

5.2 基于人工智能的信号灯识别系统
随着人工智能技术的发展,在机器人运动、智能交通系统、自动驾驶车辆、交通监控等应用中,可以使用机器学习技术实现交通信号的识别与决策。其中常用的机器学习算法如下:
实例5-8:基于CNN的交通信号识别系统(codes/5/cnn-traffic-signals-identify.ipynb)
5.2.1 项目背景和介绍
交通信号牌识别是计算机视觉领域的一个重要任务,具有广泛的应用前景,例如智能交通系统和自动驾驶技术。本项目致力于构建一个能够识别交通信号牌的深度学习模型,通过对图像进行分类,实现对不同类型交通信号牌的准确识别。本项目的主要功能是实现交通信号牌的识别任务,包括数据集的探索、预处理、模型的构建、训练和评估。整个项目的具体功能如下:
- 项目目标:项目的主要目标是构建一个模型,能够对交通信号牌进行识别。这是一个典型的计算机视觉任务,需要利用深度学习技术来学习图像中的特征,并进行分类。
- 数据集探索:项目开始时对数据集进行了探索,包括了随机展示训练集中的图片、查看交通信号牌类别以及了解数据集的分布情况。通过可视化,可以更好地理解数据的特点。
- 数据预处理:在项目中,进行了数据预处理的步骤,包括加载训练集和测试集的图片,将图片转换为灰度图,调整图片大小,对标签进行编码等。
- 模型构建:项目使用了卷积神经网络(CNN)作为模型,具体是一个LeNet5风格的网络。这个网络结构包含卷积层、池化层、全连接层等,适用于图像分类任务。
- 数据增强:为了增加模型的鲁棒性,引入了数据增强的方法。项目中使用了仿射变换(affine transformation)对训练集进行增强,包括旋转、缩放、平移等。
- 训练和调参:项目进行了模型的训练,并实现了基本的训练循环。使用了交叉熵损失函数进行训练,同时监控了训练和验证集的损失和准确率。为了提高模型性能,还实现了学习率的调整机制,以及在验证集上进行了早期停止。
- 结果展示:最后,通过 Matplotlib 绘制了训练过程中损失、准确率以及学习率的曲线图,用于观察模型的训练情况。
总体来说,本项目覆盖了计算机视觉任务的各个方面,从数据处理到模型训练,再到结果展示。这是一个实际的深度学习项目,可以帮助理解图像分类任务的基本流程和技术要点。
5.2.2 具体实现
实例文件cnn-traffic-signals-identify.ipynb具体实现流程如下所示。
1. 准备数据
(1)定义展示交通信号牌的函数show_sign(),该函数接受一组图像(imgs)和相应的标签(tags),并在一个图形界面中以每行显示一定数量的列的形式展示这些图像。
# 展示交通信号牌
def show_sign(imgs, tags, per_row=2):
n = len(imgs)
rows = (n + per_row - 1)//per_row
cols = min(per_row, n)
fig, axes = plt.subplots(rows,cols, figsize=(24//per_row*cols,24//per_row*rows))
for ax in axes.flatten(): ax.axis('off')
for i,(img,ax) in enumerate(zip(imgs, axes.flatten())):
ax.imshow(img.convert('RGB'))
ax.set_title(tags[i])
函数show_sign()的目的是使用户能够方便地查看一组交通信号牌图像,并对它们进行标记。各个参数的具体说明如下:
- 参数per_row:表示每一行要显示的列数,默认为2。
- 参数n:表示图像的总数量。
- 参数rows:表示计算得到的行数,通过除法和向上取整来确定。
- 参数cols:表示每一行实际上要显示的列数,取 per_row 和总图像数量的较小值。
(2)从训练集中随机选择100张图片,然后使用之前定义的函数show_sign()展示这些图片,并附带它们的标签。
trainlist = glob('../input/traffic-lights-identify/data/train/*/*')
### 随机展示100张训练集图片
example = [rd.randint(0, len(trainlist)-1) for _ in range(100)]
imgs = [pil_image.open(trainlist[i]) for i in example]
def tag(i):
m = trainlist[i].split('/')[-2]
return str(int(m))
tags = [tag(i) for i in example]
show_sign(imgs, tags, per_row=10)
执行后调用函数show_sign(),将100张图片以每行10列的形式展示出来,并显示相应的标签。其中部分截图如图2-8所示。

图2-8 展示的部分图片
(3)使用库PrettyTable 创建了一个漂亮的表格,用于展示交通信号牌类别的名称和对应的索引值,这样的表格对于理解数据集中不同类别的交通信号牌以及它们的索引是非常有帮助的。
from prettytable import PrettyTable
