

LLM为什么需要agent化
虽然大语言模型的能力很强大,但是Llm仅限于用于训练的知识,这些知识很快会过时,所以llm有以下缺点
- 幻觉
- 结果并不总是真实的
- 对时事的了解有限或一无所知
- 难以应对复杂推理和计算
例如:买高铁票
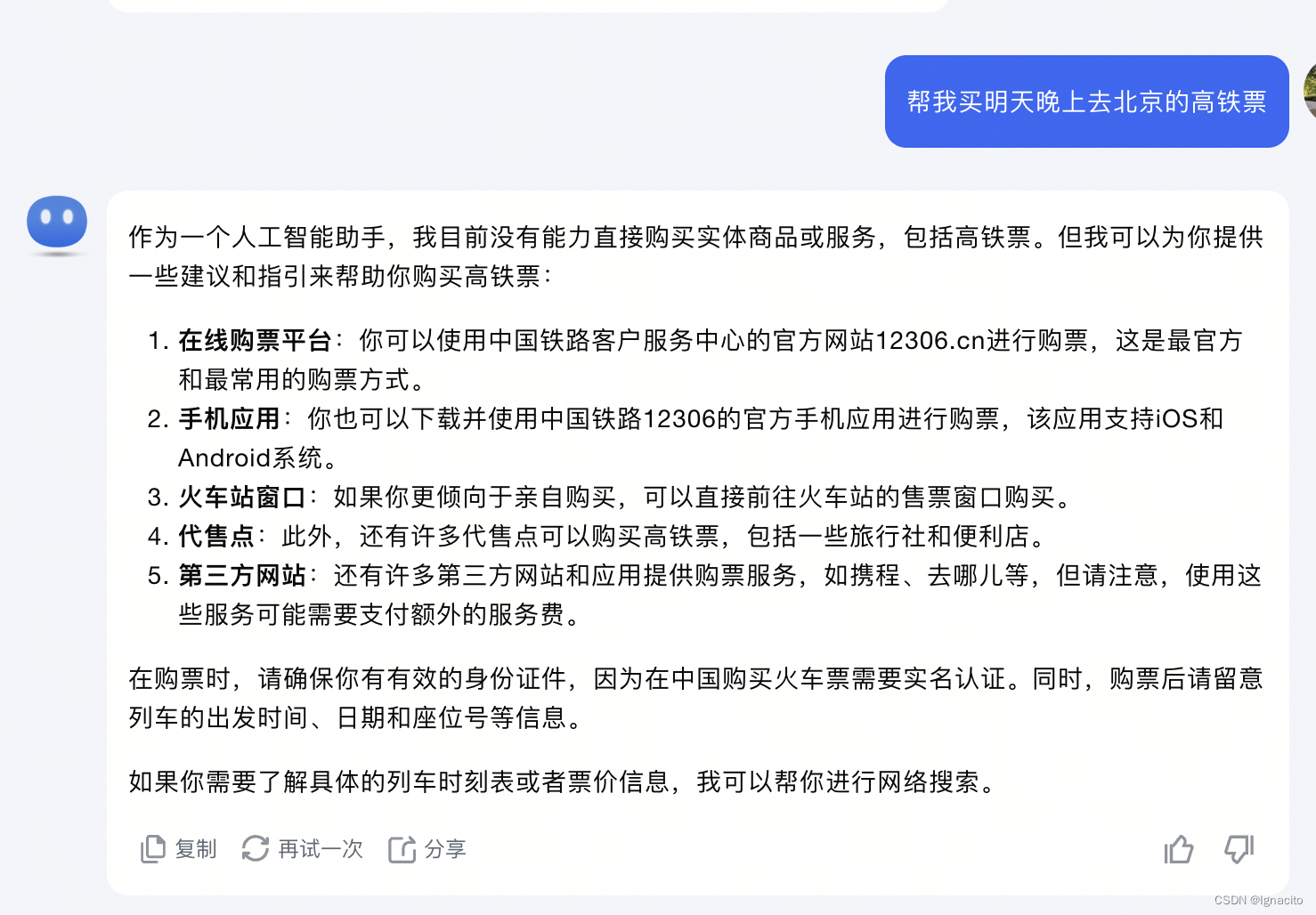
(虽然LLM完全理解了买票的行为,但是它本身并不知道“我”所处的城市,列车的时刻表,价格等等信息)
而基于大模型的Agent (LLM based Agent) 可以利用外部工具来克服以上缺点。
ReAct Agent
ReAct Agent 论文
LLM Agent 的升级之路:
Standard IO(直接回答) -> COT(chain-of-thought)(思维链) -> Action-Only (Function calling) -> Reason + Action
ReAct = Reasoning(推理) + Action(行动)
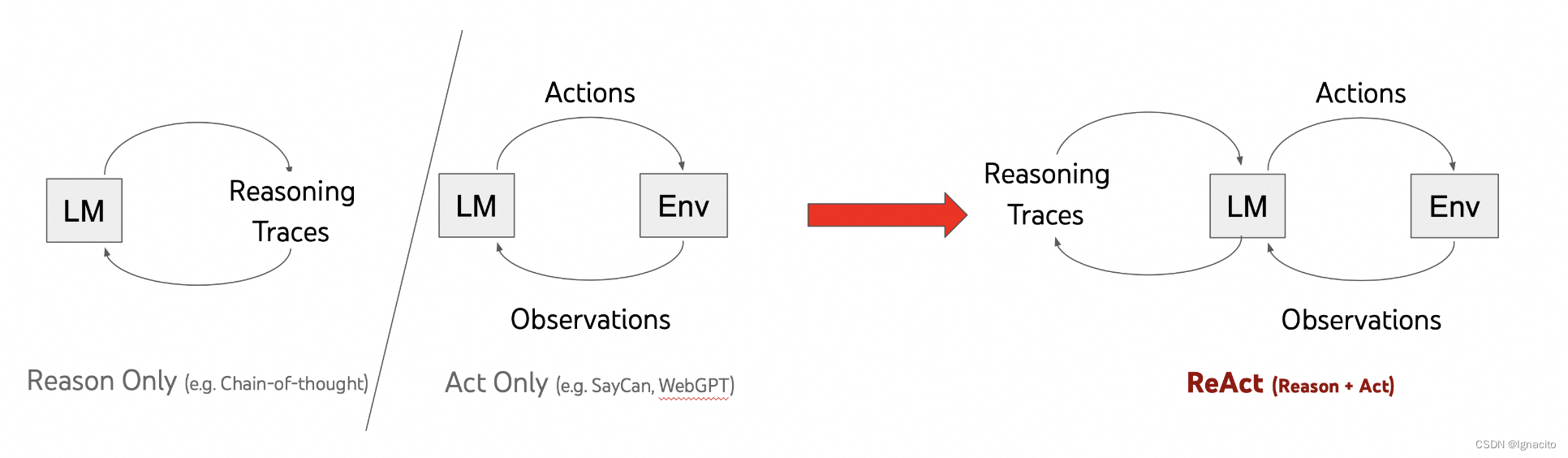
ReAct Agent 的组成部分 (通过LangChain实现)
- Models:LLM
- Prompts:对Agent的指令、约束
- Memory : 记录Action执行状态 & 缓存已知信息
- Indexes : 用于结构化文档,以便和模型交互
- Chains :Langchain的核心(链)
- Agent
ReAct Agent 的prompt 模板
from langchain_core.prompts import PromptTemplate template = '''Answer the following questions as best you can. You have access to the following tools: {tools} Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: {input} Thought:{agent_scratchpad}''' prompt = PromptTemplate.from_template(template)代码
手写一个能帮忙买火车票的智能Agent
注:火车票相关API均为mock
安装 & import依赖
pip install langchain pip install uuid pip install pydantic import json import sys from typing import List, Optional, Dict, Any, Tuple, Union from uuid import UUID from langchain.memory import ConversationTokenBufferMemory from langchain.tools.render import render_text_description from langchain_core.callbacks import BaseCallbackHandler from langchain_core.language_models import BaseChatModel from langchain_core.output_parsers import PydanticOutputParser, StrOutputParser from langchain_core.outputs import GenerationChunk, ChatGenerationChunk, LLMResult from langchain_core.prompts import PromptTemplate from langchain_core.tools import StructuredTool from langchain_openai import ChatOpenAI from pydantic import BaseModel, Field, ValidationError
定义工具(Tools)
细节可参考LangChain定义Tool
