


👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!
1. 换你来当爹:国内第3款爆火出圈的AI游戏应用,hhh 太搞笑了
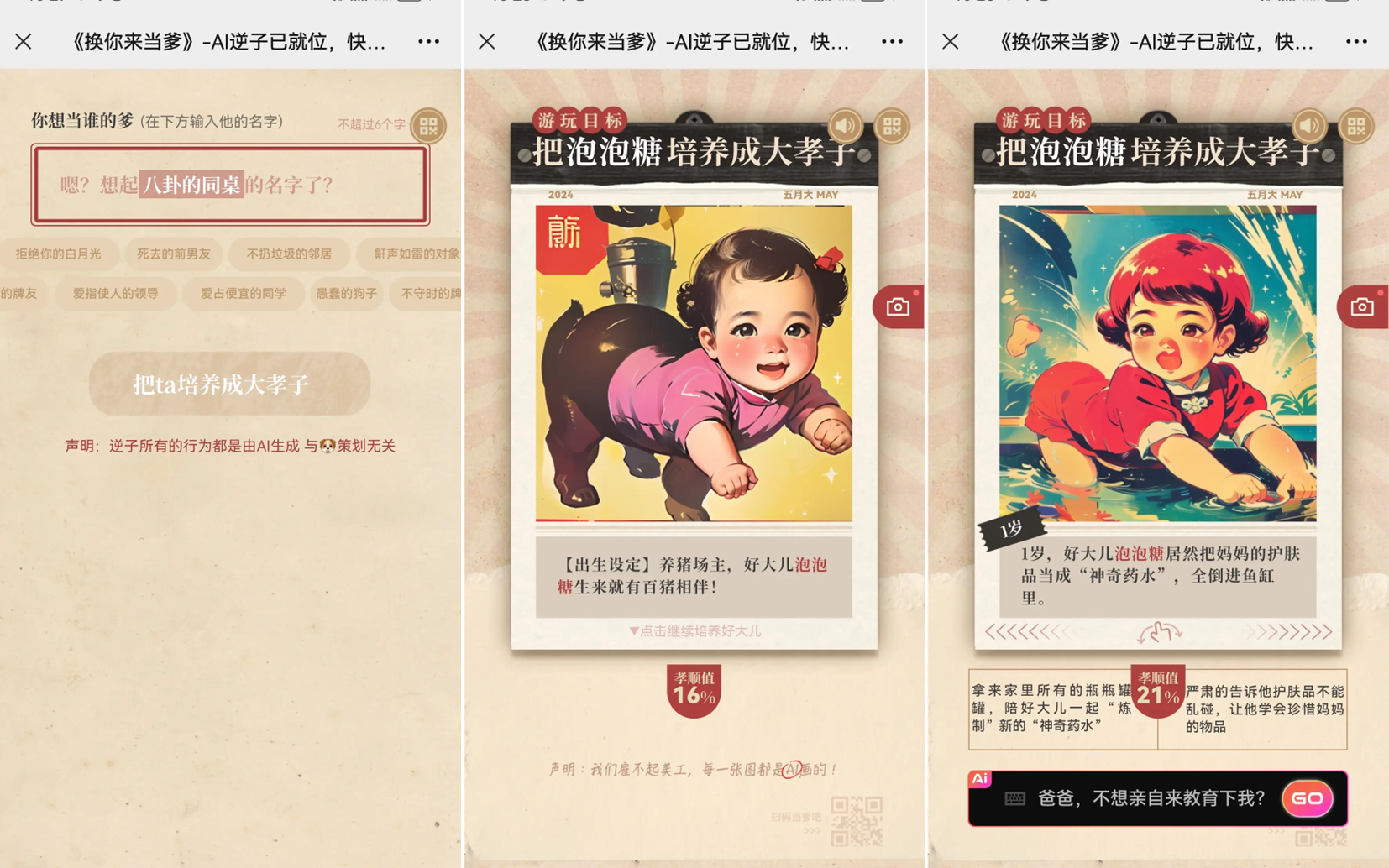
周末的时候,社群里伙伴们开始玩一款「换你来当爹」的AI游戏 🎮
进入游戏界面后,输入名字,系统随机生成孩子的「出生设定」。
然后恭喜你!可以开始当爹了!!
