

文章目录
- 单元0 前言
- 单元1 数学建模与机器学习
- 学习目标
- (一)什么是模型
- (二)数学模型的分类
- (三)数学建模的一般步骤
- (四)机器学习的概念
- (五)机器学习的分类
- (六)机器学习的算法
- (七)机器学习的步骤
- (八)机器学习三要素
- 单元2 Python安装和编程基础
- 学习目标
- (一)Python支持许多机器学习工具库
- (二)Anaconda
- (三)Jupyter Notebook
- (四)PyCharm
- (五)安装
- (六)基本数据类型
- (七)流程控制语句
- (八)习题:输入年月日,判断这一天是这一年的第几天
- 单元3 Python常用工具包
- 学习目标
- (一)NumPy
- 1、查看数组的数据类型使用dtype
- 2、特定函数创建规则型数组
- 3、数组的运算
- 4、数组索引与切片
- 5、数组的矩阵操作
- 6、数组的形状操作
- 7、NumPy数组的统计分析功能
- 8、案例1:简单房价预测(使用NumPy矩阵计算拟合房价)
- 9、案例2:使用NumPy随机数设计猜数游戏
- (二)Pandas
- 1、序列Series
- 2、数据框DataFrame
- 3、案例:读取数据创建DataFrame,统计并排序后打印
- (三)Matplotlib
【我选择这本书的理由】
这本书比较简单,案例是常见的经典案例,算法也是最基本的。还有就是数据集比较好获取,有些甚至是三方包里面自带的。
感觉对初学者比较友好。
【说明】
本笔记的结构框架与书中内容并不完全一致,依据个人兴趣及理解等做了筛选。有些知识点并不连贯,只是按条进行简单记录。
前面理论比较多,虽然简单基础,但我觉得还是有必要梳理一下,让思路更清晰。
单元2开始有代码,单元5开始才有案例。
单元0 前言
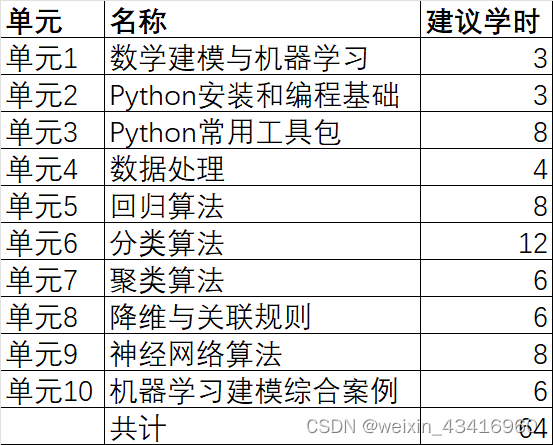
作者给出教学建议:共64学时,也就是说,一个星期就能学完啦~
单元1 数学建模与机器学习
学习目标
【知识目标】
1、掌握数学模型的概念和建模步骤
2、了解机器学习的概念和算法
【能力目标】
能够对常见问题进行简单的数学建模
(一)什么是模型
1、模型是相对于原型而言的。
所谓原型,就是客观世界中存在的现实对象、实际问题、研究对象和系统。
而模型是根据实物按比例、生态或其他特征制成的与实物相似的一种物体,模型是原型的替代品。
2、模型分为物理模型和数学模型。
物理模型是指对原型按照保留主要特征、设计次要特征……比如飞机模型、火箭模型……(不写了哈,就是乐高好吧。。反正物理模型与机器学习无关)
数学模型是用数学语言对原型进行表示的数学公式、图形或算法等形式,它是真是系统的一种抽象。
数学模型是分析、设计、预报或预测、控制实际系统的基础。
一般来说,数学模型是指用字母、数字和其他数学符号构成的等式或不等式,或用图表、图像、框图、数理逻辑等来描述系统的特征及其内部或与外部联系的模型。
数学模型的理解示意图:
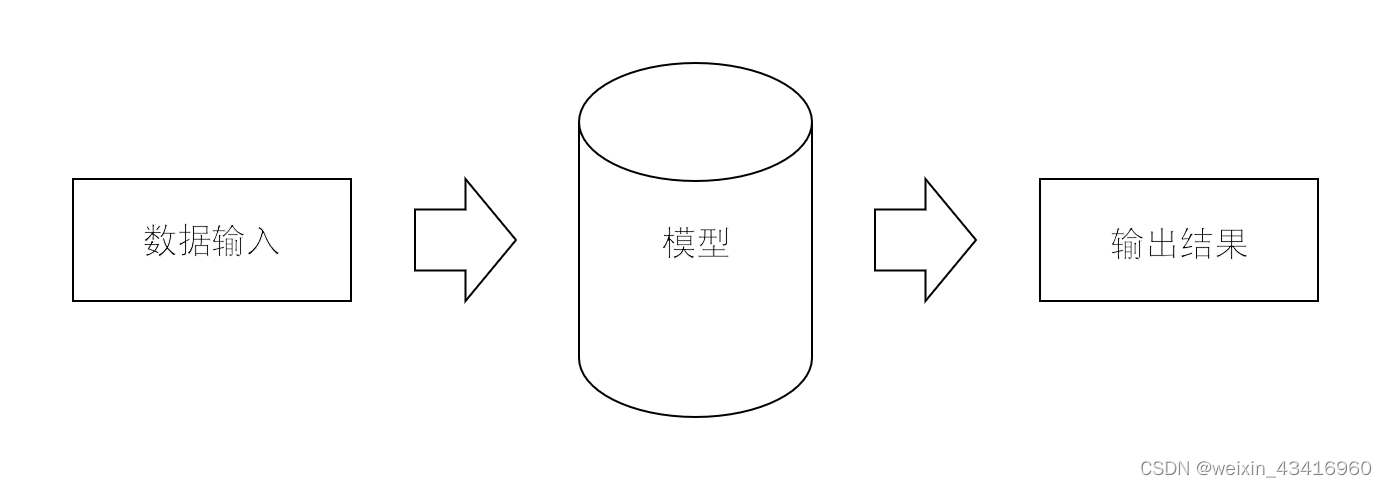
假设输入数据是x,输出结果是y,那中间的模型就是一个x和y之间的方程,当然,这只是一种片面的解释,但有助于理解模型是什么。
3、模型由结构和参数两部分构成。结构一般是根据人的理解和对事物的认识而选择或创建的,参数是通过算法根据样本数据逐步确定的,确定参数的过程叫做训练。
我的理解结构就是选择什么模型;不同的模型结构不一样,里面的x、y以及方程的解(也就是参数)就不同。
4、机器学习算法中的深度学习,实际上就是增加了结点(又称为算子,代表一个操作,一般用来表示施加的数字运算,也可以表示数据输入的起点以及输出的终点)的层数和个数,从而增加了模型的复杂度。
