

目录
- 1、引言
- 2、性能参数
- 3、开箱体验
- 4、实际使用
- 5、性能比较
- 总结
- 参考文章
1、引言
第一次接触香橙派的开发板,之前使用过Arduino、树莓派3B、树莓派4B,STM32,51单片机,没有想到国产品牌性能一样强劲,使用起来也是很方便。香橙派是深圳市迅龙软件有限公司旗下开源产品品牌,经查资料了解2014年发布了第一款开源产品,主打的是超高性价比和优异的使用体验,到现在也迭代了30多代产品,在一众开发板厂商中是比较优质的存在。本文旨在从性能参数、使用体验上综合给出个人的看法和评价,希望能够给大家带来帮助。
2、性能参数
下面列举了部分比较重要的参数,具体配置需要去官网查看。香橙派官方页面
部件 详细参数 昇腾AI处理器 4核64位Arm处理器+AI处理器 AI算力 半精度(FP16):4 TFLOPS、整数精度(INT8):8TOPS 内存 LPDDR4X 可选8GB或16GB Wi-Fi+蓝牙 支持2.4G和5G双频WIFI 摄像头 2个MIPI CSI 2 Lane接口 显示 2个HDMI接口,1个MIPI DSI 2 Lane接口 40 pin扩展口 用于扩展UART、I2C、SPI、PWM和GPIO接口 电源 支持Type-C供电,20V PD-65W 适配器 风扇接口 4pin,0.8mm间距,用于接12V风扇,支持PWM控制 电池接口 2pin,2.54mm间距,用于接3串电池,支持快充 接口详情图:


可以看到是堆料满满的一款产品,昇腾AI处理器是为了满足飞速发展的深度神经网络对芯片算力的需求,由华为公司在2018年推出的AI处理器,对整型数(INT8、INT4)或浮点数(FP16)提供了强大高效的计算力,在硬件结构上对深度神经网络做了优化,可以很高效率完成神经网络中的前向计算因此在智能终端领域有很大的应用前景。
3、开箱体验


包装盒精致小巧,封装纸盒上是橙子的标志,下面用黄色加粗颜色文字强调该产品的特色功能是深度学习领域,开发板上下用了泡沫防护,总体是很精美的。


拆开包装盒后官方提供了开发板x1,Type-C接口的20V PD-65W适配器,充电器接头的折叠设计很有意思,这个设计便于携带也能够提升产品的使用寿命。




搭配的静音风扇效果很好,开机的时候会有较大噪音,大约持续几秒后没有任何声音。WIFI和蓝牙的天线扣设计位置也相对方便。
4、实际使用
初次使用最好还是采用HDMI接口连接开发板显示,这种方式是最简单也最快捷的,官方文档中提供了三种登录系统的方式。

使用HDMI连接便携显示器:

一眼看过去很惊艳的Logo,输入官方提供的密码就可以进入系统了,烧录的系统是ubentu 22.04。
连接上WIFI后可以通过以下方式连接SSH进入系统:
ssh HwHiAiUser@IP地址
不过还是比较喜欢使用VNC多一些,下面提供一种连接上WIFL后配置VNC远程连接的方式。
步骤一:安装tightvncserver
sudo apt update sudo apt install tightvncserver
步骤二:配置vncserver密码:
sudo vncserver
步骤三:修改.vnc/xstartup文件,设置vnc服务器启动xfce桌面环境。
sudo vim .vnc/xstartup
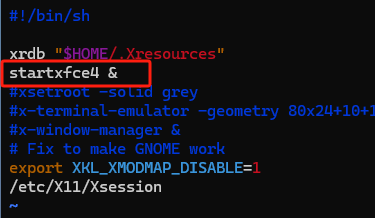
接下来就可以使用VNC远程连接开发板进入系统了。