好大儿的培养过程,伴随着各种糟心的意外,然后把难题摆在你面前。
哎呀呀!逆子…
这时,你可以在系统给定的两个选项中选择一个,当然也可以输入自己独特的「教育方式」,让好大儿深刻感受一把父爱。
好消息是,孩子终于长大一岁!
坏消息是,作死花样更多了 😡
孝顺值会随着互动过程增加或减少,达到 88% 可以让好大儿喊出那句「爸爸,您辛苦了!」但这真的很难!你玩一把就知道了~

围观的时候发现大家创意好多!给马云、马斯克、朱啸虎、坤坤当起了爸爸 hhh
而且!游戏的绘画和声音,给体验加分超多!!根据剧情实时生成的复古风海报,更是游戏的一大特色。
这应该是国内继《🎮 完蛋!我被LLM包围了!》《🎮 哄哄模拟器》之后,第三款有趣的AI游戏应用了!
👇 赶紧领取你的 AI 逆子,或者 🎮 点击进入当爹模式

2. 零一万物发布更新,开启「开源赋能生态+闭源探索商业化」双轨模型策略

5月13日,零一万物 ⋙ 发布官方公告,宣布了闭源大模型、开源大模型和 2C 产品方向的最近进展。
🔴 闭源模型
- Yi-Large(千亿参数)表现出色,并已经启动下一代 Yi-XLarge MoE 模型训练(冲击 GPT-5)
🟢 开源模型
- Yi-1.5(34B、9B、6B三个版本),每个版本达到同尺寸中 SOTA 性能最佳,并提供 Yi-1.5-Chat 微调模型
- Hugginf Face → https://huggingface.co/01-ai
- 魔搭社区 → www.modelscope.cn/organization/01ai
🟡 2C产品 - 万知
- 使用方式 https://www.wanzhi.com / 微信小程序
🟣 Yi API 平台
- 网站 https://platform.lingyiwanwu.com
🟤 官网
-
国内版 https://www.lingyiwanwu.com
-
国际版 https://01.AI

李开复教授也一改往日的低调,接受了 ⋙ 晚点LatePost 专访,聊了聊他对零一万物几个热点议题 (创业年龄太大、套壳争议) 的回应,对未来的发展构想 (万亿美元的公司,AGI 时代的微软),以及对当下市场的认知。
这篇采访里有着大量的「常识」,平静却有力量。这可能是他的阅历带来的独特气质。以及,他强调的,推理成本在显著降低。
Some Highlights:
-
PMF 已经不能够完整地定义大模型的创业了,TC-PMF 更合适,也就是还要考虑技术 technology,还要考虑成本 cost,这是一个四维的 fit。每个公司都要找到自己的 TC-PMF。
-
一个利好是,推理成本至少每年会降低十倍,这个过去两年已经发生,未来也会发生。
-
我们最早上线的生产力产品的 ROI 已经可以做到 1 了,也就是我们从用户手中收到的订阅费,已经低于我们获取用户的成本加 GPU 的成本。今年应该会有一个亿的收入,有近千万用户。
-
我们会把 0.6 当作 ROI 的基准线。烧 1 块钱可以回 6 毛钱时,就可以往前推进。一旦推到了 1 ,就表示增长还可以更激进。低于0.6 烧得越多,亏得越多,而且几乎不会有结果。
-
有些友商投放了几千万美元,烧出了几百万 DAU,如果他们有信心让用户走了又能回来,那是他们自己的策划。我们认为做应用就是按部就班:一方面你要又狠又准,在正确的时刻出手,把握时间窗口;另一方面,当这个窗口还没来时,我们选择不过度烧钱,因为赔钱的速度是完全可以预测的。
-
美国大厂的计算资源是我们的几十倍、一百倍。我们前段时间聊的一个博士最后决定去一个美国公司,因为对方答应给他 10000 张 GPU,我们谁都没有 10000 张 GPU。
3. 不要低估 DeepSeek 这次更新!它是一轮巨变开启的前兆

AI社区对 DeepSeek V2 这次更新,似乎反应平平?
