

RAG(檢索增強生成)系統的新評估似乎每天都在發布,其中許多都集中在有關框架的檢索階段。然而,生成方面——模型如何合成和表達這些檢索到的信息,在實踐中可能具有同等甚至更大的意義。許多實際應用中的案例證明,系統不僅僅要求從上下文中返回事實數據,還需要将這些事實合成一個更複雜的響應。
針對GPT-4、Claude 2.1和Claude 3 Opus(https://www.anthropic.com/news/claude-3-family)三種模型的生成能力進行了評估和比較。本文将詳細介紹研究方法、研究結果以及在此過程中遇到的這些模型的細微差别,并說明爲什麽這些内容對使用生成式人工智能進行構建的人來說非常重要。
有興趣的讀者如果想重現上述實驗的結果,那麽實驗中所需的一切都可以從GitHub存儲庫(https://github.com/Arize-ai/LLMTest_NeedleInAHaystack)中找到。
補充說明
- 盡管最初的發現表明Claude的性能優于GPT-4,但随後的測試表明,随着戰略提示工程技術的出現,GPT-4在更廣泛的評估中表現出了卓越的性能。總之,RAG系統中固有的模型行爲和提示工程當中還存在很多的問題。
- 隻需在提示模闆中簡單地添加一句“請解釋自己,然後回答問題”,即可顯著提高(超過兩倍)GPT-4的性能。很明顯,當LLM說出答案時,這似乎有助于進一步展開有關想法。通過解釋,模型有可能在嵌入/注意力空間中重新執行正确的答案。
RAG階段與生成的重要性

圖1:作者創建的圖表
雖然在一個檢索增強生成系統中檢索部分負責識别和檢索最相關的信息,但正是生成階段獲取這些原始數據,并将其轉換爲連貫、有意義和符合上下文的響應。生成步驟的任務是合成檢索到的信息,填補空白信息,并以易于理解和與用戶查詢相關的方式呈現。
在許多現實世界的應用中,RAG系統的價值不僅在于它們定位特定事實或信息的能力,還在于它們在更廣泛的框架内集成和情境化信息的能力。生成階段使RAG系統能夠超越簡單的事實檢索,并提供真正智能和自适應的響應。
測試#1:日期映射
我們運行的初始測試包括從兩個随機檢索的數字中生成一個日期字符串:一個表示月份,另一個表示日期。模型的任務是:
- 檢索随機數#1
- 隔離最後一位并遞增1
- 根據結果爲我們的日期字符串生成一個月
- 檢索随機數#2
- 從随機數2生成日期字符串的日期
例如,随機數4827143和17表示4月17日。
這些數字被放置在不同深度的不同長度的上下文中。模型最初在完成這項任務時經曆了相當困難的時期。
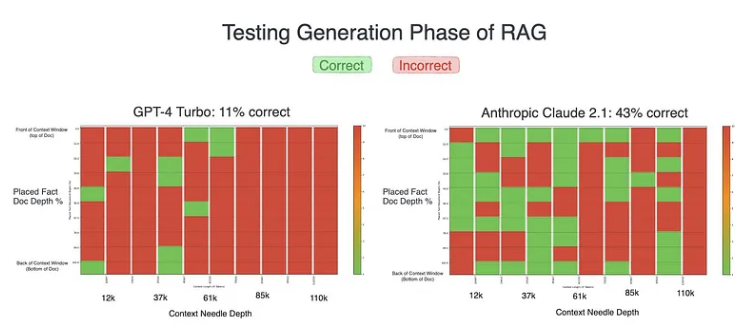
圖2:初始測試結果
雖然這兩個模型都表現不佳,但在我們的初步測試中,Claude 2.1的表現明顯優于GPT-4,成功率幾乎翻了四倍。正是在這裏,Claude模型的冗長本性——提供詳細、解釋性的回答——似乎給了它一個明顯的優勢,與GPT-4最初簡潔的回答相比,結果更準确。
在這些意想不到的實驗結果的推動下,我們在實驗中引入了一個新的變量。我們指示GPT-4“解釋自己,然後回答問題”,這一提示鼓勵了類似于Claude模型自然輸出的更詳細的響應。因此,這一微小調整的影響還是深遠的。
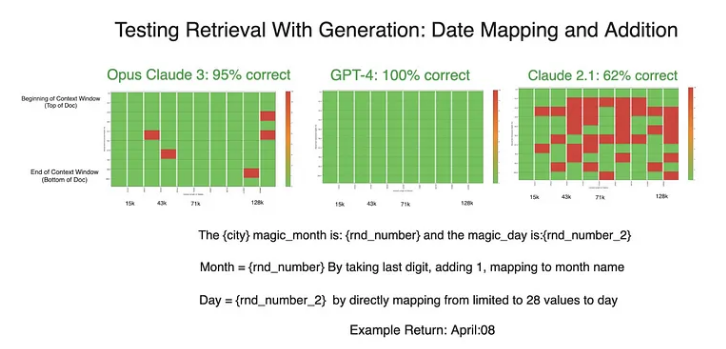
圖3:有針對性提示結果的初始測試
GPT-4模型的性能顯著提高,在随後的測試中取得了完美的結果。Claude模型的成績也有所改善。
這個實驗不僅突出了語言模型處理生成任務的方式的差異,還展示了提示工程對其性能的潛在影響。Claude的優勢似乎是冗長,事實證明這是GPT-4的一種可複制策略,這表明模型處理和呈現推理的方式會顯著影響其在生成任務中的準确性。總的來說,在我們的所有實驗中,包括看似微小的“解釋自己”這句話,都在提高模型的性能方面發揮了作用。
進一步的測試和結果

