

- 大家都知道,这些大模型都是一些单元如此的重复堆叠而已,那么这个单元到底长什么样子呢?
- 在这里,本张大帅就给你们解释的一清二楚!如果看完了我说的,你还是糊里糊涂的,请在评论区留言来打我!
- 我们姑且称呼这个单元叫做transfomer block吧!
- 首先这个transfomer block有一个输入,这个输入的shape是啥呢?
- 那就是[batch_size, seq_len, hidden_dim]
- batch_size就是表示批量大小啊!
- seq_len就是序列长度啊!
- hidden_dim这个大家意会一下啊!
- 但是要注意啊,网友们,每个batch的seq_len其实常常是不一样的,这个你在心里面要记得注意啊
- 例如batch0其实seq_len是10,batch1的seq_len是20,batch2的seq_len是30
- 但是我们这里把他写成统一的按照最大长度30,
- 但是你需要在心里知道batch0其实有效长度是10哦,batch1的有效长度是20!
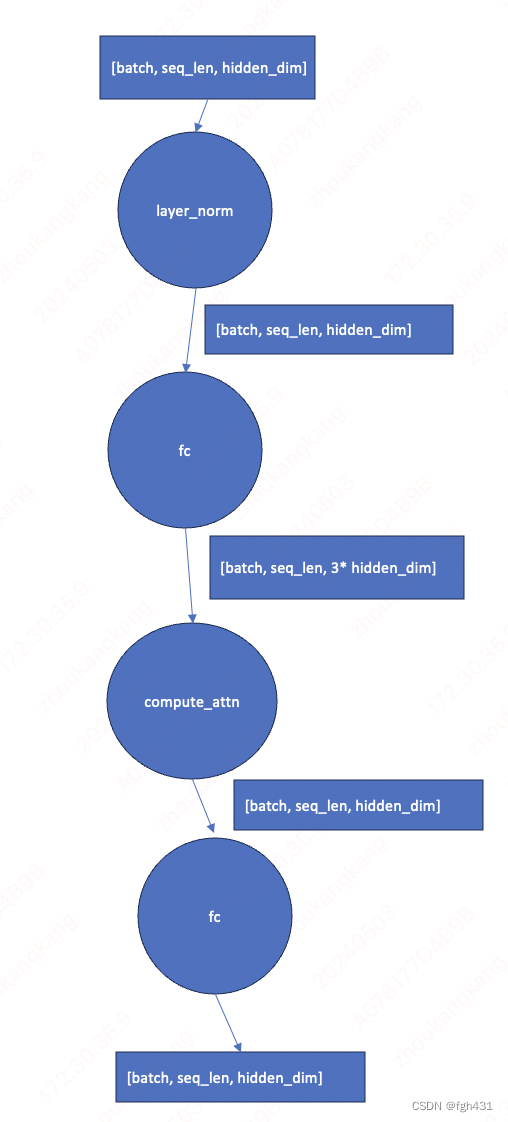
- transfomer block里面的第一个运算是啥呢?
- 是个layer_norm啦!这个Op是不改变tensor的shape的!
- 然后是一个Fc Op,那么权重的shape是啥呢?其实就是[hidden_dim , 3 * hidden_dim]
- 也就是经过这个Op后,输出tensor的shape是[batch_size, seq_len, 3 * hidden_dim]
- 这个难吗?这个很简单啊!
- 也就是说目前

- 各位看官你们看,上面的难嘛?一点也不难啊!
- 下面继续运算,拿着这个[batch_size, seq_len, 3 * hidden_dim]的tensor继续往下运算,下面的运算是个很牛的运算方式
- 首先将它split成三份,QKV,shape分别都是[batch_size, seq_len, hidden_dim]
- 然后三个东西都reshape成[batch_size, seq_len, num_head, head_dim]
- 也就是num_head * head_dim = hidden_dim
- 到目前为止,各位看官还有疑惑吗?我相信都是没有的!
- 然后再将QKV都transpose成[batch_size, num_head, seq_len, head_dim]
- 接下来就是最关键的点,attention运算!
