

| 一、毕业设计工作的进展情况(不少于3000字) 本部分主要考察:1.复杂软件系统的分析与建模能力;2.系统架构和功能结构设计能力;3.数据结构和算法分析和设计能力。 本部分是中期检查报告的主要内容,要重点论述复杂软件系统的需求分析、概要设计和详细设计工作(包括用例设计、架构设计、功能结构设计、数据库设计、算法流程设计等),既要有文字描述,又要有图表等。 具体要求:
要求报告正文用小四号中文宋体、英文新罗马字体,单倍行距。 请在最终报告中删除以上红色字体说明内容(包括本句话)! 基于Spark的个性化书籍推荐系统是一种基于大数据技术的智能推荐系统,它可以根据用户的历史行为和偏好,为用户提供个性化的书籍推荐。该系统采用Spark技术,可以实现大数据的实时处理,从而提高推荐系统的准确性和可靠性。此外,该系统还可以根据用户的习惯和偏好,提供更加个性化的书籍推荐,从而满足用户的需求。 本系统的实现功能包括: 1、数据采集模块:采集用户的历史行为和偏好数据;2、数据处理模块:使用Spark技术对数据进行实时处理;3、推荐算法模块:根据用户的历史行为和偏好,提供个性化的书籍推荐;4、用户界面模块:提供友好的用户界面,方便用户查看推荐结果;5、管理员管理模块:提供书籍管理、用户管理、分类管理以及推荐管理功能。 技术方案可行性分析: 1、技术可行性:本系统采用Spark技术,可以实现实时处理大量数据,提高推荐系统的准确性和可靠性,同时也可以支持多种推荐算法,如基于内容的推荐、基于协同过滤的推荐等,从而实现个性化的书籍推荐。 2、系统可行性:本系统采用Mysql数据库存储用户数据,使用SQL语句进行调用和分析,可以有效地提高系统的运行效率,同时也可以满足用户的需求。 3、经济可行性:本系统采用开源技术,可以有效地降低系统的开发成本,同时也可以提高系统的可靠性和稳定性。 4、社会可行性:本系统可以满足用户对书籍的需求,提供个性化的书籍推荐,从而提高用户的阅读体验,同时也可以提高用户的阅读兴趣,促进社会文化的发展。 综上所述,本系统的技术方案具有较高的可行性,可以有效地满足用户的需求,促进社会文化的发展。 