

pip install
- pip install requests
- pip install base64
- pip install pycrytodome
tools
浏览器的开发者工具,重点使用断点,和调用堆栈
工具网站:https://curlconverter.com/ 简便请求发送信息
flow
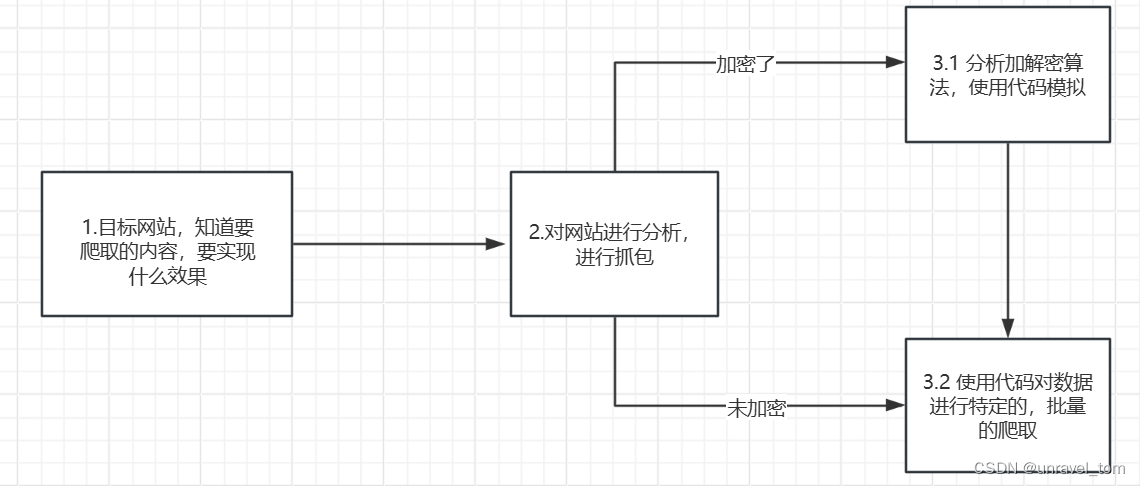
- 根据网站信息,preview,response均是加密数据,或者说请求和响应我们都需要使用代码来进行模仿
- 由请求方式是post,所以我们需要关注payload载荷发现动态值sign,mysticTime是时间戳
- 对JS代码进行分析,找到动态值生成的地方,这里可以使用initiator发起程序,使用调用堆栈进行溯源,打断点进行测试,分析可知动态值是由md5摘要得出。
- 分析可知数据是base64变种对响应数据进行base64解码处理,分析加密算法是AES对称加密,找到对称密钥key,iv,进行解密。
- 最后对json数据进行反序列化,取得特定值
Code
import requests import time import hashlib import base64 import json from Crypto.Cipher import AES from Crypto.Util.Padding import unpad def get_md5(value, is_hex=True): """ md5 abstract algorithm params: value: str, the value to be md5 is_hex: bool, whether to return the md5 value in hex format return: str, the md5 value """ md5 = hashlib.md5() md5.update(value.encode('utf-8')) if is_hex: return md5.hexdigest() else: return md5.digest() word = input("Enter the word to be translated :") url = 'https://dict.youdao.com/webtranslate' mysticTime = str(int(time.time() * 1000)) # (1)构建逆向动态值 d = 'fanyideskweb' e = mysticTime u = 'webfanyi' t = 'fsdsogkndfokasodnaso' i = f"client={d}&mysticTime={e}&product={u}&key={t}" sign = get_md5(i) # (2)请求模拟 cookies = { 'OUTFOX_SEARCH_USER_ID': '-815609020@10.55.164.249', 'OUTFOX_SEARCH_USER_ID_NCOO': '1719344943.4114175', '_ga': 'GA1.2.674292823.1712131832', } headers = { 'Accept': 'application/json, text/plain, */*', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded', 'Cookie': 'OUTFOX_SEARCH_USER_ID=-815609020@10.55.164.249; OUTFOX_SEARCH_USER_ID_NCOO=1719344943.4114175; _ga=GA1.2.674292823.1712131832', 'Origin': 'https://fanyi.youdao.com', 'Referer': 'https://fanyi.youdao.com/', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'same-site', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0', 'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'referer': 'https://fanyi.youdao.com/', } data = { 'i': word, 'from': 'auto', 'to': '', 'useTerm': 'false', 'dictResult': 'true', 'keyid': 'webfanyi', 'sign': sign, 'client': 'fanyideskweb', 'product': 'webfanyi', 'appVersion': '1.0.0', 'vendor': 'web', 'pointParam': 'client,mysticTime,product', 'mysticTime': mysticTime, 'keyfrom': 'fanyi.web', 'mid': '1', 'screen': '1', 'model': '1', 'network': 'wifi', 'abtest': '0', 'yduuid': 'abcdefg', } res = requests.post(url , cookies=cookies, headers=headers, data=data) # base64变种 --> 正常base64 res_encrypt_base64 = res.text.replace('-', '+').replace('_', '/') # (3)解码和解密数据 res_encrypt_bytes = res_encrypt_base64.encode('utf-8') # 1.解码 res_encrypt_decode = base64.b64decode(res_encrypt_bytes) # 2.解密 t = 'ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl' o = 'ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4' key = get_md5(t, is_hex=False) iv = get_md5(o, is_hex=False) aes = AES.new(key, AES.MODE_CBC, iv) source_data = aes.decrypt(res_encrypt_decode) # (4)解析数据 data = unpad(source_data, 16) # json字符串,有base64填充,所以需要去填充 data = json.loads(data) ret = [line.get('tgt') for line in data['translateResult'][0]] print("\n".join(ret))END
我的想法:想要实现的功能是结合其他爬虫程序,进行批量的文章翻译自动化,但是这个爬虫脚本有点鸡肋,文本之间不能有空格,他对长文本的内容不能很好的翻译。







