

文章目录
- 向量数据库
- 概述
- 可用实现
- 示例用法
- 元数据过滤器
- Filter String
- Filter.Expression
- 理解向量
向量数据库
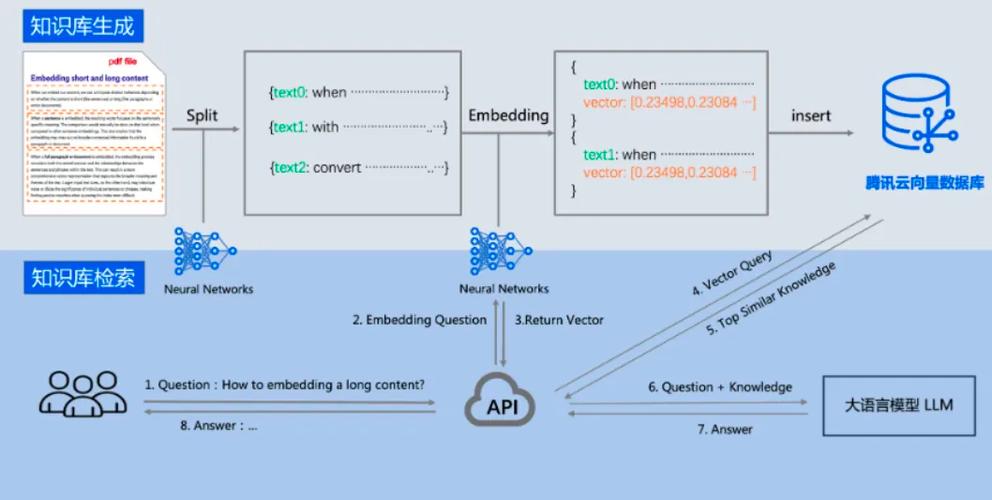
向量数据库是一种在 AI 应用中发挥关键作用的特定类型的数据库。
 (图片来源网络,侵删)
(图片来源网络,侵删)在向量数据库中,查询与传统关系数据库不同。它们不执行精确匹配,而是执行相似性搜索。当以向量作为查询时,向量数据库返回与查询向量“相似”的向量。有关如何在高层次计算此相似性的更多详细信息,请参阅 向量相似性 。
向量数据库用于将您的数据与 AI 模型集成。它们的使用的第一步是将您的数据加载到向量数据库中。然后,当用户查询要发送到 AI 模型时,首先检索一组相似的文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。这种技术被称为检索增强生成(RAG)。
 (图片来源网络,侵删)
(图片来源网络,侵删)以下部分描述了 Spring AI 接口,用于使用多个向量数据库实现和一些高级示例用法。
最后一部分旨在揭示向量数据库中相似搜索的基本方法。
概述
本节作为 Spring AI 框架中VectorStore接口及其关联类的指南。
Spring AI 通过VectorStore接口为向量数据库交互提供了抽象化的 API。
这里是 VectorStore 接口的定义:
public interface VectorStore { void add(List documents); Optional delete(List idList); List similaritySearch(String query); List similaritySearch(SearchRequest request); }和相关的 SearchRequest 构建器:
public class SearchRequest { public final String query; private int topK = 4; private double similarityThreshold = SIMILARITY_THRESHOLD_ALL; private Filter.Expression filterExpression; public static SearchRequest query(String query) { return new SearchRequest(query); } private SearchRequest(String query) { this.query = query; } public SearchRequest withTopK(int topK) {...} public SearchRequest withSimilarityThreshold(double threshold) {...} public SearchRequest withSimilarityThresholdAll() {...} public SearchRequest withFilterExpression(Filter.Expression expression) {...} public SearchRequest withFilterExpression(String textExpression) {...} public String getQuery() {...} public int getTopK() {...} public double getSimilarityThreshold() {...} public Filter.Expression getFilterExpression() {...} }要将数据插入向量数据库,请将其封装在Document对象中。Document类封装来自数据源(如 PDF 或 Word 文档)的内容,并包含表示为字符串的文本。它还包含键值对形式的元数据,包括文件名等详细信息。
插入向量数据库时,文本内容会被转换为数值数组,或称为向量嵌入。嵌入模型,如 Word2Vec、GLoVE 和 BERT,或 OpenAI 的text-embedding-ada-002,将单词、句子或段落转换为这些向量嵌入。
向量数据库的作用是存储和促进这些嵌入的相似性搜索。它本身不生成嵌入向量。要创建嵌入向量,应该使用EmbeddingClient。
接口中的similaritySearch方法允许检索与给定查询字符串类似的文档。可以通过使用以下参数来对这些方法进行微调:
- k:一个整数,指定要返回的相似文档的最大数量。这通常被称为“top K”搜索,或“K 最近邻”(KNN)。
- threshold:一个从 0 到 1 范围的双精度值,值越接近 1 表示相似度越高。默认情况下,如果您设置了 0.75 的阈值,那么只有相似度高于此值的文档才会被返回。
- Filter.Expression:用于传递类似于 SQL 中的“where”子句的流畅 DSL(领域特定语言)表达式的类,但它仅适用于Document的元数据键值对。
- filterExpression:基于 ANTLR4 的外部 DSL,接受过滤表达式作为字符串。例如,对于像 country、year 和isActive这样的元数据键,您可以使用如下表达式:country == ‘UK’ && year >= 2020 && isActive == true.
