

一、研究背景与意义
地震作为一种破坏力极强的自然灾害,给人类社会带来了巨大的生命和财产损失。尽管当前科技水平下,我们还无法直接阻止地震的发生,但准确的地震预测和预警可以为我们提供宝贵的逃生时间,从而有效降低地震灾害的损失。近年来,随着大数据技术的快速发展,利用大数据进行地震预测成为了新的研究热点。Apache Spark作为一种高效、可扩展的大数据处理框架,为地震预测提供了新的技术支撑。因此,本研究旨在构建基于Spark的地震预测系统,以提高地震预测的准确性和实时性,为地震防灾减灾工作提供有力支持。
二、研究目标与内容
本研究的主要目标包括:
- 构建基于Spark的地震数据处理与分析平台,实现地震数据的高效存储、处理和查询。
- 利用机器学习算法对地震数据进行挖掘和分析,提取地震发生的前兆信息。
- 构建地震预测模型,并通过Spark进行模型训练和预测。
- 设计并实现地震预警系统,将预测结果实时推送给相关部门和公众。
研究内容主要包括以下几个方面:
- 数据收集与预处理:收集历史地震数据、地质构造数据、气象数据等多源数据,并进行清洗、整合和标准化处理。
- 特征提取与选择:利用Spark进行大规模数据的特征提取和选择,构建地震预测的特征集。
- 模型构建与训练:选择合适的机器学习算法,利用Spark进行模型的分布式训练,优化模型参数。
- 预测与评估:利用训练好的模型进行地震预测,并通过交叉验证等方法对模型性能进行评估。
- 系统设计与实现:设计地震预测系统的整体架构,实现数据的存储、处理、预测和预警功能。
三、研究方法与技术路线
本研究将采用以下研究方法和技术路线:
- 数据收集与预处理:利用爬虫技术从相关网站获取地震数据,通过数据清洗和整合,形成标准化的数据集。
