


网址(付费认证项目):
一共五次考试机会,考完后需要重新购买课程。算子开发网络模型迁移技术学习认证_基于昇腾AI处理器的算子开发微认证_华为云学院-华为云
低分飘过~~来写点知识点
参考:昇腾社区-官网丨昇腾万里 让智能无所不及
知识点依据考题进行总结
目录
1.为什么要编写TBE算子
2.TBE基础知识
3.TBE算子开发流程
1.为什么要编写TBE算子
Ascend 模型:
原始模型输入——ATC模型转换——自定义算子开发——整网性能调优——整网泛化测试
其中,原始模型指Caffe或TensorFlow的模型
ATC模型转换会出现算子不支持的情况
模型转换
将开源框架的网络模型 通过ATC 转换成异腾AI处理器支持的离线模型
实现 算子调度的优化、权值数据重排、内存使用优化等
可以脱离设备完成模型预处理
1.TensorFlow/Caffe
|
|(Model file)
|
|
2.ATC工具
|
|(图准备,图优化,图拆分,图编译)
|
|
3.Model
.om file
常见问题:
算子不支持(80%)
原因:
1.新网络,其中算子未开发或发布
2.原框架自定义算子,需要在新框架重新适配开发
3.算子泛化不够,某些数据大小不支持
解决办法:
TBE自定义算子
2.TBE基础知识
WHAT IS TBE?
Tensor Boost Engine,自定义算子开发工具
1.开发运行在NPU上
2.在TVM( TensorVirtual Machine)框架基础上扩展
3.提供了一套Python API来实施开发活动
WHY?
1.昇腾AI软件栈不支持开发者网络中的算子
2.开发者想要自己开发算子来提高计算性能
3.开发者想要修改现有算子中的计算逻辑
WHAT IS NPU?
Neural-network Processing Unit,神经网络处理器
维基百科中,NPU被指向了“人工智能***”, 释义:“人工智能***" 是一类专用于人工智能硬件加速的微处理器或计算系统。典型的应用包括机器人学、物联网等数据密集型应用或传感器驱动的任务。
本系列课程中,NPU可以特指为昇腾AI处理器
算子
基本概念
一个函数空间到函数空间上的映射O: X一X;
我们所开发的算子是网络模型中涉及到的计算函数。
在Caffe中,算子对应层中的计算逻辑
举例:
卷积层 (Convolution Layer) 中的卷积算法,是一个算子;
全连接层中的权值求和过程,是一个算子

类型:type
在一个网络中同一类型的算子可能存在多个。
例如卷积算子的类型为Convolution
名称:name
同一网络中每一个算子的名称需要保持唯一
比如,conv1和conv2都是Convolution类型,
表示分别做一次卷积运算,
但是每次运算的名称不能重复

张量(tensor)
Tensor是TBE算子中的数据,包括输入数据与输出数据,TensorDesc (Tensor描述符)是对输入数据与输出数据的描述,TensorDesc数据结构包含如下属性:
- 名称 (name)----用于对Tensor进行索引,不同Tensor的name需要保持唯一
- 形状 (shape)----Tensor的形状,比如 (10,) 或者 (1024,1024) 或者(2,3,4) 等
默认值:无
形式: (i1,i2,...in),其中i1,i2,in为正整数
- 数据类型 (dtype)----功能描述: 指定Tensor对象的数据类型
默认值: 无
取值范围: float16, float32, int8,int16,int32,uint8,uint16, bool
说明:不同计算操作支持的数据类型不同
- 数据排布格式 (format)----多个维度的排布顺序
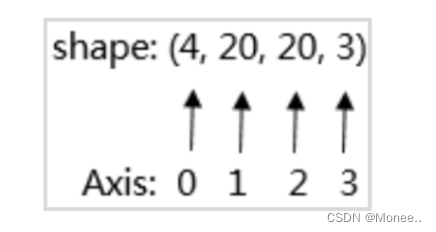
张量形状 (Shape)
物理含义:

以shape = (4,20,20,3)为例,每个像素点都由红/绿/蓝3色组成,即shape里面3的含义,照片的宽和高都是20,也就是20*20=400人像素,总共有4张的照片
张量--数据排布格式(Format)
在深度学习框架中,多维数据通过多维数组存储
比如,卷积神经网络的特征图用四维数组保存,四个维度分别为
批量大小(Batch,N) 、
特征图高度.(Height,H) 、
特征图宽度(Width,W)
特征图通道 (Channels,C)
序存储特征图数据的顺序:
caffe:NCHWTensorflow:NHWC
算子属性--轴(axis)
升维--广播机制 (Broadcast)
- TBE支持的广播规则: 可以将一个数组的每一个维度扩展为一个固定的shape,需要被扩展的数组的每个维度的大小或者与目标shape相等,或者为1,广播会在元素个数为1的维度上进行。
- 例如: 原数组a的维度为 (2, 164) ,目标shape为 (2, 128,64) ,则通过广播可以将a的维度扩展为目标shape (2128,64)。
- TBE的计算接口加、减、乘、除等不支持自动广播,要求输入的两个Tensor的shape相同,所以操作前,我们需要先计算出目标shape,然后将每个输入Tensor广播到目标shape再进行计算。
例:
Tensor A的shape为 (4, 3,1,5),Tensor B的shape为 (1,1,2,1),执行TensorA + Tensor B
- 计算出目标shape。
A( 4 , 3 , 1, 5 ),B ( 1 , 1 , 2 , 1)----->取每个维度的最大值,构建C(4,3,2,5)
- 调用广播接口分别将Tensor A与Tensor B扩展到目标Shape C。
- 调用计算接口,进行Tensor A + Tensor B。
需要广播的tensor的shape需要满足规则:每个维度的大小或者与目标shape相等,或者为1
降维 (Reduction)
将多维数组的指定轴做降维操作
ReductionOp:常见算子支持的操作类型,包含四种类型。
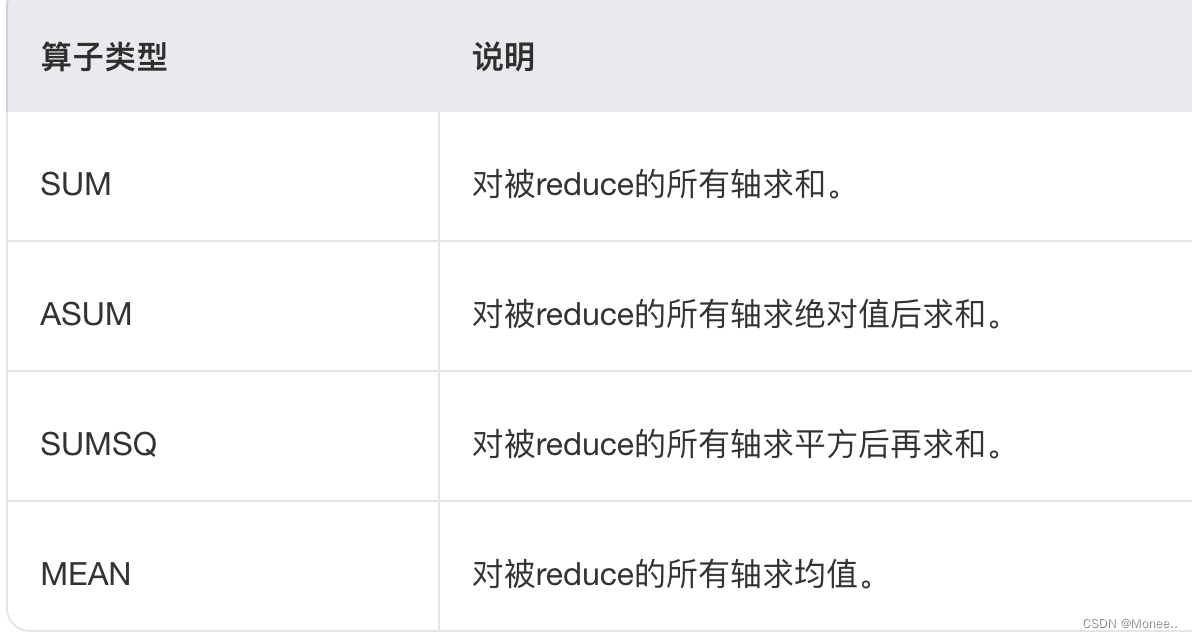 Axis: Reduction需要指定若工个轴,会对这些轴进行reduce操作,取值范用为:[-N,N-1]
Axis: Reduction需要指定若工个轴,会对这些轴进行reduce操作,取值范用为:[-N,N-1]keepdim: 对指定轴降维后,该轴是被消除还是保留为1,即此维度是否保留。取值为0表示消除,1表示保留.

