

PaddleSpeech简介
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
PaddleSpeech安装步骤
提示:要找到一个合适的PaddleSpeech版本与paddlepaddle适配非常困难!官方文档也没有明确告诉我们PaddleSpeech要与哪个版本的python、paddlepaddle、cuda版本适配,只能自己尝试。经过N多次尝试,终于找到了能用的版本。因此,请严格按照下文的步骤执行。
相关依赖:
- gcc >= 4.8.5
- paddlepaddle = 3.8
安装docker版paddlepaddle
下面将用docker安装PaddleSpeech,这样会遇到更少的问题,更容易成功!
准备工作:
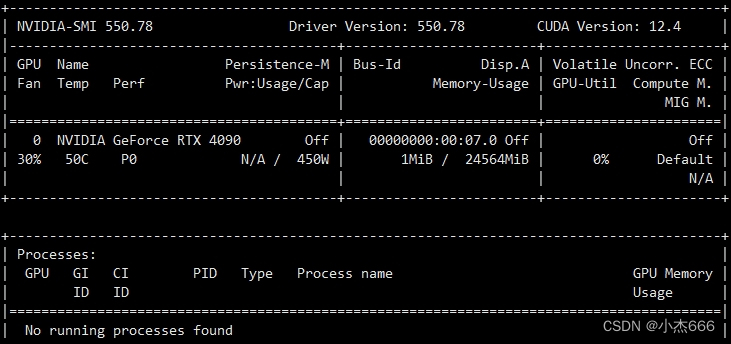
- 带GPU(以RTX4090为例)的Ubuntu 22.04系统,在 这里 下载550.78驱动的 .run 文件到Ubuntu系统内,运行命令(都以root身份运行):
# 更新系统 apt update apt upgrade # 重启系统 reboot # 安装驱动 chmod +x NVIDIA-Linux-x86_64-550.78.run # 安装过程中如果遇到需要重新打包内核,选择 "rebuild ini..." ./NVIDIA-Linux-x86_64-550.78.run # 安装成功后,重启系统 reboot # 查看是否安装成功,如果驱动安装成功,会显示如下图内容 nvidia-smi
2. 在系统中用apt安装docker:
# 删除旧版 for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done # 用apt安装新版docker sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin # 测试是否安装成功,如果成功,会输出hello-world镜像的内容 sudo docker run hello-world
- 安装 NVIDIA Container Toolkit:
# 用apt方式安装NVIDIA Container Toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# 配置NVIDIA Container Toolkit
# 如下命令会修改docker配置文件/etc/docker/daemon.json,没有则创建
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
- 安装docker版本paddlepaddle
# 下载完镜像后,可用命令 docker inspect 查看镜像创建时间 docker pull paddlepaddle/paddle:2.5.1-gpu-cuda11.2-cudnn8.2-trt8.0
在容器中安装PaddleSpeech
cd
vim docker-compose.yml
# 内容如下
services:
paddlespeech:
image: paddlepaddle/paddle:2.5.1-gpu-cuda11.2-cudnn8.2-trt8.0
container_name: paddle251
network_mode: host
entrypoint: ["/bin/bash", "/home/docker-entrypoint.sh"]
volumes:
- /root/docker-entrypoint.sh:/home/docker-entrypoint.sh
- /root/tests:/paddle
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: always
- 写一个入口脚本
vim docker-entrypoint.sh
# 内容如下:
#!/bin/bash
while true
do
echo "loop forever, sleep 3600"
sleep 3600
done
- 启动paddlepaddle容器
Docker Compose up -d
- 进入容器
# 查看容器,STATUS下面如果是 "Up ..." 表示容器启动成功 docker ps # 进入容器 docker exec -it paddle251 /bin/bash
- 安装PaddleSpeech,推荐编译安装:
# 克隆 git clone https://github.com/PaddlePaddle/PaddleSpeech.git cd PaddleSpeech mkdir ~/.pip echo -e '[global]\nindex-url = https://pypi.tuna.tsinghua.edu.cn/simple\ntrusted-host = pypi.tuna.tsinghua.edu.cn' > ~/.pip/pip.conf pip install -U 'pip>21.0,>> from paddlespeech.cli.asr.infer import ASRExecutor >>> asr = ASRExecutor() >>> result = asr(audio_file="zh.wav") >>> print(result) 我认为跑步最重要的就是给我带来了身体健康
- 语音合成
命令行一键体验
paddlespeech tts --input "你好,欢迎使用百度飞桨深度学习框架!" --output output.wav
Python API 一键预测
>>> from paddlespeech.cli.tts.infer import TTSExecutor >>> tts = TTSExecutor() >>> tts(text="今天天气十分不错。", output="output.wav")
- 声音分类
命令行一键体验
paddlespeech cls --input zh.wav
Python API 一键预测
>>> from paddlespeech.cli.cls.infer import CLSExecutor >>> cls = CLSExecutor() >>> result = cls(audio_file="zh.wav") >>> print(result) Speech 0.9027186632156372
- 声纹提取
命令行一键体验
paddlespeech vector --task spk --input zh.wav
Python API 一键预测
>>> from paddlespeech.cli.vector import VectorExecutor >>> vec = VectorExecutor() >>> result = vec(audio_file="zh.wav") >>> print(result) # 187维向量 [ -0.19083306 9.474295 -14.122263 -2.0916545 0.04848729 4.9295826 1.4780062 0.3733844 10.695862 3.2697146 -4.48199 -0.6617882 -9.170393 -11.1568775 -1.2358263 ...]
- 标点恢复
命令行一键体验
paddlespeech text --task punc --input 今天的天气真不错啊你下午有空吗我想约你一起去吃饭
Python API 一键预测
>>> from paddlespeech.cli.text.infer import TextExecutor >>> text_punc = TextExecutor() >>> result = text_punc(text="今天的天气真不错啊你下午有空吗我想约你一起去吃饭") 今天的天气真不错啊!你下午有空吗?我想约你一起去吃饭。
- 语音翻译
命令行一键体验
使用预编译的 kaldi 相关工具,只支持在 Ubuntu 系统中体验
paddlespeech st --input en.wav
Python API 一键预测
>>> from paddlespeech.cli.st.infer import STExecutor >>> st = STExecutor() >>> result = st(audio_file="en.wav") ['我 在 这栋 建筑 的 古老 门上 敲门 。']
- 测试中可能遇到 UserWarning 警告,可以不管,或者用 warnings.filterwarnings(“ignore”, category=WarningCategory) 屏蔽
更多测试用例见 这里,使用服务见 这里
参考:
https://www.cnblogs.com/iyiluo/p/17688647.html







