

(一)课题研究的背景
新能源汽车作为汽车电动化、低碳化的重要发展方向,对于提高产业竞争力、改善未来能源结构、发展低碳交通具有深远意义。全球主要发达国家都将新能源汽车作为未来发展的未来发展的重要战略方向并加快产业布局川。相较于传统燃油汽车,新能源汽车具有能耗较低、对环境污染小等优点,是传统燃油汽车所不及的,因此,新能源汽车将会是未来汽车产业发展的主要趋势。我国也大力支持新能源汽车产业的快速发展,频繁出台相关政策,全方位鼓励和扶持新能源汽车产业。一方面政府鼓励及补贴新能源汽车企业提升新能源汽车生产规模,积极研究和创新相关技术,提升新能源汽车品质;另一方面国家发放资金补贴,降低消费者购买新能源汽车的成本及并根据新能源车辆行驶里程对消费者进行资金补贴等政策(112),降低了消费者购买新能源汽车的难度,引导消费者选择新能源汽车,进而推动了新能源汽车普及率。
在全球化、信息化的时代,一些有关大数据信息的处理、分析技术已经取得了很大的进步,众多数据分析系统被广泛地应用,为了让消费者对新能源汽车更加的了解以便选出自己喜欢的汽车类型,销售分析平台就是能很好解决这一需求的技术。
(二)课题研究的内容
课题研究的内容主要有三部分,即数据获取、数据分析、数据可视化。
数据获取:基于python爬取新能源汽车相关销售数据:销量,评价,品牌价格,性能介绍等并存储到hadoop分布式系统中。
清洗分析数据:采用基于内存计算的spark计算框架结合高吞吐的HDFS分布式文件系统,对车辆销售数据进行计算和分析。
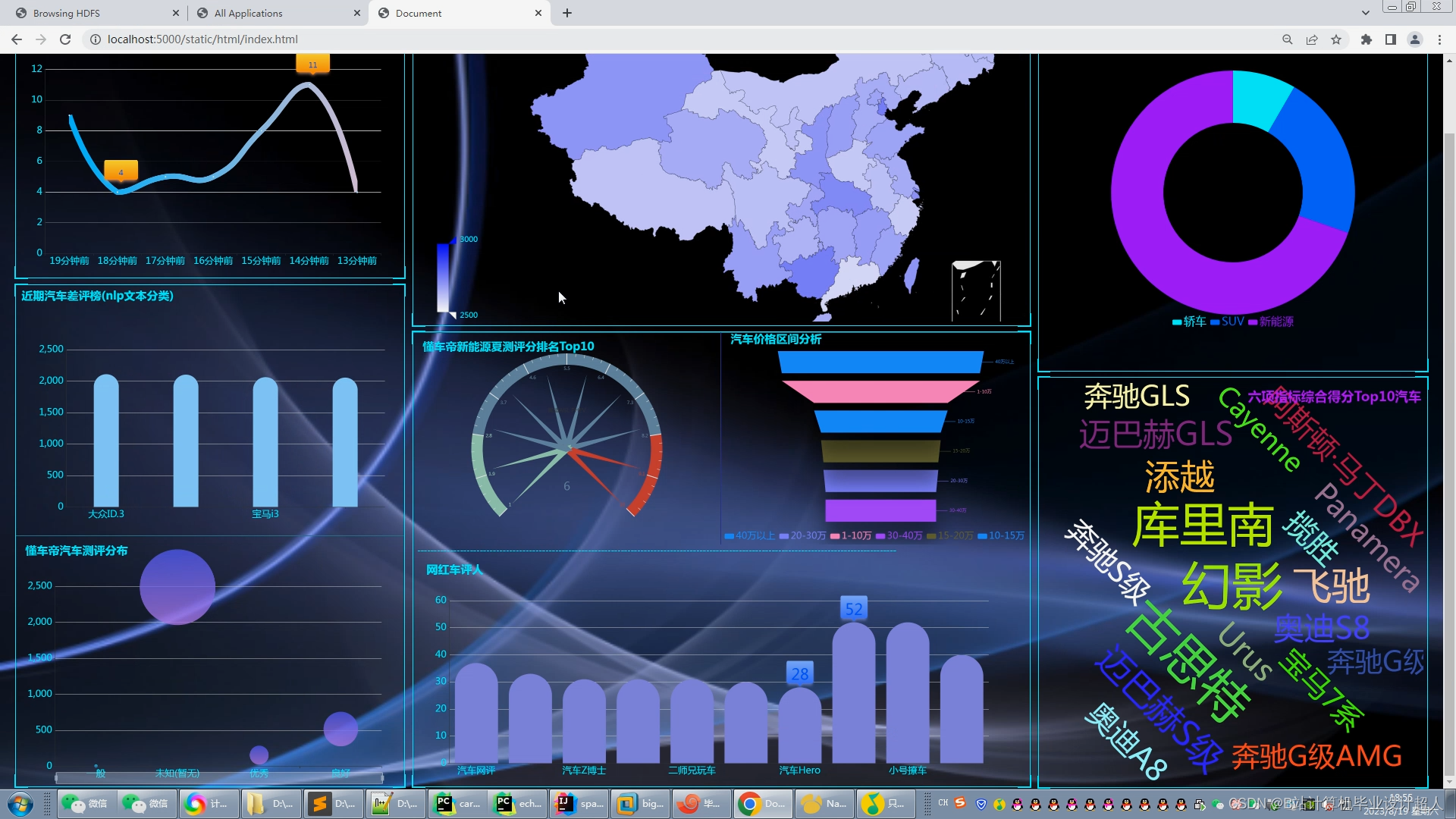