在 Metadata Filters 部分查找有关Filter.Expression的更多信息。
可用实现
这些是VectorStore接口的可用实现:
- Azure Vector Search - Azure 向量存储。
- ChromaVectorStore - Chroma 向量存储。
- MilvusVectorStore - Milvus 向量存储。
- Neo4jVectorStore - Neo4j 向量存储。
- PgVectorStore - PostgreSQL/PGVector 向量存储。
- PineconeVectorStore - PineCone 向量存储。
- QdrantVectorStore - Qdrant 向量存储。
- RedisVectorStore - Redis 向量存储。
- WeaviateVectorStore - Weaviate 向量存储。
- SimpleVectorStore - 一个简单的持久化向量存储实现,适用于教育目的。
未来版本可能支持更多的实现。
如果您需要由 Spring AI 支持的向量数据库,请在 GitHub 上提出问题,或者更好地,提交一个实现的拉取请求。
每个VectorStore实现的信息可以在本章的子章节中找到。
示例用法
要为向量数据库计算嵌入向量,您需要选择与 AI 模型相匹配的嵌入向量模型。
例如,使用OpenAI的ChatGPT,我们使用OpenAiEmbeddingClient和名称为text-embedding-ada-002的模型。
Spring Boot starter 的自动配置可以在 Spring 应用程序上下文中生成一个EmbeddingClient的实现,以便进行依赖注入。
一般通过类似批处理作业的方法将数据加载到向量存储中,首先将数据加载到 Spring AI 的Document类中,然后调用save方法。
给定一个指向我们要加载到向量数据库中的数据 JSON 文件的源文件的 String 引用,我们使用 Spring AI 的 JsonReader 来加载 JSON 中的特定字段,将它们拆分成小块,然后将这些小块传递给向量存储实现。 VectorStore 实现计算嵌入向量并将 JSON 和嵌入向量存储在向量数据库中:
@Autowired VectorStore vectorStore; void load(String sourceFile) { JsonReader jsonReader = new JsonReader(new FileSystemResource(sourceFile), "price", "name", "shortDescription", "description", "tags"); List documents = jsonReader.get(); this.vectorStore.add(documents); }然后,当用户问题传递到 AI 模型时,会进行相似性搜索以检索类似的文档,然后将这些文档“填充”到提示中,作为用户问题的上下文。
String question = List similarDocuments = store.similaritySearch(question);
可以将附加选项参数传递到similaritySearch方法中,以定义要检索多少个文档以及相似性搜索的阈值。
元数据过滤器
本节描述了您可以针对查询结果使用的各种过滤器。
Filter String
您可以将类似于 SQL 的过滤表达式作为String传递给其中一个similaritySearch重载类。
请参考以下示例:
* "country == 'BG'" * "genre == 'drama' && year >= 2020" * "genre in ['comedy', 'documentary', 'drama']"
Filter.Expression
您可以使用流式 API 的 FilterExpressionBuilder 创建 Filter.Expression 的实例。一个简单的示例如下:
FilterExpressionBuilder b = new FilterExpressionBuilder(); Expression expression = b.eq("country", "BG").build();您可以通过使用以下运算符来构建复杂的表达式:
EQUALS: '==' MINUS : '-' PLUS: '+' GT: '>' GE: '>=' LT: '







