

一、数据挖掘流程
1.数据读取
-读取数据
-统计指标
-数据规模
2.数据探索(特征理解)
-单特征的分析,诸个变量分析对结果y的影响(x,y的相关性)
-多变量分析(x,y之间的相关性)
-统计绘图
3.数据清洗和预处理
-缺失值填充
-标准化、归一化
-特征工程(筛选有价值的特征)
-分析特征之间的相关性
4.建模
-特征数据的准备和标签
-数据集的切分
-集成算法(提升算法)XGBoost、GBDT、light-GBM、神经网络(多种集成)
二、代码实现
1.数据读取
数据集可以去kaggle下载:Titanic - Machine Learning from Disaster | Kaggle。
data = pd.read_csv('./data/train.csv')
pd.set_option('display.max_columns', 20)
print(data.head(4))
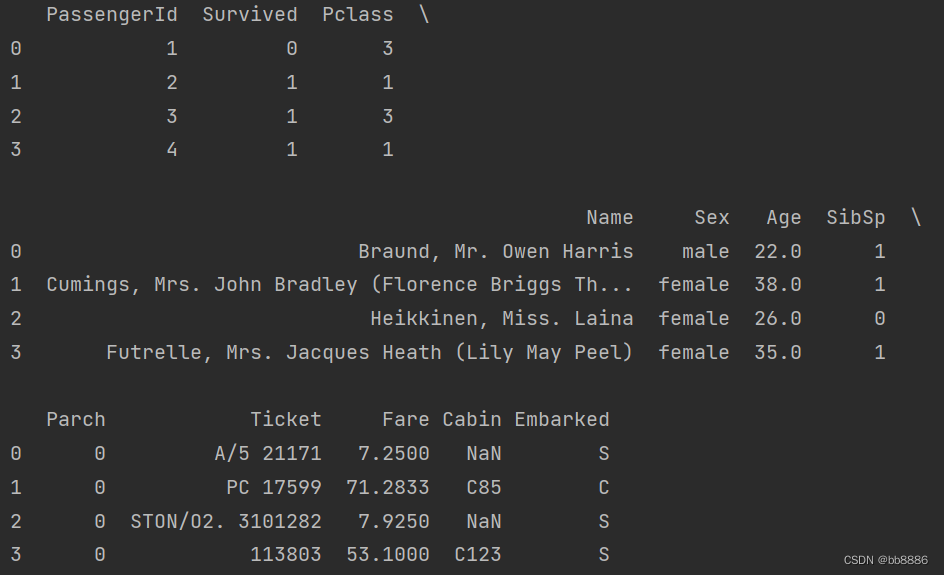
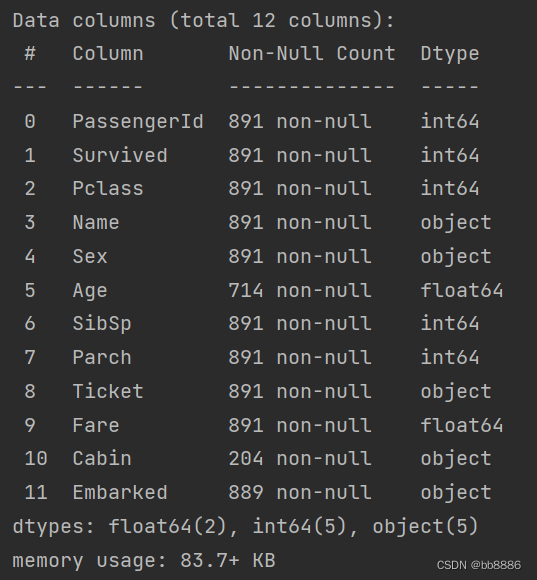
print(data.info())
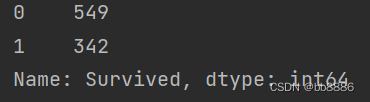
print(data['Survived'].value_counts()) # 当前列计数
2、数据探索
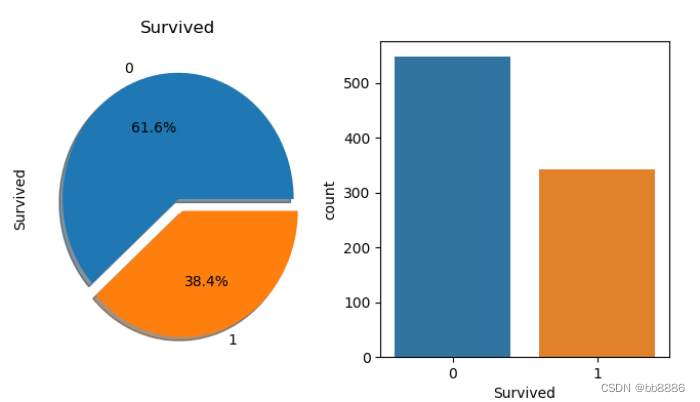
# 标签比例 获救比例,饼图
f, ax = plt.subplots(1, 2, figsize=(10, 6))
data['Survived'].value_counts().plot.pie(explode=[0, 0.1], # 偏移量
autopct='%1.1f%%', # 百分比保留小数位数
ax=ax[0], shadow=True)
ax[0].set_title('Survived') # 图一标题
sns.countplot('Survived', saturation=0.75, # 饱和度
data=data, ax=ax[1]) # 柱状图