大概率是因为它的模型能力还不足够「惊艳」。
但是!我们需要关注到一个离谱的事实:DeepSeek v2 在能力逼近第一梯队闭源模型的前提下,推理成本降到了1块钱per million token,只有 Llama 3 (70B) 的 1/7,GPT-4 Turbo 的 1/70。而且完全开源!!
推理成本的急剧降低,将为整个大模型生态,带来巨大的变化:
-
推理成本下降的速度严重超出预期。在算力没有升级的情况下,过去一年的推理成本已经降低了2个数量级,明年部署 GB200 会再进一步大幅降低。这会催生当下还无法预测的架构创新、推理优化、系统升级、甚至推理集群计算架构方面的黑科技
(而且可能是诞生在国内)。
-
短时间内,模型优化导致的算力节约,将大于需求撬动的算力增量。成本节约 - 应用爆发 - 需求增加 - 拉升算力需求…… 会导致一连串复杂的连锁反应。
-
有一点肯定,准备迎接应用爆发吧。
-
根据各方消息,OpenAI GPT-5 的架构创新以及对计算复杂度的优化,一点也不会比国内少。下一代模型除了能力提升,成本的降低(相对而言)很可能会超出大家的预期 ⋙ 阅读原文
4. 朱啸虎:AI应用明年肯定大爆发,应用赚的钱是硬件/基础设施的10倍

朱啸虎是金沙江创投主管合伙人,作为知名投资人,曾投出阿里、京东、美团、拼多多,当然也遗憾地错过了字节。
4月份,⋙ 朱啸虎讲了一个中国现实主义AIGC故事 这次访谈在AI圈和投资圈引发热议。他毫不避讳地展示了对大模型投资圈无脑跟风的鄙夷,阐述了当下中国大模型初创公司的生存窘境,也给出了他对开闭源之争、中美差距、国内外大模型公司终局的确切判断,还有对应用层创业的无限热忱和确信。
5月8日,在投中网举办的年度峰会上,朱啸虎再次表达了对「AI应用爆发」的确信。这与👆 上一条「推理成本降低 → 应用即将大爆发」的判断,可谓殊途同归 ⋙ 阅读原文
-
中国VC和美国VC很大差别似乎是美国VC过去几十年很明确,基本是十年一个周期,中国的VC过去20年都习惯短周期——每三年一个周期…(将来)中国的VC可能要习惯十年的长周期期限。
-
我们一直在关注AI的应用,且只关注能够商业化的、能够实现PMF的 AIGC 应用。而且,明年这个时间点上,AI应用肯定会大爆发。
-
每个周期一开始,都是硬件和基础设施赚的钱多一点,但到周期的后面就是应用。应用赚的钱是前面的10倍以上。
-
边缘端的开源小模型必然是未来方向,这里面商业机会特别多。
-
Sam Altman在吹牛逼,GPT-5 肯定没那么惊艳,或者惊艳与否已经不重要了。GPT-4 已经满足了绝大部分的商业需求了。
5. 我研究了40款AI热门应用:发现了它们「定价策略」里隐藏的智慧和心机
这篇文章 ⋙ How AI apps make money 探讨的主题非常有意思——当下热门的AI原生应用,是怎么收钱的呢?具体来说就是,这些应用的「定价策略」是怎样的?什么模式更有利于让用户付费?未来还有可能诞生哪些新的模式?