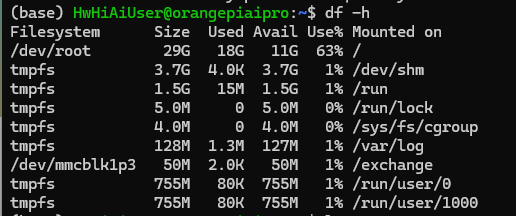
32gb内存预装完系统后还有11gb的空闲内存,足够做很多东西。
5、性能比较
正好Windows上预装了jupyter notebook,因此这里选用了MNIST手写数据集来测试开发板和Windowsa在做导入数据和模型训练时的差异性,我的WINDOW使用的是英特尔的至强 E5-2666 v3,主频2.90GHz,未做任何相关优化处理。

接下来会从数据处理、训练SGD模型、训练BP神经网络模型三个方面来比较运行速度的差异。
import sys print("Current System:====",sys.platform,"====") from sklearn.datasets import fetch_openml import numpy as np import os #Rand num np.random.seed(62) %matplotlib inline import matplotlib as mpl import matplotlib.pyplot as plt #setting plot mpl.rc('axes', labelsize=14) mpl.rc('xtick', labelsize=12) mpl.rc('ytick', labelsize=12) mpl.rcParams['font.sans-serif'] = [u'SimHei'] mpl.rcParams['axes.unicode_minus'] = False #import date def sort_by_target(mnist): reorder_train=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[:60000])]))[:,1] reorder_test=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