#将signName和索引打成一个字典
sign_names = dict([(p,w) for _,p,w in read_csv('../input/traffic-lights-identify/data/signnames.csv').to_records()])
#创建一个PrettyTable对象
sign_name_table = PrettyTable()
#添加PrettyTable字段名称
sign_name_table.field_names = ['class value', 'Name of Traffic sign']
#添加字典进入PrettyTable中
for index,sign in sign_names.items():
sign_name_table.add_row([index,sign])
sign_name_table
2. 导入数据集
加载训练集和测试集,并进行必要的预处理,以便将数据导入神经网络进行训练和测试。
SIZE = (32,32)
n_class = len(sign_names)
### 导入训练集
train = {}
train['features'] = []
train['label'] = []
print('Loading the training set:')
for sign in tqdm(range(n_class)):
path = '../input/traffic-lights-identify//data/train/' + str(sign).zfill(5) + '/*'
for i in glob(path):
img = pil_image.open(i)
img = img.convert('L') # 将图像转变为灰度图
train['features'].append(np.array(img.resize(SIZE)))
train['label'].append(sign)
train['label'] = np.array(train['label'])
### 导入测试集
test = {}
test['features'] = []
test['label'] = []
print('Loading the testing set:')
path = '../input/traffic-lights-identify/data/test/*'
for i in tqdm(glob(path)):
img = pil_image.open(i)
img = img.convert('L')
test['features'].append(np.array(img.resize(SIZE)))
n_train, n_test = len(train['features']), len(test['features'])
### 对数据特征进行维度匹配以便导入神经网络
train['features'] = np.expand_dims(train['features'], axis=-1)
test['features'] = np.expand_dims(test['features'], axis=-1)
print('Total number of classes:{}'.format(n_class))
print('Number of training examples =',n_train)
print('Number of testing examples =',n_test)
print('Image data shape=',train['features'].shape[1:])
上述代码的具体实现流程如下所示:
- SIZE 定义了图像的大小,这里是 (32, 32)。
- n_class 是交通信号牌的类别数量,由之前加载的 sign_names 字典得到。
- 创建了一个空的字典train,包含 'features' 和 'label' 两个键,用于存储训练集的图像特征和标签。
- 使用 glob 函数遍历训练集中的每个类别和图像,将图像转换为灰度图,调整大小为指定的 SIZE,并将特征和标签分别添加到 train 字典中。
- 创建了一个空的字典test,用于存储测试集的图像特征和标签。
- 对测试集的图像进行相同的处理,然后记录训练集和测试集的大小,以及图像的维度信息。
- 通过 np.expand_dims 将图像特征的维度进行扩展,以便适应神经网络的输入要求。
- 最后,打印输出数据集和图像维度的一些基本信息:
Loading the training set:
100%
43/43 [01:09run the dataaumentation op
if total_extra_imgs > 0:
X_extra = np.zeros((int(total_extra_imgs),img_height,img_width,img_depth),dtype=X_dataset.dtype)
y_extra = np.zeros(int(total_extra_imgs))
start_idx = 0
#print('start data augmentation.....')