作者根据公开榜单、外部融资信息、公开信息等,审查了有关定价模式、价值指标、套餐、免费版本和定价透明度的公开数据。最终敲定了 40 款知名 的AI 应用,并梳理了它们的详细信息 ⋙ 中文翻译版本

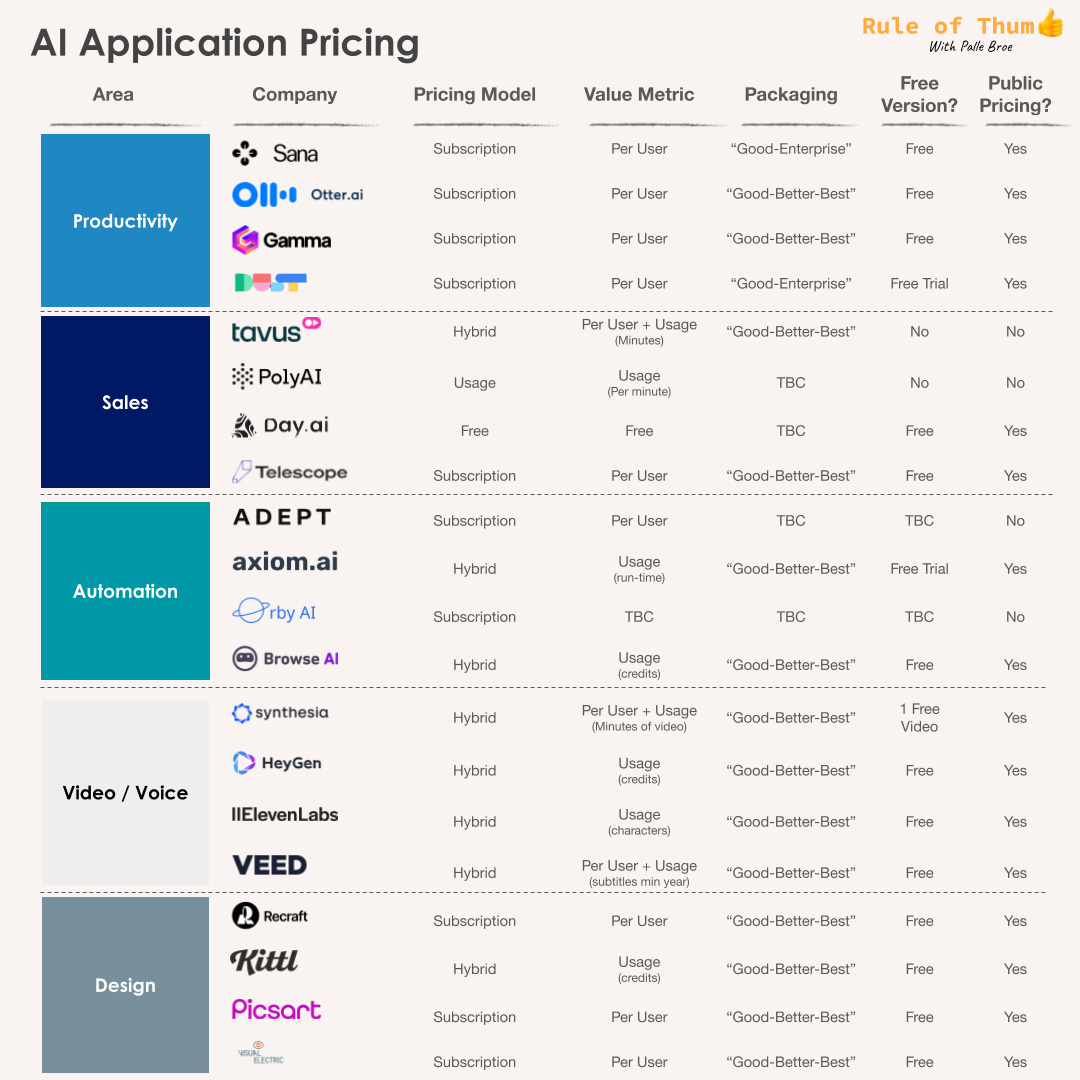
这 40 款产品覆盖了法律、健康、市场、生产力、销售、自动化、音视频、设计等领域。研究发现的 5 条明显规律:
-
定价模式的创新有限: 七成公司采用订阅模式,纯用量付费模式寥寥无几。
-
以用户数量为主要的计费指标: 这反映了 AI 应用作为「副驾驶」辅助人类工作的定位。
-
免费版本和试用期普遍存在: 超过一半的公司提供免费版本,另有五分之一提供免费试用,以促进用户早期采用。
-
「好-更好-最好」套餐模式: 这种模式为用户提供不同功能和服务级别的选择,并为企业创造清晰的升级路径。
-
定价透明度差异较大: 三分之二的公司公开定价,而企业级应用则更倾向于隐藏定价以保持竞争优势和灵活性。
从中可以观察到,AI 应用定价模式的创新趋势
-
以成果为导向的定价模式:客户只需为成功的结果付费,例如成功的交易结算、问题的解决、生成的文档等等。这将推动 AI 应用与客户建立双赢的合作伙伴关系,并加速产品的普及。
-
探索新的计费指标: 用户量可能不适合继续作为计费指标。AI 应用需要探索新的计费指标,例如处理的数据量、生成的文本或代码量、节省的时间或成本等等。
6. 各国AI 初创公司数量 · 全球排行榜:美国一骑绝尘,中英紧随其后
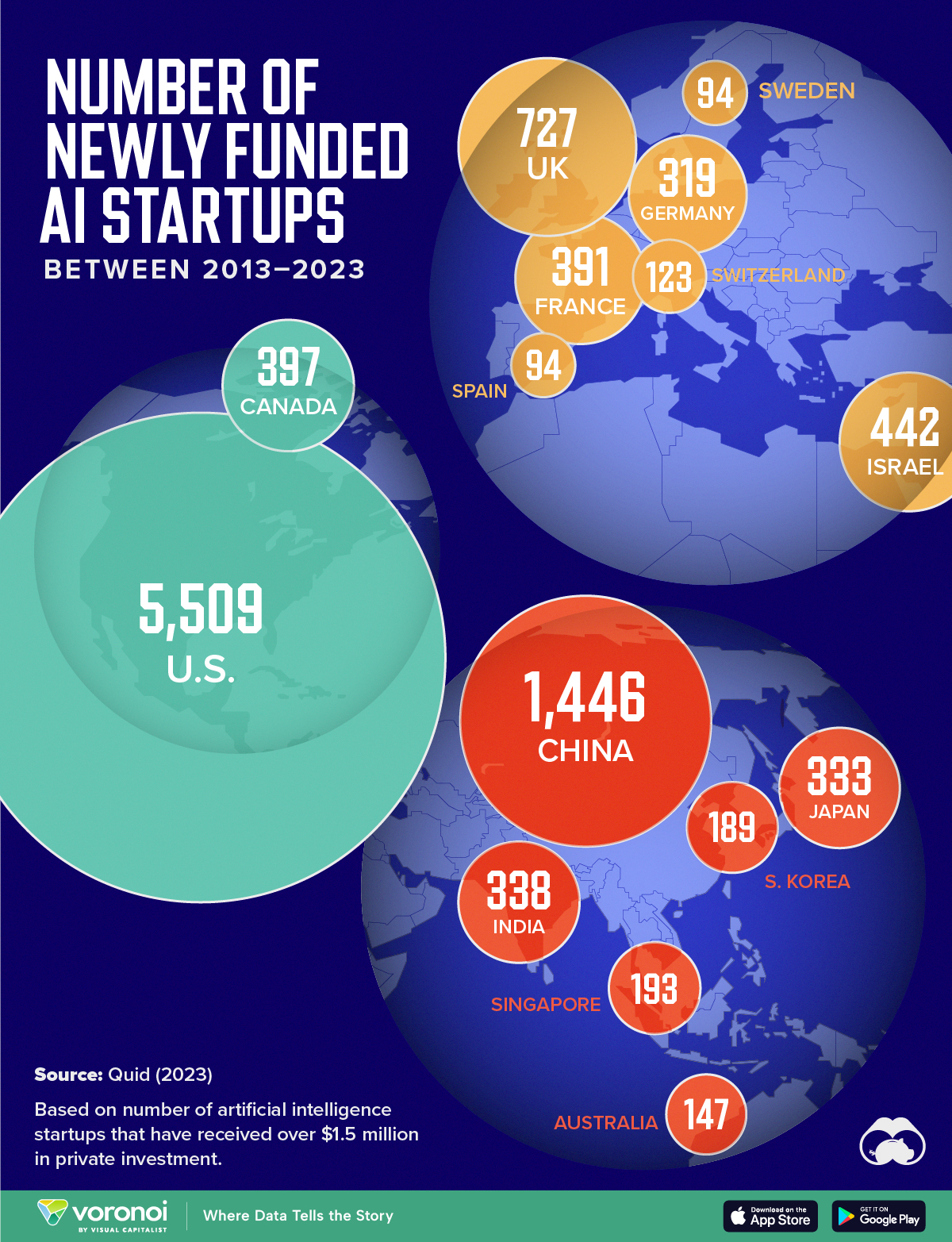
⋙ Voronoi 平台 基于斯坦福大学2024年AI指数报告中Quid的数据,分析出了过去 10 年间,全球AI创业最活跃的 15 个国家。
注意!数据是2013年至2023年间,各国新获得资金支持的AI初创公司的数量。仅将获得超过150万美元私人投资的公司纳入考量。
- United States | 美国 5,509