[60000:])]))[:,1] mnist.data[:60000]=mnist.data.loc[reorder_train] mnist.target[:60000]=mnist.target[reorder_train] mnist.data[60000:]=mnist.data.loc[reorder_test+60000] mnist.target[60000:]=mnist.target[reorder_test+60000] import time a=time.time() mnist=fetch_openml('mnist_784',version=1,cache=True) mnist.target=mnist.target.astype(np.int8) sort_by_target(mnist) b=time.time() print("Finish Time:",b-a)运行同一段代码做数据的导入处理:
开发板完成时间:
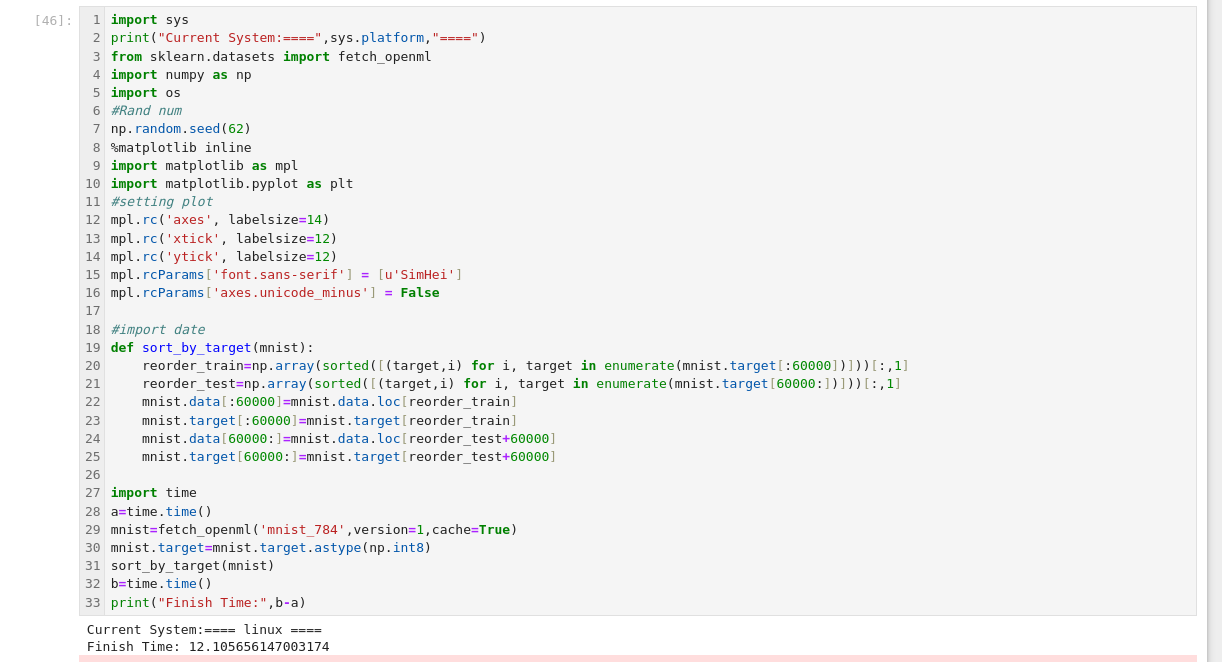
Windows端完成时间:
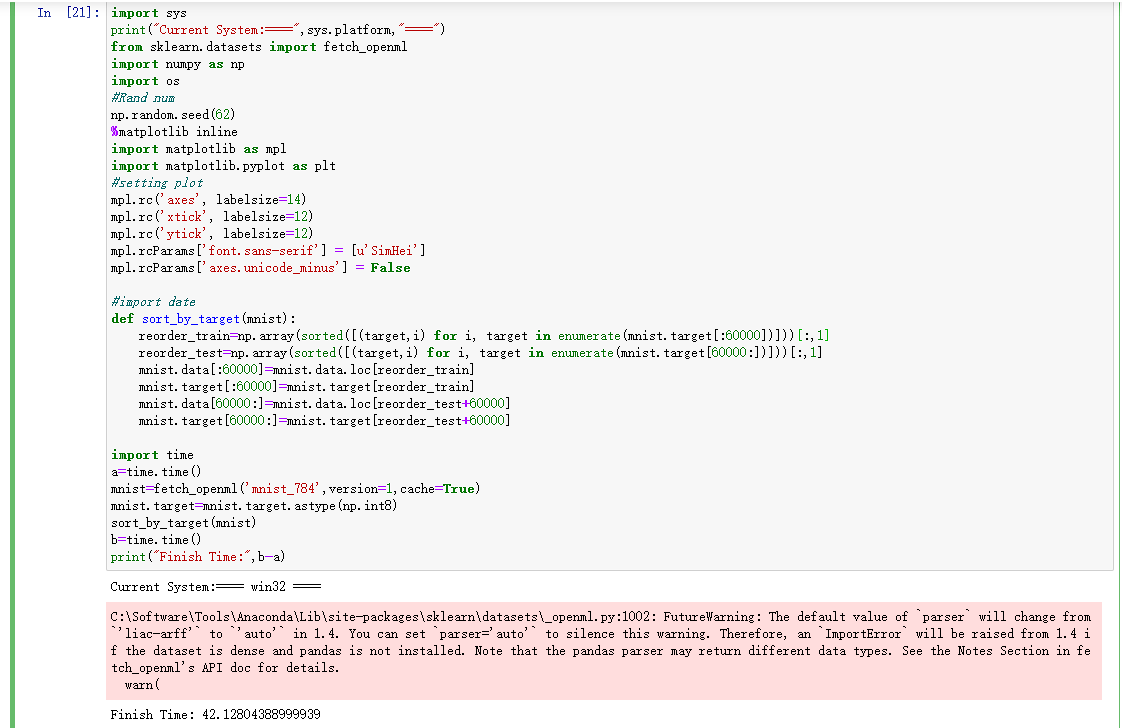
可以看出处理同一段数据,windows没有做相关优化的速度会慢一些。
SGD模型训练代码:
import sys print("Current System:====",sys.platform,"====") X,y=mnist["data"],mnist["target"] X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] import numpy as np shuffer_index=np.random.permutation(60000) X_train,y_train=X_train.iloc[shuffer_index],y_train[shuffer_index] from