

AI菜鸟向前飞 — LangChain系列之十 - RAG(上篇)
AI菜鸟向前飞 — LangChain系列之十一 - RAG(中篇)
先分享个问题的解法
# 在使用Chroma实例化过程中,可能会出现如下报错 AttributeError: type object 'hnswlib.Index' has no attribute 'file_handle_count'
当使用代码遇到如上问题时,你可以这么去解决:
pip uninstall hnswlib pip uninstall chroma-hnswlib pip install chroma-hnswlib
原因:chroma-hnswlib的一个bug导致,回到正题。
今天主要给大家介绍Indexing(索引),在正式介绍之前,先介绍个重要概念:持久化存储
向量化存储方式
在内存中
上一篇的例子,给大家演示的是非持久化存储
vector_store = Chroma(embedding_function=embeddings) # 因存储在内存中造成每次启动程序时,都要add_documents存储,否则无法查询到 print("看看有值吗:\n", vector_store.get(where={"source": {"$eq": "test.txt"}})) vector_store.add_documents(txt_docs) print("再看看有值吗:\n", vector_store.get(where={"source": {"$eq": "test.txt"}}))
看看有值吗:
{'ids': [], 'embeddings': None, 'metadatas': [], 'documents': [], 'uris': None, 'data': None}
再看看有值吗:
{'ids': ['5558fd95-9935-4070-861a-b9da7bfa8b92'], 'embeddings': None, 'metadatas': [{'source': 'test.txt'}], 'documents': ['南方将迎长达10天密集降雨热,\n苹果在中国1年收400亿苹果税,\n欢迎晚宴上他们都来了,\n湖北一村上百村民莫名有了营业执照, …………], 'uris': None, 'data': None}
持久化存储
vector_store_persist = Chroma(embedding_function=embeddings, persist_directory="./db")
# vector_store_persist.add_documents(txt_docs)
print("看看有值吗:\n", vector_store_persist.get(where={"source": {"$eq": "test.txt"}}))
结果
看看有值吗:
{'ids': ['425c92f3-7d61-44a4-b208-964586cc0e55'], 'embeddings': None, 'metadatas': [{'source': 'test.txt'}], 'documents': ['南方将迎长达10天密集降雨热,\n苹果在中国1年收400亿苹果税,\n欢迎晚宴上他们都来了,\n湖北一村上百村民莫名有了营业执照, …………], 'uris': None, 'data': None}
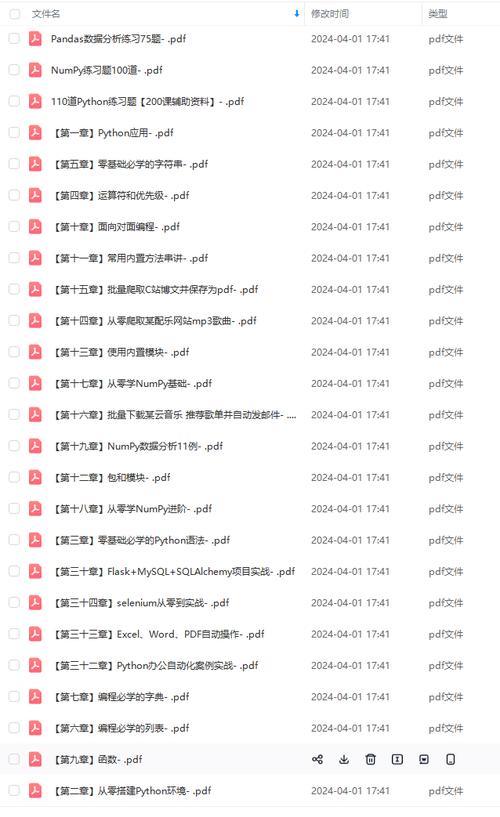
看磁盘里有什么 ![[Pasted image 20240513133207.png]]
问题来了,如果每次繁琐的调用add_documents或者是add_texts的话,遇到同一份文档,岂不是要存多次?LangChain提供了一个特别好用的API,它提供了三种索引维护(清理)模式:)
Indexing:接收的文档参数为Document对象,若对Document对象不熟悉的朋友,可参考
AI菜鸟向前飞 — LangChain系列之十一 - RAG(中篇)
| 清理模式 | 原文档被修改 向量存储是否删除 | 原文档被删除 向量存储是否删除 | 是否 支持并发 |
| None(无) | ❌ | ❌ | ✅ |
| Incremental(增量) | ✅ | ❌ | ✅ |
| Full(全量) | ✅ | ✅ | ❌ |
Document中metadata中有一个默认字段叫“source”,index也要用到它(source的含义是把文档块与原文档关联起来),用它与index的文档内容做关联。
为了更易于理解,让我们边看代码边“学习”吧
首先,让我们准备好持久化存储的方式,你猜猜为什么必须用这种呢?为什么不用内存方式的存储?