(二)数学模型的分类

这里了解即可。我感觉说的不是很对,黑白灰箱那里。等学习深入以后再验证吧。反正这里不是重要的知识点。
为什么不用脑图?不喜欢看,乱。。
(三)数学建模的一般步骤
数学建模:问题定义 ==> 数学模型 的过程。
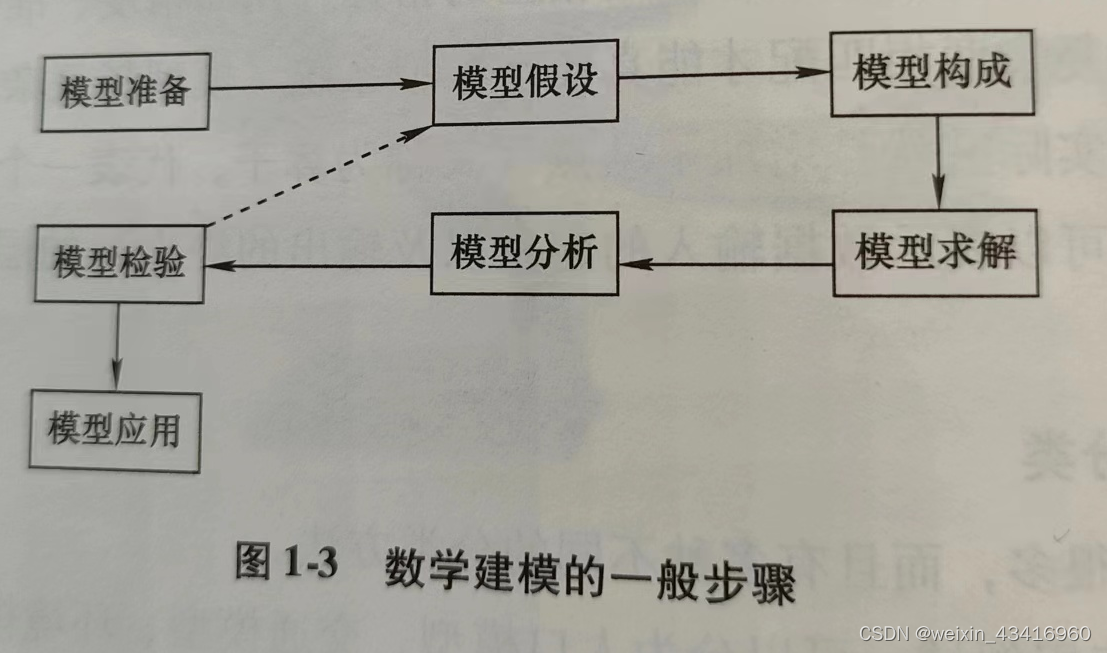
懒得自己画了,直接上图片。
【第1步】模型准备
了解问题的实际背景,明确建模目的 ==> 搜集必需的信息(如数据)=> 尽量弄清研究对象的主要特征
【第2步】模型假设
根据对象的特征和建模目的,抓住问题本质,忽略次要因素 => 对问题进行必要的、合理的简化假设
【第3步】模型构成
根据所做的假设,用数学语言、符号描述对象的内在规律,建立包含常量、变量等的数学模型,如优化模型、微分方程模型等。
建立数学模型是为了让更多人明了并加以应用,因此尽量采用简单的数学工具。
【第4步】模型求解
可以采用解方程、画图形、优化方法、逻辑运算、数值运算等各种传统的和近代的数学方法,特别是数学软件和计算机技术。
【第5步】模型分析
对结果进行分析,如结果的误差分析、统计分析、模型对数据的灵敏性分析、对假设的强健性分析等。
【第6步】模型检验
将求解和分析结果返回到实际问题,与实际的现象、数据比较,检验模型的合理性和适用性。
如果结果与实际不符,问题常常出现在模型假设上,应该修改、补充假设,重新建模(图中虚线部分)。
直到检验结果获得某种程度上的满意为止。
【第7步】模型应用
用建立的模型解决实际问题。
(四)机器学习的概念
1、人工智能的应用范围包括计算机科学、金融贸易、医疗、交通、农业、服务业等行业。
其中,机器学习是解决人工智能问题的主要技术,在人工智能体系中处于基础与核心的地位。它广泛应用与机器视觉、语音识别、自然语言处理、数据挖掘等领域。
2、通俗来讲,机器学习是让计算机通过模拟人类的学习行为,来获取新的知识和技能,重新组织已有的知识结构,以不断改善自身智能。(这个说法我不喜欢……感觉又笼统又不准确)
比如在无人驾驶汽车系统中,机器学习的任务是根据路况确定驾驶方式,遇到红灯时刹车、遇到行人时避让,学习的效果用事故发生概率度量。经验就是人类大量的驾驶数据。从这些数据中,机器学习算法能提取出各种路况下人类正确的驾驶方式,从而在无人驾驶模式下根据学习的驾驶方式来操纵汽车。
==>机器学习是对已知的样本数据(或称为经验数据)加以提炼,用数学模型完成对数据进行预测和决策的任务。
在机器学习中,用于学习的样本数据称为训练数据,完成任务的方法称为模型。
3、机器学习应用
停车场出入口的车牌识别、电商网站的商品推荐、新闻头条的新闻推荐、人脸识别、语音输入、人机对弈等。
(五)机器学习的分类
按训练方式不同,分为监督学习、无监督学习和强化学习。
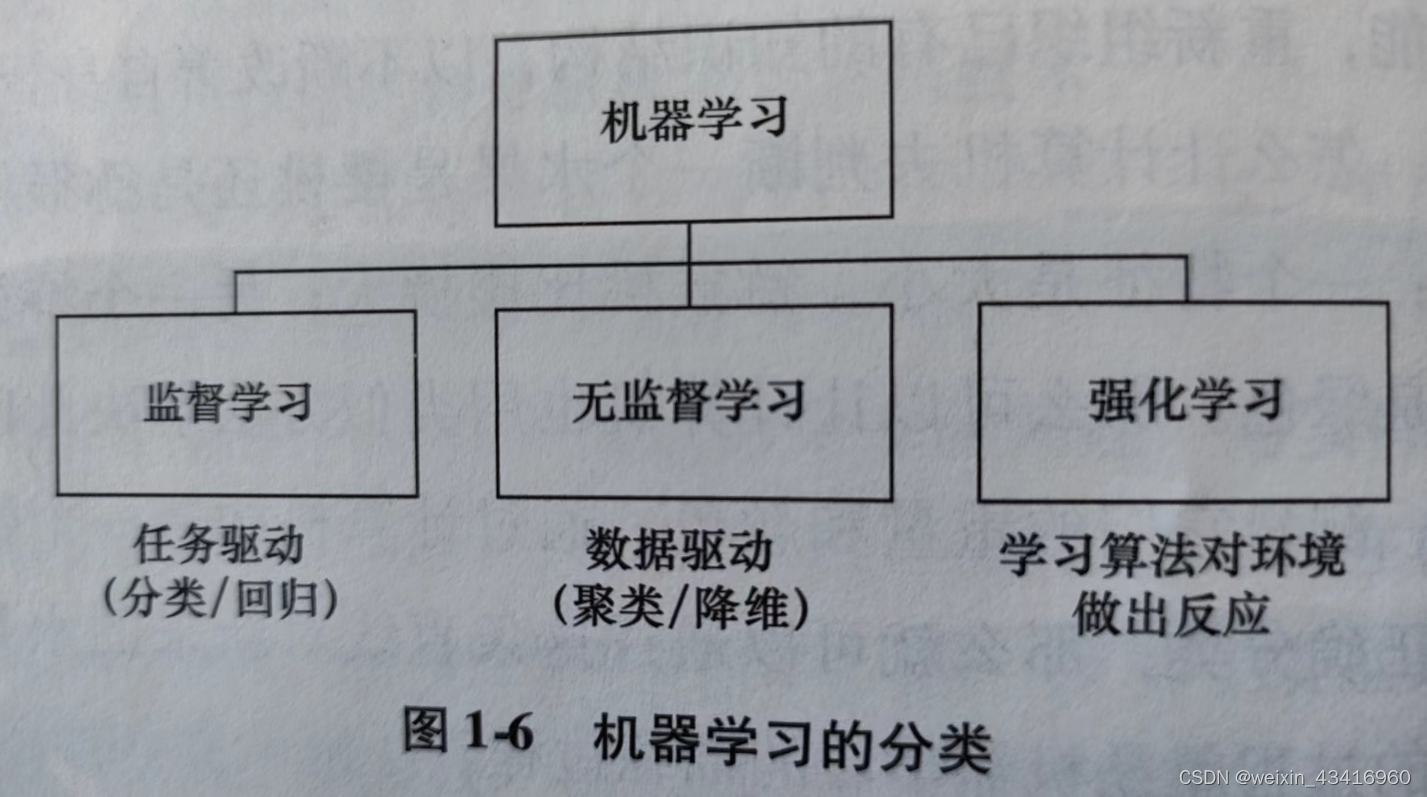
1、监督学习:监督学习的样本数据都带有相应的特征组和标签。监督学习的任务就是根据对象的特征组对标签的取值进行预测推断。
根据样本数据所带标签值的特性,可以将监督学习分为两类:
1)分类问题:标签只取有限个可能值,如垃圾邮件识别。
2)回归问题:标签取值于某个区间的连续实数,如房价预测问题。
2、无监督学习:无监督学习的样本数据不含标签。学习的任务通常是对数据本身的模式进行识别与分类。
无监督学习的典型代表:
1)聚类问题:聚类问题与监督学习中的分类问题类似,也是将数据按模式归类,只不过聚类问题中的类别是未知的,分类问题的类别是已知的。如个性化新闻推送。