圖4:用于評估生成的四個進一步測試
我們又進行了四次測試,以評估主流模型将檢索到的信息合成并轉換爲各種格式的能力:
- 字符串連接:将文本片段組合成連貫的字符串,測試模型的基本文本操作技能。
- 貨币格式:将數字格式化爲貨币,四舍五入,并計算百分比變化,以評估模型的精度和處理數字數據的能力。
- 日期映射:将數字表示轉換爲月份名稱和日期,需要混合檢索和上下文理解。
- 模運算:執行複數運算以測試模型的數學生成能力。
不出所料,每個模型在字符串連接方面都表現出了強大的性能,這也重申了以前的理解,即文本操作是語言模型的基本優勢。

圖5:貨币格式化測試結果
至于貨币格式化測試,Claude 3和GPT-4的表現幾乎完美無瑕。Claude 2.1的表現總體上較差。準确度在标記長度上變化不大,但當指針更接近上下文窗口的開頭時,準确度通常會更低。

圖6:正式的來自Haystack網站的測試結果
盡管在一代測試中取得了出色的結果,但Claude 3的準确性在一個僅用于檢索的實驗中有所下降。從理論上講,簡單地檢索數字也應該比操縱數字更容易——這使得性能的下降令人驚訝,也是我們計劃進一步測試的領域。如果有什麽不同的話,這種違反直覺的下降隻會進一步證實這樣一種觀點,即在使用RAG開發時,檢索和生成都應該進行測試。
結論
通過測試各種生成任務,我們觀察到,雖然Claude和GPT-4這兩個模型都擅長字符串操作等瑣碎任務,但在更複雜的場景中,它們的優勢和劣勢變得顯而易見(https://arize.com/blog-course/research-techniques-for-better-retrieved-generation-rag/)。LLM在數學方面仍然不太好!另一個關鍵結果是,“自我解釋”提示的引入顯著提高了GPT-4的性能,強調了如何提示模型以及如何闡明其推理對實現準确結果的重要性。
這些發現對LLM的評估具有更廣泛的意義。當比較像詳細的Claude和最初不那麽詳細的GPT-4這樣的模型時,很明顯,RAG評估(https://arize.com/blog-course/rag-evaluation/)标準必須超越以前僅重視正确性這一點。模型響應的冗長引入了一個變量,該變量可以顯著影響他們的感知性能。這種細微差别可能表明,未來的模型評估應将平均答複長度視爲一個值得注意的因素,從而更好地了解模型的能力,并确保更公平的比較。