for this_class in range(n_classes):
#print('\t Class {}|Number of extra imgs{}'.format(this_class,int(extra_imgs_per_class[this_class])))
n_extra_imgs = extra_imgs_per_class[this_class]
end_idx = start_idx + n_extra_imgs
if n_extra_imgs > 0:
#get ids of all images belonging to this_class
all_imgs_id = np.argwhere(y_dataset==this_class)
new_imgs_x = np.zeros((int(n_extra_imgs),img_height,img_width,img_depth))
for k in range(int(n_extra_imgs)):
#randomly pick an original image belonging to this class
rand_id = np.random.choice(all_imgs_id[0],size=None,replace=True)
rand_img = X_dataset[rand_id]
#Transform image
new_img = random_transform(rand_img)
new_imgs_x[k,:,:,:] = new_img
#update tensors with new images and associated labels
X_extra[int(start_idx):int(end_idx)] = new_imgs_x
y_extra[int(start_idx):int(end_idx)] = np.ones((int(n_extra_imgs),))*this_class
start_idx = end_idx
return [X_extra,y_extra]
else:
return [None,None]
上述代码的实现流程如下所示:
- 函数 data_augmentation()会根据用户的选择,决定是否保持原始数据集的类别分布。如果 keep_dist 设置为 True,则会按原始数据集的类别分布增加数据;如果设置为 False,则会平衡数据集,使每个类别都有相同数量的图像。
- 接着,根据用户的选择和参数,计算出每个类别需要增加的图像数量,并创建一个新的数组 extra_imgs_per_class 存储这些数量。
- 接下来,判断是否需要额外的数据增强。如果需要,创建新的数组 X_extra 和 y_extra 以存储增强后的图像和标签。然后,对每个类别进行循环,选择原始数据集中的图像,通过调用之前定义的 random_transform 函数进行随机仿射变换,并将增强后的图像和标签存储在 X_extra 和 y_extra 中。
- 最后,返回增强后的数据集 [X_extra, y_extra],其中 X_extra 包含增强后的图像,y_extra 包含对应的标签。
(4)通过如下代码实现数据集的划分和数据增强功能,这个过程旨在通过数据增强来扩充训练集,使模型更好地学习并提高泛化性能。
from sklearn.model_selection import train_test_split
# TODO: split the data into training and validation subsets
X_train, X_valid, y_train, y_valid= train_test_split(train['features'], train['label'], test_size=0.2, random_state=42)
print('*** Before data augmentation:')
print('Train set size:{}|Validation set size:{}\n'.format(X_train.shape[0],X_valid.shape[0]))
X_extra,y_extra = data_augmentation(X_train,y_train,augm_nbr=2000,keep_dist=False)
if X_extra is not None:
X_train = np.concatenate((X_train,X_extra.astype('uint8')),axis=0)
y_train = np.concatenate((y_train,y_extra),axis=0)
del X_extra,y_extra
print('*** After data augmentation:')
print('Train set size:{}|Validation set size:{}\n'.format(X_train.shape[0],X_valid.shape[0]))
with mpl.rc_context(rc={'font.family': 'serif', 'font.size': 11}):
fig = plt.figure(figsize=(9.5,3.5))
ax1 = fig.add_subplot(121)
plt.bar(np.arange(n_class),get_count_imgs_per_class(y_train),align='center')
ax1.set_xlabel('Class')
ax1.set_ylabel('Frequency')
ax1.set_title('Training Set')
plt.xlim([-1,43])
ax2 = fig.add_subplot(122)
plt.bar(np.arange(n_class),get_count_imgs_per_class(y_valid),align='center')
ax2.set_xlabel('Class')
ax2.set_ylabel('Frequency')