from typing import List from langchain_core.tools import StructuredTool def search_train_ticket( origin: str, destination: str, date: str, departure_time_start: str, departure_time_end: str ) -> List[dict[str, str]]: """按指定条件查询火车票""" # mock train list return [ { "train_number": "G1234", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 8:00", "arrival_time": "2024-06-01 12:00", "price": "100.00", "seat_type": "商务座", }, { "train_number": "G5678", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 18:30", "arrival_time": "2024-06-01 22:30", "price": "100.00", "seat_type": "商务座", }, { "train_number": "G9012", "origin": "北京", "destination": "上海", "departure_time": "2024-06-01 19:00", "arrival_time": "2024-06-01 23:00", "price": "100.00", "seat_type": "商务座", } ] def purchase_train_ticket( train_number: str, ) -> dict: """购买火车票""" return { "result": "success", "message": "购买成功", "data": { "train_number": "G1234", "seat_type": "商务座", "seat_number": "7-17A" } } search_train_ticket_tool = StructuredTool.from_function( func=search_train_ticket, name="查询火车票", description="查询指定日期可用的火车票。", ) purchase_train_ticket_tool = StructuredTool.from_function( func=purchase_train_ticket, name="购买火车票", description="购买火车票。会返回购买结果(result), 和座位号(seat_number)", ) finish_placeholder = StructuredTool.from_function( func=lambda: None, name="FINISH", description="用于表示任务完成的占位符工具" ) tools = [search_train_ticket_tool, purchase_train_ticket_tool, finish_placeholder]Prompt
主要任务Prompt
prompt_text = """ 你是强大的AI火车票助手,可以使用工具与指令查询并购买火车票 你的任务是: {task_description} 你可以使用以下工具或指令,它们又称为动作或actions: {tools} 当前的任务执行记录: {memory} 按照以下格式输出: 任务:你收到的需要执行的任务 思考: 观察你的任务和执行记录,并思考你下一步应该采取的行动 然后,根据以下格式说明,输出你选择执行的动作/工具: {format_instructions} """最终回复Prompt
final_prompt = """ 你的任务是: {task_description} 以下是你的思考过程和使用工具与外部资源交互的结果。 {memory} 你已经完成任务。 现在请根据上述结果简要总结出你的最终答案。 直接给出答案。不用再解释或分析你的思考过程。 """一些方便编程的工具类
class Action(BaseModel): """结构化定义工具的属性""" name: str = Field(description="工具或指令名称") args: Optional[Dict[str, Any]] = Field(description="工具或指令参数,由参数名称和参数值组成") class MyPrintHandler(BaseCallbackHandler): """自定义LLM CallbackHandler,用于打印大模型返回的思考过程""" def __init__(self): BaseCallbackHandler.__init__(self) def on_llm_new_token( self, token: str, *, chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any, ) -> Any: end = "" content = token + end sys.stdout.write(content) sys.stdout.flush() return token def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any: end = "" content = "\n" + end sys.stdout.write(content) sys.stdout.flush() return response定义Agent
