

未测量流域极端洪水的全球预测
- 灰色接近,
- 黛博拉·科恩,
- 乌苏穆兹·杜贝
- 马丁·高赫,
- 奥伦·吉隆,
-
指标细节
抽象的
洪水是最常见的自然灾害之一,对经常缺乏密集水流测量网络的发展中国家造成的影响尤为严重1。准确及时的预警对于减轻洪水风险至关重要2,但水文模拟模型通常必须根据每个流域的长数据记录进行校准。在这里,我们表明,基于人工智能的预测在预测未测量流域的极端河流事件方面实现了长达五天的可靠性,这与当前状态的临近预报(零日提前时间)的可靠性相似或更好最先进的全球建模系统(哥白尼应急管理服务全球洪水意识系统)。此外,我们在五年重现期事件中实现的精度与当前一年重现期事件的精度相似或更好。这意味着人工智能可以针对未测量流域中规模更大、影响力更大的事件更早地提供洪水预警。这里开发的模型被纳入一个可操作的早期预警系统中,该系统可在 80 多个国家实时生成公开可用(免费且开放)的预报。这项工作强调需要增加水文数据的可用性,以继续改善全球获得可靠洪水预警的机会。
其他人正在查看类似内容

利用气候和流域信息对欧洲洪水概率进行季节性预测
文章 开放获取2022 年 8 月 6 日
人工智能对气候影响:在洪水风险中的应用
文章 开放获取2023 年 6 月 8 日
从干旱灾害转向影响预测
文章 开放获取2019 年 10 月 30 日主要的
洪水是最常见的自然灾害3,自 2000 年以来,与洪水相关的灾害发生率增加了一倍多4。与洪水相关的灾害的增加是由人为气候变化引起的水文循环加速推动的5 , 6。预警系统是减轻洪水风险的有效方法,可将洪水相关死亡人数减少高达 43% 7 , 8,并将经济成本减少 35-50% 9 , 10。在易受洪水风险影响的 18 亿人口中,中低收入国家的人口几乎占 90% 1。世界银行估计,将发展中国家的洪水预警系统升级到发达国家的标准,平均每年可挽救 23,000 人的生命2。
在本文中,我们评估了在开放公共数据集上训练的人工智能(AI)在多大程度上可用于改善全球河流极端事件预报的获取。根据本文所述的模型和实验,我们开发了一个操作系统,可以对 80 多个国家/地区进行短期(7 天)洪水预报。这些预测是实时提供的,没有任何访问障碍,例如费用或网站注册 ( https://g.co/floodhub )。
河流预报的一个主要挑战是水文预测模型必须使用长数据记录11、12 来针对各个流域进行校准。缺乏流量计来提供校准数据的流域被称为未计量流域,而“未计量流域的预测”(PUB)问题是国际水文科学协会(IAHS)从2003年到2012年的十年问题13。在 PUB 十年结束时,IAHS 报告说,在解决这个问题方面几乎没有取得任何进展,并指出“迄今为止,大部分成功都是在计量盆地而不是未计量盆地中取得的,这尤其对发展中国家产生了负面影响” 14 .
世界上只有百分之几的流域进行了测量,而且流量计在世界各地的分布并不均匀。特定国家的国内生产总值与公开可用的水流观测数据记录总量之间存在很强的相关性(扩展数据图1显示了这种双对数相关性),这意味着在以下领域进行高质量预测尤其具有挑战性:最容易受到人类洪水影响。
在之前的工作15中,我们表明机器学习可用于开发可转移到未计量流域的水文模拟模型。在这里,我们将其开发为全球规模的预测系统,目标是了解可扩展性和可靠性。在本文中,我们讨论了鉴于公开的全球水流数据记录,是否有可能提供大范围内的准确河流预测,特别是极端事件的预测,以及这与当前技术水平的比较。
