


目录
一、torchvision:计算机视觉工具包
二、transforms的运行机制
(1)torchvision.transforms:常用的图像预处理方法
(2)transforms运行原理
三、数据标准化
transforms.Normalize()
四、数据增强
4.1 transforms—数据裁剪
(1)transforms.CentorCrop
(2)transforms.RandomCrop
(3)RandomResizedCrop
(4)FiveCrop &(5)TenCrop
4.2 transforms——翻转和旋转
(1)RandomHorizontalFlip & (2)RandomVerticalFlip
(3)RandomRotation()
4.3 transforms—图像变换
(1)pad
(2)ColorJitter
(3)Greyscale
(4)RandomGreyscale
(5)RandomAffine
(6)RandomErasing
(7)transforms.lambda
4.4 transforms——transforms方法选择操作
(1)transforms.RandomChoice
(2)transforms.RandomApply
(3)transforms.RandomOrder
4.5 自定义transforms方法
五、总结:二十二种transforms操作
一、裁剪
二、翻转和旋转
三、图像变换
四、transforms的操作
前情回顾:
Pytorch学习笔记(1):基本概念、安装、张量操作、逻辑回归
Pytorch学习笔记(2):数据读取机制(DataLoader与Dataset)
一、torchvision:计算机视觉工具包
• torchvision.transforms : 常用的图像预处理方法
• torchvision.datasets : 常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等
• torchvision.model : 常用的模型预训练,AlexNet,VGG, ResNet,GoogLeNet等
二、transforms的运行机制
(1)torchvision.transforms:常用的图像预处理方法
数据预处理方法:数据中心化;数据标准化;缩放;裁剪;旋转;填充;噪声添加;灰度变换;线性变换;仿射变换;亮度、饱和度及对比度变换等
compose将一系列transforms方法进行有序组合包装,依次按顺序的对图像进行操作
具体代码段如下:
导入:import torchvision.transforms as transforms
#训练集数据预处理
train_transform = transforms.Compose([
transforms.Resize((32, 32)), #缩放
transforms.RandomCrop(32, padding=4), #随机裁剪
transforms.ToTensor(), #转为tensor,同时进行归一化操作,将像素值的区间从0-255变为0-1
transforms.Normalize(norm_mean, norm_std), #数据标准化,均值变为0,标准差变为1
])
#验证集数据预处理
valid_transform = transforms.Compose([ #测试时不需要数据增强
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
• transforms.Compose: 将一系列的transforms方法进行有序的组合包装,依次按顺序的对图像进行操作
• transforms.Resize: 改变图像大小
• transforms.RandomCrop: 对图像进行裁剪(这个在训练集里面用,验证集就用不到了)
• transforms.ToTensor: 将图像转换成张量,同时会进行归一化的一个操作,将张量的值从0-255转到0-1
• transforms.Normalize: 将数据进行标准化
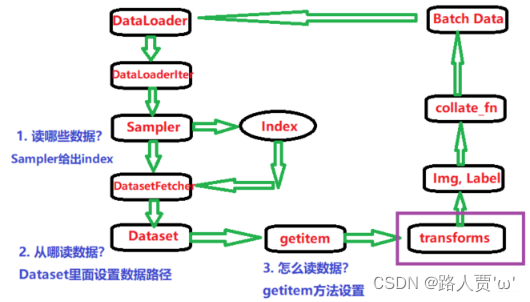
(2)transforms运行原理
把这两个transforms操作作为参数传给Dataset,在Dataset的__getitem__()方法中做图像增强。
具体代码段如下:
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
进入transforms,跳转到transforms的call函数
依次有序的从compose中调用数据处理方法
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
逻辑关系可以用下图表示:
三、数据标准化
transforms.Normalize()
功能:逐channel的对图像进行标准化。output = (input - mean)/ std

• mean:各通道的均值
• std:各通道的标准差
• inplace:是否原地操作
具体代码段如下:
此处直接调用的torch中的normalize函数
class Normalize(torch.nn.Module):
def __init__(self, mean, std, inplace=False):
super().__init__()
self.mean = mean
self.std = std
self.inplace = inplace
def forward(self, tensor: Tensor) -> Tensor:
"""
Args:
tensor (Tensor): Tensor image to be normalized.
Returns:
Tensor: Normalized Tensor image.
"""
return F.normalize(tensor, self.mean, self.std, self.inplace)
def __repr__(self):
return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)
进入torch的normalize函数
def normalize(tensor: Tensor, mean: List[float], std: List[float], inplace: bool = False) -> Tensor:
#判断是否是tensor
if not isinstance(tensor, torch.Tensor):
raise TypeError('Input tensor should be a torch tensor. Got {}.'.format(type(tensor)))
if tensor.ndim
四、数据增强
数据增强又称为数据增广, 数据扩增,是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力, 下面是一个数据增强的小例子。

4.1 transforms—数据裁剪
(1)transforms.CentorCrop
功能:从图像中心裁剪图片
torchvision.transforms.CenterCrop(size)
• size:所需裁剪图片尺寸
(2)transforms.RandomCrop
功能:从图片中随机裁剪出尺寸为size的图片

• size:所需裁剪图片尺寸
• padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d
• pad_if_need:若图像小于设定size,则填充
• padding_mode:填充模式,有4种模式
- constant:像素值由fill设定
- edge:像素值由图像边缘像素决定
- reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
- symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
• fill:constant时,设置填充的像素值
具体代码段如下:
# 测试RandomCrop随机裁剪
trans_random = transforms.RandomCrop(300)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10): # 0裁剪10次
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
(3)RandomResizedCrop
功能:随机大小、长宽比裁剪图片