class MyAgent: def __init__( self, llm: BaseChatModel = ChatOpenAI( model="gpt-4-turbo", # agent用GPT4效果好一些,推理能力较强 temperature=0, model_kwargs={ "seed": 42 }, ), tools=None, prompt: str = "", final_prompt: str = "", max_thought_steps: Optional[int] = 10, ): if tools is None: tools = [] self.llm = llm self.tools = tools self.final_prompt = PromptTemplate.from_template(final_prompt) self.max_thought_steps = max_thought_steps # 最多思考步数,避免死循环 self.output_parser = PydanticOutputParser(pydantic_object=Action) self.prompt = self.__init_prompt(prompt) self.llm_chain = self.prompt | self.llm | StrOutputParser() # 主流程的LCEL self.verbose_printer = MyPrintHandler() def __init_prompt(self, prompt): return PromptTemplate.from_template(prompt).partial( tools=render_text_description(self.tools), format_instructions=self.__chinese_friendly( self.output_parser.get_format_instructions(), ) ) def run(self, task_description): """Agent主流程""" # 思考步数 thought_step_count = 0 # 初始化记忆 agent_memory = ConversationTokenBufferMemory( llm=self.llm, max_token_limit=4000, ) agent_memory.save_context( {"input": "\ninit"}, {"output": "\n开始"} ) # 开始逐步思考 while thought_step_count >>>Round: {thought_step_count}observation}") # 更新记忆 self.__update_memory(agent_memory, response, observation) thought_step_count += 1 if thought_step_count = self.max_thought_steps: # 如果思考步数达到上限,返回错误信息 reply = "抱歉,我没能完成您的任务。" else: # 否则,执行最后一步 final_chain = self.final_prompt | self.llm | StrOutputParser() reply = final_chain.invoke({ "task_description": task_description, "memory": agent_memory }) return reply def __step(self, task_description, memory) - Tuple[Action, str]: """执行一步思考""" response = "" for s in self.llm_chain.stream({ "task_description": task_description, "memory": memory }, config={ "callbacks": [ self.verbose_printer ] }): response += s action = self.output_parser.parse(response) return action, response def __exec_action(self, action: Action) - str: observation = "没有找到工具" for tool in self.tools: if tool.name == action.name: try: # 执行工具 observation = tool.run(action.args) except ValidationError as e: # 工具的入参异常 observation = ( f"Validation Error in args: {str(e)}, args: {action.args}" ) except Exception as e: # 工具执行异常 observation = f"Error: {str(e)}, {type(e).