

(图片来源网络,侵删)
一、原理
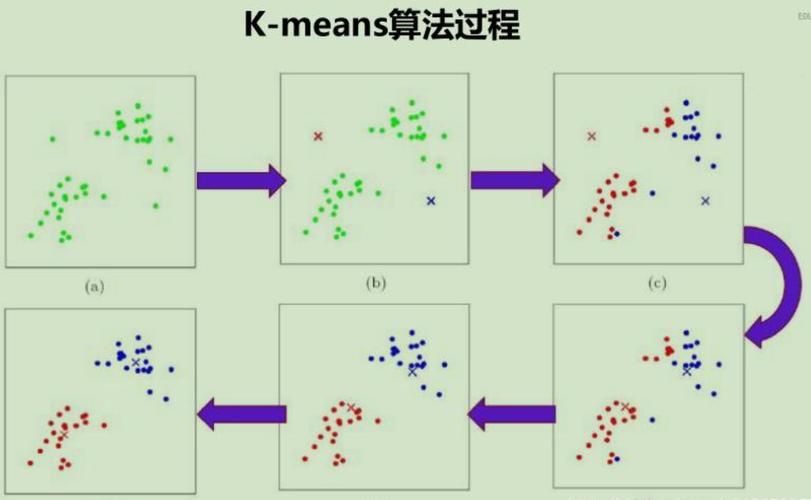
K-means聚类是一种经典的、广泛使用的无监督学习算法,主要用于将数据集划分为多个类别或“簇”。其目标是将数据集中的每个点分配到K个聚类中心之一,使得簇内的点尽可能相似,而簇间的点尽可能不同。
K-means算法的基本步骤:
- 初始化:选择K个数据点作为初始聚类中心(质心)。
- 分配:将每个点分配到最近的聚类中心,形成K个簇。
- 更新:重新计算每个簇的聚类中心,通常是簇内所有点的均值。
- 迭代:重复步骤2和3,直到满足停止条件,如质心的变化小于某个阈值或达到预设的迭代次数。
K-means算法的关键点:
- K的选择:K的选择通常是基于经验或使用如肘部法则(Elbow Method)等方法确定的。
- 初始化方法:可以随机选择,也可以使用如K-means++等更高级的方法以提高性能。
- 收敛性:K-means算法在局部最优上是收敛的,可能不会找到全局最优解,因此可能需要多次运行以获得最佳结果。
- 性能度量:使用如轮廓系数(Silhouette Coefficient)等

(图片来源网络,侵删)







