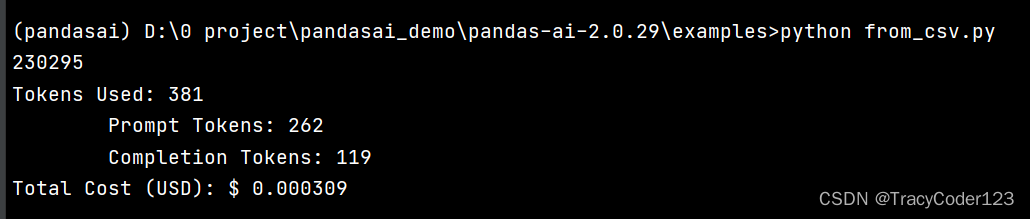
至此,PandasAI的demo就成功运行起来了。
- 运行from_csv.py:
- 进入examples目录:
- 然后,我修改了pandas-ai-2.0.29/examples目录下的from_csv.py的代码:
- 首先我生成了一个包含23条数据的csv数据集(dataset.csv,存放在了pandas-ai-2.0.29/examples/data目录中),用于测试PandasAI是否可以成功地运行:
- 另外还需要安装pandasai这个依赖:
- 在项目根目录下安装requirement文件依赖:
- 然后进入环境:
- 为了更便于管理环境,我创建了一个conda虚拟环境:
- 然后,我将下载的源码包放到了我的项目文件夹根目录下并解压了,查看pandas-ai-2.0.29文件夹下的.readthedocs.yaml文件,里面有关于python版本和依赖安装文件的说明:python版本为3.10,requirements文件为pandas-ai-2.0.29/docs/requirements.txt
- 选择版本,我选择的是v2.0.29,下载source code.zip:
- 进入PandasAI的github仓库https://github.com/Sinaptik-AI/pandas-ai,点击页面上的Releases:
-







