

欢迎来到《小5讲堂》,大家好,我是全栈小5。
这是《Python》系列文章,每篇文章将以博主角度的理解展开讲解,
特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。
温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!

目录
- 前言
- 编辑器编码
- 输出文本
- 知识点
- 编码
- 输出函数
- 文章推荐
前言
基于上篇文章内容,在使用python代码时,如果是初学者,很容易出现编码问题报错,以及输出文本的报错。
Python编辑器默认读取的是Unicode编码,对于Python而言,print输出方法,所有内容都应该是字符串,否则报错。
编辑器编码
python文件由于不是utf-8编码,导致运行起来时直接报错提示
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xb5 in position 0: invalid start byte
SyntaxError:(unicode错误)“utf-8”编解码器无法解码位置0中的字节0xb5:无效的起始字节
可以通过下面方式把文件转为UTF-8编码,然后运行就可以显示了
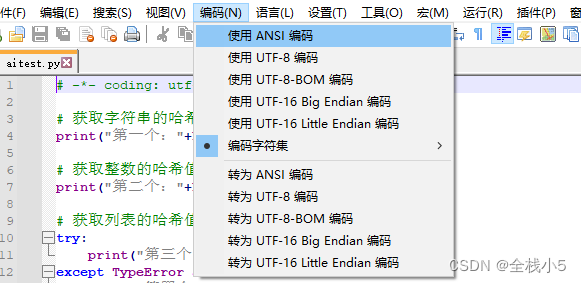
需要确保Python脚本文件以UTF-8编码保存,并且终端或编辑器也能够正确地处理Unicode字符。
使用的是Python交互式解释器,通常情况下是支持Unicode字符的,只需确保你的终端也支持UTF-8编码。
如果使用的是脚本文件,可以在文件开头添加一行指定编码方式的注释:
# -*- coding: utf-8 -*-
这样做会告诉Python解释器使用UTF-8编码读取该文件。使用的是编辑器,确保你的编辑器也以UTF-8编码打开文件。
输出文本
报错提示如下
can only concatenate str (not “int”) to str
尝试将一个字符串和一个整数进行拼接,但Python不允许直接将字符串和整数进行加法操作
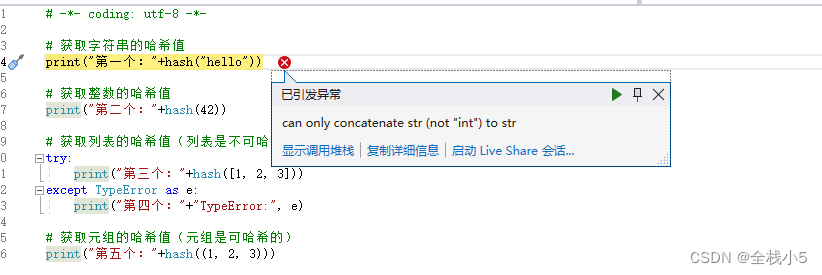
正确写法,直接将整型转为字符串即可
# -*- coding: utf-8 -*- # 获取字符串的哈希值 print("第一个:"+str(hash("hello"))) # 获取整数的哈希值 print("第二个:"+str(hash(42))) # 获取列表的哈希值(列表是不可哈希的,会抛出异常) try: print("第三个:"+str(hash([1, 2, 3]))) except TypeError as e: print("第四个:"+"TypeError:", e) # 获取元组的哈希值(元组是可哈希的) print("第五个:"+str(hash((1, 2, 3))))知识点
编码
当涉及到Python编码时,有几个重要的知识点需要了解:
1.字符串类型
Python中有两种字符串类型,即str和bytes。str是Unicode字符串,而bytes是字节字符串。在处理文本时,通常使用str类型。而在处理二进制数据(如图像、音频等)时,则使用bytes类型。
2.Unicode和编码
Unicode是一种字符集,它为世界上几乎所有的字符都定义了唯一的标识符。而编码是将Unicode字符转换为字节序列的规则。常见的编码包括UTF-8、UTF-16、UTF-32等。在Python 3中,默认的字符串类型是Unicode,并且推荐使用UTF-8编码。
3.字符串拼接
在Python中,可以使用加号(+)将两个字符串拼接在一起。但是需要注意,不能直接将字符串和其他类型(如整数、浮点数等)进行拼接,需要先将其转换为字符串类型。
4.字符串格式化
字符串格式化是一种将变量的值插入到字符串中的方法,使得字符串更具有可读性。常见的格式化方法包括format方法、f-string和%操作符。
5.文件编码
当处理文件时,特别是在读取或写入文本文件时,需要注意文件的编码格式。通常情况下,推荐使用UTF-8编码以支持更多的字符。
6.编码异常处理
在处理字符串时,可能会遇到编码相关的异常,如UnicodeError或SyntaxError。为了避免这些异常,可以在文件开头指定编码方式,或者确保所用的编辑器和终端都支持UTF-8编码。
这些知识点是Python编码中的基础,掌握它们能够帮助你更好地处理文本数据并避免常见的编码问题。
输出函数
针对上面输出文本报错情况,可以通过下面几个方式输出也是可以的。
字符串格式化允许在字符串中插入变量的值。
Python提供了几种字符串格式化的方法:
使用format方法
age = 25 message = "我今年{}岁。".format(age) print(message)使用f-string(Python 3.6及以上版本)
age = 25 message = f"我今年{age}岁。" print(message)使用%操作符
age = 25 message = "我今年%d岁。" % age print(message)
使用类型转换
你也可以通过将整数转换为字符串,然后再拼接它们:
age = 25 message = "我今年" + str(age) + "岁。" print(message)
文章推荐
【Python】尝试使用一个不可哈希的数据类型作为哈希表的键,错误提示builtins.TypeError,unhashable type
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
【Python】简单使用C/C++和Python嵌套for循环生成一个小爱心
【Python】Python3 使用Selenium模块实现简单爬虫系列一
【Python】Python基础学习之python版本对应MySQL-python版本查看
【Python】Python基础学习之python版本对应pip版本查看
总结:温故而知新,不同阶段重温知识点,会有不一样的认识和理解,博主将巩固一遍知识点,并以实践方式和大家分享,若能有所帮助和收获,这将是博主最大的创作动力和荣幸。也期待认识更多优秀新老博主。