2)降维问题:在机器学习中,每个样本的特征组可以用一个向量表示。在许多应用中特征组维度相当高,甚至达到百万级。众多的特征增加了求解问题的难度,因此需要考虑对特征组进行降维处理,即用低维度的向量表示原始的高维特征。
3、强化学习:比如训练小狗坐这个动作,当小狗动作正确时,给它一把狗粮作为奖励,当它的动作错误时就不给狗粮奖励。那么时间一长,小狗就学会了坐这个动作,这个想学习过程就是强化学习。
强化学习的任务是根据对环境的探索制定应对环境变化的策略。其机制是动作发生后观察结果,根据上一个结果做出下一个动作。
它模拟了生物探索环境与积累经验的过程。
应用:博弈策略、无人驾驶、机器人控制等诸多前沿人工智能领域。
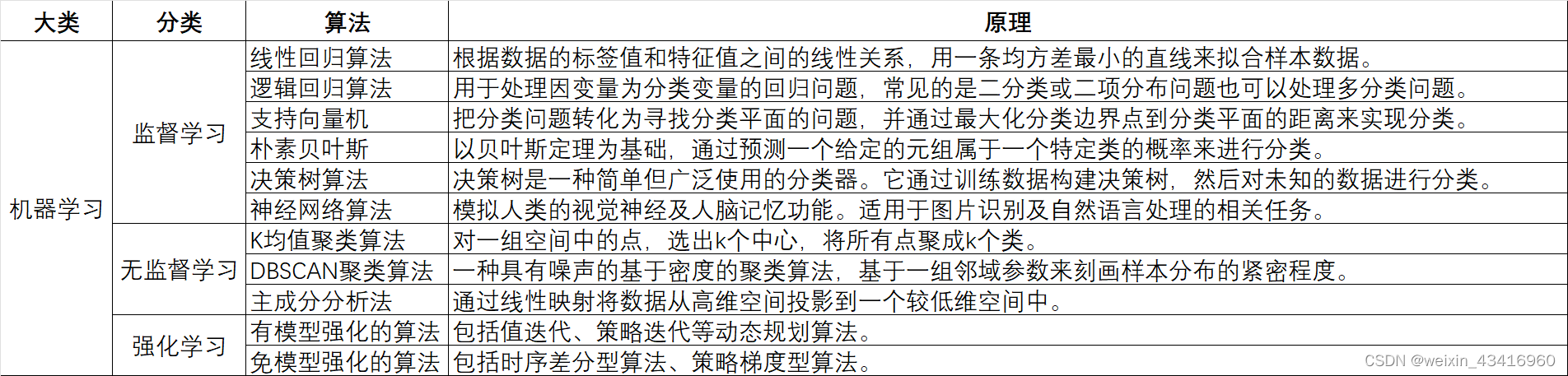
(六)机器学习的算法
(七)机器学习的步骤
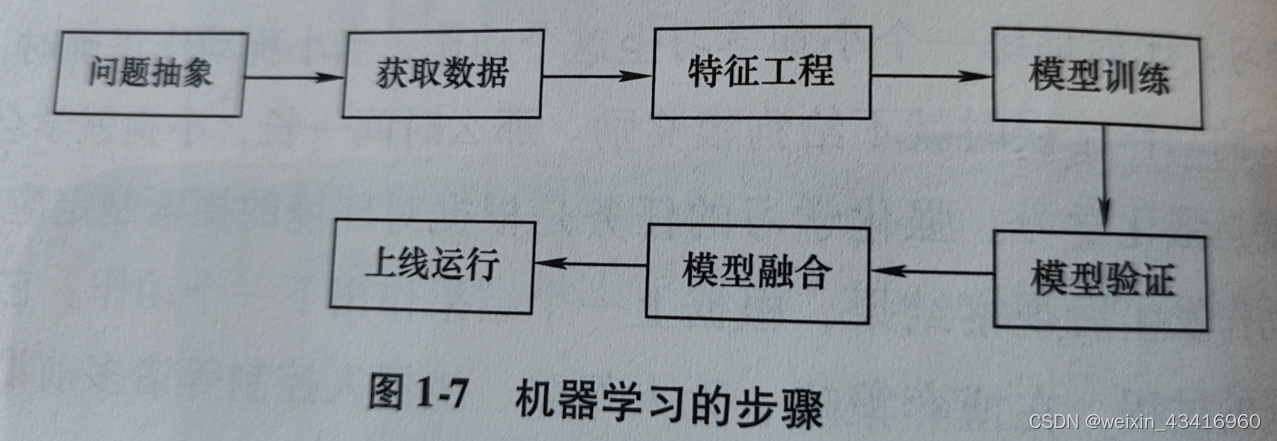
1、问题抽象:现实问题抽象成数学问题。
具体:明确可以获得什么样的数据,目标是一个分类、回归还是聚类问题。如果都不是的话,是否可以将其归类为其中的某类问题。
2、获取数据
包括获取原始数据、从原始数据中经过特征工程提取训练数据、测试数据。
3、特征工程
包括从原始数据中进行特征构建、特征提取、特征选择。
4、模型训练、诊断、调优
模型诊断中至关重要的是判断过拟合、欠拟合,常见的方法是绘制学习曲线,交叉验证。
增加训练的数据量、降低模型复杂度 ==> 降低过拟合
提高特征的数量和质量、增加模型复杂度 = => 防止欠拟合
5、模型验证、误差分析
通过测试数据,验证模型的有效性,观察误差样本,分析误差产生的原因,往往能找到提升算法性能的突破点。
6、模型融合
提升算法的准确度,主要方法是将多个模型进行融合。
在机器学习比赛中,模型融合非常常见,基本都能使得模型效果有一定的提升。
7、上线运行
模型在线上运行的效果直接决定模型的成败。
不仅包括模型的准确程度、误差等情况,还包括运行的速度、资源的消耗程度、稳定性是否可接受。
(八)机器学习三要素
数据、算法、模型。
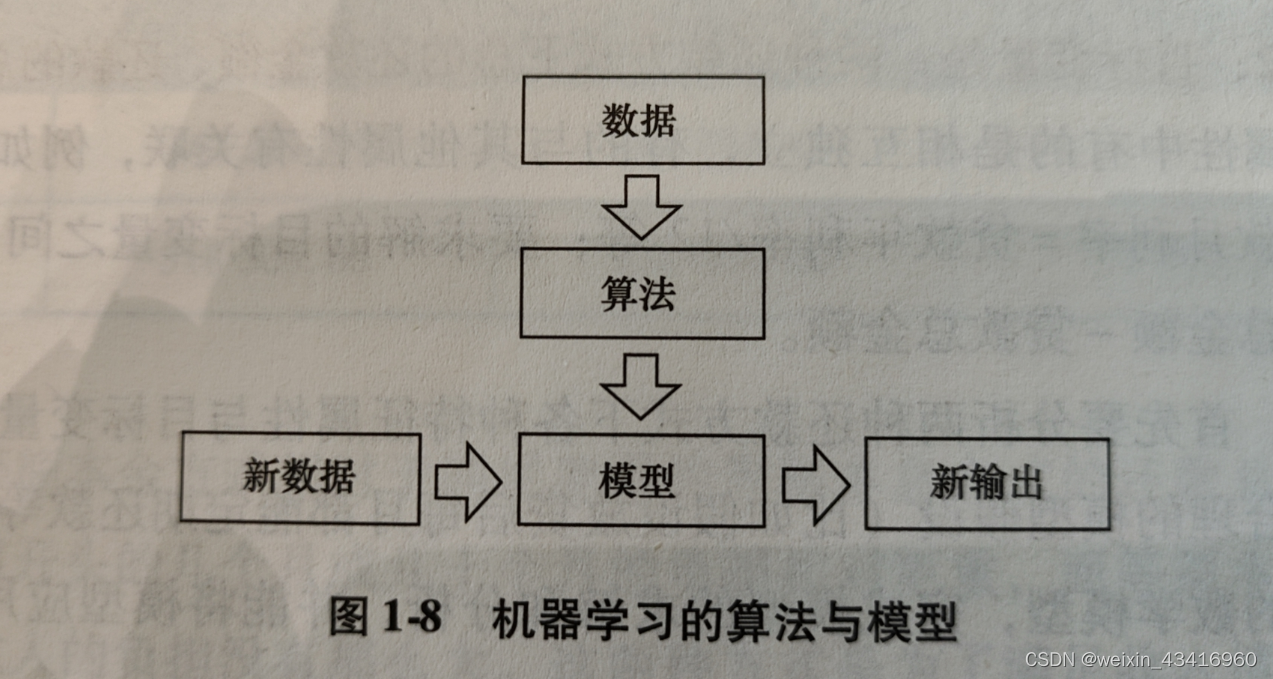
1、数据
2、算法:指的是线性回归、逻辑回归、朴素贝叶斯、支持向量机等算法。
从本质上说,这些算法都是由一些公式组成的。
比如一元线性回归方程y=ax+b就是线性回归最简单的形式。在这个公式中,x、y分别是自变量和因变量,在训练模型时输入训练数据实际上就是输入这些变量,然后通过计算将参数a、b计算出来,这样模型就训练好了。如果a=2,b=1,那么模型就是y=2x+1,利用这个模型就可以实现基本的预测功能了,而生成这个模型的过程就是数据建模的过程。现在有一个新的数据点(5,y),将x=5输入这个模型预测出y,结果是11。
点评:这个例子非常好,虽然简单,却也直观的告诉初学者,所谓算法,其实就是一个公式,或者一些公式的组合。
我们通过大量的x、y、z…等等变量(也就是训练集里面的特征值、目标值),计算出公式里面的系数a、b、c、d…等(也就是参数),然后把这些参数套到x、y、z的公式里面,就得到了模型结果(就是训练出来的模型),也就是一个系数是已知常数公式或者一些公式的组合。
然后我们用自变量(假设x、y是自变量,z是因变量)x、y套入到刚才算好a、b、c、d等系数的这个 公式/公式组合 里面,得到新的因变量z的值,看看与实际的z值接不接近(这个过程就是测试模型)。
3、模型:概括来说,模型是一个从输入到输出的函数,算法则是利用样本生成模型的方法,学习(也可称为训练)则是利用样本通过算法生成模型的过程。