实现步骤如下: 1、数据采集:采用爬虫技术,从网络上抓取书籍的相关信息,包括书籍的名称、作者、出版社、出版时间、价格等; 2、数据处理:将抓取的数据进行清洗和预处理,去除无效数据,并将数据转换为Spark可以处理的格式; 3、推荐算法:采用基于内容的推荐算法和基于协同过滤的推荐算法,根据用户的历史行为和书籍的相关信息,计算出用户的推荐列表; 4、用户界面:设计用户界面,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 5、管理员管理:设计管理员管理模块,使管理员可以对系统进行管理和维护。 数据库的详细设计方案如下: 1、用户表:用户表用于存储用户的信息,包括用户ID、用户名、密码、性别、年龄等,字段类型为int、varchar等; 2、书籍表:书籍表用于存储书籍的信息,包括书籍ID、书籍名称、作者、出版社、出版时间、价格等,字段类型为int、varchar等; 3、分类表:分类表用于存储书籍的分类信息,包括分类ID、分类名称、书籍ID等,字段类型为int、varchar等; 4、用户行为表:用户行为表用于存储用户的行为信息,包括用户ID、书籍ID、行为类型(浏览、购买等)、行为时间等,字段类型为int、varchar等。 | ||
| 二、毕业设计工作存在的问题及解决方案(不少于1000字) 重点论述在软件系统的需求分析、概要设计和详细设计过程中遇到的问题以及解决方案。 开发过程中存在的问题及解决方案如下: 1、数据采集问题:由于网络上的数据量庞大,采集数据时可能会遇到网络不稳定、数据量过大等问题,可以采用分布式爬虫技术,将爬虫任务分发到多台服务器上,提高采集效率; 2、数据处理问题:由于网络上的数据结构不统一,处理数据时可能会遇到数据格式不一致、数据缺失等问题,可以采用数据清洗技术,将数据格式统一,并填补缺失的数据; 3、推荐算法问题:由于推荐算法的复杂性,可能会遇到推荐结果不准确、推荐效率低等问题,可以采用基于机器学习的推荐算法,根据用户的历史行为和书籍的相关信息,提高推荐结果的准确性和推荐效率; 4、用户界面问题:由于用户界面的复杂性,可能会遇到界面不友好、操作不便等问题,可以采用简洁的界面设计,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 5、管理员管理问题:由于管理员管理模块的复杂性,可能会遇到管理不方便、维护不及时等问题,可以采用可视化的管理界面,使管理员可以对系统进行管理和维护。 | ||
| 三、下一步工作预测及可能存在的问题(不少于500字) 为了优化基于Spark个性化书籍推荐系统,可以采用以下措施: 1、改进推荐算法:采用深度学习技术,改进推荐算法,提高推荐结果的准确性和推荐效率; 2、改进用户界面:采用可视化的用户界面,使用户可以轻松地查看推荐列表,并可以根据自己的喜好进行选择; 3、改进管理员管理:采用自动化的管理模式,使管理员可以对系统进行管理和维护; 4、改进数据采集:采用大数据技术,改进数据采集,提高采集效率; 5、改进数据处理:采用数据挖掘技术,改进数据处理,提高数据处理效率。 可能存在的问题包括:推荐结果不准确、推荐效率低、界面不友好、操作不便、管理不方便、维护不及时、数据采集效率低、数据处理效率低等。 下一步应该采用以上措施,改进推荐算法、用户界面、管理员管理、数据采集和数据处理,以提高系统的性能和用户体验。 | ||
| 检查结论 | 指导 教师 意见 | 指导教师签字: 年 月 日 |


基于Spark个性化书籍推荐系统
系统用到的各项技术和工具的介绍:
1. Python编程语言
Python是一种流行的高级编程语言,因其简单易学、清晰明了、开发效率高等特点,被广泛应用于机器学习、科学计算、Web开发、数据处理等领域。在该系统中,Python被用于实现数据抓取、推荐算法、Web应用程序等方面。
2. PySpark
PySpark是基于Python的Apache Spark API,Spark是一种快速大规模数据处理引擎,能够进行高速批处理和交互式查询,具有高可靠性和容错性,还可以支持各种数据源和格式。在该系统中,PySpark被用于数据分析和处理。
3. Hadoop