ax2.set_title('Validation Set')
plt.xlim([-1,43])
上述代码的实现流程如下所示:
- 首先,使用函数train_test_split()将训练数据集划分成训练集 X_train, y_train 和验证集 X_valid, y_valid,其中划分比例为 80% 的训练集和 20% 的验证集。
- 接着,打印出划分前的数据集大小。
- 然后,调用之前定义的 data_augmentation 函数进行数据增强,将额外的数据添加到训练集中。如果需要额外数据,将其追加到原始训练集中。
- 最后,打印出划分后的训练集和验证集的大小:
*** Before data augmentation: Train set size:21312|Validation set size:5328 *** After data augmentation: Train set size:86000|Validation set size:5328
- 使用 Matplotlib 绘制了两个柱状图,分别表示训练集和验证集中每个类别的图像数量。如图2-8所示。
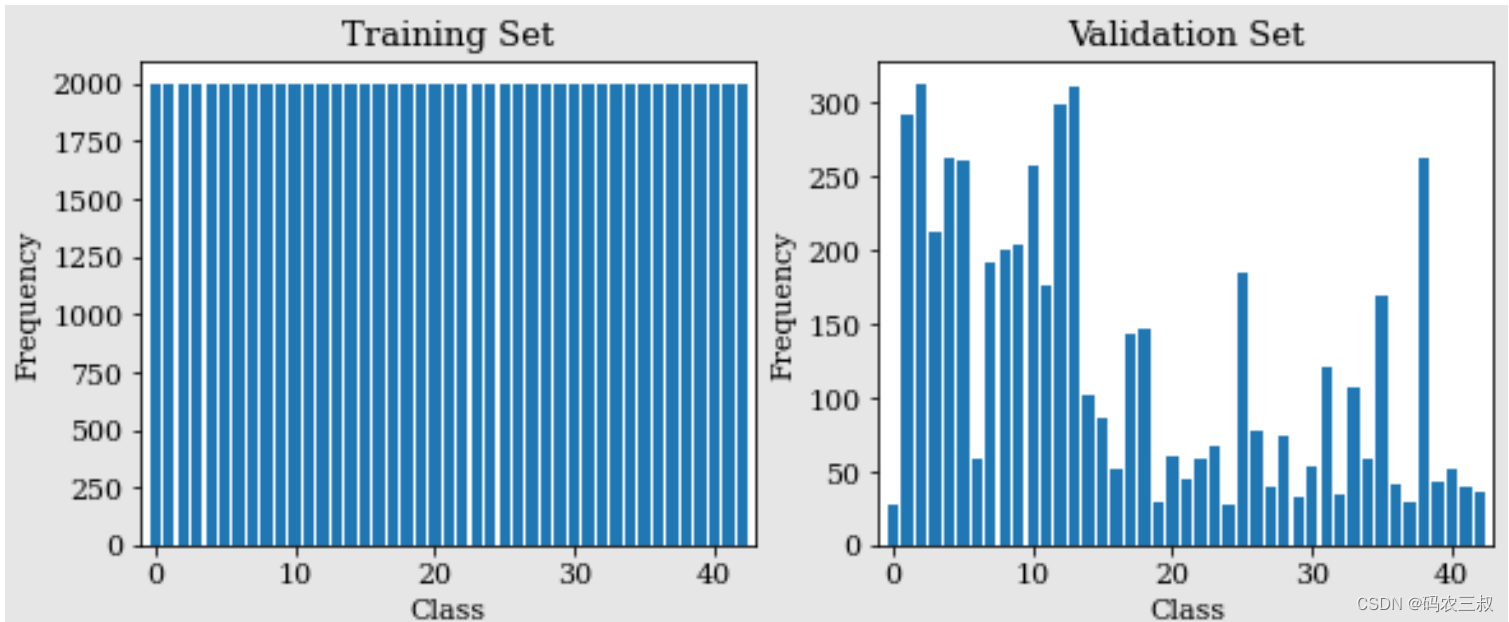
图2-8 训练集和验证集中每个类别的图像数量
4. 构建CNN模型
(1)定义函数preprocessed(),用于对输入的图像数据集进行预处理,其中主要的预处理工作是将图像的像素值缩放到范围 [-0.5, 0.5]。
def preprocessed(dataset):
n_imgs,img_height,img_width,_ = dataset.shape
processed_dataset = np.zeros((n_imgs,img_height,img_width,1))
for i in range(len(dataset)):
img = dataset[i]
processed_dataset[i,:,:,:] = img/255.-0.5
return processed_dataset
X_train, X_valid = preprocessed(X_train), preprocessed(X_valid)
X_train.shape
在上述代码中,对训练集 X_train 和验证集 X_valid 分别调用了 preprocessed 函数,将处理后的数据集保存在相同的变量中。最后打印输出形状大小信息:
(86000, 32, 32, 1)
(2)通过如下代码返回指定图像的形状,由于 X_train 是一个数据集,X_train[1] 表示该数据集中的第二个样本(图像)。因此,X_train[1].shape 将返回该图像的形状。
X_train[1].shape
执行后会输出:
(32, 32, 1)
(3)定义一个名为 TrafficDataset 的数据集类,用于封装交通数据集。这个类继承自 PyTorch 的 Dataset 类,这是一个抽象类,需要实现 __getitem__ 和 __len__ 两个方法。
import torch
#Dataset是一个类 DataLoader是一个封装
from torch.utils.data import Dataset, DataLoader
#封装交通数据集
class TrafficDataset(Dataset): # from torch.utils.data import Dataset
def __init__(self, data, label):
self.data = data
self.label = label
def __getitem__(self, index):
img = self.data[index]
img = torch.Tensor(img)
#需要把最后一位(表示通道数)挪到数组的第一位去
#permute作用是改变Tensor的维度
img = img.permute(2,0,1).type(torch.FloatTensor)
if self.label is not None:
target = int(self.label[index])
else:
target = 100
return img,target
def __len__(self):
return self.data.shape[0]
(4)使用 PyTorch中的类DataLoader创建训练、验证和测试数据加载器,这些数据加载器将在训练、验证和测试阶段用于按批次加载数据,方便模型的训练和评估。
bs = 256 #shuffle表示是否打乱数据 train_loader = DataLoader(TrafficDataset(X_train, y_train), batch_size=bs, shuffle=True, num_workers=0) valid_loader = DataLoader(TrafficDataset(X_valid, y_valid), batch_size=bs, shuffle=True, num_workers=0) test_loader = DataLoader(TrafficDataset(test['features'], None), batch_size=bs, shuffle=False, num_workers=0)
(5)从训练数据加载器 train_loader 中获取一个批次的数据,其中 x 是图像数据,y 是对应的标签。通过 for x, y in train_loader: break 这样的语句,可以获取第一个批次的数据。最后,通过 y 查看该批次中图像的标签。
for x,y in train_loader:
break
y
执行后会输出:
tensor([41, 29, 11, 23, 16, 15, 19, 24, 2, 29, 38, 35, 24, 18, 3, 31, 10, 21,
41, 11, 19, 7, 35, 26, 27, 29, 16, 11, 24, 20, 37, 14, 42, 27, 25, 30,