plt.show()
# 男女获救比例 print(data.groupby(['Sex', 'Survived'])['Survived'].count())
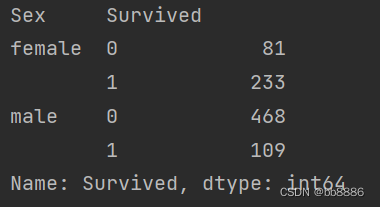
sns.countplot('Sex', hue='Survived', data=data) # 柱状图
plt.show()
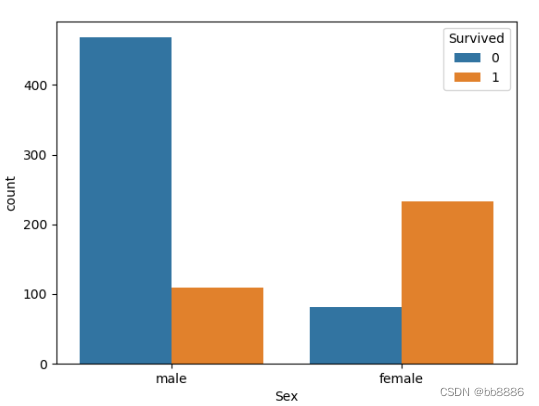
# 船舱等级和获救之间的关系 print(pd.crosstab(data['Pclass'], data['Survived'], margins=True))
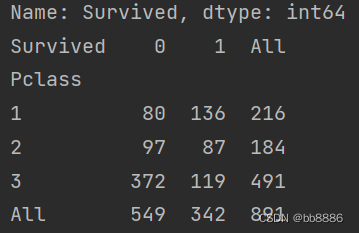
sns.countplot('Pclass', hue='Survived', data=data)
plt.show()
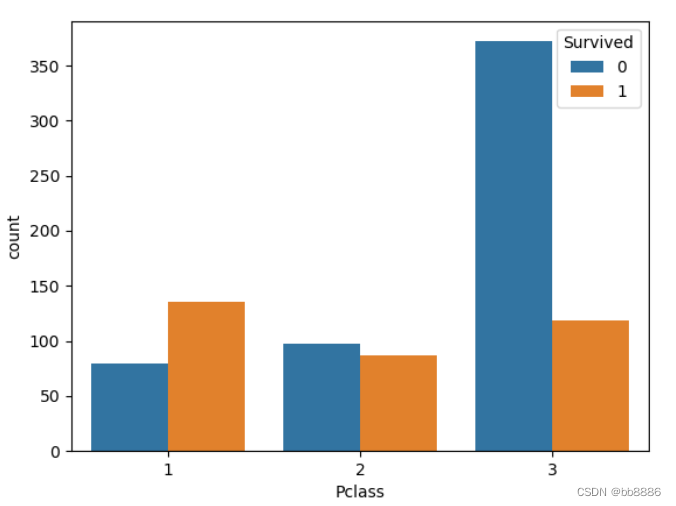
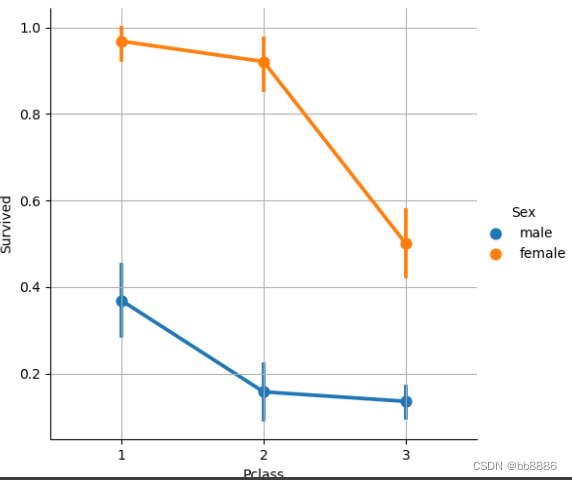
# 不同性别及船舱等级和获救之间的关系 print(pd.crosstab([data['Sex'], data['Survived']], data['Pclass'], margins=True))

sns.factorplot('Pclass', 'Survived',
hue='Sex', # 颜色
data=data) # 降维画图
plt.grid()
plt.show()
3.数据清洗和预处理
3.1 提取性别身份,并将少数类归为其他
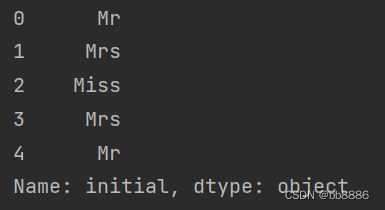
data['initial'] = data['Name'].str.extract('([A-Za-z]+)\.') # 提取性别身份
print(data['initial'].head(5))
print(pd.crosstab(data['initial'], data['Sex']).T)