目前最先进的实时全球规模水文预测是全球洪水意识系统 (GloFAS) 16 , 17。 GloFAS 是哥白尼应急管理服务 (CEMS) 的全球洪水预报系统,由欧盟委员会联合研究中心负责交付,并由欧洲中期天气预报中心 (ECMWF) 作为 CEMS 水文预报中心运营– 计算。我们使用 GloFAS 版本 4,这是 2023 年 7 月上线的当前运行版本。世界不同地区还存在其他预报系统18 , 19 , 20,许多国家都有负责产生预警的国家机构。鉴于洪水对世界各地社区影响的严重性,我们认为预测机构对其预测、预警和方法进行评估和基准测试至关重要,而实现这一目标的重要第一步是将历史预测存档。
人工智能提高预测可靠性
本研究开发的人工智能模型使用长短期记忆 (LSTM) 网络21来预测 7 天预测范围内的每日水流。该模型在方法中详细描述,并且适合研究的模型版本在开源 NeuralHydrology 存储库22中实现。输入、目标和评估数据在方法中描述。
该 AI 预测模型使用5,680 个流量计的随机k倍交叉验证进行了样本外训练和测试。方法中报告了其他类型的交叉验证实验(即,保留终端流域、整个气候区或整个大陆的所有仪表)。此外,AI 模型报告的所有指标都是使用训练中未出现的时间段的流量计数据计算的(除了训练中未出现的流量计之外),这意味着交叉验证分割在样本外时间和地点。相比之下,GloFAS 的指标是通过测量和未测量位置的组合以及校准和验证时间段的组合来计算的。这意味着比较有利于 GloFAS 基准。这是必要的,因为校准 GloFAS 的计算成本很高,以至于在交叉验证分割上重新校准是不可行的。
我们的目标是了解极端事件预测的可靠性,因此我们报告不同重现期事件的精确度、召回率和 F1 分数(F1 分数是精确度和召回率的调和平均值)。其他标准水文指标在方法中报告。统计检验在方法中描述。
图1显示了 1984 年至 2021 年期间 0 天提前期的 2 年重现期事件的 F1 分数差异的全球分布(N = 3,360)。前置时间表示为从预测时间算起的天数,因此 0 天前置时间意味着流量预测是针对当天的(临近预报)。 AI 模型在重现期事件的 64% (65%)、70% (73%)、60% (73%) 和 49% (76%) 指标上比 GloFAS 版本 4 有所改进(至少相当于) 1 年(N = 3,638,P = 6 × 10 −87,科恩d = 0.22),2 年(N = 3,673,P d = 0.41),5 年(N = 3,360,P = 8 × 10 −130 , d = 0.42) 和 10 年 ( N = 2,920, P d = 0.33)。
图 1:1984 年至 2021 年期间,我们的 AI 模型和 GloFAS 之间的 2 年重现期事件的临近预报(0 天提前期)F1 分数之间的差异。
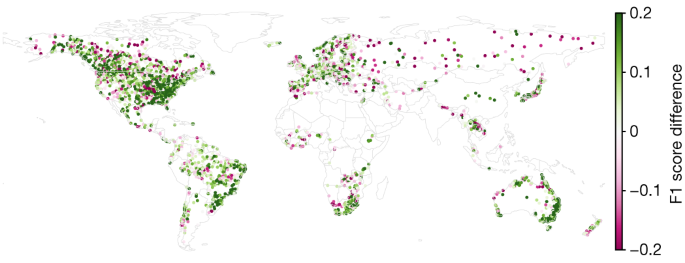
AI 模型在 70% 的仪表中比 GloFAS 有所改进 ( N = 3,673)。 GloFAS 模拟数据来自气候数据存储33。来自 GeoPandas 34的底图。
全尺寸图像退货期
更极端的水文事件(即重现期较长的事件)既更重要,而且(使用经典水文模型时)通常更难以预测。关于使用人工智能或其他类型的数据驱动方法的一个常见担忧23,24,25,26是可靠性可能会因训练数据中罕见的事件而降低。先前的证据表明,这种担忧对于水流建模可能无效27。