算法和模型的区别是什么啊? 我理解的是,这个公式里面系数的求解过程是算法。当系数求出来了,公式也就确定下来了,然后这个模型也就确定了。 算法就是求解公式/函数的过程,模型就是求出来的这个公式/函数。 比如我们要做一个公式,先加10再减5再取绝对值,这个加、减、取绝对值,都是算法,最后我们通过这个算法组合,得到一个或几个公式,这个结果(一个或几个公式)就是模型。 (不知道我理解的对不对)
单元2 Python安装和编程基础
目前人工智能相关的程序通常使用python来编写的,原因?
1、python是一门解释型脚本语言,入门简单、易上手。
2、phthon开发效率高,有非常强大的第三方库,基本上可以实现计算机能实现的任何功能。在这些库的基础上进行开发,可以大大降低开发周期。==>站在巨人肩膀上
学习目标
【知识目标】
1、掌握python软件的安装方法
2、掌握python编程基础语法
【能力目标】
1、能够独立安装python软件和用到的工具包
2、能够使用Jupyter Notebook或PyCharm编写案例的代码
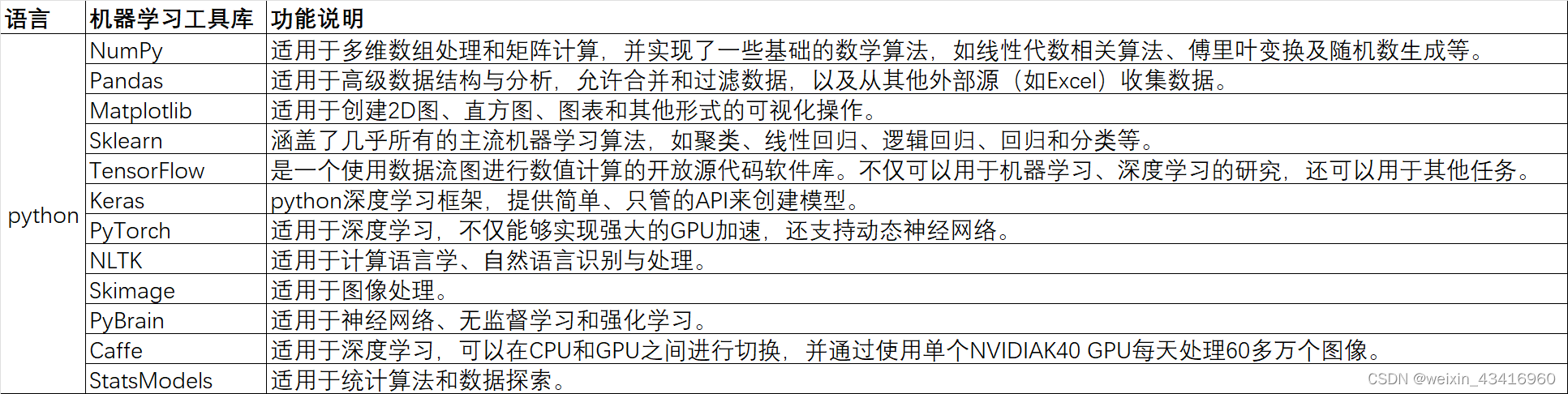
(一)Python支持许多机器学习工具库
例如:
(二)Anaconda
1、Anaconda是Python的一个集成管理工具,它把Python中有关数据计算分析的包都集成在一起,里面包含了720多个数据科学相关的开源包,在数据可视化、机器学习、深度学习等方面都有涉及。
2、它同时也是个环境管理器,解决了多版本Python并存、切换的问题。
3、还有个巨大优势:即,有偏数据分析风格的Spyder集成环境以及交互很好的Jupyter Notebook应用。
==> Anaconda优点总结:省时省心、分析利器
(三)Jupyter Notebook
本质是一个Web应用程序,便于创建和共享文字化程序文档,支持实时代码、数学方程、可视化和Markdown。
【优点】
1、极其适合数据分析:运行即可在cell下得到结果。
2、支持多语言:只要安装对应程序语言的核(kernel),就可使用该语言。
3、分享便捷:支持以网页的形式分享,也支持导出成HTML、Markdown、PDF等多种格式的文档。
4、远程运行:在任何地点都可以通过网络连接远程服务器来实现运算。
5、交互式展现:不仅可以输出图片、视频、数学公式,还可以呈现一些互动的可视化内容,需要交互式插件(Interactive Widgets)来支持。
【缺点】
1、不太适合做工程。
2、不方便调试。
(四)PyCharm
带有一整套可以帮助用户在使用Python语言开发时提高效率的工具。
如:调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制等。
此外,该IDE还提供了一些高级功能,以用于支持Django框架下的专业Web开发。
IDE,全称“Integrated Development Environment”,中文意思为“集成开发环境”。 集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。 IDE一般包括代码编辑器、编译器、调试器和图形用户界面等工具,可以独立运行,也可以和其它程序并用。 常见的IDE如微软的Visual Studio系列、Borland的C++ Builder、Delphi系列等。
(五)安装
书中演示了Python、Anaconda、PyCharm、Jupyter Notebook,挤一挤Python扩展包的安装方法和安装过程。略。
关于Anaconda的安装可参考本人另一篇博客:
【机器学习】anaconda安装过程
【安装python扩展包】有三种方法
1、直接复制
针对单文件模块,可直接把文件复制到Python安装目录下的Lib文件夹下($python_dir/Lib)