sklearn.linear_model import SGDClassifier sgd_clf=SGDClassifier(max_iter=5,tol=None,random_state=42) c=time.time() sgd_clf.fit(X_train,y_train) d = time.time() print("SGD Model Train Time:",d-c) SGDClassifier(alpha=0.0001, average=False, class_weight=None, early_stopping=False, epsilon=0.1, eta0=0.0, fit_intercept=True, l1_ratio=0.15, learning_rate='optimal', loss='hinge', max_iter=5, n_iter_no_change=5, n_jobs=None, penalty='l2', power_t=0.5, random_state=42, shuffle=True, tol=None, validation_fraction=0.1, verbose=0, warm_start=False)SGD模型训练时间:
开发板:
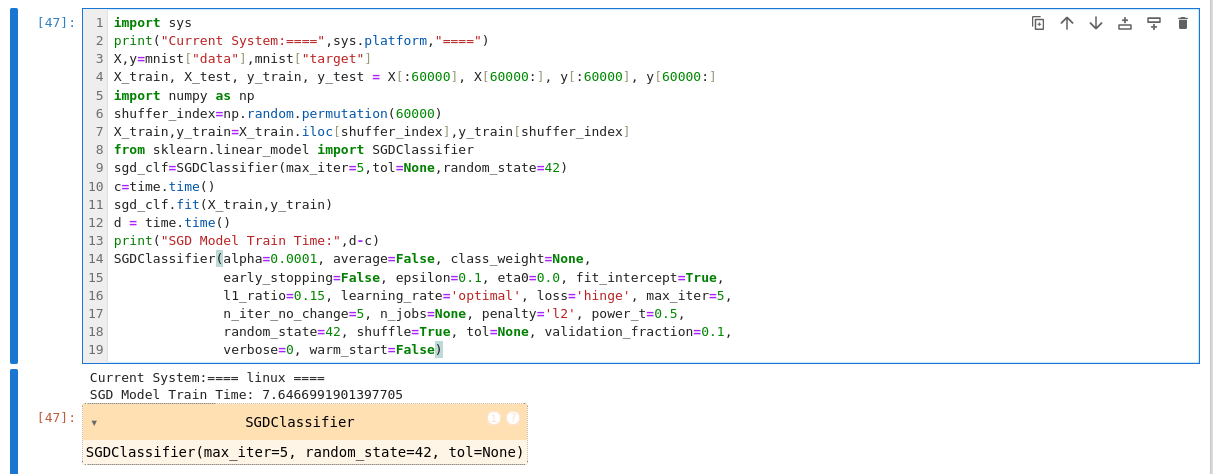
WINDOWS训练时间:
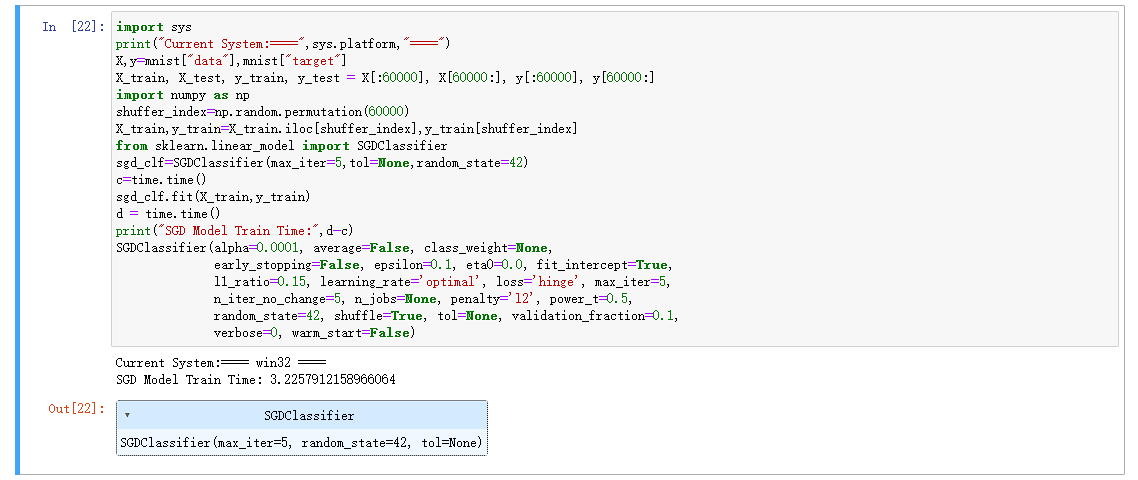
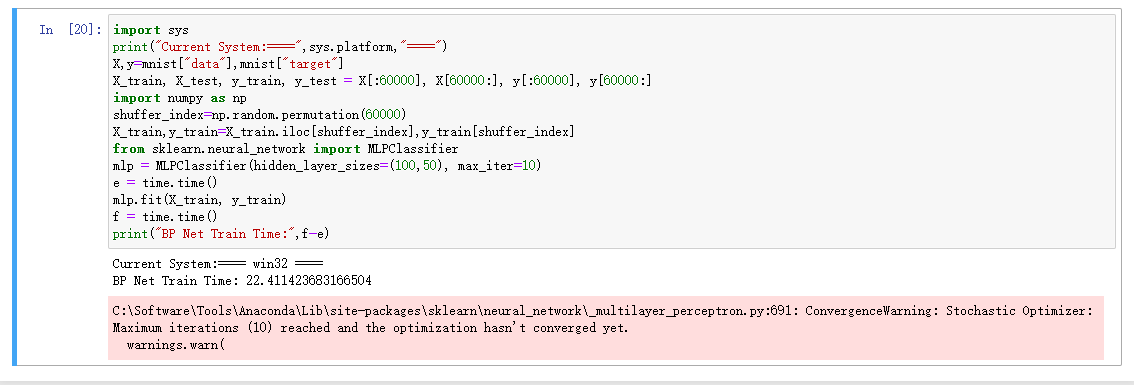
BP神经网络训练代码:
import sys print("Current System:====",sys.platform,"====") X,y=mnist["data"],mnist["target"] X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] import numpy as