图2显示了不同重现期事件的精确率和召回率的分布。 AI 模型在所有重现期(N > 3,000,P d = 0.15(1 年精确度分数)到d = 0.46(2 年精确度分数)回忆分数)。在α = 1%(N = 3,465,P = 0.02,d = -0.01)和召回率时,AI 模型在 5 年重现期事件中的精确度分数与 GloFAS 在 1 年重现期事件中的精确度分数之间的差异并不显着。 5 年事件的 AI 模型得分优于 1 年事件的 GloFAS 回忆得分(N = 3,586,P = 1 × 10 −18,d = 0.20)。
图 2:临近预报(0 天提前期)精度和召回率随返回周期的变化的分布。
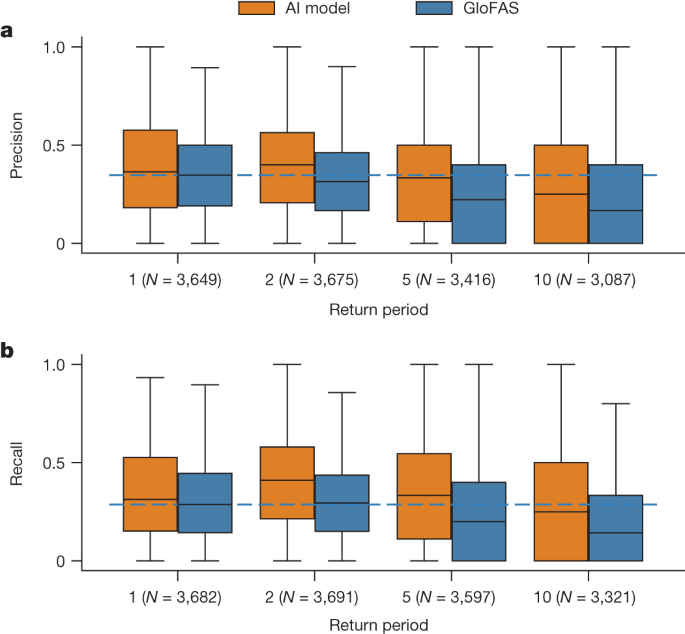
a , b,平均而言,AI 模型在所有回报期都更可靠。 AI 模型对 5 年重现期事件的精度与 1 年重现期事件的 GloFAS 没有统计差异,而且回想起来,它比 1 年重现期事件的 GloFAS 更好。统计测试在正文中报告。方框显示分布四分位数,须线显示排除异常值的全部范围。蓝色虚线是 1 年事件中 GloFAS 得分的中位数,绘制作为参考。刻度标签指示每个箱线图的样本大小(仪表数量);精确度得分 ( a ) 和召回率得分 ( b ) 是在稍微不同的仪表组上计算的,如果观测或模型预测中给定仪表位置处没有给定幅度的事件,导致一个模型的一个分数未定义。在所有情况下,GloFAS 和 AI 模型始终通过一组相同的仪表进行比较。 GloFAS 模拟数据来自气候数据存储33。
全尺寸图像预测提前期
图3显示了 1 年至 10 年回报期的 7 天预测范围内交付周期的 F1 分数。与 GloFAS 即时预报(0 天提前期)相比,AI 预测在 1 年的 5 天提前期内具有更好或没有统计差异的可靠性(F1 分数)(AI 明显更好;N = 2,415,P = 6 × 10 −6,d = 0.08),2 年(无统计学差异;N = 2,162,P = 0.98,d = 2 × 10 −4)和 5 年(无统计学差异;N = 1,298,P = 0.69, d = 0.025) 返回周期事件。
图 3:所有评估指标上 F1 分数的分布,作为不同回报期提前期的函数。
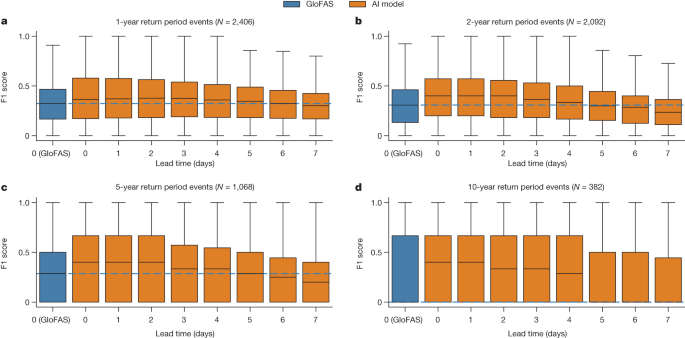
a – d,AI 模型在 1 年 ( a )、2 年 ( b )、5 年 ( c ) 和 10 年 ( d ) 回报期事件中的 F1 分数长达 5 天,在 0 天提前期的相同事件中,其在统计上优于 GloFAS,或没有统计差异。统计测试在正文中报告。方框显示分布四分位数,须线显示排除异常值的全部范围。蓝色虚线是 GloFAS 即时预报的中值分数,绘制为参考。 GloFAS 模拟数据来自气候数据存储33。
全尺寸图像大陆
这两种模型在世界不同地区的可靠性方面存在差异。在 5 年重现期事件中,GloFAS 在得分最低的大陆(南美洲,F1 = 0.15)和得分最高的大陆(欧洲,F1 = 0.32)的平均 F1 得分之间存在 54% 的差异,这意味着,平均而言,真阳性预测的可能性是其两倍(按比例)。 AI 模型在得分最低的大陆(南美洲,F1 = 0.21)和得分最高的大陆(西南太平洋:F1 = 0.46)的平均 F1 得分之间也存在 54% 的差异,这主要是由于大幅增长西南太平洋地区相对于 GloFAS 的技能水平 ( d = 0.68)。
图4显示了 F1 分数在各大洲和重现期的分布。 AI 模型在所有大陆和重现期中都具有较高得分 ( P
-