- China | 中国 1,446
- United Kingdom | 英国 727
- Israel | 以色列 442
- Canada | 加拿大 397
- France | 法国 391
- India | 印度 338
- Japan | 日本 333
- Germany | 德国 319
- Singapore | 新加坡 193
- South Korea | 韩国 189
- Australia | 澳大利亚 147
- Switzerland | 瑞士 123
- Sweden | 瑞典 94
- Spain | 西班牙 94
7. 训练大模型到底要用多少数据?人类数据还够用吗?
根据公开信息,整理了 LlaMa 3 和 GPT-4 大模型训练集的大小。为了方便大家有个直观的感受,附上人类 5 岁和 20 岁时的习得的文本数量。
Training Set (Words) Training Set (Tokens) 相对大小 (Llama 3 = 1) Recent LLMs Llama 3 11 trillion 15T 1 GPT-4 5 trillion 6.5T 0.5 Humans Human, age 5 30 million 40 million 10^-6 Human, age 20 150 million 200 million 10^-5 一直有消息说,目前的大模型训练,已经几乎耗尽了人类积累的高质量文本。更恐怖的是,训练下一代大模型需要的数据量是之前的 10 倍。
数据会用完吗?没有数据了怎么办? 仔细盘了盘人类的数据「库存」! ⋙ 点击查看各部分数据的详细解释
可以得出的基本结论是:高品质的、公开的数据规模是有上限的;私有数据流规模庞大,但在商业化应用方面有诸多限制;未来的大模型训练可能更多依赖于合成数据。