Hadoop是一个开源的大数据处理框架,能够处理和存储大量的分布式数据,并提供了高可靠性和容错性。Hadoop主要由HDFS和MapReduce组成,HDFS用于数据存储,而MapReduce则用于数据计算。在该系统中,Hadoop被用于大规模数据存储和处理。
4. Django Web框架
Django是一个基于Python的Web框架,可以帮助开发者快速构建高质量、可扩展的Web应用程序,具有诸如自带ORM、自动管理Web请求等优点。在该系统中,Django被用于实现用户模块、图书分类模块、图书查询模块和后台管理模块等。
5. Scrapy框架
Scrapy是一个Python编写的Web爬虫框架,可用于快速地爬取网站数据并进行数据处理。该框架提供了强大的页面解析能力和异步网络请求支持,适用于大规模数据抓取场景。在该系统中,Scrapy被用于实现数据抓取模块。
6. Vue.js
Vue.js 是一款流行的渐进式 JavaScript 框架,用于构建用户界面。它具有易用性、高效率等特点,被广泛应用于前端开发领域。在该系统中,Vue.js被用于构建前端界面。
7. Element Plus
Element Plus是基于Vue.js的UI框架,提供了丰富的UI组件、特效和交互。该框架具有可定制性、易用性和高性能等特点,适用于各种Web应用程序的构建。在该系统中,Element Plus被用于构建前端界面。
8. 协同过滤算法
协同过滤算法是一种基于相似度的推荐算法,能够通过用户历史行为数据来预测用户对未看过的物品的喜好程度,从而完成推荐。在该系统中,协同过滤算法被用于实现图书推荐模块。
该系统各个模块的实现细节:
1. 数据抓取模块实现
该模块使用Scrapy框架实现了对“豆瓣读书”网站上的图书数据的抓取。具体步骤如下:
- 分析目标网站:分析“豆瓣读书”网站的网页结构、URL链接等信息,确定需要抓取的数据。
- 定义爬虫:在Scrapy中定义Spider,包括指定起始URL、定义爬取规则和数据处理方法等。
- 解析页面:使用XPath或CSS Selector对HTML页面进行解析,提取出需要的数据,如书名、作者、评分等。
- 存储数据:将解析得到的数据存储到数据库中。
2. 用户模块实现
该模块实现了以下功能:
- 用户注册:用户可以通过注册页面填写用户名、密码、邮箱等信息进行注册,注册信息将被保存到数据库中。
- 用户登录:用户可以通过登录页面输入用户名和密码进行登录,系统会检查数据库中是否存在该用户,并验证账号密码是否正确。
3. 图书分类模块实现
该模块用于展示图书分类,并提供了分类查询功能。具体步骤如下:
- 提取分类信息:从数据库中提取所有的图书分类信息,如小说、历史、传记等。
- 展示分类信息:将提取到的分类信息在前端页面进行展示。
- 分类查询:用户可以选择一个特定的分类,系统会根据用户选择的分类来查询该分类下的所有图书信息,并将查询的结果展示在前端页面中。
4. 图书查询模块实现
该模块用于根据书名、书籍分类、作者和ISBN等信息筛选图书,分页查询的功能。具体步骤如下:
- 定义图书模型:通过Django内置的ORM框架创建图书模型,该模型定义了图书的各种属性,包括书名、作者、ISBN、价格、出版社等。
- 接收查询条件:用户可以在前端页面输入查询条件,如书名、作者、分类等,系统接收到这些查询条件后,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 数据查询:根据用户输入的查询条件,使用Django的QuerySet方法从数据库中查询满足条件的图书数据。
- 分页展示:使用Django自带的Paginator组件对查询结果进行分页,将其展示在前端页面中。
5. 协同过滤推荐算法实现
该模块实现了基于用户的协同过滤和基于物品的协同过滤算法。具体步骤如下:
- 构建评分矩阵:将用户对图书的浏览评分构建成评分矩阵,使用矩阵运算进行相似度计算。
- 基于用户的协同过滤算法:根据用户之间的相似度,预测目标用户对图书的评分,并为用户推荐相似性高的图书。
- 基于物品的协同过滤算法:根据图书之间的相似度,为用户推荐相似度高的图书。
6. 后台管理模块实现
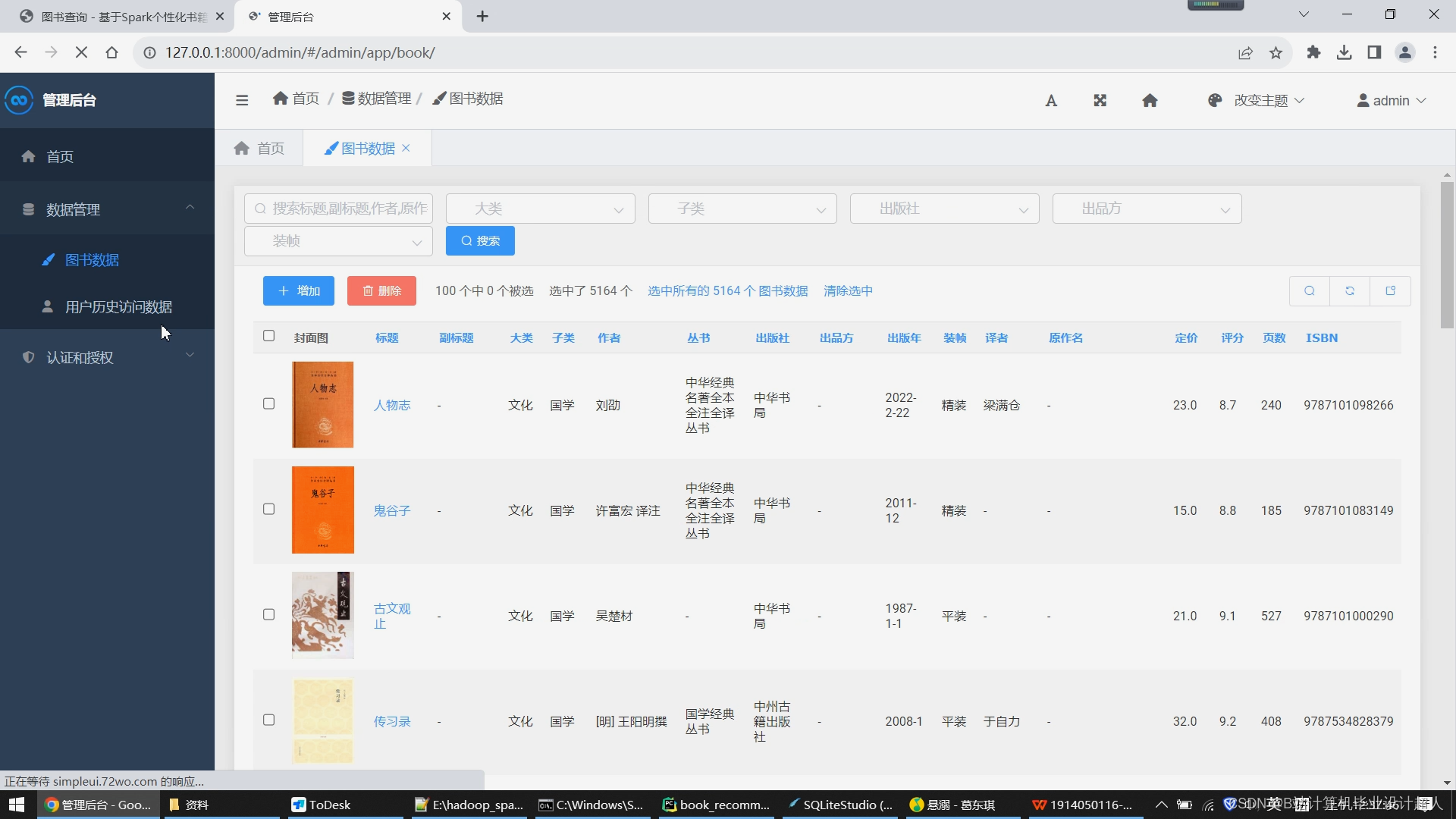
该模块提供了管理员对抓取到的图书数据进行管理的功能。具体步骤如下:
- 管理员登录:管理员输入用户名和密码,通过验证后进入后台管理系统。
- 数据管理:管理员可以查看和修改数据库中的图书信息,包括图书名称、作者、ISBN号、价格等。
技术及功能关键词:
python pyspark hadoop django scrapy vue element-plus 协同过滤算法
通过scrapy爬虫框架抓取“豆瓣读书”网站上的书籍数据
前台用户通过登陆注册后进入系统
管理员可在后台管理所有抓取到的图书数据
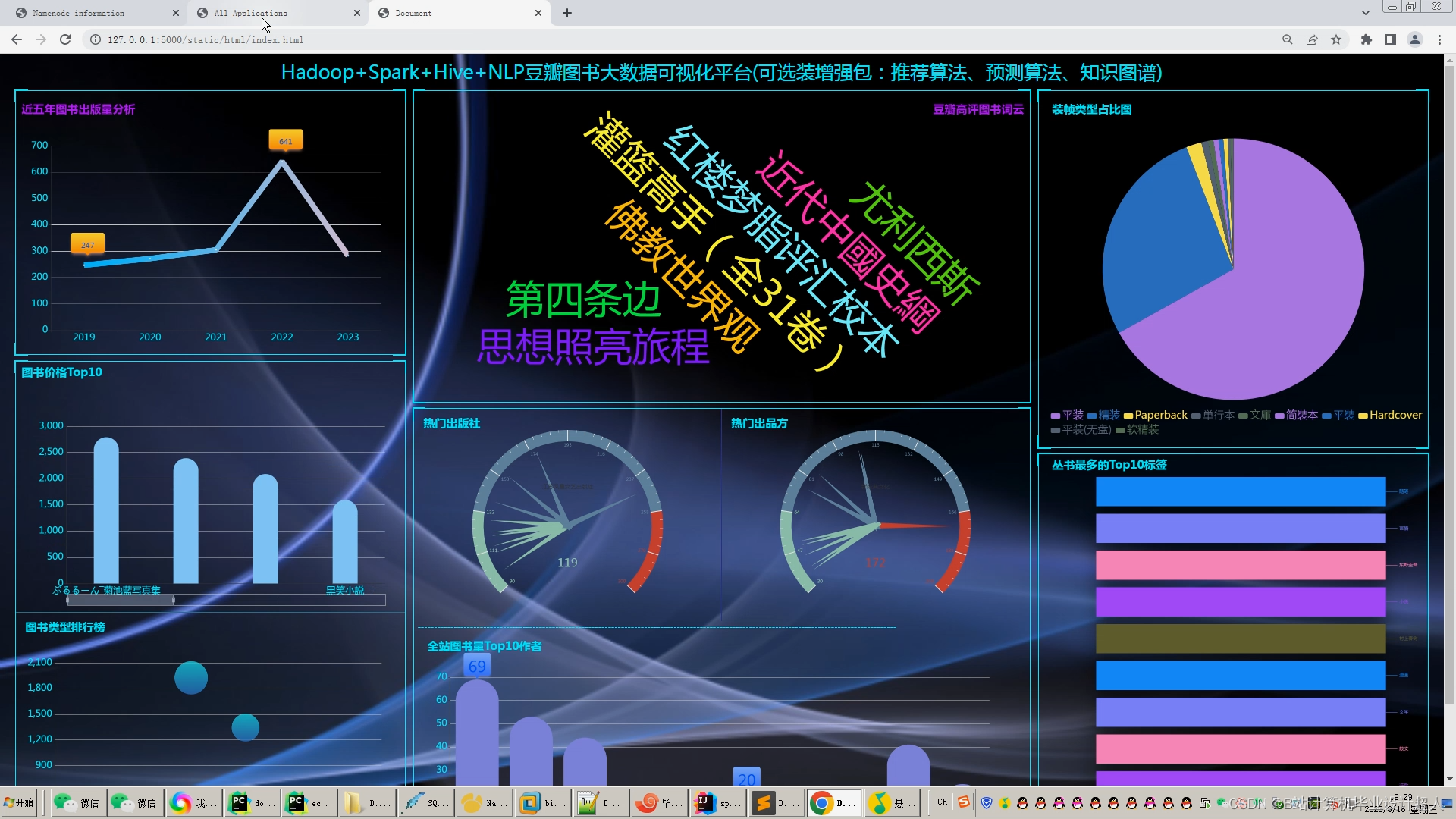
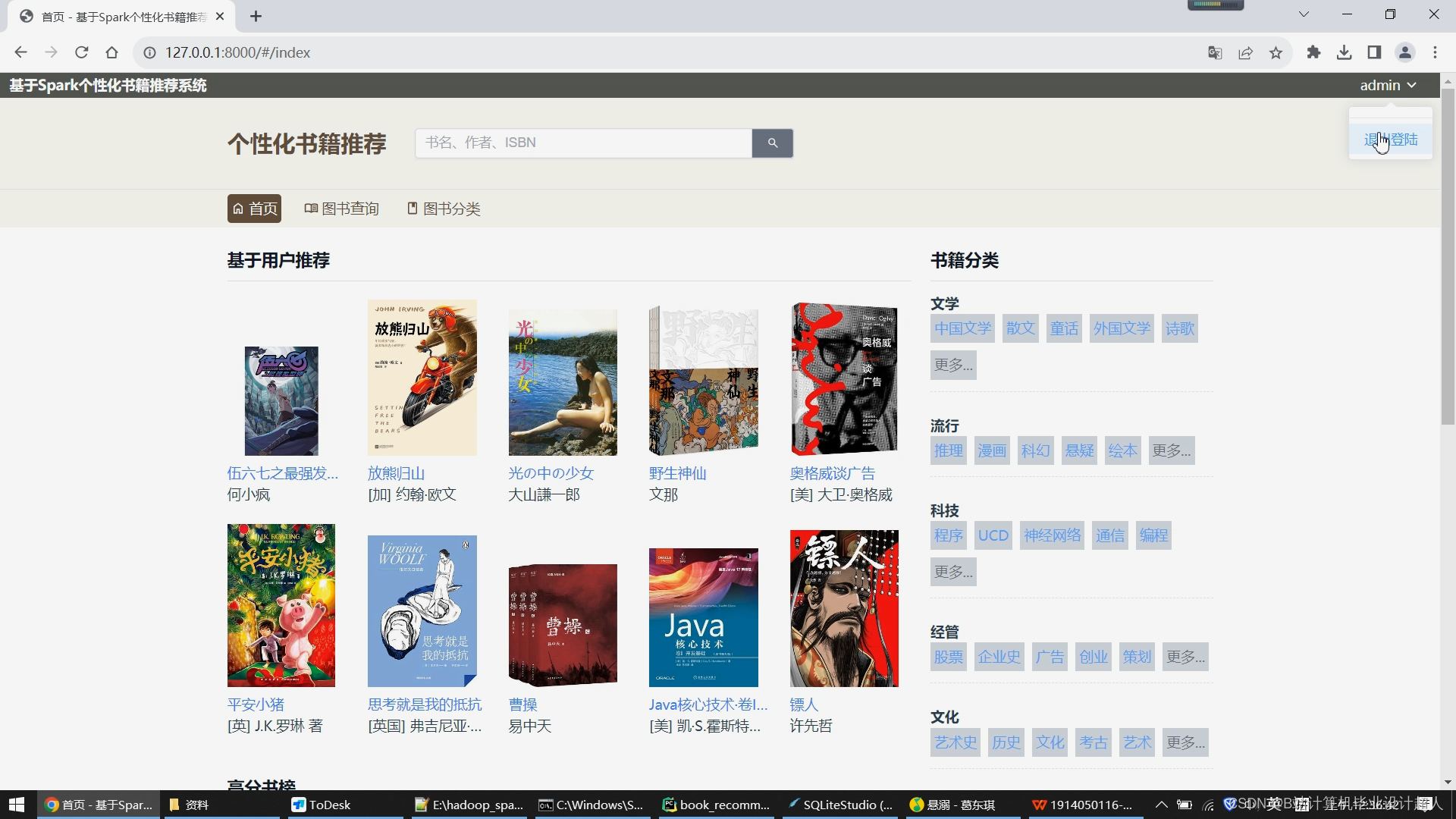
首页分为左右两侧,右侧展示所有图书的分类,比如文学、流行、科技、经管、文化、生活等大类,大类下亦有许多小类;左侧展示基于用户的协同过滤推荐算法给用户推荐的10个图书数据,下方是根据图书评分推荐的高分书榜
图书查询模块,可以根据书名、书籍分类、作者和ISBN等信息筛选图书,底部带有一个分页器,以10本书籍信息为一页实现分页查询,降低后端数据库的压力
图书分类模块,展示了所有图书的大类小类,用户可以通过点击某一分类,实现快速查找合适自己口味的图书信息
当用户访问某一书籍详情时,页面展示了图书的封面、作者、译者、出版社、出品方、类型、出版年、页数、装帧类型、ISBN等基本信息,还展示了图书的内容简介以及大纲等;在此页面的底部最后部分,我们向用户推荐了5本基于物品的协同过滤算法推荐的图书结果
目录结构(只关注标注了中文的):
├── app 图书数据后端最重要的模块!!!
│ ├── __init__.py
│ ├── admin.py 后台显示数据的配置
│ ├── apps.py 协同过滤算法代码!!!
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py 图书相关的数据库模型
│ ├── tests.py
│ ├── urls.py
│ └── views.py 图书相关所有重要的后端代码!!!!!
├── auth 用户登陆注册模块
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py 登陆注册的代码!
