

前言
基本概览了人工智能领域的基础知识,从Agent入手,经过搜索,逻辑等。
但对于领域前沿以及一些科研相关的内容没有过多涉及,还是比较浅显。
我准备分笔记、备考两个页面来讲清楚这门课程怎么收获知识+成绩。这里先放笔记。

人工智能笔记
第1章 绪论
人工智能的4种观点
-
像人一样思考
-
像人一样行动
-
合理地思考
-
合理地行动:★理性Agent:能够实现最佳期望结果而行动的Agent
第2章 智能Agent
2.1 Agent和环境
-
【2024期中】Agent:可以感知环境并在环境中行动的事物
-
Agent函数:描述Agent行为,将感知序列映射为行动
-
Agent程序:实现Agent函数
2.2 理性Agent
【2024期中】理性Agent:对每一个可能的感知序列,根据已知的感知序列和Agent具有的先验知识,理性Agent应该采取能使其性能度量最大化的行动。
或:理性 Agent 为合理行动的 Agent,Agent 根据它所知道的做了“正确的事情”。
2.3 环境PEAS
【2024期中】一个 Agent 包含 4 个部分,性能、环境、执行器、感知器
任务环境:PEAS
-
性能:Performance
-
环境:Environment
-
执行器:Actuators
-
传感器:Sensors
任务环境的性质
-
完全可观察部分可观察(完全可观察:每个时间点上都能获取环境的完整状态)
-
单Agent多Agent
-
确定的随机的不确定的(确定的:下一状态完全取决于当前状态和Agent执行的动作)【举例:真空吸尘器世界自动驾驶】
-
片段式的延续式的(下一片段不依赖于之前片段中采取的行动)【举例:流水线上的分类任务自动驾驶和国际象棋】
-
静态的动态的半动态的(环境在Agent计算时是否会发生变化。若Agent性能评价随时间流逝而变化,为半动态)【举例:字谜游戏自动驾驶国际象棋(计时)】
-
离散的连续的(环境的状态,时间;Agent的感知信息和行动)【举例:国际象棋自动驾驶】
-
已知的未知的(Agent的知识状态,即Agent了解环境的“物理法则”)环境的部分/完全可观察环境已知/未知【举例:翻牌游戏(已知环境部分可观察)视频游戏(未知环境完全可观察)】
2.4 Agent结构
Agent=体系结构+程序
★Agent程序(基础4个+转化为学习Agent)
(每张对应的图要能画出来,下图由前向后每次迭代增加功能)
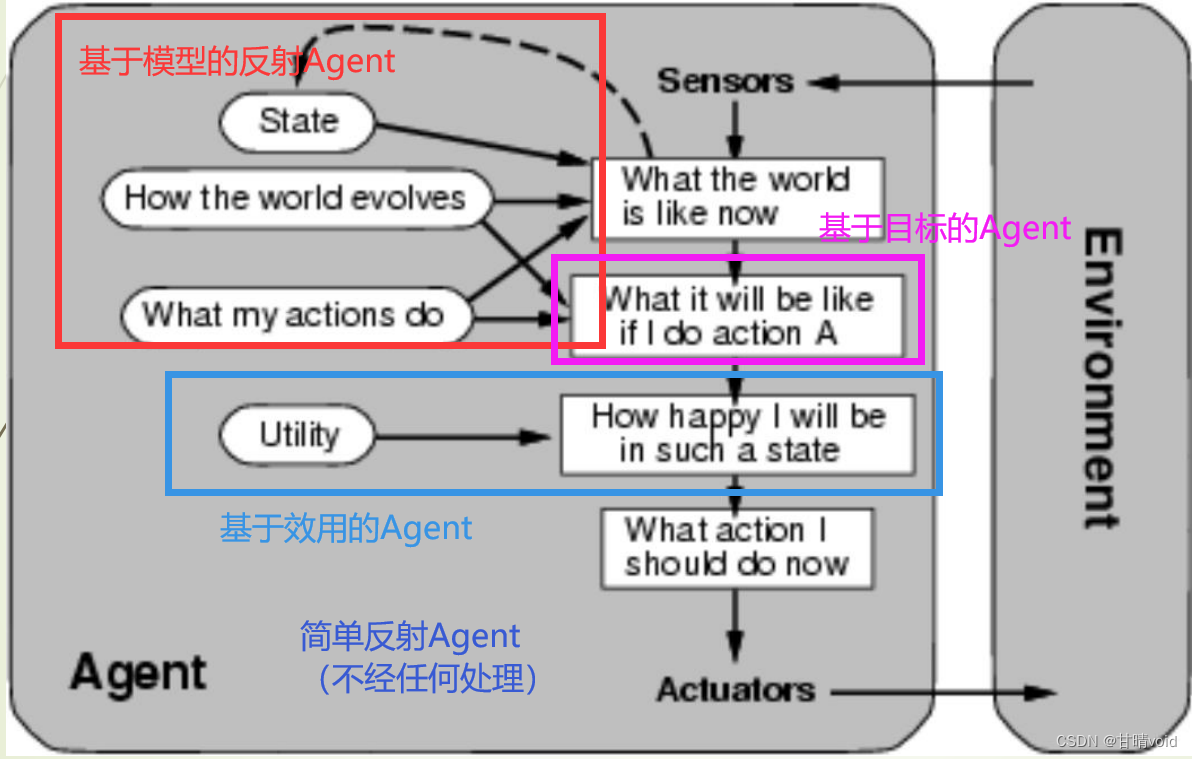
-
简单反射Agent:基于当前感知选择行动,不关注感知历史
-
基于模型的反射Agent:Agent根据感知历史维持内部状态,Agent随时更新内部状态信息
-
基于目标的Agent:除了感知信息之外,还需要根据目标信息来选择行动
-
基于效用的Agent:当达到目标的行为有多种时,基于效用进行决策
【2020期中】学习Agent:由性能元件,评判元件,学习元件,问题产生器构成

-
评判元件:根据固定的性能标准告诉学习元件Agent的运转情况
-
学习元件:学习部件根据评判部件反馈的评价Agent的表现,确定如何修改执行部件
-
性能元件:接受感知,选择外部行动
-
问题产生器:负责得到新的和有信息的经验的行动提议
第3章 通过搜索进行问题求解
3.1 问题求解Agent
搜索问题求解Agent步骤:形式化,搜索,执行
问题的定义
-
初始状态:In(A)
-
行动:对于状态s,ACTION(s)={GO(B), GO(C), GO(D)}
-
转移模型:RESULT(IN(A), GO(B))=IN(B)
-
目标测试:测试当前状态是否目标状态{IN(TARGET)}
-
路径耗散:反应性能度量
3.2 问题实例
真空吸尘器世界
-
-
-
-
-
-