np shuffer_index=np.random.permutation(60000) X_train,y_train=X_train.iloc[shuffer_index],y_train[shuffer_index] from sklearn.neural_network import MLPClassifier mlp = MLPClassifier(hidden_layer_sizes=(100,50), max_iter=10) e = time.time() mlp.fit(X_train, y_train) f = time.time() print("BP Net Train Time:",f-e)BP神经网络训练时间:
开发板:
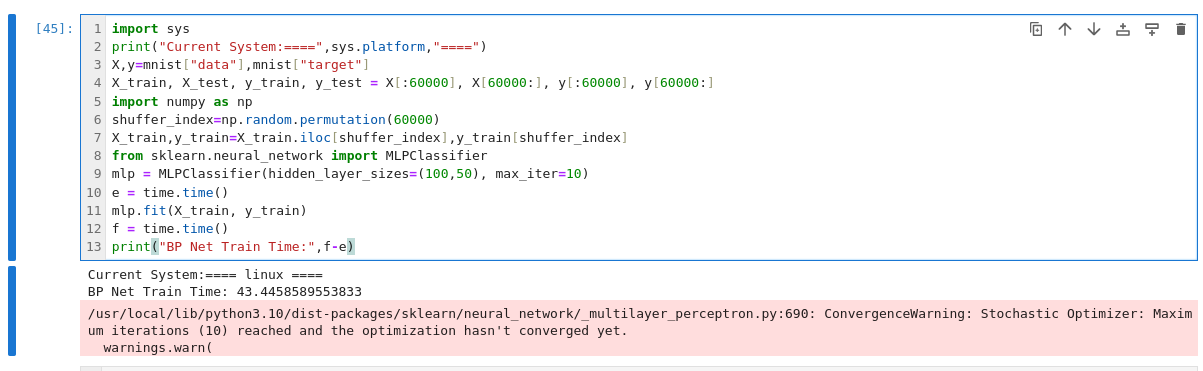
WINDOW:
最终结果:
设备/时间(秒) 导入数据 训练SGD 训练BP神经网络 香橙派AI PRO 12.11s 7.65s 43.45s E5-2666 v3 42.13s 3.23s 22.41s 可以看出本次香橙派AI Pro的实力还是不错的,数据处理的速度会比E5-2666 v3快些,不过在模型训练方面可能会稍有逊色,大约需要花上两倍的时间进行处理,开发板达到这个效果已经很棒了。
总结
这款产品综合下来性价比很高,并不昂贵的价格采用昇腾AI技术路线,提供8TOPS AI算力,个人感觉已经满足诸如视频图像分析、自然语言处理、智能小车、人工智能、智能安防、智能家居等多个领域的使用要求,相信16GB版本更能让人眼前一亮。
参考文章
1、BP Network mnist手写数据集 基于sklearn
2、基于jupyter notebook的python编程-----MNIST数据集的的定义及相关处理学习
3、MNIST手写数字识别sklearn实践
4、机器学习第三章:MNIST手写数字预测
5、瑞芯微RK3399开发板香橙派4使用 VNC 远程登录的方法