- 特征提取与选择:基于地震学、地质学等领域的知识,提取与地震发生相关的特征,并利用Spark的MLlib库进行特征选择。
- 模型构建与训练:选择如随机森林、支持向量机等机器学习算法,利用Spark的分布式计算能力进行模型训练。
- 预测与评估:将训练好的模型部署到Spark集群中,进行实时地震预测,并通过准确率、召回率等指标评估模型性能。
- 系统设计与实现:采用微服务架构和容器化技术,设计并实现地震预测系统的各个模块,确保系统的可扩展性和高可用性。
四、预期成果与创新点
通过本研究,预期将取得以下成果:
- 构建一个高效、准确的地震预测系统,为地震防灾减灾工作提供有力支持。
- 提出一种基于Spark的地震数据处理与分析方法,提高地震数据处理的效率和准确性。
- 优化地震预测模型的性能,提高地震预测的准确率和实时性。
本研究的创新点主要包括:
- 将Spark技术应用于地震预测领域,实现了大规模地震数据的高效处理和分析。
- 结合地震学、地质学等领域的知识,提出了基于多源数据的地震预测方法。
- 通过优化模型参数和算法选择,提高了地震预测的准确性和实时性。
五、研究计划与安排
本研究计划分为以下几个阶段进行:
- 文献调研与需求分析(XXXX年XX月-XXXX年XX月):收集并整理相关文献,明确研究目标和内容,进行需求分析。
- 数据收集与预处理(XXXX年XX月-XXXX年XX月):收集地震数据并进行预处理,形成标准化的数据集。
- 特征提取与选择(XXXX年XX月-XXXX年XX月):提取地震预测相关特征,并利用Spark进行特征选择。
- 模型构建与训练(XXXX年XX月-XXXX年XX月):选择合适的机器学习算法,利用Spark进行模型训练和参数优化。