- 先用Q和K做矩阵乘法,这个矩阵乘法其实是batch matmul,就是torch.matmul(Q,K.transpose([0,1,3,2]))
- 得到的tensor shape是[batch_size, num_head, seq_len, seq_len]
- 然后除以一个sqrt(head_dim)
- 然后有时候,还会再加上一个attn_mask,他的shape呢就是[batch_size, num_head, seq_len, seq_len]
- 接着来一个softmax,得到attention_weight
- 也就是attn_weight = softmax(torch.matmul(Q,K.transpose([0,1,3,2])) / sqrt(head_dim) + attn_mask)
- 至此我们得到了最终的attn_weight!
- 最后再用attn_weight和V进行矩阵乘法得到最终的输出tensor!
- 最终tensor的shape是[batch_size, num_head, seq_len, head_dim]
- 最后记得把他transpose成[batch_size, seq_len, num_head, head_dim]
- 然后再reshape成[batch_size, seq_len, hidden_dim]
- 至此上面的运算过程就完成了!
- 我们把他叫做attention计算过程!
- 目前图变成下面这样啦!

- attention层出来之后的shape就是[batch_size, seq_len, hidden_dim]
- 然后呢,再来一个全联接层,权重shape是[hidden_dim,hidden_dim]
- 所以出来的tensor shape还是[batch_size, seq_len, hidden_dim]
- 至此,模型的图如下图所示。
- 最后,来一个牛逼哄哄的add操作
- 图变成下面这样啦!
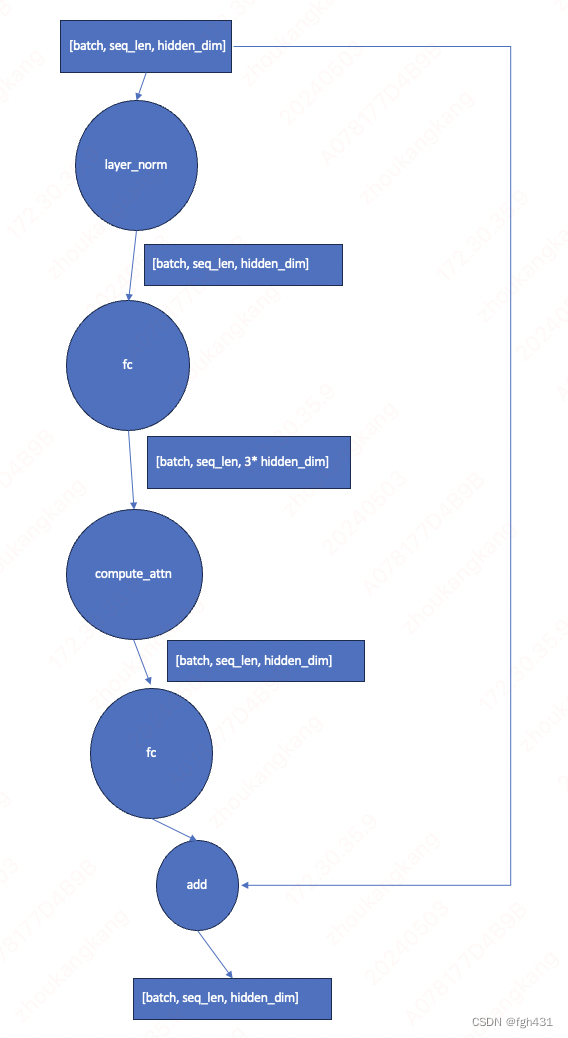
各位老板请注意,上面的两个fc模块到底有没有bias,取决于每个模型的不同,有可能有,也有可能没有!
- 下面的几个操作其实都是简单的啦!
- 首先再来一个layer_norm操作!然后接着是一个fc操作!权重是[hidden_dim, intermediate_size]
- 这个 intermediate_size 一般都是比hidden_dim大很多的!
- 然后就是激活啦!
- 然后又是另一个fc,权重是[intermediate_size, hidden_dim]
- 最后是一个性感的Add操作
- 也就是下面的图片的这样,至此我们就把到底啥是transformer block给讲完了!
