

OpenCV 入门系列:
OpenCV 入门(一)—— OpenCV 基础
OpenCV 入门(二)—— 车牌定位
OpenCV 入门(三)—— 车牌筛选
OpenCV 入门(四)—— 车牌号识别
OpenCV 入门(五)—— 人脸识别模型训练与 Windows 下的人脸识别
OpenCV 入门(六)—— Android 下的人脸识别
OpenCV 入门(七)—— 身份证识别
从本篇文章开始我们进入 OpenCV 的 Demo 实战。首先,我们会用接下来的三篇文章介绍车牌识别 Demo。
1、概述
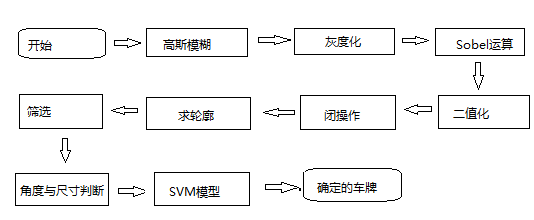
识别图片中的车牌号码需要经过三步:
- 车牌定位:从整张图片中识别出牌照,主要操作包括对原图进行预处理、把车牌从整图中抠出
- 字符分割:将牌照中的字符进行切割
- 字符识别:识别单个字符,然后拼接成字符串
本节是 OpenCV 车牌识别的第一节课,主要完成了车牌定位的工作。具体流程:
2、项目搭建
Demo 使用 Visual Studio 开发,有关 Visual Studio 配置 OpenCV 项目的详细过程在上一篇文章中已经介绍过,这里就只是再简单提一下。
2.1 项目配置
在 Visual Studio 中创建一个 CMake 项目 LicensePlateRecognition,配置 CMakeLists.txt 如下:
cmake_minimum_required (VERSION 3.8)
project ("LicensePlateRecognition")
# 指明 OpenCV 的头文件目录,编译时会去该目录下寻找 OpenCV 的头文件
include_directories("G:/Tools/OpenCV/build/include")
# 指明 OpenCV 的库文件目录,链接时会去该目录下寻找 OpenCV 的库文件
link_directories("G:/Tools/OpenCV/build/x64/vc15/lib")
# 将指定的源代码添加到此项目的可执行文件
add_executable (LicensePlateRecognition "LicensePlateRecognizer.cpp" "PlateLocator.cpp" "SobelLocator.cpp" "VLPR_1.cpp")
# 指明可执行文件或库文件依赖的库,opencv_world410d 在链接时会链接到目标 LicensePlateRecognition
target_link_libraries(LicensePlateRecognition opencv_world410d)
如果运行时说找不到 opencv_world410d.dll,请将库目录添加到环境变量并重启 VS 再试。
2.2 框架搭建
说一下被添加到 add_executable() 中编译的源码的功能:
-
LicensePlateRecognizer 是车牌识别器,传入一个车牌图像会返回车牌号:
int main() { Mat src = imread("C:/Users/69129/Desktop/Test/test2.jpg"); LicensePlateRecognizer lpr("C:/Users/69129/Desktop/Test/svm.xml", "C:/Users/69129/Desktop/Test/train/ann/ann.xml", "C:/Users/69129/Desktop/Test/train/ann/ann_zh.xml"); // 识别车牌,返回车牌号 string str_plate = lpr.recognize(src); cout 删除缓存,然后在 CMakeLists 通过 Ctrl + S 重新生成可执行文件,否则新建的 cpp 不会自动被添加到可执行文件中3、Sobel 算法定位车牌
我们使用 Sobel 算法实现 SobelLocator 定位器的 locate(),3.1 ~ 3.8 节的标题就是根据前面给出的流程图做出的实现步骤。
3.1 高斯模糊
高斯模糊算法本质上是一种数据平滑技术,图像处理恰好是一个直观的应用实例,具体内容可以参考阮一峰大神的博客:高斯模糊的算法。
我们这里需要了解 OpenCV 的高斯模糊函数 GaussianBlur 如何使用:
/** 使用高斯滤镜(滤波器)对图像进行模糊处理。该函数将源图像与指定的高斯核进行卷积。支持原地滤波。 @param src 输入图像;图像可以具有任意数量的通道,但是它们将独立处理,但是深度应为 CV_8U、CV_16U、CV_16S、CV_32F 或 CV_64F @param dst 输出图像,与 src 具有相同的大小和类型 @param ksize 高斯核大小。ksize.width 和 ksize.height 可以不同,但它们都必须是正奇数。 或者,它们可以为零,然后它们将从 sigma 中计算得出 @param sigmaX X 向的高斯核标准差 @param sigmaY Y方向的高斯核标准差;如果 sigmaY 为零,则它被设置为与 sigmaX 相等,如果 两个 sigma 都为零,则它们分别从 ksize.width 和 ksize.height 计算得出(有 关详细信息,请参见 #getGaussianKernel);为了完全控制结果,无论将来可能对 所有这些语义的修改如何,建议指定 ksize、sigmaX 和 sigmaY @param borderType 素外推方法,参见 #BorderTypes */ CV_EXPORTS_W void GaussianBlur( InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY = 0, int borderType = BORDER_DEFAULT );调用 GaussianBlur() 对原图进行高斯模糊:
/** * 车牌定位,输入原图 src,输出候选图集合 dst_plates */ void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 Mat blur; // 构造 Size 的宽高必须是正奇数,宽高越大越模糊 GaussianBlur(src, blur, Size(5, 5), 0); imshow("src", src); imshow("blur", blur); ... }对比效果如下:

3.2 灰度化
实际上,色彩对于图像识别是有干扰的,因此需要通过灰度化对图像“降噪”,为 Sobel 边缘检测算法(该算法只接受灰度图)做准备:
void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 ... // 2.灰度化 Mat gray; // 注意颜色是 BGR,OpenCV 早期用 BGR 表示颜色,而不是现在我们熟悉的 RGB cvtColor(blur, gray, COLOR_BGR2GRAY); imshow("gray", gray); ... }灰度化效果:

可否先对原图灰度化后再高斯模糊呢?没有硬性规定,但是高斯模糊接收彩色图的模糊效果更好。
3.3 Sobel Derivatives 运算
Sobel Derivatives —— Sobel 导数是一种用于计算图像梯度的算子。它是一种线性滤波器,用于检测图像中的边缘。Sobel 算子结合了水平和垂直方向的差分操作,从而可以同时计算图像在水平和垂直方向上的梯度。这使得 Sobel 算子在图像处理中广泛应用于边缘检测、图像增强和特征提取等任务中。
Sobel 算子的计算过程涉及对图像进行卷积操作,具体而言,它使用一个 3 × 3 的卷积核分别对图像进行水平和垂直方向的卷积。通过计算卷积结果的导数,可以得到图像在水平和垂直方向上的梯度强度。这些梯度信息可以用来检测图像中的边缘,因为边缘通常表示图像中灰度值的剧烈变化。
Sobel 算子在图像处理和计算机视觉领域具有广泛的应用,例如边缘检测、角点检测、图像平滑和模糊等。它是一种简单而有效的方法,可用于提取图像的结构信息并进行特征提取。更详细的信息与公式可参考 OpenCV 官方文档 Sobel Derivatives。
我们通过 Sobel 运算可以得到图像一阶水平方向导数,目的是检测图像中的垂直边缘,便于区分车牌(注意 Sobel 运算只能对灰度图像有效,因此进行 Sobel 运算前必须先进行灰度化工作):
void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 // 2.灰度化 ... // 3.Sobel 运算 Mat sobel_16; // 输入的图像是 8 位的,而经过 Sobel 求导,导数可能会大于 // 255 或小于 0,因此结果的数据深度要用 16 位,8 位不够 // CV_16S 表示有符号 16 位整型 // 最后两个参数 1 与 0 分别表示仅对 X 方向求导,Y 方向不用 Sobel(gray, sobel_16, CV_16S, 1, 0); // sobel_16 无法显示,需要转回 8 位 Mat sobel; convertScaleAbs(sobel_16, sobel); imshow("sobel", sobel); ... }Sobel 运算后的效果:

可以看到,经过 Sobel 运算后,物体轮廓要比灰度图明显了。
3.4 二值化
二值化的通俗说法就是非黑即白。对图像的每个像素做一个阈值处理,为后续的形态学操作准备。
具体来讲,就是灰度图中每个像素值是 0 ~ 255,表示灰暗程度。现在我们设定一个阈值 t,像素值小于 t 的设为 0,否则设为 1,这样所有的像素就只有 0 或 1 两个值。
在 OpenCV 中,二值化使用 threshold() 函数:
/** 对每个数组元素应用固定级别的阈值。 该函数对多通道数组应用固定级别的阈值处理。通常,该函数用于将灰度图像转换为 二值图像(也可以使用 #compare 函数实现此目的)或者用于去除噪声,即过滤掉 像素值过小或过大的像素。函数支持几种类型的阈值处理,这些类型由参数 type 决定。 此外,特殊值 #THRESH_OTSU 或 #THRESH_TRIANGLE 可以与上述类型的阈值组合使用。 在这些情况下,函数将使用 Otsu's 算法或 Triangle 算法确定最优阈值,并将其用于 替代指定的 thresh。 @note 目前,Otsu's 算法和 Triangle 算法仅适用于 8 位单通道图像。 @param src 输入数组(多通道、8 位或 32 位浮点数)。 @param dst 输出数组,与 src 具有相同的大小、类型和通道数。 @param thresh 阈值。 @param maxval 在 #THRESH_BINARY 和 #THRESH_BINARY_INV 阈值类型中使用的最大值。 @param type 阈值类型(参见 #ThresholdTypes)。 @return 如果使用了 Otsu's 算法或 Triangle 算法,则返回计算出的阈值。 */ CV_EXPORTS_W double threshold( InputArray src, OutputArray dst, double thresh, double maxval, int type );使用 threshold() 进行二值化:
void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 // 2.灰度化 // 3.Sobel 运算 ... // 4.二值化(非黑即白,对比更强烈) Mat shold; // OTSU 算法 threshold(sobel, shold, 0, 255, THRESH_OTSU + THRESH_BINARY); imshow("shold", shold); }效果:

可以看出对比度更明显,轮廓更清晰了。
3.5 形态学操作(闭操作)
形态学操作的目的是将车牌字符连接成一个连通区域,便于取轮廓。
形态学操作的对象是二值化图像,操作有多种类型,腐蚀,膨胀是许多形态学操作的基础。我们先来了解部分操作类型:
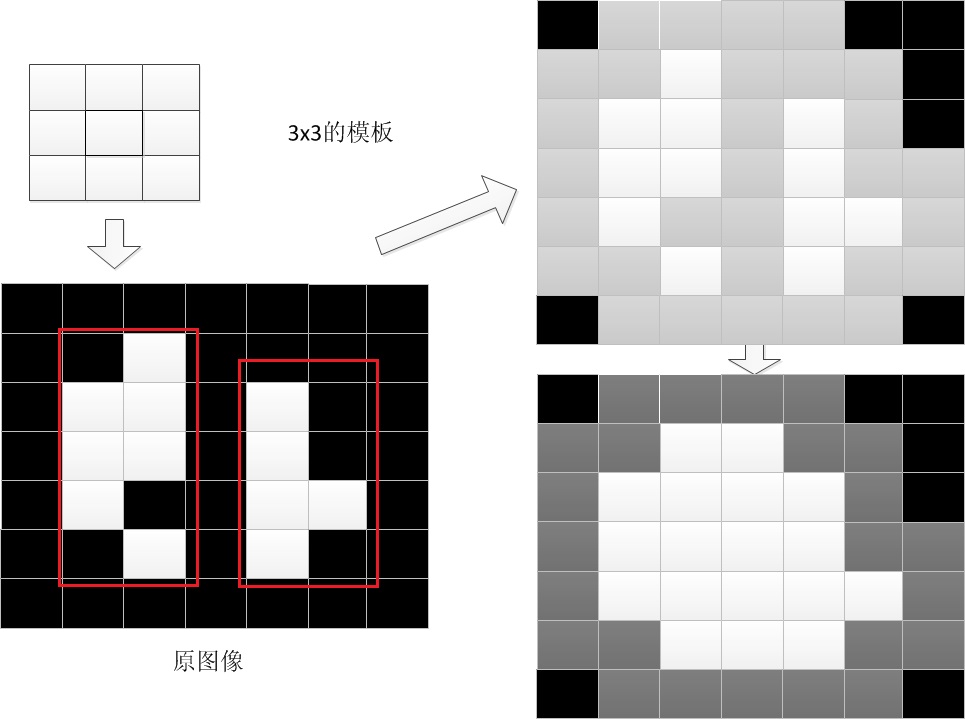
- 腐蚀(黑色腐蚀白色):让像素 x 位于模板的中心,根据模版的大小,遍历所有被模板覆盖的其他像素,修改像素 x 的值为所有像素中最小的值。实际上就是对于中心点像素 x,模板范围内没有黑色则保留,否则该像素涂黑:
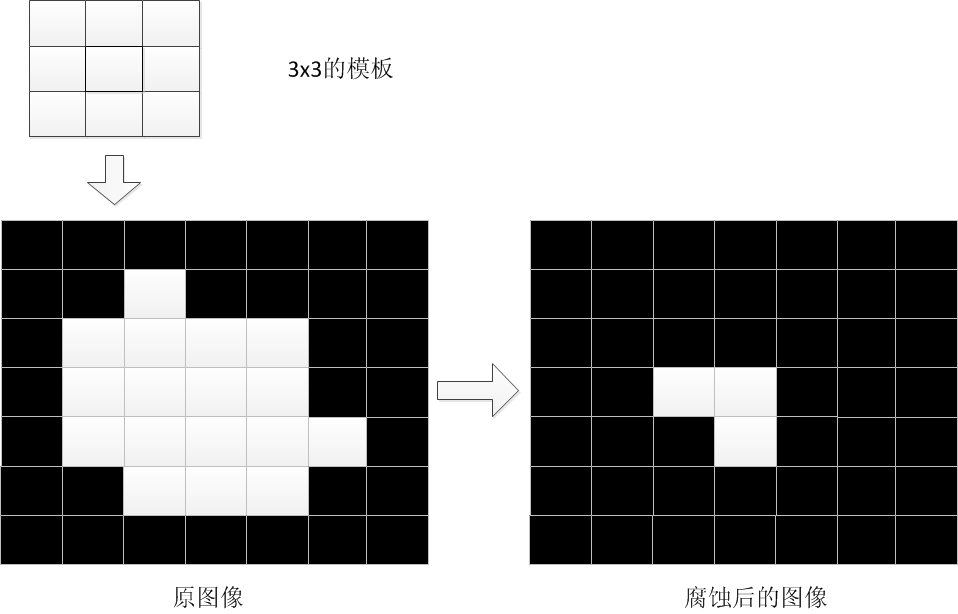
假如按照从上至下、从左至右的顺序逐个检查像素点,现在检查到第一排最右侧,设该像素点为 X,让 X 位于模板中心:
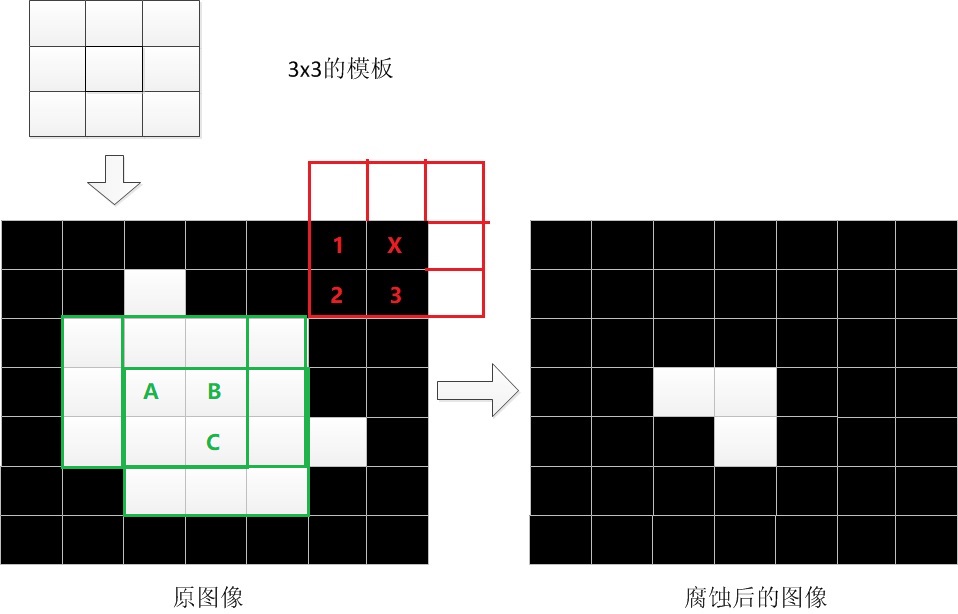
那么原图像被模板覆盖的除了 X 还有 1、2、3 共 4 个像素点,只要有 1 个是黑色,X 就要被涂成黑色。整个原图中只有 A、B、C 三个像素作为中心的 3 * 3 矩形全部为白色,因此腐蚀后的效果就像右边的图那样。
-
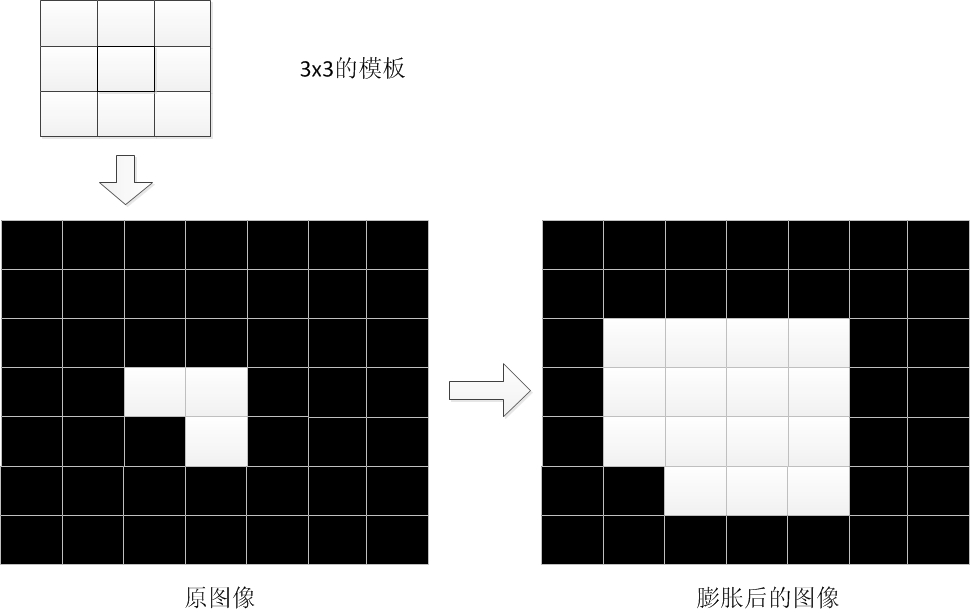
膨胀(白色膨胀占领黑色)与腐蚀操作相反:
-
开操作是先腐蚀,再膨胀:

-
闭操作是先膨胀,再腐蚀:
可以看到,闭操作将两个分开的部分融合成一个部分,这正是我们要做的把车牌字符的各个部分融合为整个车牌的轮廓:
void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 // 2.灰度化 // 3.Sobel 运算 // 4.二值化(非黑即白,对比更强烈) // 5.形态学操作中的闭操作 Mat close; // 获取模板,模板类型是矩形 Mat element = getStructuringElement(MORPH_RECT, Size(17, 3)); // MORPH_CLOSE 表示进行闭操作 morphologyEx(shold, close, MORPH_CLOSE, element); imshow("close", close); }效果如下:

可以看到原本车牌字符是分开的,现在都融合到一个车牌轮廓之中。
3.6 找轮廓
将连通域的外围画出来,便于形成外接矩形。这个矩形我们认为是可以有旋转角度的矩形,不一定是与 X 或 Y 正方向垂直的矩形。
在找轮廓的过程中会用到如下几个 API:
-
findContours() 用于查找轮廓:
/** @brief 在二值图像中查找轮廓 该函数使用 @cite Suzuki85 算法从二值图像中提取轮廓。轮廓是形状分析和目标检测与识别的有用工具。 请参阅 OpenCV 示例目录中的 squares.cpp。 @note 自 OpenCV 3.2 起,此函数不会修改源图像。 @param image 输入的 8 位单通道图像。非零像素被视为 1。零像素保持为 0,因此图像被视为二值图像。 您可以使用 #compare、#inRange、#threshold、#adaptiveThreshold、#Canny 等函数 将灰度图像或彩色图像转换为二值图像。如果 mode 等于 #RETR_CCOMP 或 #RETR_FLOODFILL, 则输入也可以是标签的 32 位整数图像(CV_32SC1)。 @param contours 检测到的轮廓。每个轮廓以点的向量形式存储(例如 std::vector)。 @param hierarchy 可选的输出向量(例如 std::vectorcv::Vec4i),包含关于图像拓扑的信息。它的元素个数 与轮廓的数量相同。对于每个 i-th 轮廓 contours[i],元素 hierarchy[i][0]、 hierarchy[i][1]、hierarchy[i][2] 和 hierarchy[i][3] 被设置为同一层次级别上下一个 轮廓、前一个轮廓、第一个子轮廓和父轮廓的0-based索引。如果轮廓 i 没有下一个、上一个、 父轮廓或嵌套轮廓,则 hierarchy[i] 的相应元素将为负数。 @param mode 轮廓检索模式,参见 #RetrievalModes @param method 轮廓逼近方法,参见 #ContourApproximationModes @param offset 可选的偏移量,用于将每个轮廓点平移。如果轮廓是从图像 ROI 中提取的, 然后在整个图像上下文中进行分析,这将非常有用。 */ CV_EXPORTS_W void findContours( InputArray image, OutputArrayOfArrays contours, OutputArray hierarchy, int mode, int method, Point offset = Point()); /** @overload */ CV_EXPORTS void findContours( InputArray image, OutputArrayOfArrays contours, int mode, int method, Point offset = Point()); -
minAreaRect() 用于查找最小面积旋转矩形:
/** @brief 寻找包围输入2D点集的最小面积旋转矩形。 该函数计算并返回指定点集的最小面积边界矩形(可能是旋转的)。开发者需要注意, 返回的旋转矩形在数据接近Mat元素边界时可能包含负索引。 @param points 输入的 2D 点集向量,存储在 std::vector 或 Mat 中 */ CV_EXPORTS_W RotatedRect minAreaRect( InputArray points );
minAreaRect函数用于找到能够包围给定的 2D 点集的最小面积旋转矩形。
该函数计算并返回一个最小面积的包围矩形(可能是旋转的),用于指定的点集。开发者应该注意,返回的RotatedRect对象可能包含负索引,当数据接近Mat元素边界时。
函数接受一个输入参数points,表示 2D 点的输入向量或矩阵。这些点可以使用std::vector或Mat来存储。
函数返回一个RotatedRect类型的对象,表示最小面积的旋转矩形。RotatedRect是一个包含旋转矩形相关信息的类,包括旋转矩形的中心坐标、宽度、高度和旋转角度等。
需要注意的是,当数据接近Mat元素边界时,返回的RotatedRect对象可能包含负索引。开发者在使用返回的旋转矩形时需要注意这一点。
void SobelLocator::locate(Mat src, vector& dst_plates) { // 1.高斯模糊 // 2.灰度化 // 3.Sobel 运算 // 4.二值化(非黑即白,对比更强烈) // 5.形态学操作中的闭操作 ... // 6.找轮廓 // vector是点的集合,可以连成线,线的集合就是轮廓了 vector contours; findContours(close, // 闭操作后的图像 contours, // 轮廓,接收结果 RETR_EXTERNAL, // 轮廓检索模式:外轮廓 CHAIN_APPROX_NONE // 轮廓近似算法模式:不进行轮廓近似,保留所有的轮廓点 ); // 一张图片会有多个轮廓,遍历将其画出 RotatedRect rotatedRect; for each (vector points in contours) { rotatedRect = minAreaRect(points); // 在原图 src 上画一个红色的、包围旋转矩形的最小正立整数矩形 rectangle(src, rotatedRect.boundingRect(), Scalar(0, 0, 255)); } imshow("找轮廓", src); ... }可以看到,在原图中找出了大大小小 N 多个轮廓:

3.7 尺寸判断
从上图看出,经过轮廓查找,一张图片中可以找出很多个轮廓,但是有很多从大小上判断,就明显就不可能是车牌。所以我们通过尺寸判断的方式,初步筛选排除不可能是车牌的矩形(中国车牌的一般大小是 440mm * 140mm,宽高比为 3.14)。
由于尺寸判断对于车牌定位而言是一个通用操作,因此将其放在基类 PlateLocator 作为一个 protected 成员(方便特定算法子类覆盖):
