

AI学习指南数学工具篇-梯度下降算法之小批量梯度下降(Mini-batch Gradient Descent)
在机器学习和深度学习领域,梯度下降算法是一种常用的优化方法,可以用于最小化损失函数以更新模型参数。在梯度下降算法中,小批量梯度下降(Mini-batch Gradient Descent)是一种介于批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)之间的优化算法。本文将详细介绍小批量梯度下降算法的原理、优点和应用,并通过详细的示例帮助读者理解该算法的实际运用。
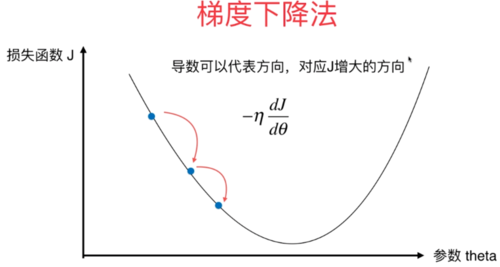
1. 小批量梯度下降算法的原理
小批量梯度下降算法是一种通过迭代更新模型参数来最小化损失函数的优化算法。与批量梯度下降算法不同的是,小批量梯度下降算法每次迭代时并不使用全部训练样本进行参数更新,而是随机选择一小部分样本(通常为 32 或 64 个样本)进行更新。这样可以在一定程度上保留了批量梯度下降算法的稳定性,同时又减少了每次迭代的计算成本。
具体来说,小批量梯度下降算法的参数更新规则如下:
对于每个训练样本 ( x ( i ) , y ( i ) ) (\mathbf{x}^{(i)}, y^{(i)}) (x(i),y(i)) ,计算其对模型参数的梯度
∇ J ( θ ; x ( i ) , y ( i ) ) \nabla J(\theta; \mathbf{x}^{(i)}, y^{(i)}) ∇J(θ;x(i),y(i)) ;
从训练集中随机选择一小批量样本,计算它们的平均梯度
1 B ∑ i = 1 B ∇ J ( θ ; x ( i ) , y ( i ) ) \frac{1}{B} \sum_{i=1}^{B} \nabla J(\theta; \mathbf{x}^{(i)}, y^{(i)}) B1i=1∑B∇J(θ;x(i),y(i)) ;
使用平均梯度更新模型参数:
θ = θ − α 1 B ∑ i = 1 B ∇ J ( θ ; x ( i ) , y ( i ) ) \theta = \theta - \alpha \frac{1}{B} \sum_{i=1}^{B} \nabla J(\theta; \mathbf{x}^{(i)}, y^{(i)}) θ=θ−αB1i=1∑B∇J(θ;x(i),y(i)),其中 α \alpha α 是学习率;
重复上述步骤直到满足停止条件(如达到最大迭代次数或损失函数收敛)。
小批量梯度下降算法的原理比较简单,主要就是通过计算一小批量样本的平均梯度来更新模型参数。接下来我们将介绍小批量梯度下降算法的优点和应用。
2. 小批量梯度下降算法的优点
相对于批量梯度下降算法和随机梯度下降算法,小批量梯度下降算法具有以下优点:
节省内存:与批量梯度下降算法相比,小批量梯度下降算法每次只需加载一小部分样本到内存中,从而在处理大规模数据集时能够节省内存。
加速收敛:相对于随机梯度下降算法,小批量梯度下降算法每次使用一小批量样本进行参数更新,能够更稳定地收敛,并且可以通过并行计算加速训练过程。
更好的学习率调整:在实际应用中,小批量梯度下降算法通常能够更有效地利用学习率调整方法,从而更有效地优化模型参数。
因此,小批量梯度下降算法在实际应用中具有较大的优势,能够更快地收敛和更有效地优化模型参数。接下来我们将介绍小批量梯度下降算法在深度学习领域的应用。
3. 小批量梯度下降算法的应用
小批量梯度下降算法在深度学习领域有着广泛的应用,特别是在训练大规模数据集和复杂模型时更为常见。以下是小批量梯度下降算法在深度学习中的几个经典应用示例。
3.1 图像分类
在图像分类任务中,通常使用深度卷积神经网络(CNN)模型对图像进行分类。由于图像数据集通常较大,因此训练过程需要大量的计算资源和时间。小批量梯度下降算法能够更有效地处理大规模图像数据集,并且可以利用GPU等并行计算资源加速训练过程。
import tensorflow as tf
# 加载图像数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 构建卷积神经网络模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax)
])
# 编译模型并使用小批量梯度下降算法进行训练
model.compile(optimizer=tf.keras.optimizers.SGD(), loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=64, epochs=10)
3.2 语言模型
在自然语言处理任务中,如机器翻译、文本生成等任务,通常使用循环神经网络(RNN)或者长短时记忆网络(LSTM)模型进行建模。小批量梯度下降算法能够更有效地处理大规模文本数据集,并且可以通过并行计算加速训练过程。
import tensorflow as tf
# 加载文本数据集
text_data = load_text_data()
# 构建循环神经网络模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embed_size, input_length=max_seq_length),
tf.keras.layers.LSTM(128),
tf.keras.layers.Dense(num_classes, activation="softmax")
])
# 编译模型并使用小批量梯度下降算法进行训练
model.compile(optimizer=tf.keras.optimizers.SGD(), loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=32, epochs=10)
4. 总结
在本文中,我们详细介绍了小批量梯度下降算法的原理、优点和应用,并通过图像分类和语言模型两个实际示例展示了该算法在深度学习领域的应用。小批量梯度下降算法作为一种介于批量梯度下降和随机梯度下降之间的优化算法,在大规模数据集和复杂模型训练中具有较大的优势,能够更快地收敛和更有效地优化模型参数。希望本文能够帮助读者更好地理解小批量梯度下降算法,并在实际应用中取得更好的效果。







