

以下是十大常见的人工智能算法在Python中的基本实现代码。请注意,这些代码仅用于演示目的,并未针对性能或效率进行优化。在实际项目中,你可能需要使用更高级的库或工具,例如TensorFlow或PyTorch,来进行这些算法的实现。
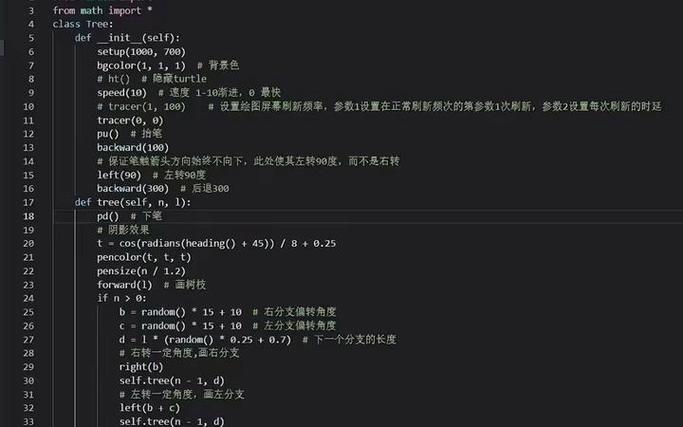
(图片来源网络,侵删)
1、线性回归 (Linear Regression)
from sklearn.linear_model import LinearRegression import numpy as np # 创建数据 X = np.array([[1], [2], [3], [4], [5]]) y = np.array([2, 4, 6, 8, 10]) # 拟合模型 model = LinearRegression() model.fit(X, y) # 预测 print(model.predict([[6]]))
2、逻辑回归 (Logistic Regression)
from sklearn.linear_model import LogisticRegression import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = LogisticRegression() model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
3、K近邻 (K-Nearest Neighbors)
from sklearn.neighbors import KNeighborsClassifier import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = KNeighborsClassifier(n_neighbors=3) model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
4、决策树 (Decision Tree)
from sklearn.tree import DecisionTreeClassifier import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = DecisionTreeClassifier() model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
5、朴素贝叶斯 (Naive Bayes)
from sklearn.naive_bayes import GaussianNB import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = GaussianNB() model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
6、随机森林 (Random Forest)
from sklearn.ensemble import RandomForestClassifier import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = RandomForestClassifier(n_estimators=100) model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
7、支持向量机 (Support Vector Machines)
from sklearn import svm import numpy as np # 创建数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 拟合模型 model = svm.SVC(kernel='linear') model.fit(X, y) # 预测 print(model.predict([[5, 6]]))
8、梯度提升树 (Gradient Boosting Trees)
from sklearn.ensemble import GradientBoostingClassifier from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 创建模拟数据 X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=0, shuffle=False) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化梯度提升树分类器 gb_clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=42) # 训练模型 gb_clf.fit(X_train, y_train) # 预测测试集 y_pred = gb_clf.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print(f"Accuracy: {accuracy:.2f}") # 可以进一步查看模型的特征重要性 feature_importances = gb_clf.feature_importances_ print(f"Feature importances: {feature_importances}")
9、主成分分析 (Principal Component Analysis, PCA)
from sklearn.decomposition import PCA import numpy as np # 创建数据 X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) # 拟合模型 pca = PCA(n_components=1) pca.fit(X) # 转换数据 X_pca = pca.transform(X) print(X_pca)
10、聚类算法:K-Means
from sklearn.cluster import KMeans import numpy as np # 创建数据 X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]]) # 拟合模型 kmeans = KMeans(n_clusters=2, random_state=0) kmeans.fit(X) # 预测聚类标签 labels = kmeans.predict(X) print(labels) # 预测聚类中心 centers = kmeans.cluster_centers_ print(centers)
这些代码都是使用sklearn库的基本示例,它是一个非常流行的Python机器学习库,提供了大量的预构建算法和工具。在实际应用中,你可能需要调整参数、处理数据、评估模型性能等。此外,对于深度学习和其他更复杂的任务,你可能会使用TensorFlow、PyTorch等框架。
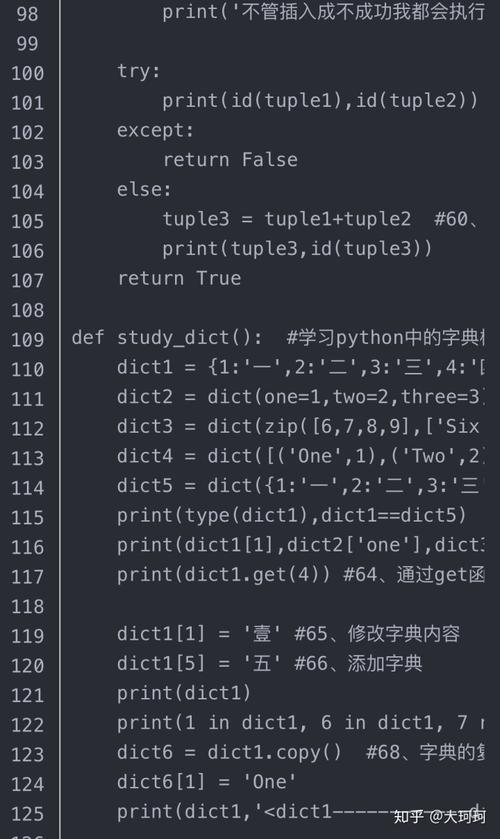
(图片来源网络,侵删)