/** * 通过宽高比和面积两个方面校验传入的 RotatedRect 是否可能为车牌 */ bool PlateLocator::verifySizes(RotatedRect rotatedRect) { // 容错率 float error = 0.75; // 理想宽高比(训练样本使用的车牌规格为 136,36,因此将其用作理想宽高比计算) float aspect = float(136) / float(36); // 利用容错率计算出最小宽高比与最大宽高比 float aspectMin = (1 - error) * aspect; float aspectMax = (1 + error) * aspect; // 真实宽高比 float realAspect = float(rotatedRect.size.width) / float(rotatedRect.size.height); if (realAspect areaMax) || (realAspect aspectMax)) { return false; } return true; }在找轮廓的过程中会遍历形成矩形,用 verifySizes() 判断这些矩形是否符合规格,符合的存入 vec_sobel_rects 集合中:
// 6.找轮廓 // vector是点的集合,可以连成线,线的集合就是轮廓了 vector contours; findContours(close, // 闭操作后的图像 contours, // 轮廓,接收结果 RETR_EXTERNAL, // 轮廓检索模式:外轮廓 CHAIN_APPROX_NONE // 轮廓近似算法模式:不进行轮廓近似,保留所有的轮廓点 ); // 一张图片会有多个轮廓,遍历将其画出 RotatedRect rotatedRect; vector vec_sobel_rects; for each (vector points in contours) { rotatedRect = minAreaRect(points); // 在原图 src 上画一个红色的、包围旋转矩形的最小正立整数矩形 rectangle(src, rotatedRect.boundingRect(), Scalar(0, 0, 255)); // 7.尺寸判断,符合规格的放入 vec_sobel_rects 集合中 if (verifySizes(rotatedRect)) { vec_sobel_rects.push_back(rotatedRect); } } imshow("找轮廓", src); // 用绿色矩形画出符合尺寸规格的轮廓 for each (RotatedRect rect in vec_sobel_rects) { rectangle(src, rect.boundingRect(), Scalar(0, 255, 0)); } imshow("尺寸判断", src);经过尺寸判断,有可能为车牌的矩形被画成绿色:

3.8 矩形矫正
由于图片中的车牌不可能都像上面那样是正向的,也有可能是斜向的,比如下面这种:

那么在车牌定位阶段,就势必要对车牌轮廓的矩形进行旋转调整到水平正向位置,在旋转时还要注意不能超出原图的范围,最后还要将车牌图片调整到合适的大小方便后续识别。因此矩形矫正主要包括三方面内容:
- 获取一个范围安全(不会超过原图范围)的矩形
- 将偏斜的车牌调整为水平,为后面的车牌判断与字符识别提高成功率
- 调整车牌图片为合适大小为,确保候选车牌与导入机器学习模型之前尺寸一致,方便后续进行车牌字符识别
进入代码。上一步我们得到了尺寸校验合格的矩形集合 vec_sobel_rects,接下来就对这些矩形进行校正,并将校正结果存入 SobelLocator::locate() 的参数 dst_plates 中:
void SobelLocator::locate(Mat src, vector& dst_plates) { ... // 8.矩形矫正 tortuosity(src, vec_sobel_rects, dst_plates); // 查看校正结果 for each (Mat m in dst_plates) { imshow("Sobel 定位候选车牌", m); // 通过输入任意按键查看每一个候选车牌 waitKey(); } }tortuosity() 是校正操作的入口,包含了上面提到的三种矫正方法:
void PlateLocator::tortuosity(Mat src, vector& rects, vector& dst_plates) { // 遍历要处理的矩形 for each (RotatedRect rect in rects) { // 矩形角度 float angle = rect.angle; float r = float(rect.size.width) / float(rect.size.height); if (r 0) { // 旋转角度在 X 轴顺时针 5° 到逆时针 5° 的范围内就不用旋转了 dst = src_rect.clone(); } else { // 矩形相对于 safe_rect 的中心点坐标 Point2f ref_center = rect.center - safe_rect.tl(); Mat rotated_mat; // 旋转,结果保存在 rotated_mat 中 rotation(src_rect, rotated_mat, rect.size, ref_center, angle); dst = rotated_mat; } // 3.调整大小 Mat plate_mat; plate_mat.create(36, 136, CV_8UC3); resize(dst, plate_mat, plate_mat.size()); dst_plates.push_back(plate_mat); dst.release(); } }136 * 36 是我们训练车牌识别模型时使用的车牌样本图片宽高,为了提高识别率,我们在最后输出车牌定位结果时,也将图片宽高设置为 136 * 36。
计算范围安全的矩形:
/** * 获取一个范围安全(不会超过 src)的矩形 */ void PlateLocator::safeRect(Mat src, RotatedRect rotatedRect, Rect2f& safe_rect) { // RotatedRect 不含坐标信息,转换为带坐标的 Rect2f Rect2f boundRect = rotatedRect.boundingRect2f(); // 左上角坐标为 (t1_x,t1_y) float t1_x = boundRect.x > 0 ? boundRect.x : 0; float t1_y = boundRect.y > 0 ? boundRect.y : 0; // 右下角坐标为 (br_x,br_y) float br_x = boundRect.x + boundRect.width
-
-
- 腐蚀(黑色腐蚀白色):让像素 x 位于模板的中心,根据模版的大小,遍历所有被模板覆盖的其他像素,修改像素 x 的值为所有像素中最小的值。实际上就是对于中心点像素 x,模板范围内没有黑色则保留,否则该像素涂黑:







