

目录
第一章
第三章
第四章
第五章
第六章
第七章
第十章
第十二章
第十三章
第一章
图灵机
英国科学家艾伦•图灵(Alan Turing)将人们进行数学运算的过程进行抽象,交给一个假想的机器进行运算。
第三章
矩阵乘法不满足交换律
第四章
机器学习(Machine Learning),就是让计算机也能像人一样学习,从数据中找到信息,从而学习一些规律,也就是“利用经验来改善系统自身的性能”。
在计算机系统中“经验”通常以 数据的形式存在 机器学习的类型:- 监督学习 主要类型是分类和回归
- 无监督学习 代表算法:聚类算法、降维算法
- 强化学习 代表算法:Q-Learning
结构不同:生物神经网络是图结构,人工神经网络是层次结构
传递的信号不同:生物神经网络中传递的是生物电信号,人工神经网络中传递的是数据。
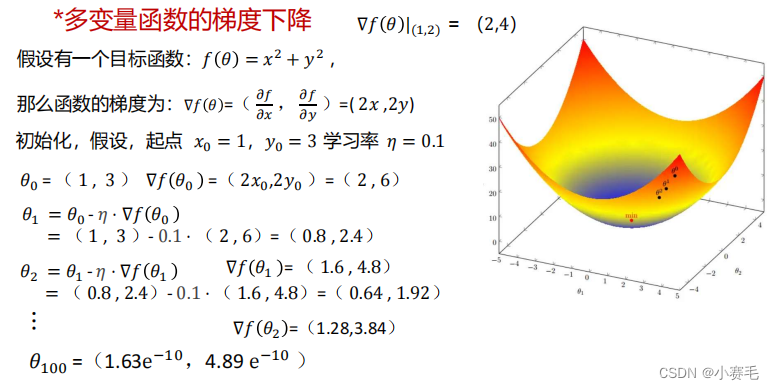
感知机只能解决二分类问题,以及拟合任何的线性函数(即线性分类或线性回归) 我们希望找到一种度量实际输出值与期望输出值之间误差的方式,这种度量方式可以使用函数表示,这个函数称为误差损失函数,神经网络的训练过程就是要找到一组权重,使得误差损失函数最小。 激活函数(Activation Function) 可以将输入信号转换为非线性输出信号 *梯度下降算法中的数学原理—梯度
 按照梯度方向移动,函数变化率最大,函数增长的最迅猛。
按照梯度方向移动,函数变化率最大,函数增长的最迅猛。

第五章
TensorFlow 中的基本数据类型,可以理解为多维数组,可以表示各种数据,如图片、音频、文本等。 如何构建(3+5)+ 3*5 = 23 的计算图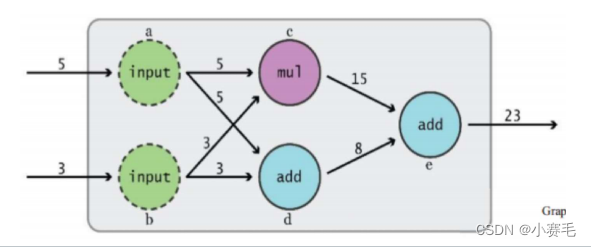
低阶API的使用:
Adam优化器结合了随机梯度下降算法(SGD)和自适应学习率算法能够快速收敛并且减少训练时间。
高阶API的使用——1 tk.keras构建模型
通过“序贯式”和“函数式”两种方式构建模型
序贯式 方式一:先通过构造函数创建一个Sepuential模型,再通过model.add依次 添加不同层。model = tf.keras.Sequential() #创建一个全连接层,神经元个数为256,输入为784,激活函数为ReLU model.add(tf.keras.layers.Dense(256,activation='relu',input_dim=784)) model.add(tf.keras.layers.Dense(256,activation='relu')) model.add(tf.keras.layers.Dense(10,activation='softmax'))
❤函数式:使用tf.keras构建函数模型,常用于更复杂的网络构建。
# 创建一个模型,包含一个输入层和三个全连接层 inputs = tf.keras.layers.Input(shape = (4)) x = tf.keras.layers.Dense(32,activation='relu')(inputs) x = tf.keras.layers.Dense(64,activation='relu')(x) output = tf.keras.layers.Dense(3,activation='softmax')(x) model = tf.keras.Model(inputs=inputs,outputs=outputs)高阶API的使用— 2 model.complie 编译模型
编译模型关键代码
model.compile( optimizer = tf.keras.optimizer.Adam(learning_rate = 0.001), loss =tf.keras.losses.sparse_categorical_crossentropy, metrics=[‘accuracy’] )高阶API的使用— 3 model.fit训练模型
训练模型关键代码 model.fit(data_loader.train_data, #训练数据 data_loader.train_label, #训练数据的标签 epochs = num_epochs, #迭代次数 batch_size=batch_size) #批次大小 高阶API的使用— 4 model.evaluate 评估模型evaluate()函数将对所有输入和输出预测,并且收集分数,包括损失,还有其他指 标。只需提供测试数据及标签即可。 model.evaluate(data_loader.test_data,data_loader.test_label) *高阶API的使用— 5 iris数据集分类示例
