

1、POD启动状态一直为ContainerCreating,提示cni0的IP与既有子网不同
报错信息
使用 kubectl describe pods -n 命令可看到提示信息
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox “745720ffb20646054a167560299b19bb9ae046fe6c677b5d26312b89a26554e1”: failed to set bridge addr: “cni0” already has an IP address different from 172.20.2.1/24
进入到对应计算节点,使用ip a命令确认cni0的IP信息,使用cat /run/flannel/subnet.env查看flannel网络插件分配的子网IP,发现两者确实不一致。
解决办法
删掉这个IP错误的网卡cni0, 之后flanneld自动重新创建。命令如下。
ifconfig cni0 down ip link delete cni0
2、POD启动状态一直为ContainerCreating,提示cgroup无法分配内存
报错信息
failed to create container for [kubepods burstable pod…]: mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod…: cannot allocate memory
原因
cgroup内存泄露
解决办法
- 方法一:将集群节点的CentOS系统内核升级到5.4以上版本,频率会明显降低
- 方法二:重启节点服务器,但运行过一段时间后还是会出现这种问题
3、prometheus采集到的kube_node_labels指标,label信息不全
分析
该指标由 kube-state-metrics (deployment)采集,经curl在集群内访问该exporter,原始采集到的指标即不完整
解决办法
与其他采集正常的k8s集群对比,发现所用kube-state-metrics (deployment)版本有差异,将其镜像版本由2.0.0 改为了 v1.9.7 问题得到解决,效果如下。
4、deployment部署状态为ReplicaFailure
现象
deployment应用后,状态为ReplicaFailure,pod无法启动
分析过程:查看对应replicaset的event信息,确认原因
- 命令行方式
具体步骤如下:
(1) 查看deployment详细信息,condition为ReplicaFailure
[root@10-75-18-18 ~]# kubectl describe deploy redis-hdms -n kunlun-cn-poc-m9 ... Conditions: Type Status Reason ---- ------ ------ Available False MinimumReplicasUnavailable ReplicaFailure True FailedCreate Progressing False ProgressDeadlineExceeded OldReplicaSets: redis-hdms-54c669b665 (0/1 replicas created) Events:
(2) 确认对应replicaset的名称
# 方法1 从上步骤的描述结果中查找 # 方法2:使用命令检索,再按时间等信息匹配 [root@10-75-18-18 ~]# kubectl get rs -n kunlun-cn-poc-m9 |grep redis-hdms redis-hdms-54c669b665 1 0 0 97m redis-hdms-6f749b758d 1 0 0 95m
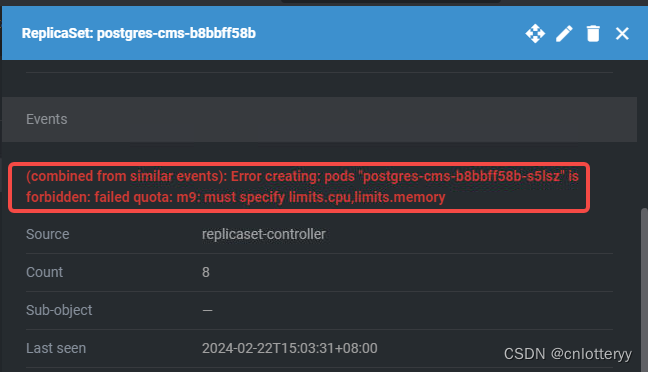
(3) 查看replicaset的情况,event中warning提示未设置limits.cpu和limits.memory
[root@10-75-18-18 ~]# kubectl describe rs redis-hdms-54c669b665 -n kunlun-cn-poc-m9 ... Conditions: Type Status Reason ---- ------ ------ ReplicaFailure True FailedCreate Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedCreate 59m replicaset-controller Error creating: pods "redis-hdms-54c669b665-dx5lf" is forbidden: failed quota: m9: must specify limits.cpu,limits.memory
- 图形界面方式
从图形界面关联找到其对应的replicaset,点击查看其event信息
解决办法
在deployment对应的yaml中增加资源limits信息即可
(20240222)
5、pod持续重启,提示Back-off restarting failed container
现象
pod持续重启,提示Back-off restarting failed container
原因分析
(1) 查看pod详细信息,Last State中查看原因为OOMKilled,即内存不足
[root@10-75-18-18 ~]# kubectl describe pod minio-74c9cf8669-f8wc7 -n kunlun-cn-poc-m9 ... Last State: Terminated Reason: OOMKilled Exit Code: 137 Started: Thu, 22 Feb 2024 14:18:43 +0800 Finished: Thu, 22 Feb 2024 14:18:44 +0800 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 48s (x5 over 2m29s) kubelet, 192-167-20-74 Container image "registry.xxx.com/infra/minio:RELEASE.2020-06-18T02-23-35Z" already present on machine Normal Created 48s (x5 over 2m29s) kubelet, 192-167-20-74 Created container minio Normal Started 47s (x5 over 2m28s) kubelet, 192-167-20-74 Started container minio Warning BackOff 33s (x10 over 2m24s) kubelet, 192-167-20-74 Back-off restarting failed container解决办法
在deployment对应的yaml中修改内存资源配置
其他常见原因
- 无常驻进程
https://blog.csdn.net/yztezhl/article/details/125421316
https://serverfault.com/questions/924243/back-off-restarting-failed-container-error-syncing-pod-in-minikube
- 其他
https://www.imooc.com/article/339069
(20240222)
- 其他
- 无常驻进程
- 图形界面方式
- 命令行方式