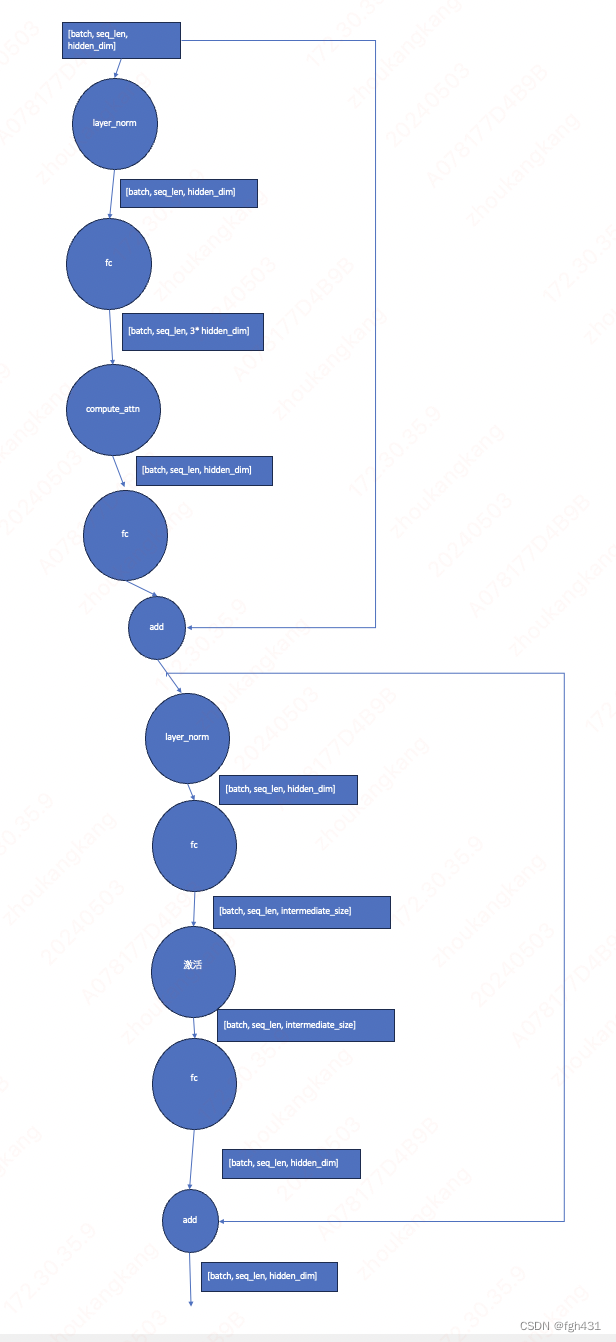
总结一下
- transformer block的输入是[batch_size, seq_len, hidden_dim],输出也是这么大,因此可以很方便的堆叠起来,例如把40个这样的block串起来!
高性能变长推理
- 看官你好,上面的 transformer block的输入shape是[batch_size, seq_len, hidden_dim],但是由于不同的batch的seq_len是不一样的,因此这样搞肯定比较冗余!
- 例如此时有3个batch,seq_len分别是10,20,30,原本的方案是将输入的shape搞成[3,30,hidden_dim]。
- 我们观察transformer block发现一个细节,也就是除了compute_attn模块外,
- 其他的计算单元都是不操纵batch和seq_len维度的!例如layer_norm,fc等
- 而只操纵hidden_dim维度的!
- 也就是说,对于fc op,我们可以将输入只看成2维,对于layer_norm也是如此
- 对于add操作,我们甚至可以将输入只看成1维
- 这样我们只需要将输入搞成[10+20+30, hidden_dim]这么大的输入即可!
- 但是在算compute_attn模块时候,我们需要额外传入seq_lens=[10,20,30]即可!
- 如此就实现了变长推理了!
- 对于add操作,我们甚至可以将输入只看成1维
- transformer block的输入是[batch_size, seq_len, hidden_dim],输出也是这么大,因此可以很方便的堆叠起来,例如把40个这样的block串起来!
- 各位看官你们看,上面的难嘛?一点也不难啊!
- transfomer block里面的第一个运算是啥呢?
- 首先这个transfomer block有一个输入,这个输入的shape是啥呢?