2、使用pip工具
3、使用源文件
在Github上下载对应的压缩包,解压缩之后,文件夹下会有个setup.py文件,从命令行窗口进入该文件夹,输入命令:
python setup.py install
即可完成扩展包安装。
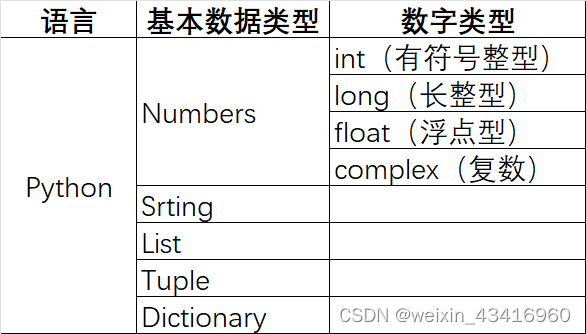
(六)基本数据类型
Python有5个标准的数据类型:Numbers(数字)、Sting(字符串)、List(列表)、Tuple(元组)、Dictionary(字典)。
可以用type()查看变量类型。
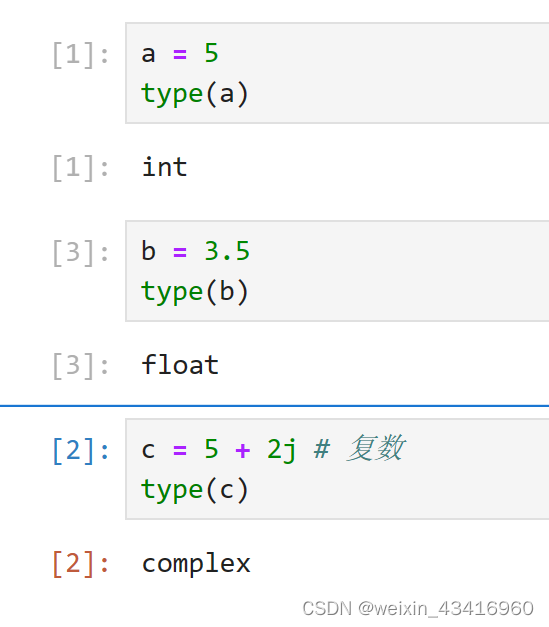
1、Numbers(数字)
2、String(字符串)
1)Python中可以使用单引号、双引号、或者三个引号来创建字符串。
2)字符串切片:可以使用变量[头下标:尾下标:步长]来截取相应的字符串。其中,默认步长为1,同时默认头下标为0、尾下标为字符串长度。
我理解这里所说的下标,是索引?
当步长为负数时,默认头下标为字符串长度-1,且默认尾下标为none(尾下标不是0,否则不包含第0个字符;尾下标也不是-1,否则指的是最后一个字符)。
==>当步长为负数的时候,就是倒着来。从后往前截取。
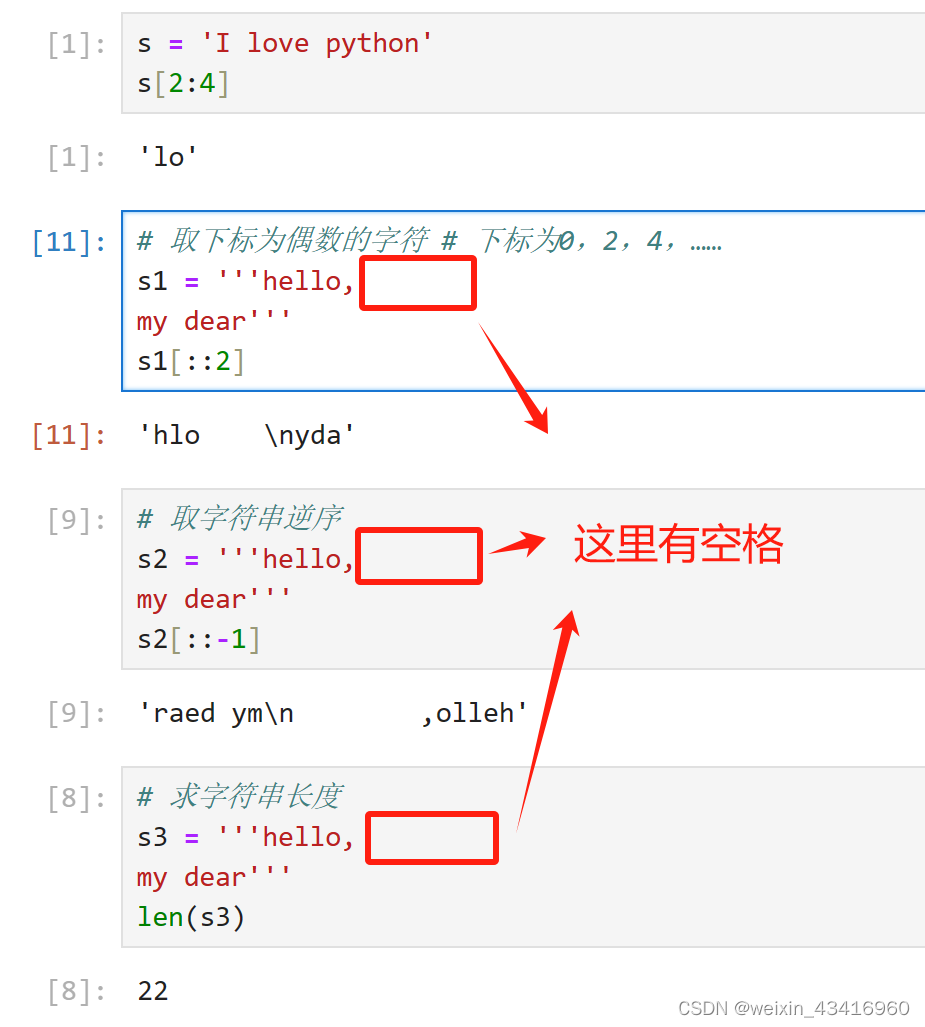
s = 'I love python' s[2:4] # 取下标为偶数的字符 # 下标为0,2,4,…… s1 = '''hello, my dear''' s1[::2] # 取字符串逆序 s2 = '''hello, my dear''' s2[::-1] # 求字符串长度 s3 = '''hello, my dear''' len(s3)
3、List(列表)
把都好风格的不同数据项用方括号括起来即是列表。其数据项不需要具有相同的类型,切片操作和字符串一致。

【常用的列表操作方法】
- list.append(obj):在列表末尾添加新的对象
- list.extend(other_list):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- list.index(obj):从列表中找出某个对象第一次匹配的索引位置
- list.insert(index, obj):将对象插入列表中的指定位置
- list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- list.remove(obj):移除列表中某个值的第一个匹配项
- list.sort([func]):对原列表进行排序

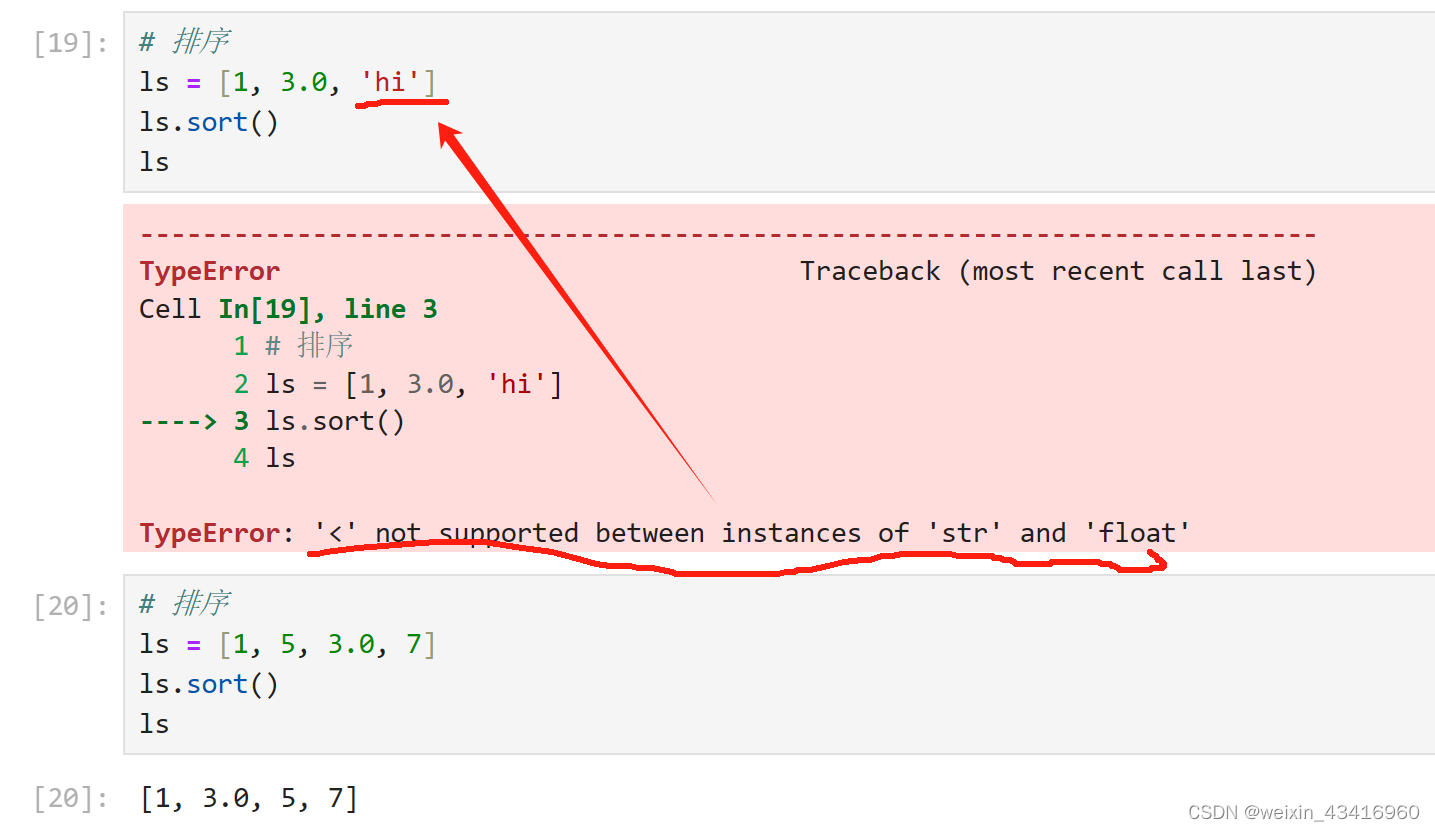
列表里面,虽然可以有各种数据类型,但排序的时候要注意他们是否可以直接比较大小。
4、Tupple(元组)
一般情况下,用小括号将逗号分隔的不同数据项括起来即为元组,但是小括号可以省略。
可以将元组看作特殊的列表,因为元组不能进行修改。

5、Dictionary(字典)
字典由键和对应值成对组成,每个键与值用冒号“:”隔开,每对用逗号分隔,整体放在花括号“{}”中。
字典也被称作关联数组或哈希表。
1)键必须独一无二,值不必
2)只可以是任意数据类型,但必须是不可变的,也就是只能是字符串、数值或元组。

(七)流程控制语句
编程语言中的流程控制语句分为顺序语句、分支语句和循环语句。
1、顺序语句:不需要单独的关键字来控制,就是逐行执行。
2、条件分支语句是通过判断条件的执行结果(true/false)来决定执行哪个分支的代码块,当判断结果为true则执行true分支的语句,否则执行false分支的语句(可以没有false分支语句)。
3、循环语句:用于多次执行一个代码语言或代码块,Python中提供for循环和while循环。


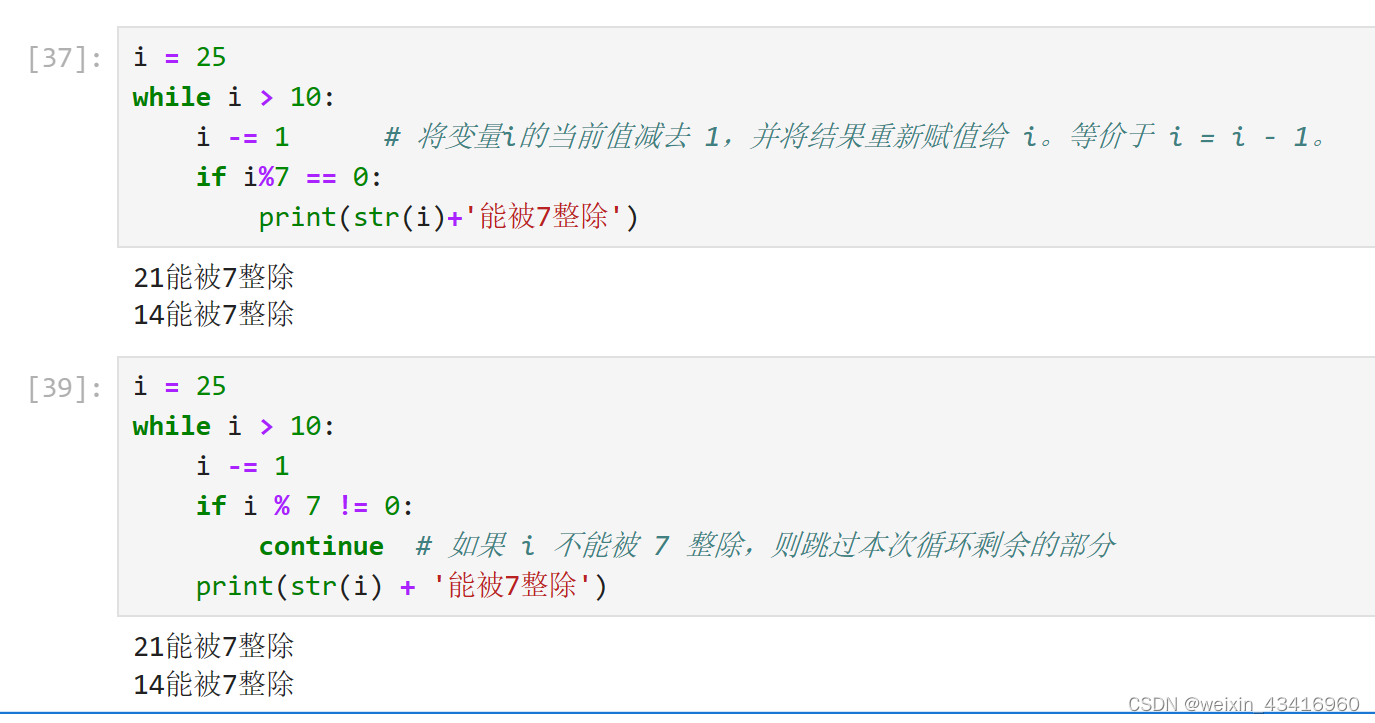

(八)习题:输入年月日,判断这一天是这一年的第几天
(代码来自文心一言)
def is_leap_year(year): """判断是否是闰年""" return (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0) # 判断是否是闰年,是返回True,不是返回False。 def day_of_year(year, month, day): """计算这一天是一年中的第几天""" month_days = [31, 28 + is_leap_year(year), 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] return sum(month_days[:month - 1]) + day # 2月份的天数28与True相加等于29,与False相加等于28. # 返回值是输入月份的上一个月对应的列表里面元素之和(也就是截止到上个月的天数),再加上输入的“日”(也就是当月的天数)。 # 示例使用 year = int(input("请输入年份: ")) month = int(input("请输入月份: ")) day = int(input("请输入日期: ")) # 调用函数并打印结果 day_number = day_of_year(year, month, day) print(f"{year}年{month}月{day}日是一年中的第{day_number}天")单元3 Python常用工具包
学习目标
【知识目标】
1、掌握NumPy库中数组的运算、随机数处理和数据统计分析方法
2、掌握Pandas库中Series序列和DataFrame数据框的使用方法
3、掌握Matplotlib库中散点图、曲线图、直方图、柱状图、饼图等的绘制方法
4、学习Sklearn中数据集、算法的调用方法
【能力目标】
1、能够调用NumPy库方法对模型数据进行计算处理
2、能够使用Series序列和DataFrame对模型数据进行统计分析
3、能够调用Matplotlib库设计绘图布局,进行图形绘制
4、能够调用Sklearn中机器学习算法进行模型训练和数据预测
(一)NumPy
1、NumPy是Numerical Python的缩写。
2、提供了快速计算数组的例程,包括数学运算、逻辑运算、形状操作、排序、选择、I/O、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等。
3、NumPy的核心是数组(arrays),具体来说是多维数组(n-dimensional arrays)。
NumPy就是对这些数组进行创建、删除、运算等操作的一个程序包。
1、查看数组的数据类型使用dtype
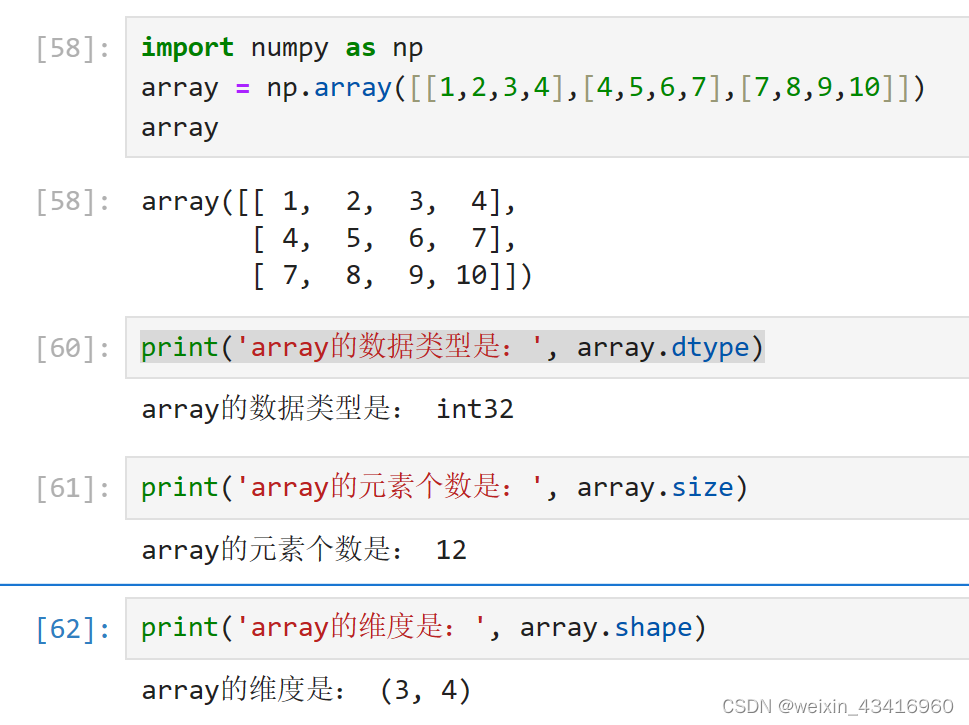
NumPy中最常用的数据类型是bool、int32、int64、float16、float32等。
2、特定函数创建规则型数组
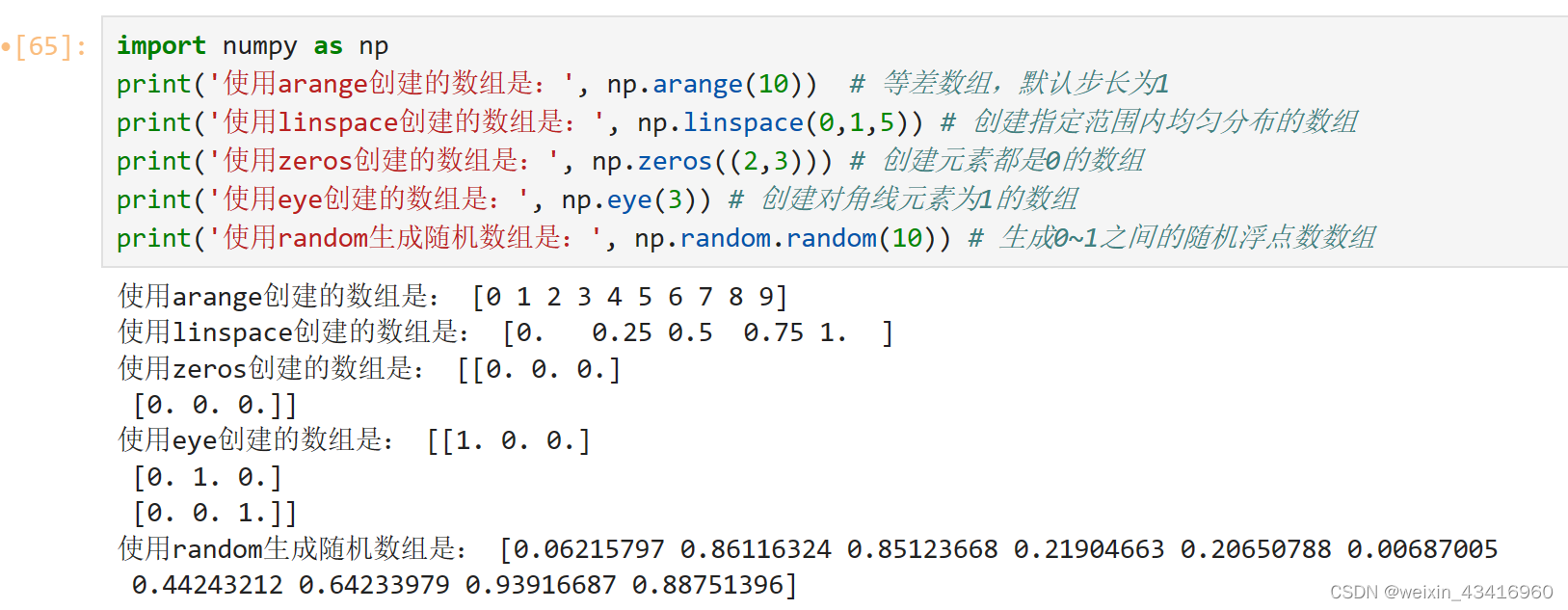
3、数组的运算

4、数组索引与切片

5、数组的矩阵操作
用mat()函数创建矩阵,dot()函数进行矩阵相乘,X.T表示矩阵X的转置。
NumPy线性代数库linalg中的inv函数可用于方阵求逆。
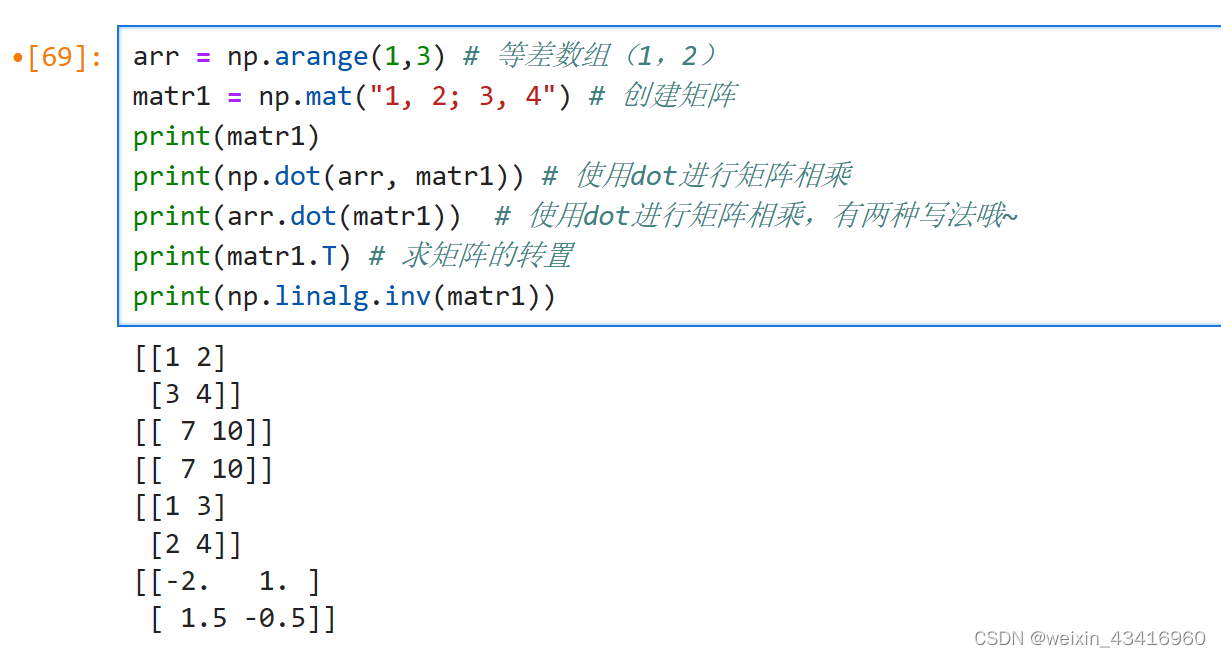
在NumPy中,np.mat()创建的矩阵Matrix必须是二维的,但是np.array()可以是多维的,Matrix是arrays的一个分支,包含于arrays。所以矩阵拥有数组的所有特性。
6、数组的形状操作

7、NumPy数组的统计分析功能

对二位数组来说,既可以对所有元素进行求和等统计,也可以对列或行进行统计,此时就需要额外再设置一个参数axis,表示按照第几个维度进行计算。

8、案例1:简单房价预测(使用NumPy矩阵计算拟合房价)
使用NumPy矩阵计算拟合房价
# 案例来自《机器学习建模基础》机械工业出版社 ## 案例1 简单房价预测 # 给出房屋面积及售价,求出模型(也就是公式)。模型/公式确定后,可利用它做下一步的预测。 # 思路: # 房价预测问题属于典型的回归模型的求解问题。 # 可以列出个样本点的售价组成的向量y、房子面积组成的矩阵X以及函数的参数向量θ,它们之间的关系为y=Xθ,求解参数的公式为θ=(XTX)-1XTy (这里的-1和T都应该在右上角的) # 在本案例中,y=[100, 120,117, 125],每个样本的特征是房子面积,特征向量是x=(1,房子面积),所以矩阵X=[[1,100], [1,150], [1,130], [1,160]],参数向量θ=[θ0, θ1] (这里的0、1是右下角). import pandas as pd import numpy as np import matplotlib.pyplot as plt # 创建一个字典,其中键是列名(标题),值是列的数据 data = { '面积/m³': [100, 150, 130, 160], '售价/万元': [100, 120, 117, 125] # '城市': ['北京', '上海', '深圳'] } print('data:', data) # 使用字典创建DataFrame df = pd.DataFrame(data) # 显示DataFrame print('df:\n', df) # print(df) X = np.array([[1,100], [1,150], [1,130], [1,160]]) # 由样本数据的房屋面积生成的X数组 y = np.array([100, 120,117, 125]) # 由样本数据的房价生成的y数组 a = np.linalg.inv(np.dot(X.T, X)) # 求出X转置乘以X,然后求逆 b = np.dot(a, X.T) # 然后再乘以X转置 theta = np.dot(b, y) # 求出参数theta print('theta:', theta) plt.plot(X[:,1], y, 'bo') # 绘制样本点数据 x = np.linspace(50, 200, 100) f = theta[0] + theta[1] * x plt.plot(x, f, 'r') plt.show() # 可见房价模型的参数θ0和θ1分别是61.5和0.4,所以房价模型的数据表达式就是y=61.5+0.4x,利用这个模型就可以通过新的房屋样本的房屋面积来预测房价。9、案例2:使用NumPy随机数设计猜数游戏
(1)生成随机浮点数和整数
print(np.random.rand(3,2)) # 参数3,2用于构建矩阵大小 print(np.random.randint(10,size=(5,4))) # 返回[1,10)间的随机整数,构成5行4列数组 print(np.random.rand()) # 返回一个随机值 print(np.random.randint(0,10,3)) # 返回{0,10)之间的3个随机数(2)有时候我们进行随机操作,希望每次的随机结果相同,怎么办呢?