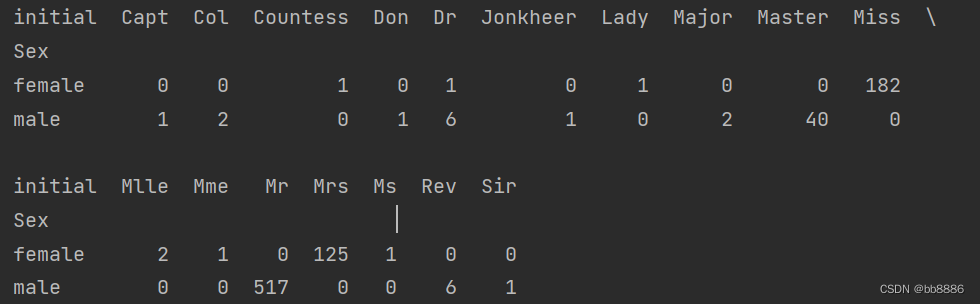
将少数的列变为other列。(除Master、Mr、Miss、Mrs外的其他列变为other列)
def transformOther(str):
if str != 'Master' and str != 'Miss' and str != 'Mr' and str != 'Mrs':
str = 'other'
return str
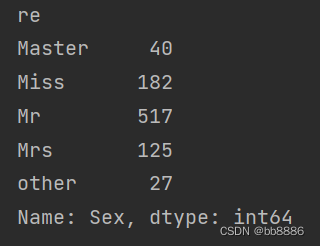
data['re'] = data['initial'].apply(transformOther) print(data['re'].unique())
![]()
print(data.groupby('re')['Sex'].count())
3.2 缺失值填充
3.2.1填补Age缺失值(用各性别下年龄均值去填补Age缺失值)
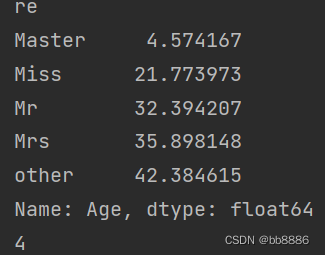
# 各性别下年龄均值
print(data.groupby('re')['Age'].mean())
print(int(data.groupby('re')['Age'].mean()[0]))
def FillNullAge(age):
for str in data['re'].values:
if np.isnan(age):
age = int(data.groupby('re')['Age'].mean()[str])
return age
data['Age'] = data['Age'].apply(FillNullAge)
print(data['Age'].isnull().sum())
![]()
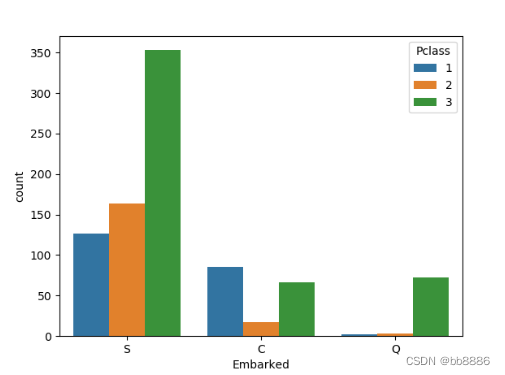
3.2.2 填充港口数据
上船港口和船舱等级之间的关系。
# 上船港口和船舱等级之间的关系
print(pd.crosstab(data['Embarked'], data['Pclass'], margins=True))