12, 8, 14, 40, 31, 27, 26, 17, 5, 31, 31, 28, 3, 12, 13, 1, 6, 11,
5, 40, 39, 9, 36, 0, 22, 37, 20, 27, 8, 26, 23, 42, 1, 16, 7, 13,
40, 6, 28, 26, 4, 26, 36, 42, 30, 3, 16, 16, 39, 42, 12, 3, 3, 27,
4, 24, 21, 14, 33, 38, 2, 9, 9, 21, 39, 8, 35, 30, 1, 14, 27, 42,
34, 2, 38, 32, 26, 41, 14, 22, 30, 40, 14, 7, 42, 15, 5, 42, 21, 8,
37, 3, 32, 4, 28, 42, 28, 41, 21, 14, 14, 28, 15, 0, 6, 3, 24, 24,
13, 3, 14, 32, 8, 33, 19, 23, 3, 1, 27, 20, 2, 13, 2, 28, 27, 20,
12, 24, 20, 28, 42, 3, 39, 28, 9, 5, 19, 39, 38, 4, 2, 6, 38, 18,
19, 24, 28, 22, 10, 40, 42, 37, 22, 0, 4, 40, 37, 31, 25, 11, 9, 9,
27, 17, 34, 42, 31, 9, 31, 21, 4, 13, 20, 0, 24, 9, 16, 2, 23, 15,
16, 12, 10, 24, 17, 29, 35, 36, 3, 24, 40, 8, 19, 26, 6, 39, 8, 25,
36, 29, 0, 12, 37, 25, 17, 27, 14, 31, 21, 19, 14, 11, 10, 26, 35, 26,
28, 10, 25, 29])
(6)定义了一个名为 TrafficNet 的卷积神经网络(CNN)模型,模型的输出将用于计算损失,并在训练过程中进行优化。
import torch
from torch import nn, optim
from torch.nn import functional as F
# CNN模型主题 上面定义方法 下面直接进行调用
class TrafficNet(nn.Module):
def __init__(self, num_classes):
#这里注意一定一定要添加这个!!注意继承规则
super().__init__()
self.num_classes = num_classes
self.conv0 = nn.Conv2d(1,6,5)
self.pool0 = nn.MaxPool2d(2)
self.conv1 = nn.Conv2d(6,16,5)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16,400,5)
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(800,num_classes)
#上面这两层可以写成这样 Sequential表示一个序列
#self.fc = nn.Sequential(nn.Dropout(0.2),nn.Linear(800,num_classes))
#注意:Pytorch中最后一层的激活函数内含在损失函数中 不能再在这里添加一个激活函数
#上面定义卷积 下面来调用
def forward(self, x):
x = self.conv0(x)
x = torch.relu(x)
x = self.pool0(x)
x = self.conv1(x)
x = torch.relu(x)
x1 = self.pool1(x)
x2 = self.conv2(x1)
x3 = torch.relu(x2)
x4 = torch.flatten(x1,start_dim = 1)
x5 = torch.flatten(x3,start_dim = 1)
x6 = torch.cat((x4,x5),dim = 1)
x = self.fc(x6)
return x
model = TrafficNet(num_classes=n_class)
对上述代码的具体说明如下:
- __init__ 方法:模型的初始化方法,定义了模型的各个层,包括卷积层 (Conv2d)、池化层 (MaxPool2d)、全连接层 (Linear) 以及 Dropout 层。这里使用了三个卷积层和两个池化层,以及一个全连接层,最后输出模型的预测结果。
- forward 方法:定义了数据在模型中的前向传播过程。在这个方法中,对输入的数据依次经过卷积、激活函数(ReLU)、池化等操作,最终通过全连接层输出预测结果。
- 通过 flatten 操作将两个卷积层的输出展平。
- 将展平后的两部分连接在一起。
- 通过全连接层 (fc) 输出最终的预测结果。
5. 训练模型
(1)准备训练所需的基础设施,包括文件夹的创建、设备的选择、损失函数的定义以及优化器的设置。
if not os.path.exists('models'):
os.makedirs('models') # 用于储存模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
criterion = nn.CrossEntropyLoss()
model = model.to(device)
lr = 0.001
optimizer = optim.Adam(model.parameters(), lr=lr)
(2)通过如下代码实现了一个简单的 PyTorch 训练循环,这个训练循环执行了多个训练周期(epoch),每个 epoch 都会遍历整个训练数据集。在每个 epoch 中,模型的参数会根据损失进行更新,并且在训练过程中的损失值将被记录。注意,这只是一个简化版本的训练循环,适用于快速了解和尝试。在实际应用中,通常还需要添加验证集的评估、学习率调整、模型保存等功能。
def train_model(epoch, history=None):