- 系统设计与实现(XXXX年XX月-XXXX年XX月):设计地震预测系统的整体架构,实现各个功能模块。
- 预测与评估(XXXX年XX月-XXXX年XX月):利用训练好的模型进行地震预测,并评估模型性能。
- 论文撰写与成果整理(XXXX年XX月-XXXX年XX月):整理研究成果,撰写开题报告和毕业论文。
六、研究条件与保障
本研究将依托学校的高性能计算中心和实验室的硬件资源,确保研究的顺利进行。同时,研究团队具备丰富的地震数据处理和机器学习算法开发经验,为研究的深入开展提供了有力保障。此外,研究团队还将积极与国内外相关领域的专家学者进行合作与交流,共同推动地震预测技术的发展。
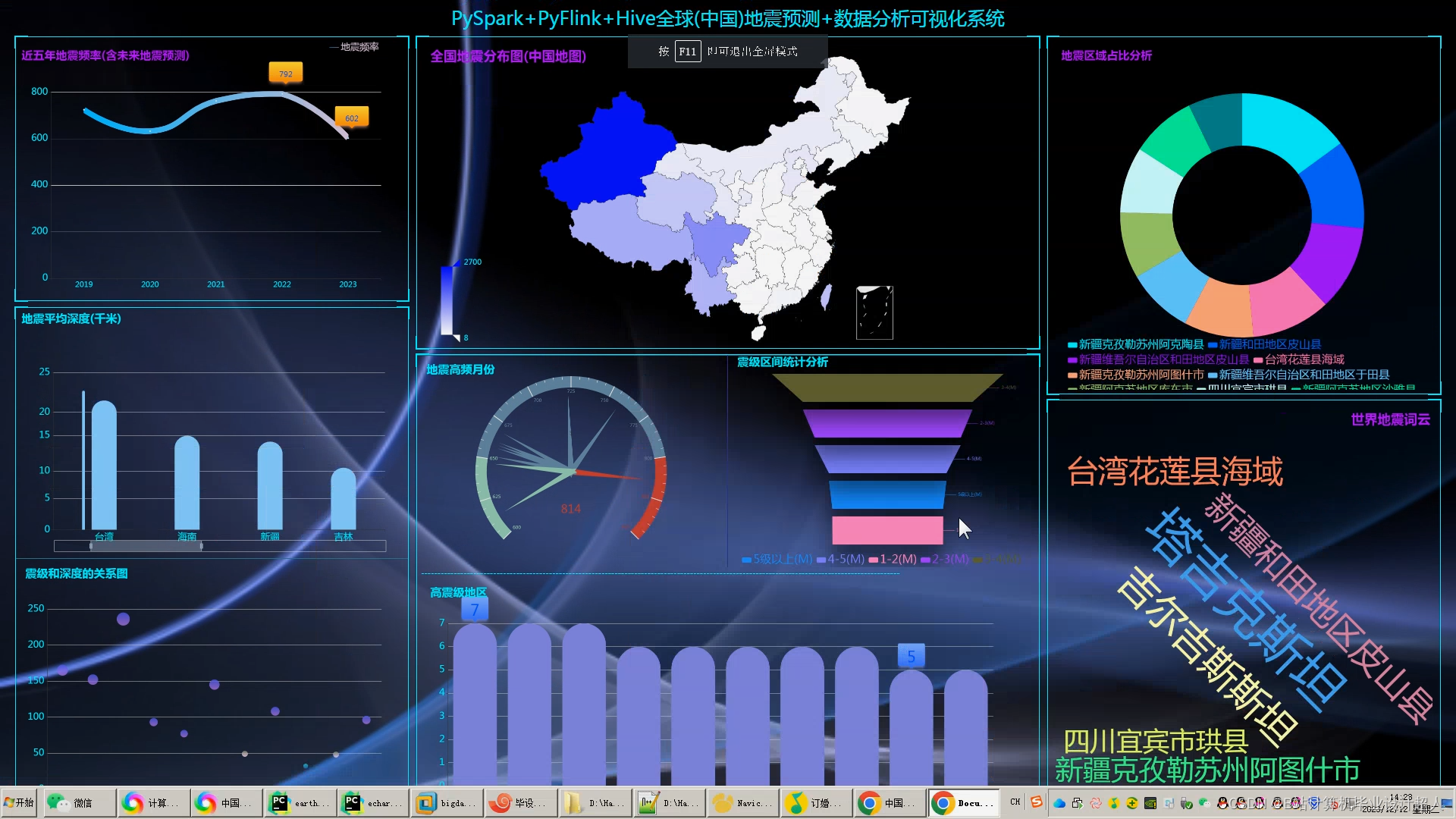
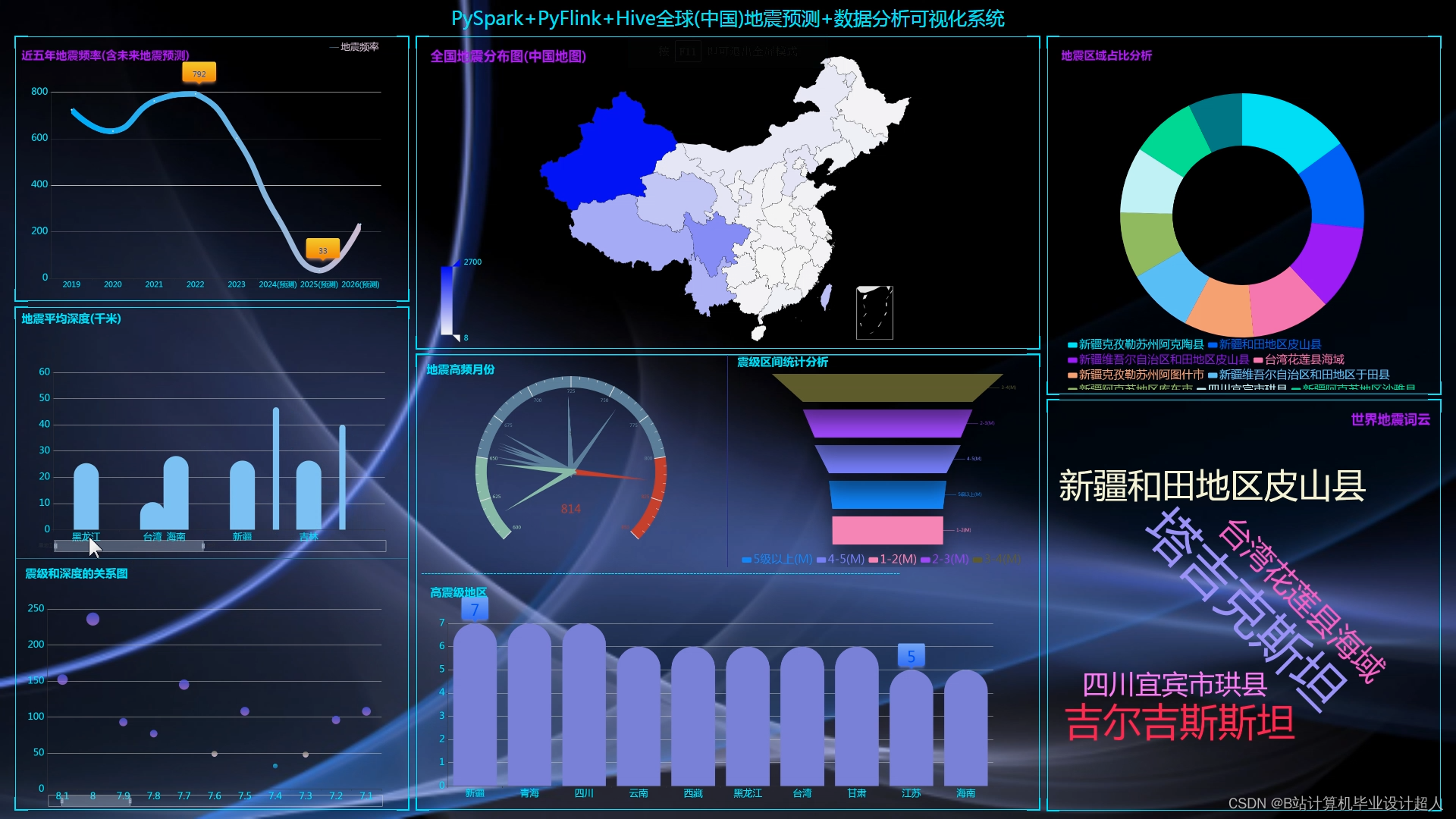