数据可视化 :对分析出来的结果集进行可视化展示是大数据分析流程中很重要的一个层面。对于用户来说,单纯的数字展现在其面前是没有任何效果的。所以,我们需要利用数据可视化技术,将Hadoop数据分析平台计算分析的结果集以曲线图、柱状图等表格的形式进行可视化展示,使得分析出来的数据更加清晰明了。
(三)课题研究的意义
新能源汽车销售分析平台研究的意义在于帮助企业更好地了解市场和消费者需求,提高销售效率和客户满意度。具体来说,它可以帮助企业了解市场趋势和竞争对手情况,从而制定更加精准的销售策略。可以通过数据分析,了解消费者的需求和偏好,为其推荐适合的车型和配置,提高销售转化率。实现对新能源汽车供应链和售后服务的实时管理和监控,提高供应链效率和售后服务质量。通过与客户关系管理系统的集成,建立和维护客户关系,提高客户满意度和忠诚度。总之,新能源汽车销售分析平台的研究对于企业提高市场竞争力、提高销售效率和客户满意度都具有重要意义。
(四)国内外研究现状
1.国外研究现状
在国外新能源汽车销售分析平台的研究领域,目前主要的方法是基于大数据和人工智能技术来构建一个智能化、个性化的销售分析平台。这种方法的原理是通过收集和分析海量的新能源汽车销售数据,运用大数据技术和人工智能技术,实现智能化和个性化的销售预测、市场分析、客户画像等功能,从而提高销售效率和客户满意度。这种方法的优点在于,它可以实现对海量数据的快速处理和分析,从而更好地了解市场和客户需求,提高销售效率和客户满意度。同时,它还可以通过智能化和个性化的推荐,帮助销售人员更好地了解客户,提高销售业绩。
2.国内研究现状
新能源汽车销售分析平台在国内的研究现状相对较好。随着新能源汽车市场的不断扩大,越来越多的企业开始关注新能源汽车销售分析平台的建设和应用。目前,国内已经有一些知名的汽车销售分析平台,例如易车、汽车之家等,它们通过大数据分析和人工智能技术,为汽车厂商和经销商提供销售数据分析和决策支持。这些平台不仅可以实时监测销售数据,还可以通过用户行为分析来优化营销策略和提升用户体验。此外,一些新兴的汽车销售分析平台也在不断涌现,例如懂车帝、车好多等。这些平台通过提供个性化的推荐服务、在线咨询服务等,帮助用户更好地了解和购买新能源汽车。然而,尽管新能源汽车销售分析平台的研究现状相对较好,但在实际应用中还存在一些问题和挑战。例如,如何提高平台的智能化水平、如何更好地整合线上线下资源、如何保障用户隐私和数据安全等问题都需要进一步研究和解决。总的来说,新能源汽车销售分析平台在国内的研究现状已经取得了一定的进展,但仍需不断探索和创新,以更好地服务于新能源汽车市场的发展。
(五)设计方案选型分析
收集数据:收集和查找相关的资料,理解新能源汽车销售数据,对新能源汽车销售数据有一定的认识,浏览汽车销售网站,明确数据的来源。确定数据采集的方法,收集和学习利用python网络爬虫实现数据爬取的案例。
存储数据:将数据存入hadoop分布式系统中。
数据分析:采用基于内存计算的spark计算框架结合高吞吐的HDFS分布式文件系统,对车辆销售数据进行计算和分析
数据展示:将Hadoop数据分析平台计算分析的结果集以曲线图、柱状图等表格的形式进行可视化展示,使得分析出来的数据更加清晰明了
二、课题任务、重点研究内容及实现途径
(一)课题任务
课题任务的内容主要有三部分,即数据获取、数据分析、数据可视化。
数据获取:基于python爬取新能源汽车相关销售数据:销量,评价,品牌价格,性能介绍等并存储到hadoop分布式系统中。
清洗分析数据:采用基于内存计算的spark计算框架结合高吞吐的HDFS分布式文件系统,对车辆销售数据进行计算和分析。