├── book_recommend_system
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py 后端配置文件
│ ├── urls.py 路由配置文件
│ └── wsgi.py
├── db.sqlite3
├── dist
│ ├── assets
│ │ ├── detail.15fd66c8.js
│ │ ├── detail.36aa23b0.css
│ │ ├── detail.6b0150d6.js
│ │ ├── index.0b336648.css
│ │ ├── index.0ee13b90.css
│ │ ├── index.1a0a0bcd.js
│ │ ├── index.485fc076.js
│ │ ├── index.4c336a7c.js
│ │ ├── index.63bf9bc7.css
│ │ ├── index.6d5765b8.js
│ │ ├── index.79803d2c.js
│ │ ├── index.9860a311.js
│ │ ├── index.9877344b.js
│ │ ├── index.bd7b408d.js
│ │ ├── index.db570182.css
│ │ ├── login.248044ee.js
│ │ ├── login.5d7fb03b.js
│ │ ├── login.61bcbfce.css
│ │ ├── register.211ff2cd.css
│ │ ├── register.5042fb1f.js
│ │ └── register.c3ddecb6.js
│ └── index.html
├── fake.py
├── frontend
│ ├── README.md
│ ├── index.html
│ ├── package-lock.json
│ ├── package.json
│ ├── public
│ ├── src
│ │ ├── App.vue
│ │ ├── assets
│ │ ├── components
│ │ ├── directives
│ │ ├── layout_h
│ │ ├── layout_v
│ │ ├── main.js
│ │ ├── mixins
│ │ ├── router
│ │ ├── stores
│ │ ├── utils
│ │ └── views 前端源代码,前台所有页面的代码都在这!!!
│ └── vite.config.js
├── index
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ ├── utils.py
│ └── views.py
├── manage.py
├── middlewares
│ └── __init__.py
├── recommend.py
├── requirements.txt
├── scrapy.cfg
├── spider
│ ├── __init__.py
│ ├── extendsion
│ │ ├── __init__.py
│ │ └── selenium
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py 爬虫数据入库逻辑
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── book.py 爬虫代码!!!
└── 项目介绍.txt
28 directories, 83 files
代码分享如下:
Spark MLlib中的推荐算法主要基于协同过滤(Collaborative Filtering)原理实现,具体包括基于用户的协同过滤和基于物品的协同过滤两种方法。
-
基于用户的协同过滤(User-Based Collaborative Filtering):
- 基本思想是找到与目标用户兴趣相似的其他用户,将这些用户喜欢的物品推荐给目标用户。
- 算法步骤:
- 计算用户之间的相似度,常用的相似度计算方法包括余弦相似度、皮尔逊相关系数等。
- 预测目标用户对未评价物品的评分,一般采用加权平均或加权和来进行预测。
- 根据预测评分推荐物品给目标用户。
-
基于物品的协同过滤(Item-Based Collaborative Filtering):
- 基本思想是找到与目标物品相似的其他物品,将这些相似物品推荐给用户。
- 算法步骤:
- 计算物品之间的相似度,通常使用余弦相似度或其他相似度度量。
- 根据用户的历史行为和喜好,预测用户对未评价物品的评分。
- 根据预测评分推荐物品给用户。
在Spark MLlib中,推荐算法还可以结合矩阵分解等技术来提高推荐的准确性和效率。例如,通过使用交替最小二乘法(Alternating Least Squares, ALS)来进行矩阵分解,从而进行隐式反馈数据的推荐。
总的来说,Spark MLlib中的推荐算法主要利用用户-物品交互数据,通过计算用户之间或物品之间的相似度,来预测用户对未知物品的兴趣度,从而实现个性化的推荐服务。
import os
import django
from django.db import connection
import pandas as pd
import numpy as np
from pyspark.sql import SparkSession
from pyspark.sql.dataframe import DataFrame
import pyspark.sql.functions as func
from pyspark.mllib.recommendation import ALS
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("ERROR")
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "book_recommend_system.settings")
django.setup()
sql = """
SELECT
u.id AS uid,
b.id AS bid,
count( h.id ) AS `rating`
FROM
book b,
auth_user u
LEFT JOIN history h ON h.user_id = uid
AND h.book_id = bid
GROUP BY
bid,
uid
ORDER BY
bid;
"""
cursor = connection.cursor()
cursor.execute(sql)
columns = ("uid", "pid", "rating")
rdd = sc.parallelize(cursor)
model = ALS.train(rdd, 10)
print([i.product for i in model.recommendProducts(3, 10)])
# sdf: DataFrame = spark.createDataFrame(pdd, schema=columns)
# # print(df)
# # df.printSchema()
# pivot: DataFrame = sdf.groupby("pid").pivot("uid").sum("rating").orderBy("pid")
# cols, d = pivot.select()
# pivot.show(5)