Words Tokens 相对大小(Llama 3 = 1) 📀 网络数据 优质网络数据 11 trillion 15T 1 高质量非英文网络数据 13.5 trillion 18T 1 📀 代码 公共代码 – 0.78T 0.05 私有代码 – 20T 1.3 📀 学术出版物和专利 学术文章 800 billion 1T 0.07 专利 150 billion 0.2T 0.01 📀 书籍 Google Books 3.6 trillion 4.8T 0.3 Anna’s Archive (books) 2.8 trillion 3.9T 0.25 每本独特的书 16 trillion 21T 1.4 📀 社交媒体 推特/X 8 trillion 11T 0.7 微博 29 trillion 38T 2.5 脸书 105 trillion 140T 10 📀 公开可用的音频 (转录) YouTube 5.2 trillion 7T 0.5 TikTok 3.7 trillion 4.9T 0.3 所有播客 560 billion 0.75T 0.05 电视档案 50 billion 0.07T 10^-3 广播档案 500 billion 0.6T 0.04 📀 私人数据 所有存储的即时消息 500 trillion 650T 45 所有存储的电子邮件 900 trillion 1200T 80 📀 总人类通信 每日总人类通信 115 trillion 150T 10 1800年以来的总人类通信 3 million trillion 4000000T 10^5 有史以来的总人类通信 6 million trillion 8000000T 10^5 
◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ > 前往 🎡ShowMeAI,获取结构化成长路径和全套资料库,用知识加速每一次技术进步!
-
-
-
- 网站 https://platform.lingyiwanwu.com
- 使用方式 https://www.wanzhi.com / 微信小程序







