

一、显示 API 简介
使用 utils.discovery.all_displays 查找可用的 API。
Sklearn 的utils.discovery.all_displays可以让你看到哪些类可以使用。
from sklearn.utils.discovery import all_displays displays = all_displays() displays
Scikit-learn (sklearn) 总是会在新版本中添加 "Display "API,因此这里可以了解你的版本中有哪些可用的 API 。例如,在我的 Scikit-learn 1.4.0 中,就有这些类:
[('CalibrationDisplay', sklearn.calibration.CalibrationDisplay),
('ConfusionMatrixDisplay',
sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay),
('DecisionBoundaryDisplay',
sklearn.inspection._plot.decision_boundary.DecisionBoundaryDisplay),
('DetCurveDisplay', sklearn.metrics._plot.det_curve.DetCurveDisplay),
('LearningCurveDisplay', sklearn.model_selection._plot.LearningCurveDisplay),
('PartialDependenceDisplay',
sklearn.inspection._plot.partial_dependence.PartialDependenceDisplay),
('PrecisionRecallDisplay',
sklearn.metrics._plot.precision_recall_curve.PrecisionRecallDisplay),
('PredictionErrorDisplay',
sklearn.metrics._plot.regression.PredictionErrorDisplay),
('RocCurveDisplay', sklearn.metrics._plot.roc_curve.RocCurveDisplay),
('ValidationCurveDisplay',
sklearn.model_selection._plot.ValidationCurveDisplay)]
二、显示决策边界
使用 inspection.DecisionBoundaryDisplay 显示决策边界
如果使用 Matplotlib 来绘制,会很麻烦:
-
使用 np.linspace 设置坐标范围;
-
使用 plt.meshgrid 计算网格;
-
使用 plt.contourf 绘制决策边界填充;
-
然后使用 plt.scatter 绘制数据点。
现在,使用 inspection.DecisionBoundaryDisplay 可以简化这一过程:
from sklearn.inspection import DecisionBoundaryDisplay from sklearn.datasets import load_iris from sklearn.svm import SVC from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt iris = load_iris(as_frame=True) X = iris.data[['petal length (cm)', 'petal width (cm)']] y = iris.target svc_clf = make_pipeline(StandardScaler(), SVC(kernel='linear', C=1)) svc_clf.fit(X, y) display = DecisionBoundaryDisplay.from_estimator(svc_clf, X, grid_resolution=1000, xlabel="Petal length (cm)", ylabel="Petal width (cm)") plt.scatter(X.iloc[:, 0], X.iloc[:, 1], c=y, edgecolors='w') plt.title("Decision Boundary") plt.show()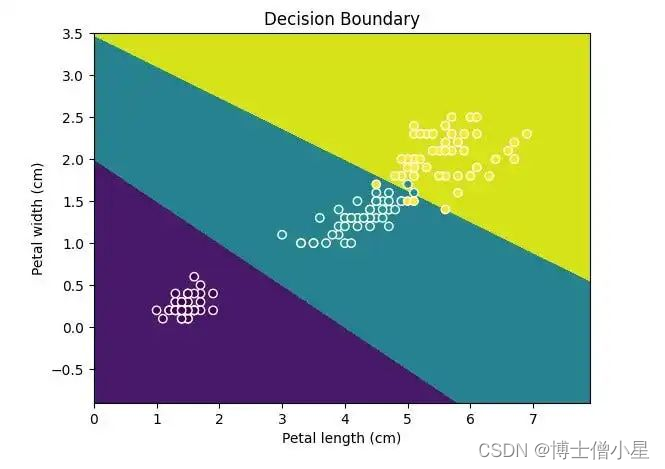
使用 DecisionBoundaryDisplay 绘制三重分类模型。
请记住,Display 只能绘制二维数据,因此请确保数据只有两个特征或更小的维度。
三、概率校准
要比较分类模型,使用 calibration.CalibrationDisplay 进行概率校准,概率校准曲线可以显示模型预测的可信度。
CalibrationDisplay使用的是模型的 predict_proba。如果使用支持向量机,需要将 probability 设为 True:
from sklearn.calibration import CalibrationDisplay from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification from sklearn.ensemble import HistGradientBoostingClassifier X, y = make_classification(n_samples=1000, n_classes=2, n_features=5, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) proba_clf = make_pipeline(StandardScaler(), SVC(kernel="rbf", gamma="auto", C=10, probability=True)) proba_clf.fit(X_train, y_train) CalibrationDisplay.from_estimator(proba_clf, X_test, y_test) hist_clf = HistGradientBoostingClassifier() hist_clf.fit(X_train, y_train) ax = plt.gca() CalibrationDisplay.from_estimator(hist_clf, X_test, y_test, ax=ax) plt.show()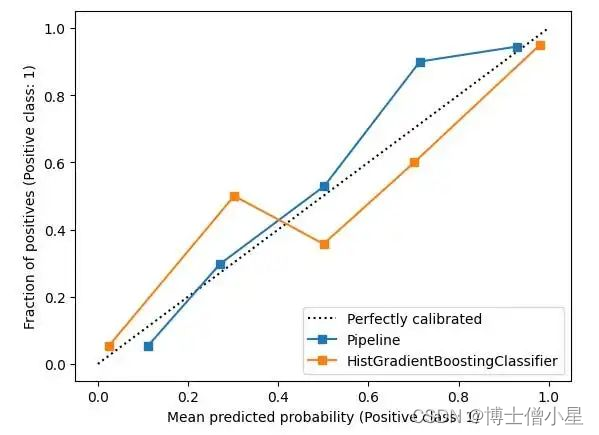
CalibrationDisplay.
