

使用 AI进行Python 小程序开发,会是什么样子的:只要你问的准,AI给出的答案?自己试试看,入门越来越低。
(图片来源网络,侵删)
人还要做什么?还能做什么?
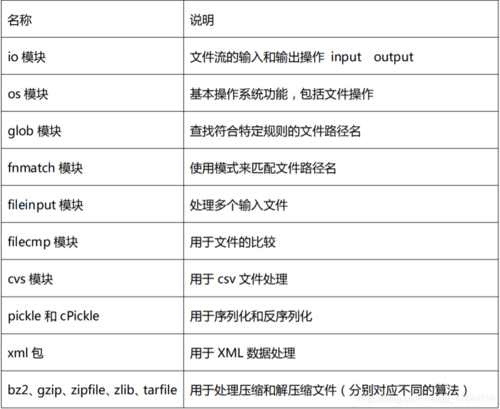
需求:给定目录 -- 需求持续补充中

(图片来源网络,侵删)
1)统计该目录及子目录下文件类型(以后缀区分)、文件数量(文件及文件夹、总量及不同类型数量)、绘制目录结构
2)给定关键字,判断目录下文件是否包含该关键字:如果包含,输出该文件名、关键字个数、所处位置(行)
。。。。。。。
9)程序打包成 EXE 文件供外部使用
- 提问1:python 查看目录及子目录文件列表
## 创作助手 import os def get_all_files(directory): file_list = [] for root, dirs, files in os.walk(directory): for file in files: file_list.append(os.path.join(root, file)) return file_list directory = "your/directory/path" files = get_all_files(directory) for file in files: print(file) - 提问2:python 判断文件后缀名
filename = "example.txt" # 文件名 # 可能的后缀名列表 allowed_extensions = [".txt", ".doc", ".pdf", ".jpg", ".png"] # 判断文件后缀名 for ext in allowed_extensions: if filename.endswith(ext): print("文件后缀名为", ext) break else: print("文件后缀名不在允许的范围内") - 提问3:python 判断当前文件后缀名是什么
import os filename = 'example.txt' extension = os.path.splitext(filename)[1] print(extension)
- 提问4:python 将不同后缀的文件名放入字典中并统计数据
import os # 指定文件夹路径 folder_path = '/path/to/folder' # 获取文件夹中的所有文件名 files = os.listdir(folder_path) # 创建一个空字典用于存放文件后缀及数量 file_ext_dict = {} # 遍历每个文件 for file in files: # 获取文件后缀 file_ext = os.path.splitext(file)[1] # 判断文件后缀是否已存在于字典中 if file_ext in file_ext_dict: # 如果存在,则数量加1 file_ext_dict[file_ext] += 1 else: # 如果不存在,则新增键,并设置数量为1 file_ext_dict[file_ext] = 1 # 打印字典中的数据 for ext, count in file_ext_dict.items(): print(f"{ext}: {count}") >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> .txt: 10 .docx: 5 .xlsx: 3 .jpg: 2 - 提问5:python,读取文件并判断文件中是否包含某个字段
## check_field_in_file函数,接受一个字段和一个文件名作为参数 ## 尝试打开文件并逐行遍历文件内容,如果在任何一行中找到了包含给定字段的字符串,则返回True; ## 如果文件找不到,则输出相应的错误信息,并返回False def check_field_in_file(field, filename): try: with open(filename, 'r') as file: for line in file: if field in line: return True except FileNotFoundError: print(f"File '{filename}' not found.") return False field = "example_field" filename = "example.txt" if check_field_in_file(field, filename): print(f"File '{filename}' contains the field '{field}'.") else: print(f"File '{filename}' does not contain the field '{field}'.")
- 提问6:python,读取 doc 文件
pip install python-docx from docx import Document # 打开doc文件 doc = Document('myfile.doc') # 读取文档中的段落 for para in doc.paragraphs: print(para.text) # 读取文档中的表格 for table in doc.tables: for row in table.rows: for cell in row.cells: print(cell.text) - 提问7:python,读取 excel 文件
pip install pandas import pandas as pd # 读取 Excel 文件 data = pd.read_excel('filename.xlsx') # 显示数据 print(data) - 提问8:python,读取 pdf 文件
pip install PyPDF2 import PyPDF2 # 打开PDF文件 with open('example.pdf', 'rb') as file: # 创建PDF对象 pdf = PyPDF2.PdfFileReader(file) # 获取PDF中的页数 num_pages = pdf.numPages # 读取每一页的内容 for page in range(num_pages): # 获取当前页的对象 page_obj = pdf.getPage(page) # 提取当前页的文本内容 text = page_obj.extract_text() # 打印文本内容 print(text) - 提问9:python,读取 txt 文件 -- 这是最常规的读写,放在最后
with open('myfile.txt', 'r') as file: for line in file: print(line) - 提问10:python 使用xlrd xlwt读取office文件
pip install xlrd pip install xlwt import xlrd # 打开Excel文件 workbook = xlrd.open_workbook('file.xlsx') # 选择第一个工作表 worksheet = workbook.sheet_by_index(0) # 读取单元格数据 cell_value = worksheet.cell_value(0, 0) print(cell_value) # 遍历所有行和列 for row in range(worksheet.nrows): for col in range(worksheet.ncols): cell_value = worksheet.cell_value(row, col) print(cell_value) ------------------------------------- import xlwt # 创建一个新的Excel文件 workbook = xlwt.Workbook() # 添加一个工作表 worksheet = workbook.add_sheet('Sheet1') # 写入单元格数据 worksheet.write(0, 0, 'Hello') # 保存Excel文件 workbook.save('file.xlsx')
后续
1. 如果把 10 条提问放在一起能否完成一个完整的项目代码呢?
2. AI生成的代码能够直接应用于最终项目吗?需要修改吗?是提问不到位还是AI不足以替代人的工作?
3. 最终代码修正,慢慢做好了。。。。。。
- 准备
#******************************************************************** # Copyright (c) 2024,LeiXun Studio # All Rights Reserved. # # File Name: fileCheck.py # Summary: check files in folder: count and content # # @Version: 0.1 # @Author: Roy # @Start Date: 2024/5/12 #*********************************************************************
- 变量定义
folderPath = '' # target folder; default: C:\Windows\System32 fileList = [] # file ist in target folder filecount = 0 # total file count filetype = {} # {type:count},file type and type count querystr = '' # query string in file strfile = {} # {filename:strcount}, file name and string show count