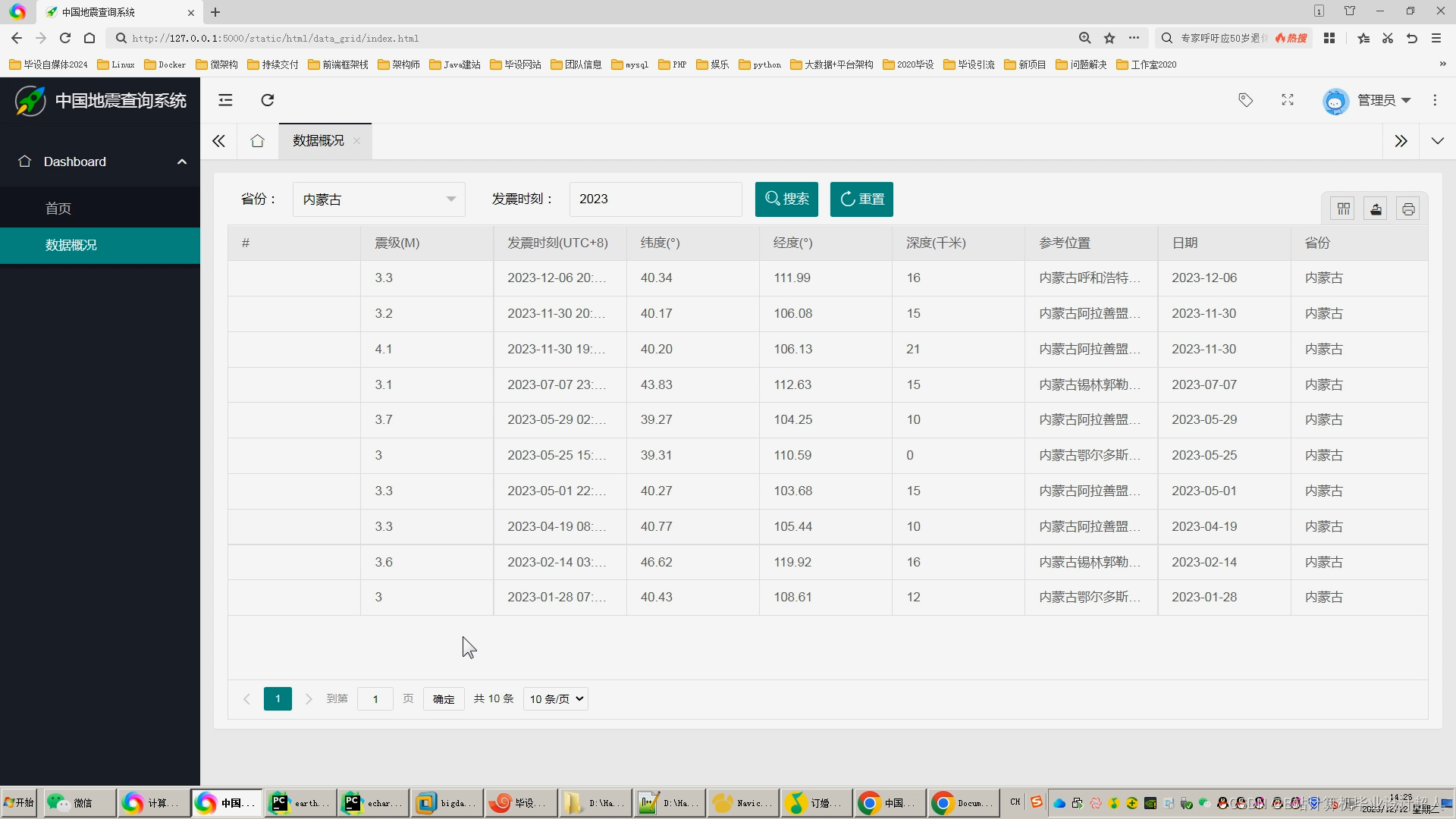
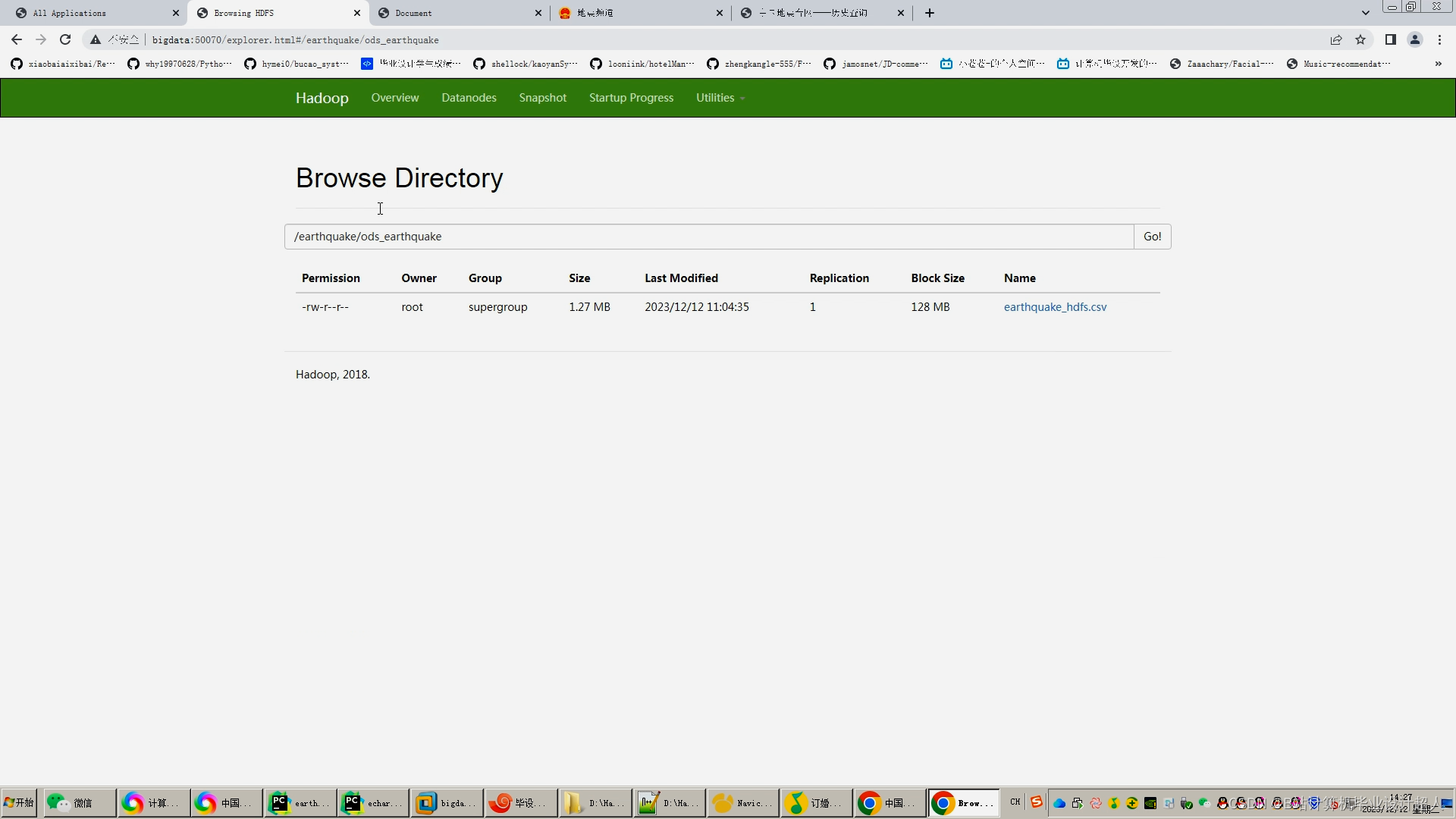
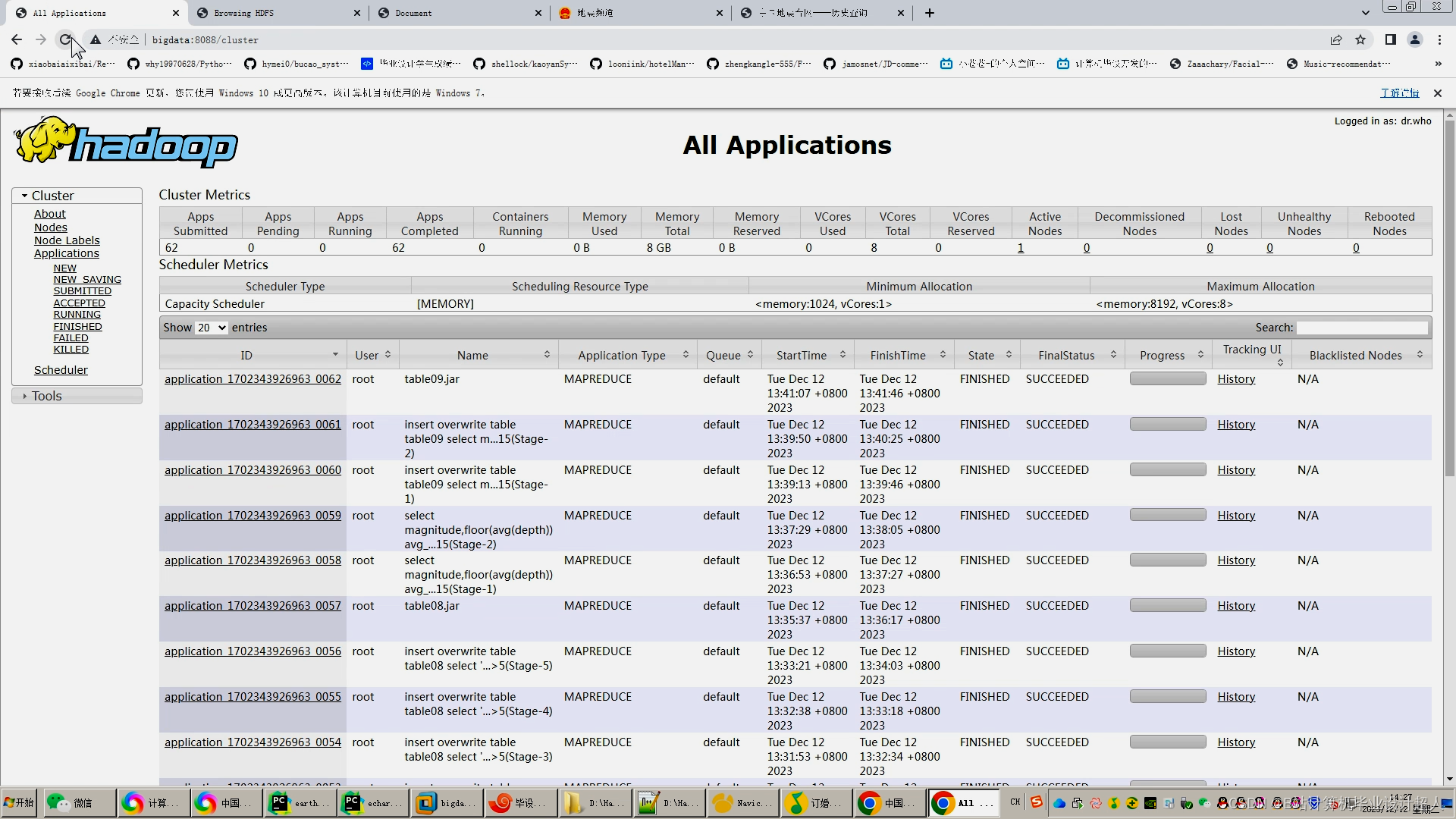
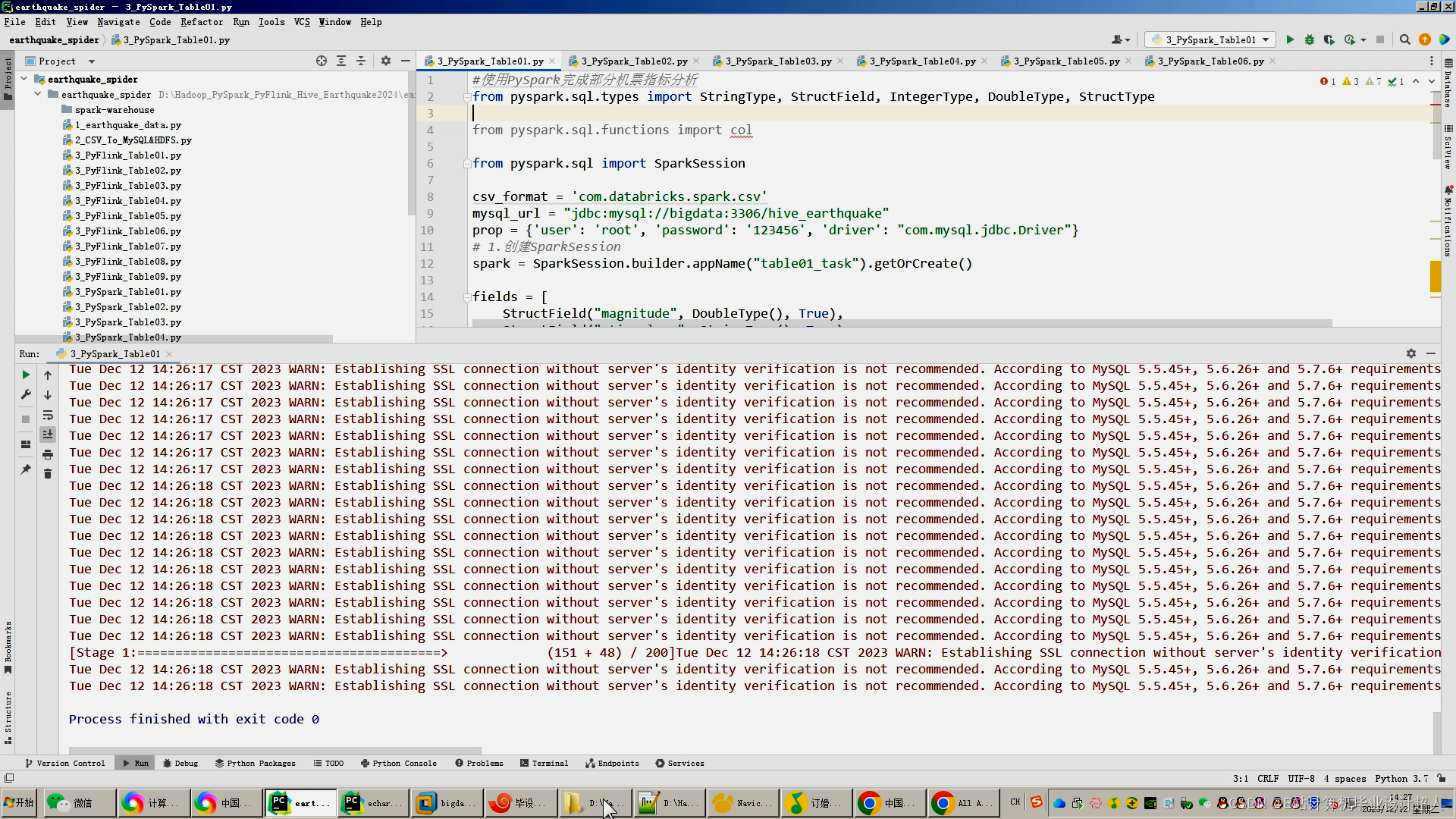
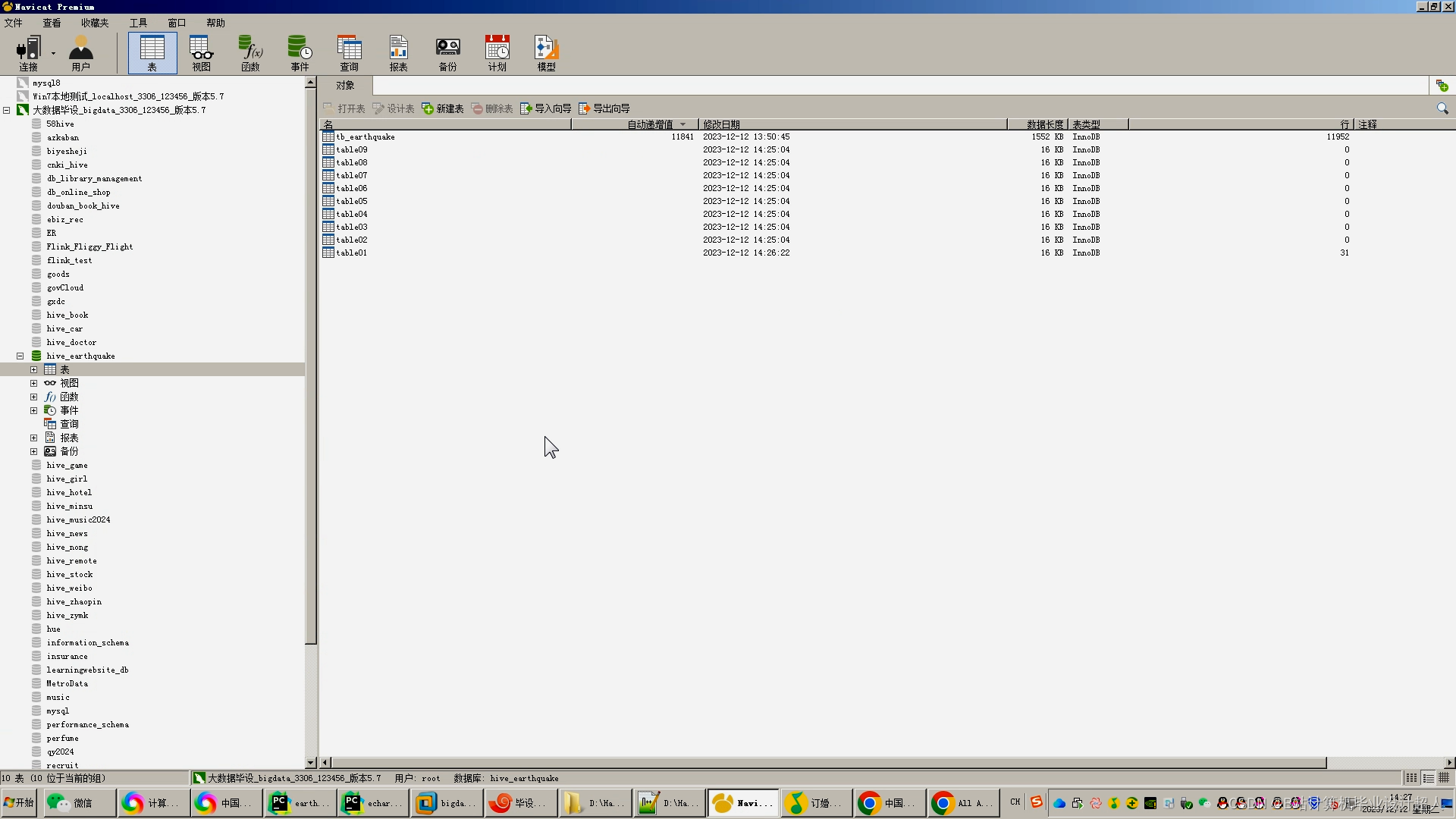
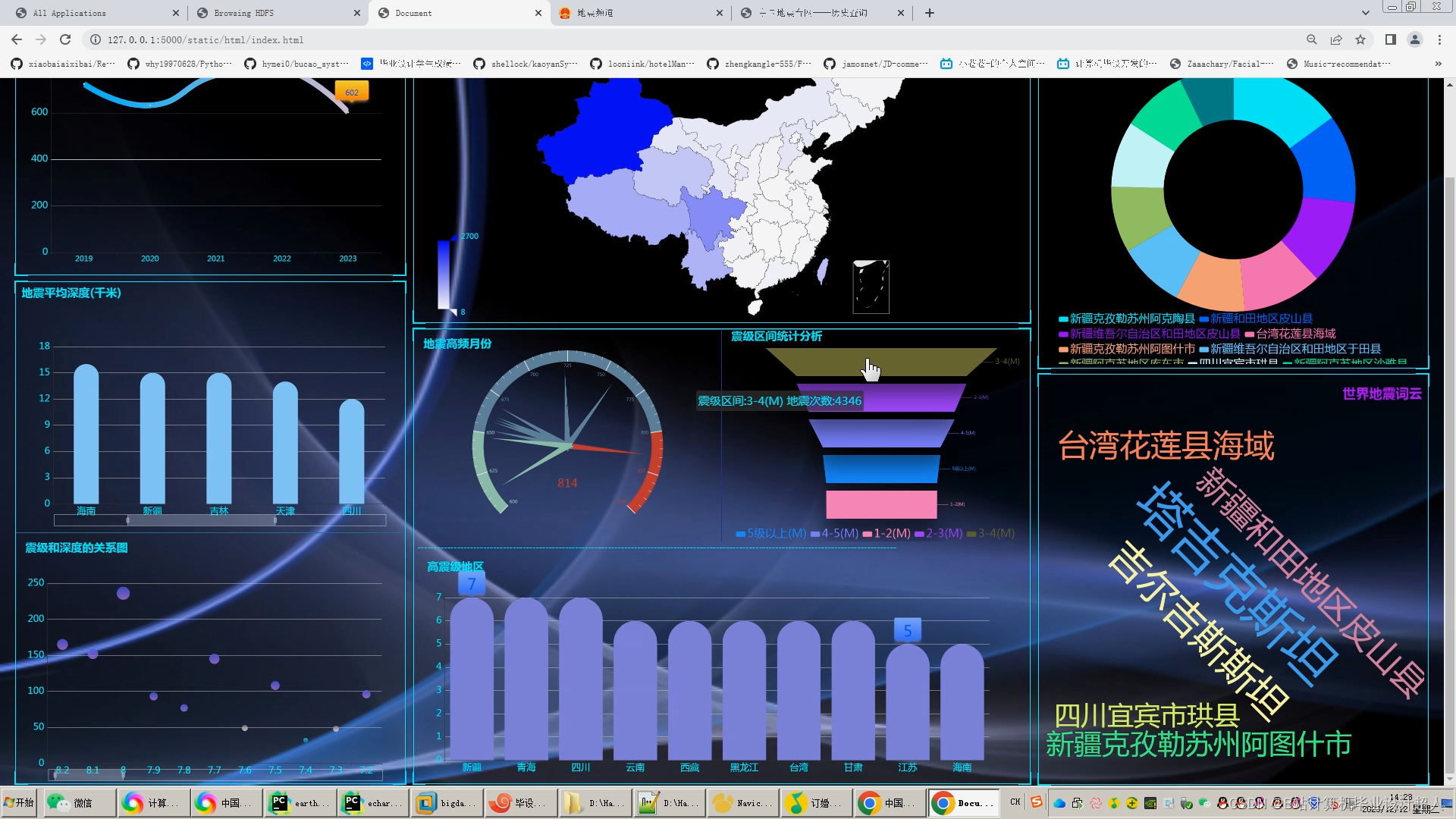
核心预测算法代码如下:
package com.bigdata.storm.kafka.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @program: storm-kafka-api-demo
* @description: redis工具类
* @author: 小毕
* @company: 清华大学深圳研究生院
* @create: 2019-08-22 17:23
*/
public class JedisUtil {
/*redis连接池*/
private static JedisPool pool;
/**
*@Description: 返回redis连接池
*@Param:
*@return:
*@Author: 小毕
*@date: 2019/8/22 0022
*/
public static JedisPool getPool(){
if(pool==null){
//创建jedis连接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接数
jedisPoolConfig.setMaxTotal(20);
//最大空闲连接
jedisPoolConfig.setMaxIdle(5);
pool=new JedisPool(jedisPoolConfig,"node03.hadoop.com",6379,3000);
}
return pool;
}
public static Jedis getConnection(){
return getPool().getResource();
}
/* public static void main(String[] args) {
//System.out.println(getPool());
//System.out.println(getConnection().set("hello","world"));
}*/
} 