• size:所需裁剪图片尺寸
• scale:随机裁剪面积比例,默认(0.08,1) (在0.08-1之间选择一个比例进行裁剪)
• ratio:随机长宽比,默认(3/4,4/3)
• interpolation:插值方法 (由于裁剪之后的图片可能会小于size,故进行插值操作)
- PIL.Image.NEAREST
- PIL.Image.BILINEAR
- PIL.Image.BICUBIC
(4)FiveCrop &(5)TenCrop
功能:在图像的上下左右及中心裁剪出尺寸为size的5张图片,TenCrop还在这5张图片的基础上再水平或者垂直镜像得到10张图片

• size:所需裁剪图片尺寸
• vertical_flip:是否垂直翻转
4.2 transforms——翻转和旋转
(1)RandomHorizontalFlip & (2)RandomVerticalFlip

功能:依概率水平(左右)或垂直(上下)翻转图片
- p:翻转概率
(3)RandomRotation()
功能:随机旋转图片

• degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a, b)时,在(a, b)之间选择旋转角度
• resample:重采样方法
• expand:是否扩大图片,以保持原图信息
• center:旋转点设置,默认中心旋转完整代码:
# -*- coding: utf-8 -*- import os BASE_DIR = os.path.dirname(os.path.abspath(__file__)) import numpy as np import torch import random from torch.utils.data import DataLoader import torchvision.transforms as transforms from PIL import Image from matplotlib import pyplot as plt path_lenet = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "model", "lenet.py")) path_tools = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "tools", "common_tools.py")) assert os.path.exists(path_lenet), "{}不存在,请将lenet.py文件放到 {}".format(path_lenet, os.path.dirname(path_lenet)) assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools)) import sys hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..") sys.path.append(hello_pytorch_DIR) from tools.my_dataset import RMBDataset from tools.common_tools import set_seed, transform_invert set_seed(1) # 设置随机种子 # 参数设置 MAX_EPOCH = 10 BATCH_SIZE = 1 LR = 0.01 log_interval = 10 val_interval = 1 rmb_label = {"1": 0, "100": 1} # ============================ step 1/5 数据 ============================ split_dir = os.path.abspath(os.path.join("..", "..", "data", "RMB_data", "rmb_split")) if not os.path.exists(split_dir): raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir)) train_dir = os.path.join(split_dir, "train") valid_dir = os.path.join(split_dir, "valid") norm_mean = [0.485, 0.456, 0.406] norm_std = [0.229, 0.224, 0.225] train_transform = transforms.Compose([ transforms.Resize((224, 224)), #统一图片尺寸 # 1 CenterCrop # transforms.CenterCrop(196), # 512 # 2 RandomCrop # transforms.RandomCrop(224, padding=16), # transforms.RandomCrop(224, padding=(16, 64)), # transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)), # transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True # transforms.RandomCrop(224, padding=64, padding_mode='edge'), # transforms.RandomCrop(224, padding=64, padding_mode='reflect'), # transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'), # 3 RandomResizedCrop # transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)), # 4 FiveCrop # transforms.FiveCrop(112), # transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])), # 5 TenCrop # transforms.TenCrop(112, vertical_flip=False), # transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])), # 1 Horizontal Flip # transforms.RandomHorizontalFlip(p=1), # 2 Vertical Flip # transforms.RandomVerticalFlip(p=0.5), # 3 RandomRotation # transforms.RandomRotation(90), # transforms.RandomRotation((90), expand=True), # transforms.RandomRotation(30, center=(0, 0)), # transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std), ]) valid_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(norm_mean, norm_std) ]) # 构建MyDataset实例 train_data = RMBDataset(data_dir=train_dir, transform=train_transform) valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform) # 构建DataLoder train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE) # ============================ step 5/5 训练 ============================ for epoch in range(MAX_EPOCH): for i, data in enumerate(train_loader): inputs, labels = data # B C H W img_tensor = inputs[0, ...] # C H W #invert函数对transforms进行逆操作,可以将浮点数据转为img,便于观察 img = transform_invert(img_tensor, train_transform) plt.imshow(img) plt.show() plt.pause(0.5) plt.close() # FiveCrop 和 TenCrop的可视化操作,因为输出为5维 # bs, ncrops, c, h, w = inputs.shape # for n in range(ncrops): # img_tensor = inputs[0, n, ...] # C H W # img = transform_invert(img_tensor, train_transform) # plt.imshow(img) # plt.show() # plt.pause(1)4.3 transforms—图像变换
(1)pad
功能:对图片边缘进行填充

• padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a,b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a,b,c,d
• padding_mode:填充模式,有四种模式,constant、edge、reflect和symmetric(具体请见三.2.(2)节)
• fill:constant时, 设置填充的像素值,(R,G,B)or(Gray)padding_mode优先级高于fill
(2)ColorJitter
功能:调整亮度、对比度、饱和度和色相, 这个是比较实用的方法。

• brightness:亮度调整因子
- 当为a时,从[max(0,1-a),1+a]中随机选择
- 当为(a,b)时,从[a,b]中选择
• contrast:对比度参数,同brightness
• saturation:饱和度参数,同brightness
• hue:色相参数- 当为a时,从[-a,a]中选择参数,注:0







