目录
- 1. 分析网页试着拿到多个页面的url
- 2. 抓取250个电影
- 3. start_requests的使用
- 4. 代码规范
- 导库的优化
- 关于重写
- 最终修改后的代码
- 总结
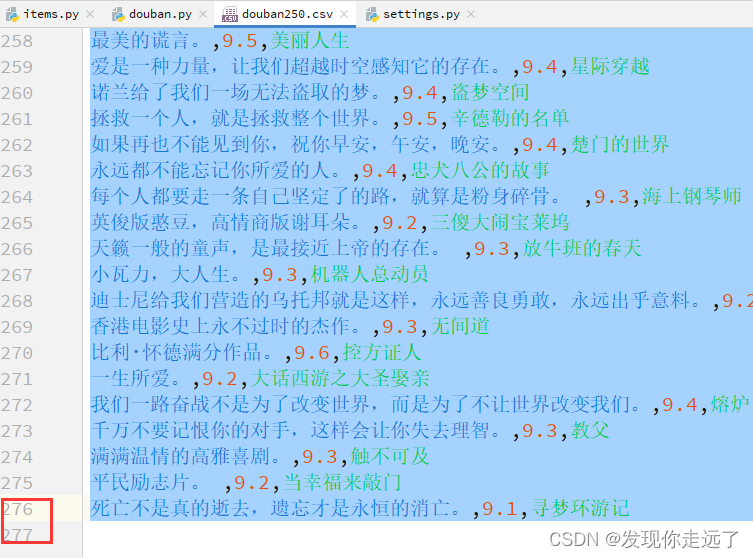
div > div.article > ol > li") for list_item in list_items: movie_item=MovieItem()#新建类的对象 # 电影标题的 Selector # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1) movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # 电影评分 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # # 电影影评 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 yield movie_item#把整理得到的数据给管道 # 单个页面selector # content > div > div.article > div.paginator > a:nth-child(3) # ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。 hrefs_list=myselector.css('div.paginator > a::attr(href)') for href in hrefs_list: url=response.urljoin(href.extract()) print(url)cmd运行,可以看到获取了url
scrapy crawl douban
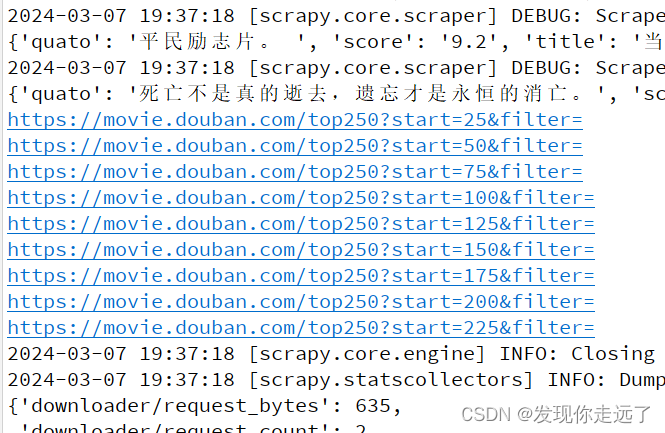
div > div.article > ol > li") for list_item in list_items: movie_item=MovieItem()#新建类的对象 # 电影标题的 Selector # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1) movie_item['title']=list_item.css("span.title::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # 电影评分 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num movie_item['score']=list_item.css("span.rating_num::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 # # 电影影评 # content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > p.quote > span movie_item['quato']=list_item.css("span.inq::text").extract_first() # extract_first()从选择器中提取第一个匹配的数据。 yield movie_item#把整理得到的数据给管道 # 单个页面selector # content > div > div.article > div.paginator > a:nth-child(3) # ::attr(href)表示选取元素的href属性。使用.getall()方法可以获取匹配到的所有元素的href属性值,并将其存储在一个列表中。 hrefs_list=myselector.css('div.paginator > a::attr(href)') for href in hrefs_list: url=response.urljoin(href.extract()) # print(url) # 将 Request 对象加入到爬虫的请求队列中,以便发送请求,相当于对每个页面执行抓取数据 yield Request(url=url) #注意这个Request是来自scrapy的. from scrapy import Selector,Requestcmd运行
scrapy crawl douban -o douban250.csv