__name__}, args: {action.args}" return observation @staticmethod def __update_memory(agent_memory, response, observation): agent_memory.save_context( {"input": response}, {"output": "\n返回结果:\n" + str(observation)} ) @staticmethod def __chinese_friendly(string) - str: lines = string.split('\n') for i, line in enumerate(lines): if line.startswith('{') and line.endswith('}'): try: lines[i] = json.dumps(json.loads(line), ensure_ascii=False) except: pass return '\n'.join(lines)测试
if __name__ == "__main__": my_agent = MyAgent( tools=tools, prompt=prompt_text, final_prompt=final_prompt, ) task = "帮我买24年6月1日早上去上海的火车票" reply = my_agent.run(task) print(reply)结果
第一轮思考
Agent根据要求,选择了需要使用的Tool,组装了请求参数并完成了调用。
(还可以多定义一些Tools,比如获取当前位置的,获取今天日期的工具等等,这样这里的查询火车票的参数可以更智能)
>>>>Round: 0 "name": "查询火车票", "args": { "origin": "当前位置", "destination": "上海", "date": "2024-06-01", "departure_time_start": "00:00", "departure_time_end": "12:00" } } ---- Observation: [{'train_number': 'G1234', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 8:00', 'arrival_time': '2024-06-01 12:00', 'price': '100.00', 'seat_type': '商务座'}, {'train_number': 'G5678', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 18:30', 'arrival_time': '2024-06-01 22:30', 'price': '100.00', 'seat_type': '商务座'}, {'train_number': 'G9012', 'origin': '北京', 'destination': '上海', 'departure_time': '2024-06-01 19:00', 'arrival_time': '2024-06-01 23:00', 'price': '100.00', 'seat_type': '商务座'}]h4第二轮思考/h4 p根据查询出的车票信息去调用购票的Tool/p pre class="brush:python;toolbar:false">>Round: 1 "name": "购买火车票", "args": { "train_number": "G1234" } } ---- Observation: {'result': 'success', 'message': '购买成功', 'data': {'train_number': 'G1234', 'seat_type': '商务座', 'seat_number': '7-17A'}} h4第三轮思考/h4 pLLM识别到任务已完成,输出了结果/p pre class="brush:python;toolbar:false">>Round: 2 "name": "FINISH" } 购买成功。您已成功购买2024年6月1日早上从北京出发前往上海的火车票,车次为G1234,座位类型为商务座,座位号为7-17A。