数据可视化 :对分析出来的结果集进行可视化展示是大数据分析流程中很重要的一个层面。对于用户来说,单纯的数字展现在其面前是没有任何效果的。所以,我们需要利用数据可视化技术,将Hadoop数据分析平台计算分析的结果集以曲线图、柱状图等表格的形式进行可视化展示,使得分析出来的数据更加清晰明了。
(二)重点研究内容
本文重点研究的内容是使用Hadoop分析和存储。Apache 组织借鉴Google 的 Big Table、GFS和 MapReduce,提出了开源项目 Hadoop。Hadoop数据分析平台是具有分布式系统的框架,是目前最为广泛使用的云计算平台。
本项目需爬取不少于20页的数据,并基于Hadoop大数据平台对上传的车辆数据经过初步分析后,存储到hadoop分布式系统中,同时采用spark技术作为系统的大数据计算模型,计算结果根据不同场景需要,存储到Hbase和Mysql中供数据可视化使用,运用echarts,mysqpl等技术构建可视化大屏,将分析结果以可视化图表的形式进行展示。
(三)实现途径
- 入门硬件配置
客户端电脑,基本配置为:四核、2.5GHZ以上的64位处理器,16G以上内存,硬盘剩余空间50G以上,显示器要求1024*768以上。
- 和其他软件配合使用
操作系统 Ubuntu ,VMware,Hadoop,hbase,spark,MySQL,pycharm,echarts等。
三、进度计划
| 序号 | 起止周次 | 工作内容 |
| 1 | 1周至2周 | 确定毕业选题 |
| 2 | 3周至5周 | 撰写开题报告 |
| 3 | 6周至7周 | 根据开题报告完成毕业设计实践任务 前期软件环境准备阶段 |
