

今天分享的项目是由华为和腾讯的研究人员联手开发的AniPortrait,只需一段音频和一个静态的肖像图像,就能生成一段数字人视频。支持音频生成视频、视频生成视频。我已经将项目打包,离线解压即可使用!(整合包在文章末尾自取)
配置要求
WIN
- Windwos10/11操作系统
- 16G显存以上的英伟达显卡
- 如果出现cuda错误,建议安装cuda11.7或以上版本
MAC
暂不支持本地离线版本
可访问在线链接进行体验(需科学上网)
https://huggingface.co/spaces/ZJYang/AniPortrait_official
使用方法
音频生视频
- 将音频文件上传到指定位置
- 接着上传希望动画化的图片

- 上传一个头部姿势参考视频,这个视频将作为生成视频的人物动作姿态的参考依据。(这是一个可选选项)
- 默认的视频尺寸为512×512像素。根据自身情况进行调节。

- 视频长度,默认为60,建议设定为0。根据音频计算生成长度。
- 步数,默认25。即模型处理图像的迭代次数。步数越高,生成的视频画面将越精细,但同时对计算资源的需求也越大。

- 种子值可以保持不变。

视频生视频
操作方法跟音频生视频类似,上传源视频即可。
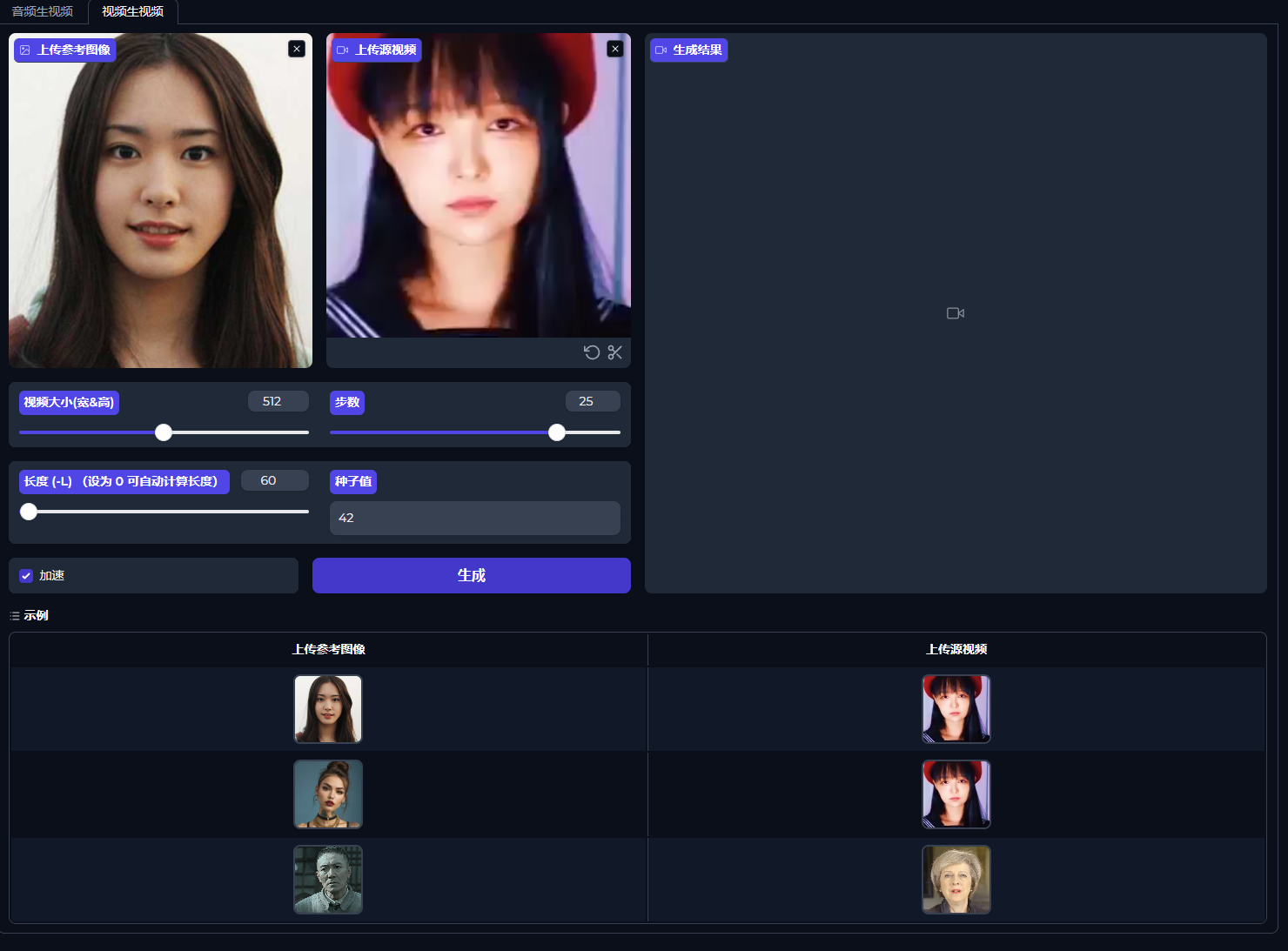
需要注意的是,这个项目是有示例的,点击示例会自动配置示例的音频和图片,但是生成示例会很慢!建议用自己的图和音频先试下!
常见问题
这个项目使用时可能会遇到UTF-8编码问题。
解决方法:
打开控制面板---时钟和区域
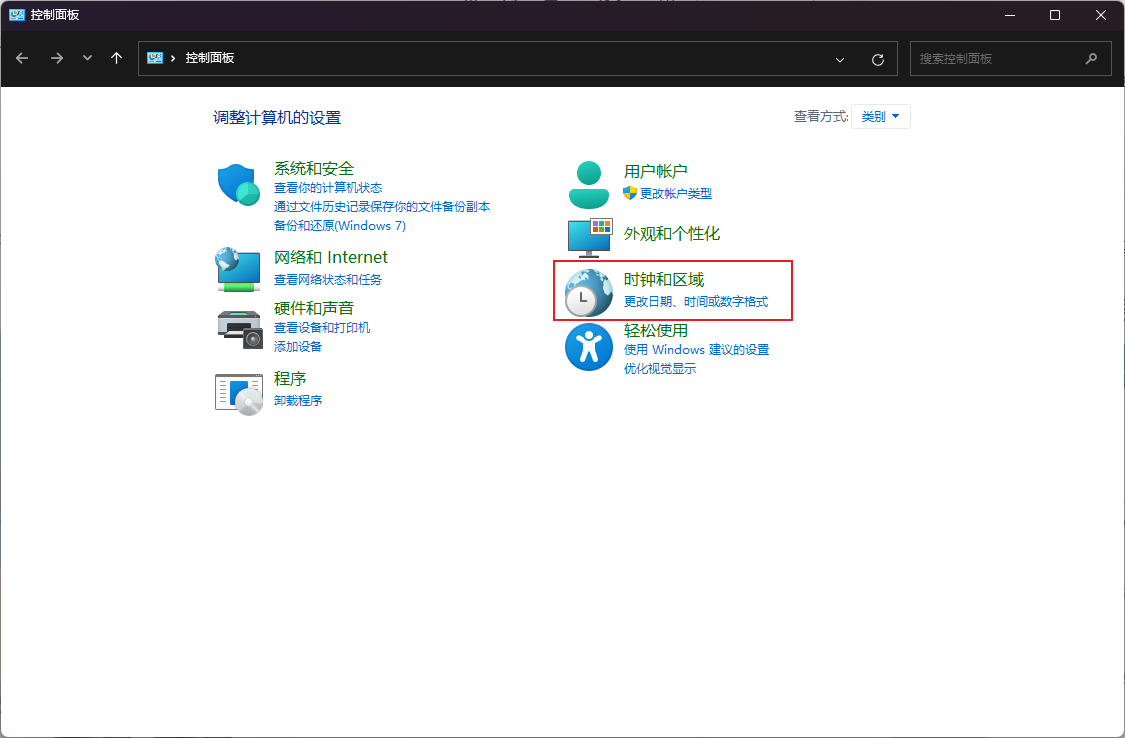
点击区域