model.train()
t = tqdm(train_loader)
for batch_idx, (img_batch, label_batch) in enumerate(t):
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
optimizer.zero_grad()
output = model(img_batch)
loss = criterion(output, label_batch)
t.set_description(f'train_loss (l={loss:.4f})')
if history is not None:
history.loc[epoch + batch_idx / len(train_loader), 'train_loss'] = loss.data.cpu().numpy()
loss.backward()
optimizer.step()
torch.save(model.state_dict(), 'models/epoch{}.pth'.format(epoch))
(3)定义验证函数 evaluate(),用于在每个训练周期结束后对模型进行验证。这个验证函数在模型训练中用于评估模型在验证集上的性能,并可以用于调整超参数或选择最佳模型。
from sklearn.metrics import accuracy_score
def evaluate(epoch, history=None): # 验证函数
model.eval() # 开启验证模式,此时模型的参数不可修改
valid_loss = 0.
all_predictions, all_targets = [], []
with torch.no_grad():
for batch_idx, (img_batch, label_batch) in enumerate(valid_loader):
all_targets.append(label_batch.numpy().copy())
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
output = model(img_batch)
loss = criterion(output, label_batch)
valid_loss += loss.data
predictions = torch.argmax(torch.softmax(output, axis=-1), axis=-1)
all_predictions.append(predictions.cpu().numpy())
all_predictions = np.concatenate(all_predictions)
all_targets = np.concatenate(all_targets)
valid_loss /= (batch_idx+1)
valid_acc = accuracy_score(all_targets, all_predictions)
if history is not None:
history.loc[epoch, 'valid_loss'] = valid_loss.cpu().numpy()
print('Epoch: {}\tLR: {:.6f}\tValid Loss: {:.4f}\tValid Acc: {:.4f}'.format(
epoch, optimizer.state_dict()['param_groups'][0]['lr'], valid_loss, valid_acc))
return valid_loss, valid_acc
(4)如下代码实现了一个基本的训练循环,其中包含学习率的调整机制。在每个训练周期中,调用了 train_model 函数进行模型训练,然后调用了 evaluate 函数进行验证,并记录相应的指标。如果验证集上的损失没有下降并持续超过 patience 个周期,就会降低学习率。如果学习率的调整次数超过了 max_lr_changes,则提前停止训练。
history_train = pd.DataFrame()
history_valid = pd.DataFrame()
n_epochs = 100
init_epoch = 0
max_lr_changes = 2
valid_losses = []
valid_accs = []
lrs = []
lr_reset_epoch = init_epoch
patience = 3
lr_changes = 0
best_valid_loss = 1000.
for epoch in range(init_epoch, n_epochs):
torch.cuda.empty_cache()
gc.collect()
train_model(epoch, history_train)
valid_loss, valid_acc = evaluate(epoch, history_valid)
valid_losses.append(valid_loss)
valid_accs.append(valid_acc)
if valid_loss patience and
min(valid_losses[-patience:]) > best_valid_loss):
# "patience" epochs without improvement
lr_changes +=1
if lr_changes > max_lr_changes: # 早期停止
break
lr /= 5 # 学习率衰减
print(f'lr updated to {lr}')
lr_reset_epoch = epoch
optimizer.param_groups[0]['lr'] = lr
lrs.append(optimizer.param_groups[0]['lr'])
执行后会打印输出训练过程:
train_loss (l=0.4790): 100% 336/336 [00:09