| 4 | 8周至9周 | 分析可视化实现阶段 |
| 5 | 9周至10周 | 提交源文件和可视化效果展示 |
| 6 | 11周至14周 | 确定论文结构 撰写毕业设计论文 |
| 7 | 15周至16周 | 提交毕业设计论文初稿 |
| 8 | 17周至18周 | 修改毕业设计论文 提交毕业设计查重稿 |
| 9 | 18周至19周 | 修改毕业设计论文 提交毕业设计答辩稿 |
| 10 | 20周至21周 | 答辩准备 |
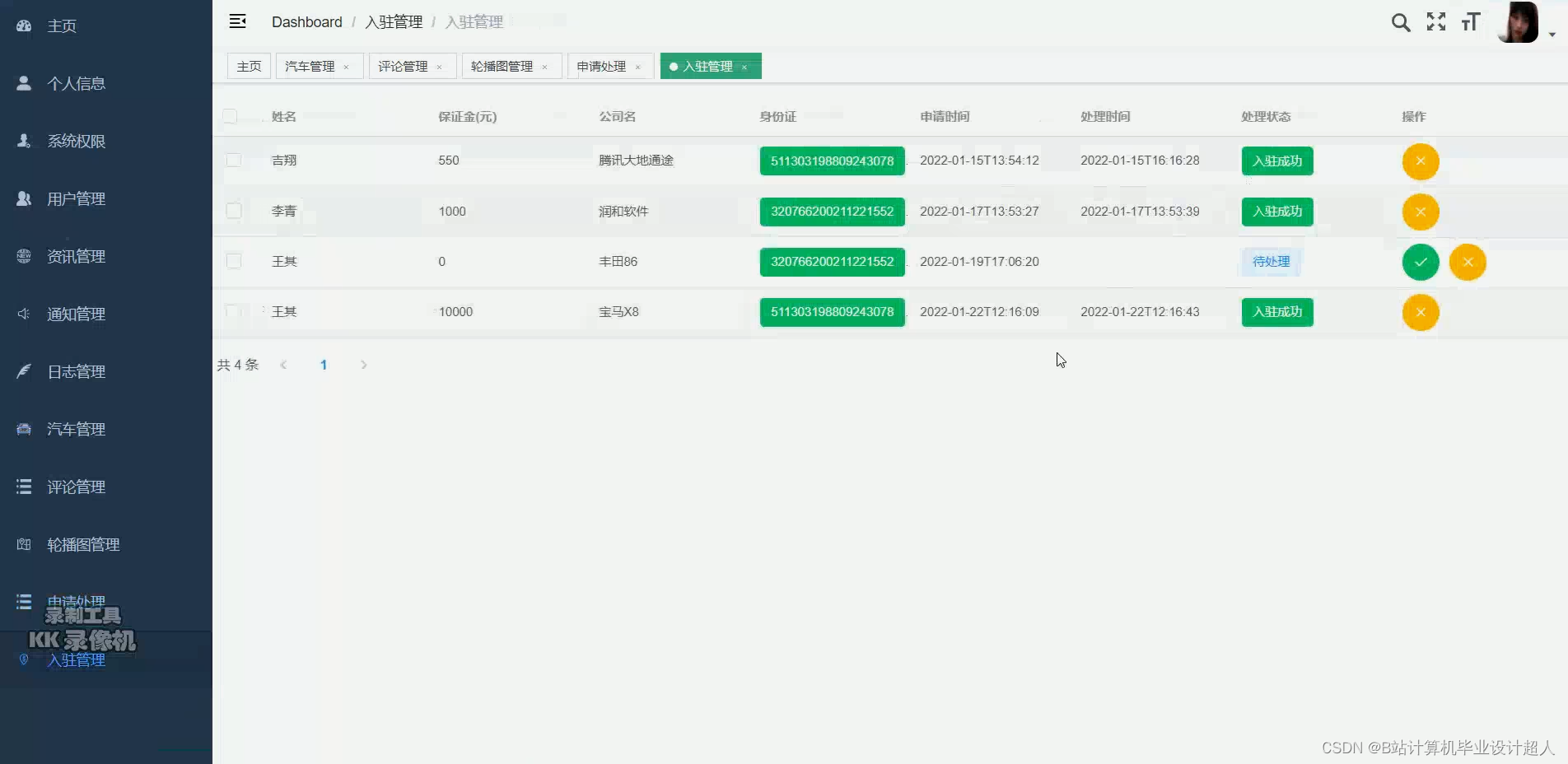
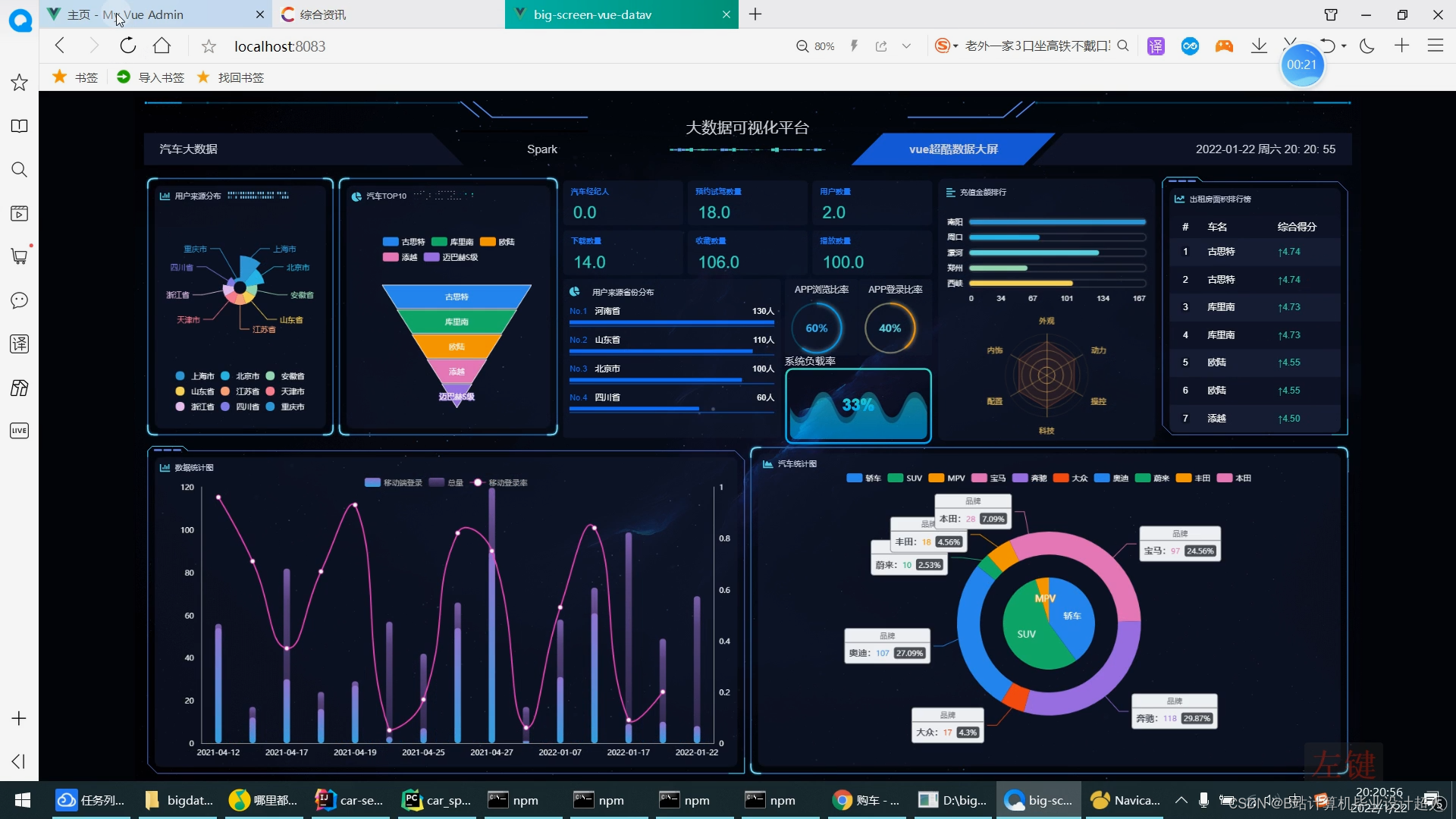
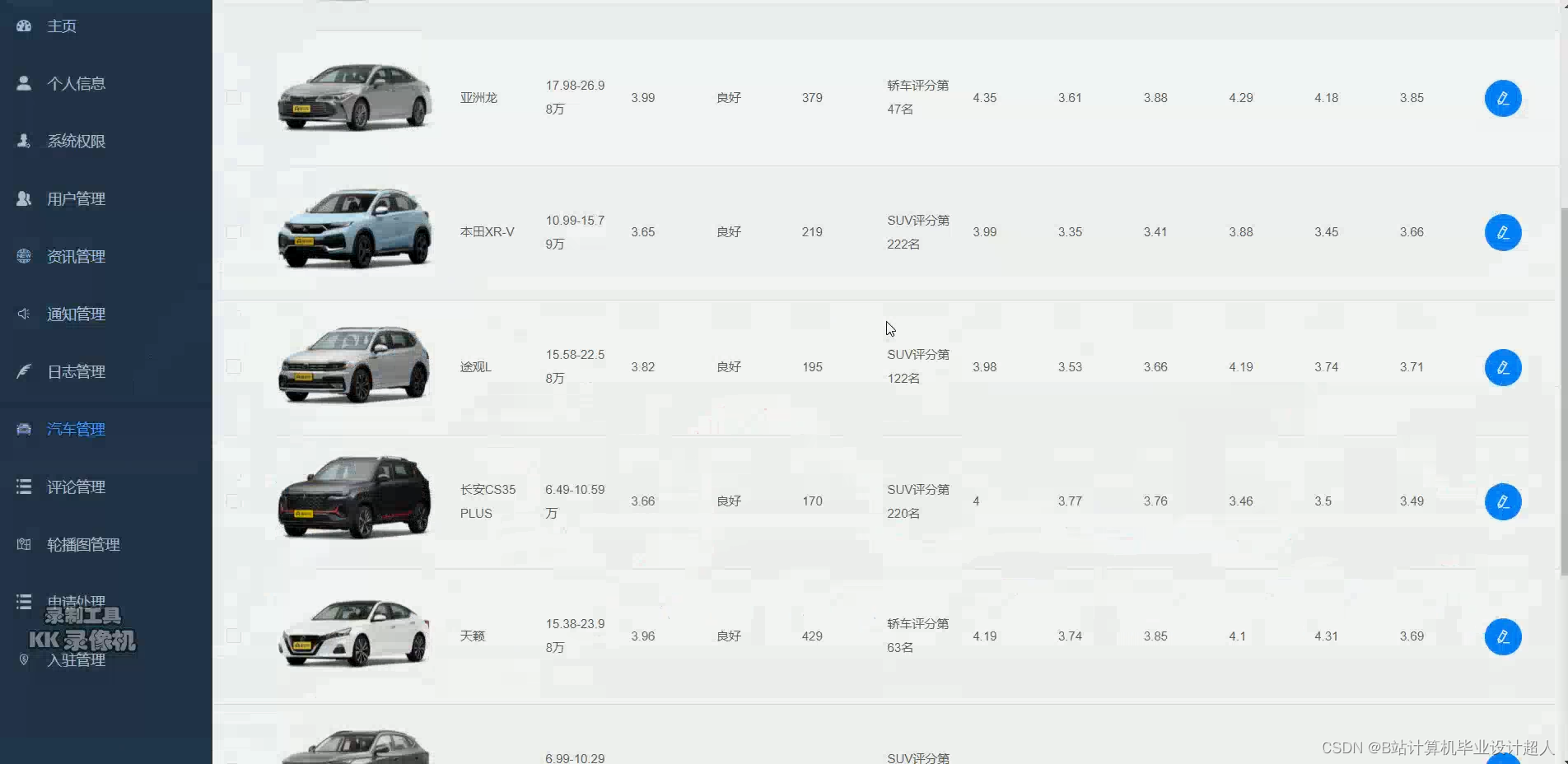
核心算法代码分享如下:
import scrapy
from scrapytest.items import CarItem
class CarSpider(scrapy.Spider):
name = 'car_anhui'
pvareaid=102179#currengpostion']
#
pvareaid=102179#currengpostion'
# page_num = 2
# 重写start_requests()方法,把所有URL地址都交给调度器
def start_requests(self):
for i in range(1,101,1):
url = f'XXXX'
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
car_list = response.xpath('//*[@id="goodStartSolrQuotePriceCore0"]/ul/li')
for car_list_i in car_list:
item = CarItem()
name = car_list_i.xpath('./a/div[2]/h4/text()').get()
price = car_list_i.xpath('./a/div[2]/div[1]/span[1]/em/text()').get()
newprice = car_list_i.xpath('./a/div[2]/div[1]/s/text()').get()
if newprice != None:
newprice = newprice.replace('万','')
else:
newprice = newprice
item['name'] = name
item['price'] = price
item['newprice'] = newprice
href = car_list_i.xpath('./a/@href').get()
if href[0:16] == 'XXXXX':
url_1 = 'https:' + href
# print(url_1)
yield scrapy.Request(url=url_1,meta={'item':item},callback=self.parse_detail)
else:
url_2 = 'XXXXX' + href
# print(url_2)
yield scrapy.Request(url=url_2,meta={'item':item},callback=self.parse_detail)
# if self.page_num 