四、显示混淆矩阵
在评估分类模型和处理不平衡数据时,需要查看精确度和召回率。使用 metrics.ConfusionMatrixDisplay绘制混淆矩阵(TP、FP、TN 和 FN)。
from sklearn.datasets import fetch_openml from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import ConfusionMatrixDisplay digits = fetch_openml('mnist_784', version=1) X, y = digits.data, digits.target rf_clf = RandomForestClassifier(max_depth=5, random_state=42) rf_clf.fit(X, y) ConfusionMatrixDisplay.from_estimator(rf_clf, X, y) plt.show()
五、Roc 和 Det 曲线
因为经常并列评估Roc 和 Det 曲线,因此把metrics.RocCurveDisplay 和 metrics.DetCurveDisplay两个图表放在一起。
-
RocCurveDisplay比较模型的 TPR 和 FPR。对于二分类,希望 FPR 低而 TPR 高,因此左上角是最佳位置。Roc 曲线向这个角弯曲。
由于 Roc 曲线停留在左上角附近,右下角是空的,因此很难看到模型差异。
-
使用 DetCurveDisplay 绘制一条带有 FNR 和 FPR 的 Det 曲线。它使用了更多空间,比 Roc 曲线更清晰。Det 曲线的最佳点是左下角。
from sklearn.metrics import RocCurveDisplay from sklearn.metrics import DetCurveDisplay X, y = make_classification(n_samples=10_000, n_features=5, n_classes=2, n_informative=2) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y) classifiers = { "SVC": make_pipeline(StandardScaler(), SVC(kernel="linear", C=0.1, random_state=42)), "Random Forest": RandomForestClassifier(max_depth=5, random_state=42) } fig, [ax_roc, ax_det] = plt.subplots(1, 2, figsize=(10, 4)) for name, clf in classifiers.items(): clf.fit(X_train, y_train) RocCurveDisplay.from_estimator(clf, X_test, y_test, ax=ax_roc, name=name) DetCurveDisplay.from_estimator(clf, X_test, y_test, ax=ax_det, name=name)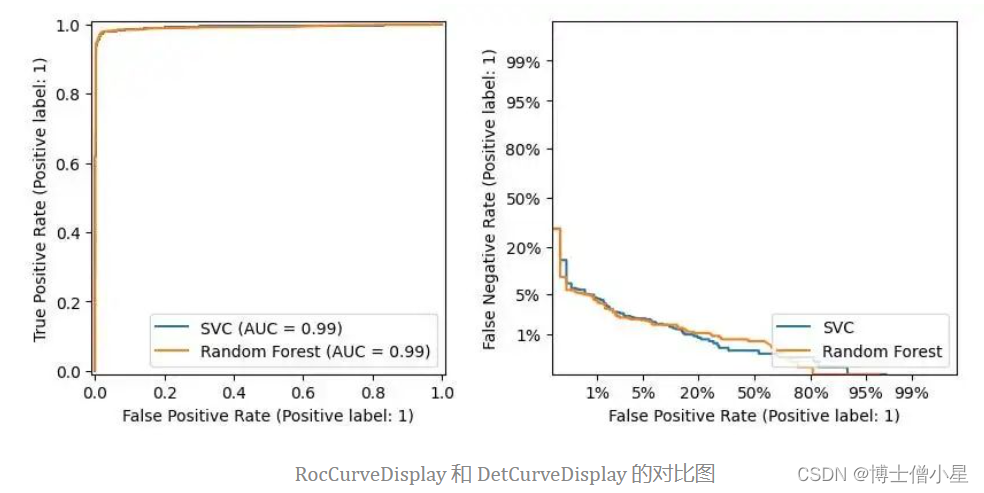
六、调整阈值
在数据不平衡的情况下,希望调整召回率和精确度。可以使用使用 metrics.PrecisionRecallDisplay 调整阈值
-
-