如果:
- Axis=0,对2维矩阵来说就是行,也就是对这个2维矩阵每行对应的数据进行相加,得到[2,2,2],降为1维

- Axis=1,每列对应的数据进行相加
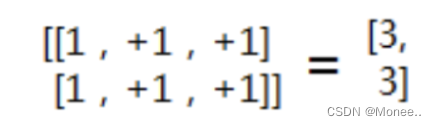
- Axis=[0,1],先对轴0进行降维求和得到[2,2,2], 再对[2,2,2]继续降维求和得到6,最后得到是0维
- Axis=1,不降维,原样输出
- Axis为空,就是对所有维度进行降维,最后得到0维的标量。
TBE算子开发方式
开发方式 特点 DSL 开发难度:易
适用人群:入门开发者,仅需要了解神经网终和TBE DSL相关知识特点: TBE工具提供自动优化机制,给出较优的调度流程
TIK 开发难度: 难
适用人群: 高级开发者,需要掌握Davinci硬件缓冲区架构,对性能有较高要求特点: 接口偏底层,用户需要自己控制数据流以及算子的硬件调度 (schedule)
3.TBE算子开发流程
整体流程
Mind Studio工具操作部分- 工程创建
- 算子开发
- 单算子验证
- 算子编译
- 算子部署
- 网络运行验证
算子开发包括
- 算子分析
- 算子代码实现
- 算子适配插件实现
- 算子原型定义
- 算子信息定义
单算子验证包括
- UT/ST/BBIT测试用例实现
网络运行验证包括
- 网络测试用例实现
def sqrt(input_x, output_y, kernel_name="sqrt"): #算子方法签名&入参 shape = inpout_x.get("shape") dtype = input_x.get("dtype") input_dtype = dtype.lower() data = tvm.placeholder(shape, name="data", dtype=input_dtype) #输入Tensor占位符 #定义计算过程 log_val = te.lang.cce.vlog(data) const_val = tvm.const(0.5,"float32") mul_val = te.lang.cce.vmuls(log_val,const_val) res = te.lang.cce.vexp(mul_val) #定义调度过程 with tvm.target.cce(): schedule = generic.auto_schedule(res) #算子构建 config = {"name": kernel_name, "tensor_list":[data, res]} te.lang.cce.cce_build_code(schedule, config)算子入参
def sqrt (input_x, output_y, kernel_name="sqrt"): """ Parameters input_x : dict shape and dtype of input output_y : dict shape and dtype of output kernel_name : str kernel name, default value is "sqrt” """>shape : Tensor的属性,表示Tensor的形状,用list或tuple类型表示
例如 (3,2,3)、(4, 10) 。
>dtype : Tensor的数据类型,用字符串类型表示。
例如“float32”、“float16""int8”等。
输入占位符
TBE算子输入占位符
data = tvm.placeholder(shape, name="data", dtype=input_dtype)
tvm.placeholder() 是tvm框架的API,用来为算子执行时接收的数据占位,
通俗理解:与C语言中%d、%s一样,返回的是一个Tensor对象,上例中使用data表示,入参为shape,name,dtype,是为Tensor对象的属性
这里的输入是指算子执行时的输入数据,与编译时期入参不同,编译时期入参input_x(shape,type)是为了得到算子执行文件的入参
定义计算过程
定义计算过程是指使用DSL语言,根据数学算式,描述出实现算子功能的计算步骤
只要是te.lang.cce.name(),皆为TBE框架的API调度(schedule)
with tvm.target.cce() schedule = generic.auto_schedule(res)计算过程描述完之后,就会做调度,
调度是与硬件相关的,功能主要是调整计算过程的逻辑,意图优化计算过程,使计算过程更高效,以及保证计算过程中占用硬件存储空间不会超过上限。
构建
config = {"name": kernel name, "tensor list": [data, res]} te.lang.cce.cce_build_code(sch, config)TBE框架提供了cce build code0APl,传入schedule以及相关的配置项,即可完成编译生成最终硬件可执行文件。
算子 ComputeAPI
接口皆为te.lang.cce.name的形式
接口分类 作用 elewise_compute 对Tensor中每个原子值分别做相同操作,样例中te.lang.cce.vabs 即对每个数值x求绝对值 reduction_compute 对Tensor按轴进行操作,例如te.lang.cce.sum(data,axis)表示对data按axis进行累加 segment_compute 对Tensor进行分段操作 cast_compute 对Tensor中数据的数据类型进行转换,例如float16转换为float32 broadcast_compute 对Tensor按照目标shape进行广播,如shape为 (3,1,2) 的Tensor广 播成(3,3,2)的Tensor mmad_compute 支持矩阵乘法 卷积相关compute 除以上几种compute,还有一些专门针对卷积的compute st测试
ST测试即系统测试(System Test) ,在仿真环境下,验证算子功能的正确性
- 正确的生成.o和.json文件。ST侧重测试各种数据类型、shape等场景下生成的算子的正确性
- 测试算子逻辑的正确性。ST通过C++用例调用runtime的接口,然后端到端计算出执行结果,并取回结果和预期结果(Tensorflow或者numpy生成)进行比较,来测试算子逻辑的正确性。也可进行性能分析。
- ST测试用例在仿真环境下运行
需要考试帮助可加我wx ,考不过可退款

- 网络测试用例实现
- 计算出目标shape。