准备工作
向量化数据库
from langchain.indexes import SQLRecordManager, index vectorstore = Chroma(embedding_function=embeddings, persist_directory="./db") # 这个是第一次见,它的作用是把持久化的数据库作为记录管理... # 简单来说,index会需要往这里存数据,可以找到它 record_manager = SQLRecordManager(namespace="Chroma/langchain-index", db_url="sqlite://./db/chroma.sqlite3")
Document数据(注意source)
doc1 = Document(page_content="欢迎晚宴上他们都来了", metadata={"source": "dinner.txt"})
doc2 = Document(page_content="三组数据看实体经济发展质效提升", metadata={"source": "economy.txt"})
doc3 = Document(page_content="苹果在中国1年收400亿苹果税", metadata={"source": "apple.txt"})
索引函数的粗糙封装
def index_docs(doc: List[Document], record_manager=record_manager, vectorstore=vectorstore, cleanup=None, source_id_key="source", force_update=False):
return index(doc, record_manager, vectorstore, cleanup=cleanup, source_id_key=source_id_key, force_update=force_update)
(试验)正式开始
None模式程序
# 清除向量存储,这行代码的含义,看完本章后,你就懂了 index([], record_manager, vectorstore, cleanup="full", source_id_key="source") # line-one index_docs(doc=[doc1, doc1, doc1 ……(此处省略一万个], cleanup=None) # line-two index_docs(doc=[doc1, doc2], cleanup=None) # line-three index_docs(doc=[doc1, doc2, doc3], cleanup=None) # line-four doc3.page_content = "Apple 发布 M4芯片的iPad Pro" print("修改doc2之后,再次索引", index_docs([doc1, doc2, doc3], cleanup=None,source_id_key="source")) print("当前存储的数量", vectorstore._collection.count()) # line-five index_docs(doc=[], cleanup=None) # line-six print("源文档被删除,再次索引后,当前存储的数量", vectorstore._collection.count())
输出结果
# line-one
{'num_added': 1, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
# line-two
{'num_added': 1, 'num_updated': 0, 'num_skipped': 1, 'num_deleted': 0}
# line-three
{'num_added': 1, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 0}
# line-four
当前存储的数量 3
修改doc2之后,再次索引 {'num_added': 1, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 0}
当前存储的数量 4
# line-five
{'num_added': 0, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
# line-six
源文档被删除,再次索引后,当前存储的数量 4
重点解析:
-
line-one:无论传入多少个一样的文档,都会索引入向量数据库一次(num_added)
-
line-two:若遇到相同的文件,会跳过(num_skipped);不同的,会添加(num_added)
-
line-four:文档内容(page_content)被修改后,再次索引时会继续添加已修改后的文档内容到向量数据库(num_added),原来的所有数据都不会改变,虽然是跳过(num_skipped)两个,但已经存储的不会被删除或修改,存储的数量变成了4个
-
line-six:若再次索引时,原文档被删除(传入为空),所有已存储的数据无变化
Incremental 增量模式
程序
# line-one index_docs([doc1, doc2], cleanup="incremental") # line-two index_docs([doc1, doc2, doc3], cleanup="incremental", source_id_key="source") # line-three doc3.page_content = "Apple 发布 M4芯片13英寸平板电脑iPad Pro" print("修改doc2之后,再次索引", index_docs([doc1, doc2, doc3], cleanup="incremental", source_id_key="source")) # line-four print("当前存储的数量", vectorstore._collection.count()) # line-five index_docs([], cleanup="incremental", source_id_key="source") # line-six print("源文档被删除,再次索引后,当前存储的数量", vectorstore._collection.count())输出结果
# line-one {'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0} # line-two {'num_added': 1, 'num_updated': 2, 'num_skipped': 0, 'num_deleted': 0} # line-three 修改doc2之后,再次索引 {'num_added': 1, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 1} # line-four 当前存储的数量 3 # line-five {'num_added': 0, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0} # line-six 源文档被删除,再次索引后,当前存储的数量 3重点解析
-