sns.countplot('Embarked', # 上船的港口
hue='Pclass', data=data)
plt.show()

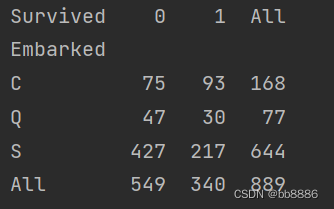
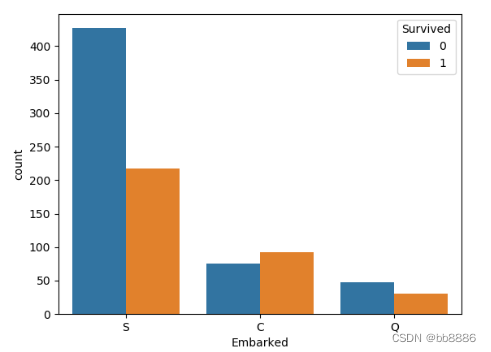
上船港口和获救之间的关系。
# 上船港口和获救之间的关系
print(pd.crosstab(data['Embarked'], data['Survived'], margins=True))
sns.countplot('Embarked', hue='Survived', data=data)
plt.show()
填补港口数据为s。
data['Embarked'].fillna('s', inplace=True) # 填补港口数据
print(data['Embarked'].isnull().any())

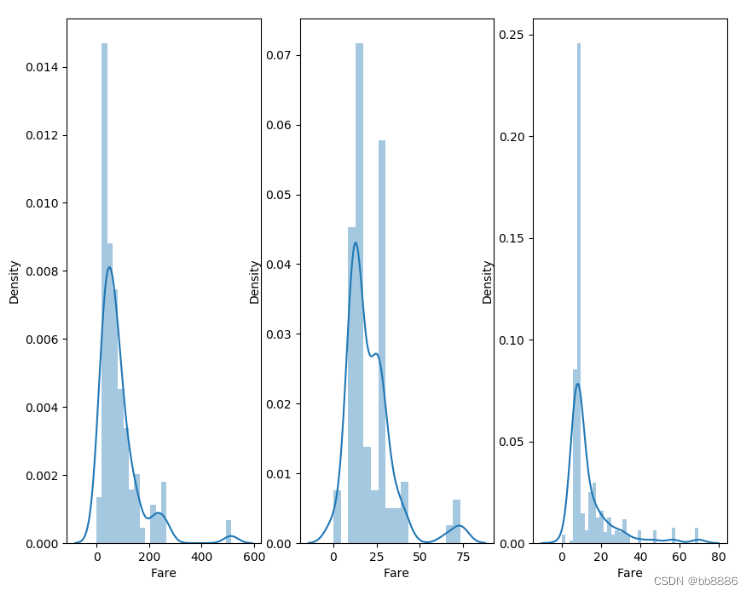
不同船舱的核密度估计图
# 不同船舱的核密度估计图 f, ax = plt.subplots(1, 3, figsize=(10, 8)) sns.distplot(data[data['Pclass'] == 1].Fare, ax=ax[0]) sns.distplot(data[data['Pclass'] == 2].Fare, ax=ax[1]) sns.distplot(data[data['Pclass'] == 3].Fare, ax=ax[2]) plt.show()
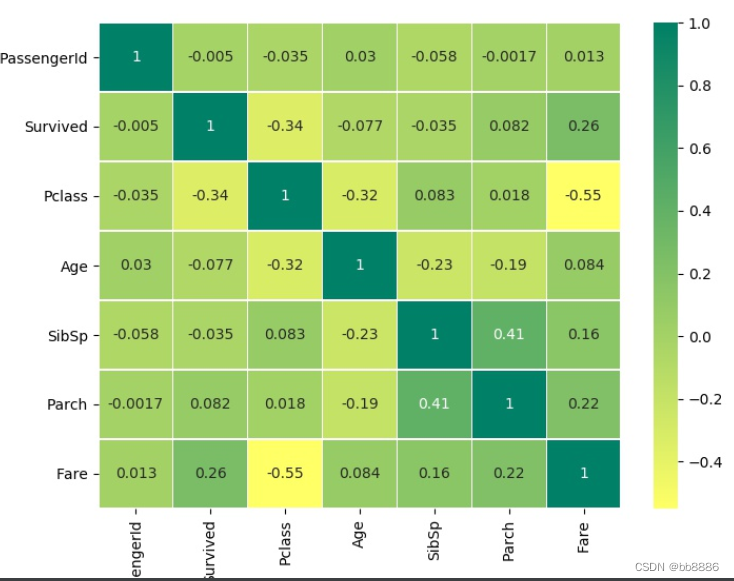
相关性热图
# 相关性热图
sns.heatmap(data.corr(), annot=True, linewidths=0.2, cmap='summer_r')
fig = plt.gcf()
fig.set_size_inches(8, 6)
plt.savefig('heatmap.jpg')
3.3 数据处理
3.3.1 年龄分段(