One-Hot编码
例如,如果有三个类别“中国” “美国”和“日本”,则One-Hot 编码可以表示为 0 中国:100 1 美国:010 2 日本:001
第六章
卷积层的作用是运用卷积操作提取特征,卷积层越多,特征的 表达能力越强。 池化层的作用是缩小特征图的尺寸,减少计算量 卷积过程是用一个大小固定的 卷积核按照一定 步长输入矩阵进行 点积运算,将卷积 结果输入激活函数得到矩阵称为特征图。 填充多少像素,通常有两个选择:valid和same valid卷积(valid convolutions):意味着不填充 same卷积(same convolutions):意味着填充后输出和输入的大小是相同 的 p=(f-1)/2 过拟合 如果一味地追求模型对训练数据的预测能力(即降低训练误差),所选模型 的复杂度往往会比真模型更高。但此时预测误差会逐渐提高,这种现象称为 过拟合(overfitting)。 池化层又称为下采样层 池化操作通常有两种, 一种是常用的最大池化,另一种是不常用的平均池化。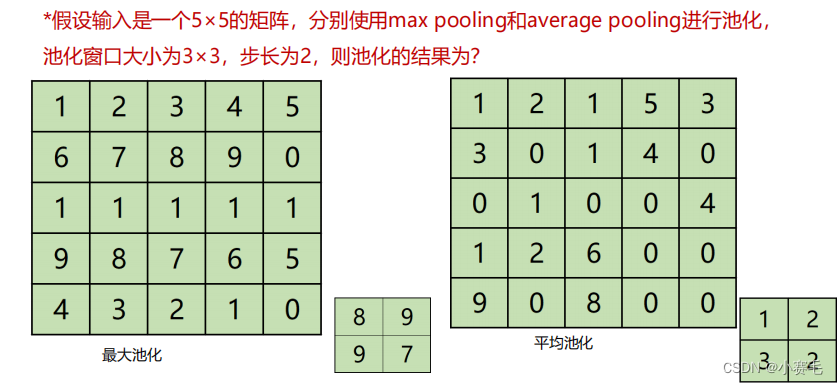
典型的数据增强的方法
几何变换类操作:水平和垂直方向上的翻转、旋转、缩放、平移、随机裁剪等 颜色变换类操作:噪声、模糊、颜色扰动、擦除、填充等。
简答题:局部响应归一化 Local Response Normalization (LRN) LRN模仿了生物神经系统的“侧抑制”机制,对局部神经元活动创建了竞争环境,使 得其中响应比较大的值变得更大,并抑制其他反馈较小的神经元,增强了模型的泛化 能力。当我们使用ReLU这种没有上限边界的损失函数的时候,这种局部抑制显得很 有效果。但是不适合sigmoid这种有固定边界并能抑制过大值的激活函数。 简答题:模型调优 –梯度下降算法 批量梯度下降法(BGD):每次迭代计算梯度,使用整个数据集。每次更新都会朝着正确的方向进 行,最后能够保证收敛于极值点。缺陷是学习时间太长,消耗大量内存。 随机梯度下降法(SGD):从整个数据集中随机选取一个数据,因此每次迭代的时间非常快。但收 敛时震荡,不稳定,在最优解附近波动,难以判断是否已经收敛。可能陷入局部极值。
第七章
GoogLeNet 的核心是 Inception 架构 简答题:Dense网络 DensseNet脱离了加深网络层数和加宽网络来提升网络性能的思维定势。和传统的网络相比,它 的优点如下: ➢ 省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。 ➢ 省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右。 ➢ 抗过拟合。DenseNet 具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。 ➢ 泛化性能更强。如果没有数据增强,CIFAR-100下,ResNet表现下降很多,DenseNet下降不 多,说明DenseNet泛化性能更强。第十章
简答题:LSTM是一种有三个“门”结构的特殊网络结构。从左至右,依次为“遗忘门(forget gate)、输入门(input gate)、输出门( output gate)”
- 遗忘门:决定什么时候把以前的状态忘记
- 输入门:用于确定更新的信息。分成两部分,1、通过sigmoid层找到需要更新的细胞状态;2、通过tanh层创建一个新的细胞状态 𝐶𝑡 向量加入状态中。 遗忘门找到需要忘记的信息 𝑓𝑡 后,将它与旧的状态𝐶𝑡−1相乘
- 输出门:需要确定输出什么值,这个输出将于基于细胞状态。
双向RNN是由两个RNN堆叠在一起的,输出的结果是由两个RNN共同决定的
第十二章
图像领域应用: 创建动漫角色 姿势引导人形象生成 风格转换 超分辨率重建(图像修复) 文本到图像 目标检测 图像修复第十三章
智能体, 是强化学习的核心 智能体的核心是策略 强化学习的特点: ➢ 强化学习是一种无监督学习,它侧重在探索与行为之间做权衡,找 到达到目标的最佳方法。 ➢ 强化学习的结果反馈具有时间延迟性。相比之下,监督学习的反馈 是即时的。 ➢ 强化学习处理的是不断变化的序列数据,并且每个状态输入都是由 之前的行动和状态迁移得到的。 ➢ 智能体的当前行动会影响其后续的行动。智能体选择的下一状态不 仅和当前状态有关,也和当前采取的动作有关 无模型的强化学习: 蒙特卡洛算法 时序差分学习算法