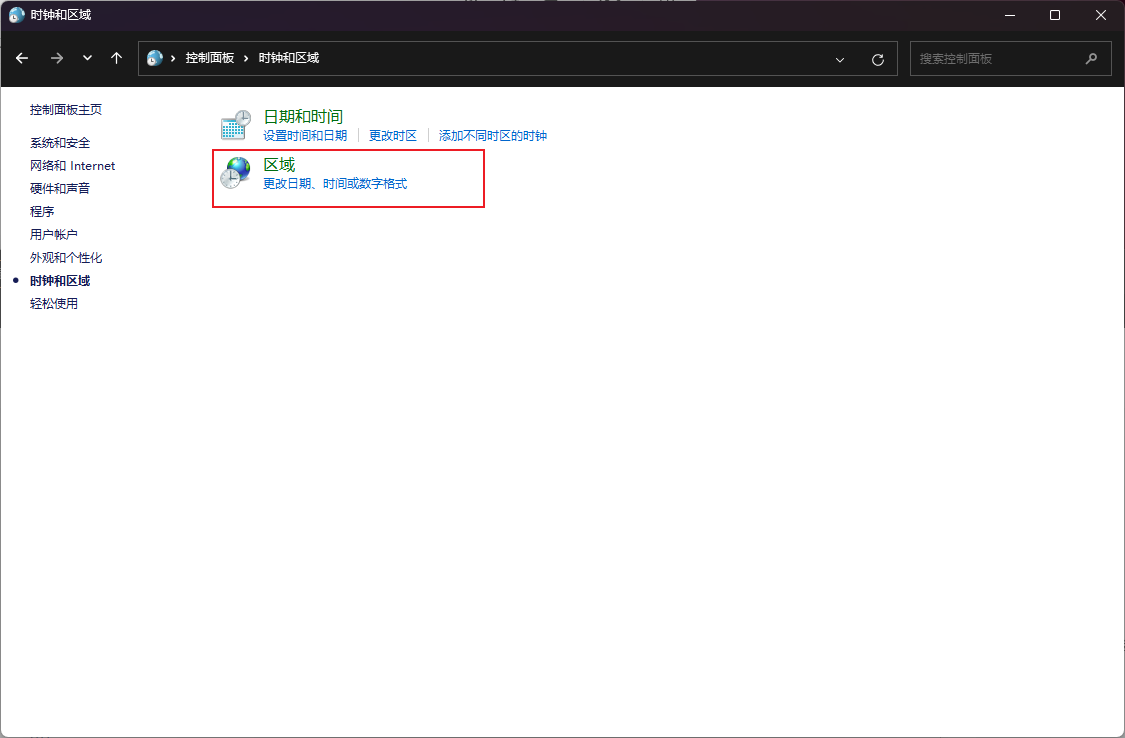
点击管理
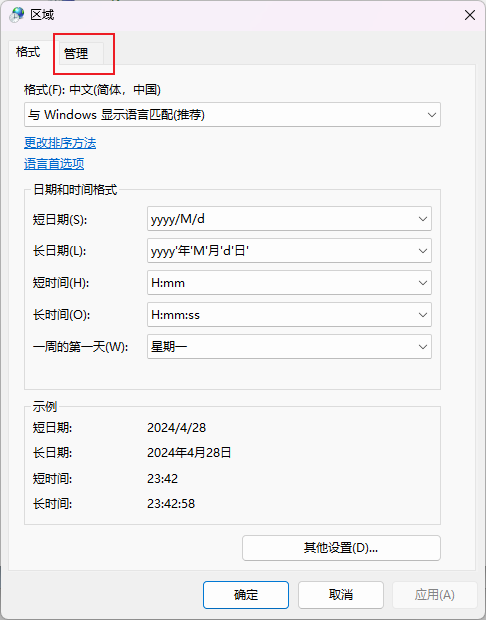
点击更改系统区域设置
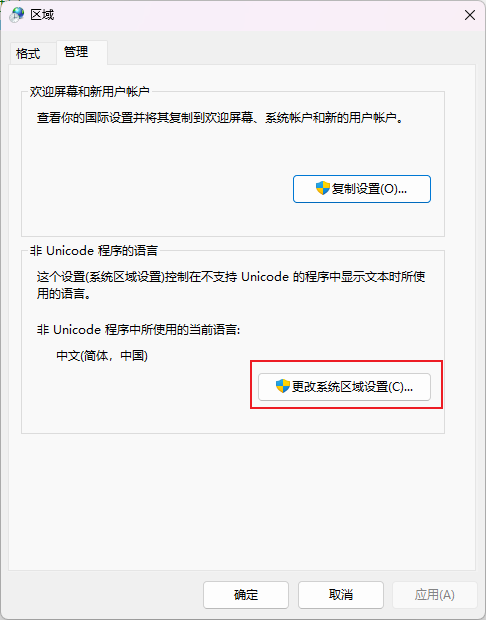
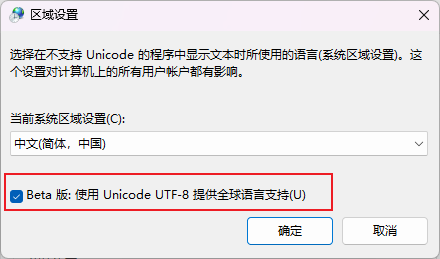
勾选这个选项,然后重启电脑即可。
技术实现
- 利用wav2vec2.0作为Audio2Lmk阶段的基础模型。
- 为了提高网络对唇部运动的敏感性,在渲染姿态图像时,将上下唇用不同的颜色区分开来。
- 所有图像被调整至512x512的分辨率进行训练。
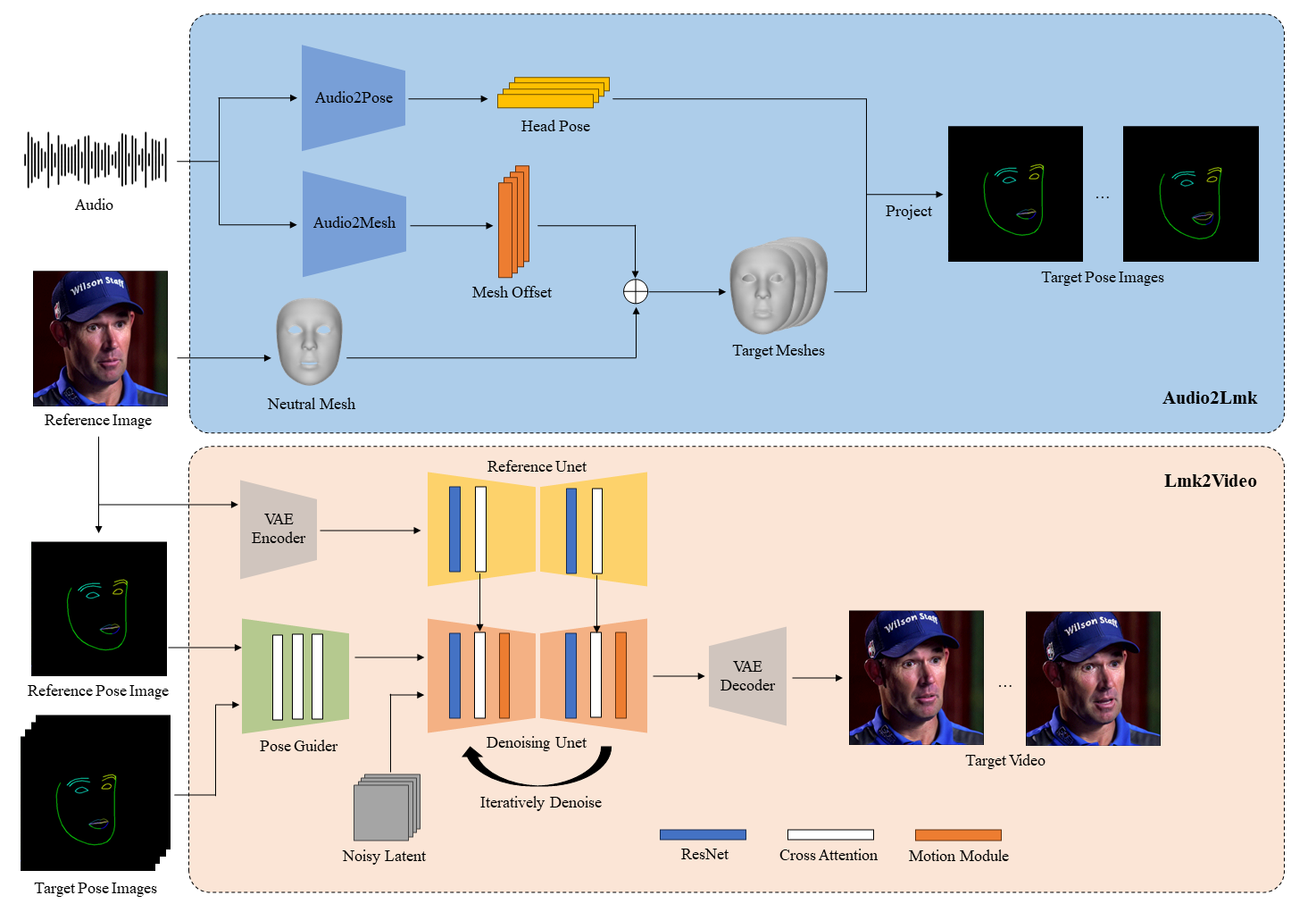
- 音频到面部标记(Audio2Lmk)
-
- 使用预训练的wav2vec模型从音频中提取特征,这些特征能够准确识别发音和语调。
- 通过两个全连接层(fc layers),将音频特征转换为3D面部网格。
- 利用transformer解码器,结合交叉注意力机制,预测头部姿态序列。
- 面部标记到视频(Lmk2Video)
-
- 给定参考肖像图像和面部标记序列,Lmk2Video模块创建与标记序列对齐且外观与参考图像一致的时间一致性肖像动画。
- 网络结构设计灵感来源于AnimateAnyone,使用Stable Diffusion 1.5作为基础,整合了时间运动模块。
整合包获取
👇🏻👇🏻👇🏻什么?是不是收费的?👇🏻👇🏻👇🏻

关注公众号,发送【AniPortrait】关键字获取整合包。

如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!







