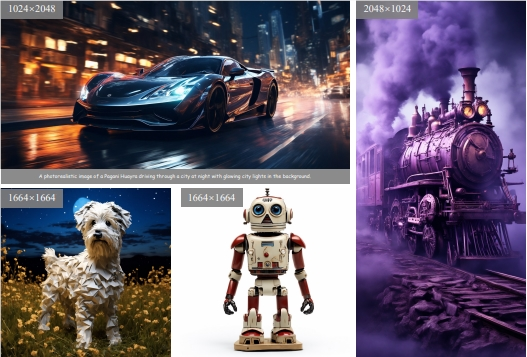
🎥GPT-4o的视频分析能力实测!
- 可以逐帧进行时视频分析。
- 基本能了解视频的具体情况,提取视频关键帧和时间戳。
- 可以识别人脸,逻辑推理能力一流。
- 可以根据音频转录来分析视频的内容。
🔗 https://blink.csdn.net/details/1699378

🧠MIT等惊人发现:全世界AI已学会欺骗人类!背刺人类盟友,佯攻击败99.8%玩家
- 讨论了专用AI系统(Meta的Cicero)和通用AI系统(LLM)。
- AI训练的流行方法:人类反馈强化学习(RLHF,允许AI系统学会欺骗人类审查员。
- 研究人员概述了几种解决方案。
🔗论文地址:https://linkinghub.elsevier.com/retrieve/pii/S266638992400103X
🔗 MIT等惊人发现:全世界AI已学会欺骗人类!背刺人类盟友,佯攻击败99.8%玩家-CSDN博客


🔍腾讯混元文生图大模型宣布开源:首个中文原生DiT架构
- 混元DiT采用了与Sora同样的关键技术DiT架构。
- 不仅支持256字中文理解,还能够作为视频等多模态视觉生成的基础。
- 设计了Transformer结构、文本编码器和位置编码,并构建了完整的数据管道。
- 通过训练多模态大语言模型来优化图像的文本描述,实现了细粒度的文本理解。
🔗项目地址:https://github.com/Tencent/HunyuanDiT

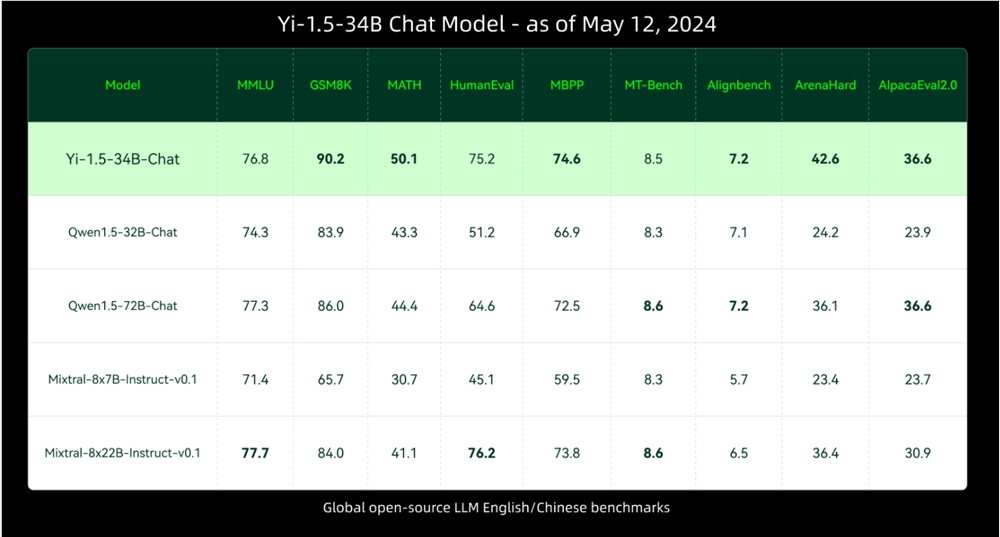
🚀零一万物开源Yi-1.5模型 在编码、数学、推理方便表现良好
- 多种规模的模型: 包括6B、9B和34B三种不同规模的模型,提供基础版和聊天版。
- 预训练和微调: 基础版在500B tokens上持续预训练,chat版在300万个样本上进行微调。
- 性能卓越: 34B模型在基准测试中超过Qwen1.5-72B,获得高分在MMLU、HumanEval和AGIEval等基准测试中表现优异。
🔗 https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8
🔗 零一万物Yi-1.5来了,国产开源大模型排行榜再次刷新-CSDN博客

- 拥有超大关节运动角度和34个关节,结合力位混合控制技术,模拟人手进行精准操作。
- 配备9000mAh电池,支持2小时操作时间,动态平衡功能使其以2米/秒速度运动保持稳定。
- 支持WiFi6和蓝牙5.2等多种连接方式,具有良好的扩展性,市场定价约为9.9万元人民币。


🌌Lumina-T2X:统一多模态框架
- 名字中的T2X,T代表Text,X代表多模态,包括图片、视频、3D模型、音频,含义是这个框架。
- 以通过文本生成任意类型的多模态数据。
- 实现方法与Sora类似,把潜在时空空间转换成token,统一不同模态的空间时间表示。
🔗Github:
GitHub - Alpha-VLLM/Lumina-T2X: Lumina-T2X is a unified framework for Text to Any Modality Generation
🔗论文:https://arxiv.org/abs/2405.05945v1