line-two:若遇到相同的文件,会跳过(num_skipped);不同的,会添加(num_added)
-
line-three:文档内容(page_content)被修改后,再次索引时会删除已存储的原文档内容(num_deleted),添加已修改后的文档内容到向量数据库(num_added)
-
line-six:若再次索引时,原文档被删除(传入为空),所有已存储的数据无变化
Full全量模式
程序
# line-one index_docs([doc1, doc2], cleanup="full", source_id_key="source") # line-two index_docs([doc1, doc2, doc3], cleanup="full", source_id_key="source") # line-three doc3.page_content = "Apple 发布 M4芯片11英寸平板电脑iPad Pro" print("修改doc2之后,再次索引", index_docs([doc1, doc2, doc3], cleanup="full", source_id_key="source")) # line-four print("当前存储的数量", vectorstore._collection.count()) # line-five index_docs([], cleanup="full", source_id_key="source") # line-six print("源文档被删除,再次索引后,当前存储的数量", vectorstore._collection.count())输出结果
# line-one {'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0} # line-two {'num_added': 1, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 0} # line-three 修改doc2之后,再次索引 {'num_added': 1, 'num_updated': 0, 'num_skipped': 2, 'num_deleted': 1} # line-four 当前存储的数量 3 # line-fix {'num_added': 0, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 3} # line-six 源文档被删除,再次索引后,当前存储的数量 0重点解析
-
line-three:文档内容(page_content)被修改后,再次索引时会删除已存储的原文档内容(num_deleted),添加已修改后的文档内容到向量数据库(num_added)
-
line-six:若再次索引时,原文档被删除(传入为空),所有已存储的数据都将被删除(num_deleted)
这三种就介绍完了,但大家会发现有一个“num_updated“,从前到后都没有遇到过,是因为,要加一个参数 程序
index_docs(doc=[doc1, doc2]) index_docs(doc=[doc1, doc2, doc3], force_update=True)
输出结果
{'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0} {'num_added': 1, 'num_updated': 2, 'num_skipped': 0, 'num_deleted': 0}这次"num_updated"有值了吧 : )
具体要用哪种模式,根据场景选择不同的,另外还要注意的有:
当内容发生变化时,在索引期间将有一段时间新旧版本都可能返回给用户——这是因为在新内容写入时,旧版本还没被删除之前造成的
需要用好不同的模式:
-
Incremental模式:可以最大限度地减少这段时间,因为它能够在写入时连续进行清理
-
Full模式:在所有的都写入后进行清理
关于Retriever
最后让我们看下 对于RAG中一个特别重要的Retriever,先来讲常用参数:
Top K 前K个结果
程序
texts = [ "南方将迎长达10天密集降雨热", "苹果在中国1年收400亿苹果税", "欢迎晚宴上他们都来了", "湖北一村上百村民莫名有了营业执照", "三组数据看全国实体经济发展质效提升", "南方即将迎来密集降雨热天气,长达10多天", "台湾地震把福州乌塔震歪?假的", "在中国1年苹果被收400亿苹果税", "上海外滩特警回应因为太帅走红", "北京", "我在上海东方明珠广场" ] dbstore = Chroma.from_texts(texts=texts, embedding=DashScopeEmbeddings(model="text-embedding-v2")) retriver = dbstore.as_retriever(search_kwargs={'k': 3}) res = retriver.invoke("请根据文中的信息内容只回答出关于城市地点的内容") print(res)输出结果
[Document(page_content='北京'), Document(page_content='南方将迎长达10天密集降雨热') Document(page_content='南方即将迎来密集降雨热天气,长达10多天')]
MMR 最大边界相似性
程序
retriver = dbstore.as_retriever(search_type="mmr", search_kwargs={'k': 3}) res = retriver.invoke("请根据文中的信息内容只回答出关于城市地点的内容") print(res)输出结果
[Document(page_content='北京'), Document(page_content='南方将迎长达10天密集降雨热') Document(page_content='台湾地震把福州乌塔震歪?假的')]
与Top K比较一下:),你就能看到MMR的妙处了
Similarity score threshold 相似度阈值
程序
retriver = dbstore.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.7}) res = retriver.invoke("请根据文中的信息内容只回答出北京的内容")输出结果
[Document(page_content='北京')]
总结
对RAG的介绍暂时告一段落,涉及到一些高级的Retriever,等后面有空单独开个专题再给大家介绍,实在是太重磅、内容相当多,到时与agent一起介绍。
-
-
-