主要指定随机种子就可以。
常用的函数:
np.random.seed(100) # 种子设成100 print(np.random.rand(3,2))
这里每次都把种子设置成100,说明随机策略相同,无论执行多少次随即操作,结果都是相同的。
不同的种子结果不同。
(3)生成服从正态分布的随机值
1)np.random.randn(d0,d1,d2,…,dn)可以返回一个或一组服从正态分布的随机样本值。
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。
2)当没有参数时,返回一个浮点数。
当有多个参数时,返回一个对应维度的多维数组。如np.random.randn(2,3)返回一个2行3列的数组。
print(np.random.randn()) print(np.random.randn(2,3))
(4)使用NumPy随机数设计猜数游戏
realNumber = np.random.randint(1,20) # 生成1到20之间的随机整数 for i in range(3): # 给三次机会 guessNumber = int(input('请输入你猜的数:')) # 读入用户猜的数 if guessNumber realNumber: print('猜大了!') else: print('恭喜你,猜对了!') break(二)Pandas
(1)Pandas是Python Data Analysis Library的简称,意为“Python数据分析库”。它是基于NumPy构建的。
Pandas用来分析结构化数据,其功能强大且提供了高级数据结构和数据操作工具。
(2)Pandas包含了数据读取、清洗、分析、矩阵运算以及数据挖掘等功能,最初用于金融数据分析,因其功能强大而应用日益广泛,成为许多数据分析的基础工具。
1、序列Series
(1)在Pandas中有两类重要的数据结构:序列(Series)和数据框(DataFrame)。
(2)Series类似于NumPy中的一维数组,并且其中每个数据对应一个索引值,可以使用一维数组中的函数或方法,也可以通过索引标签的方式获取数据,而且具有索引的自动对齐功能。
# 通过一维数组的方式创建Series import numpy as np import pandas as pd s = pd.Series(np.arange(3)) # 通过NumPy数组的方式创建序列 print(s) ls = [3,5,7] t = pd.Series(ls) # 通过python列表的方式创建序列 print(t) # 这里没有指定索引,所以索引都是从0开始。 # 当然也可以指定索引值 ls = [3,5,7] t = pd.Series(ls) t.index = ['a','b','c'] print(t)
(3)Series的索引数据有三种方法:
- loc()方法通过行号列标签索引行数据
- iloc()方法通过行号列号索引行数据
- ix()方法通过行标签或行号索引数据(基于loc和iloc的混合)
# Series索引操作 s1 = pd.Series({'a':10,'b':20,'c':30,'d':40,'e':50}) print('按行号索引:', s1.iloc[1]) # 按行号查找 print('按标签索引:', s1.loc['c']) # 按标签查找 s1['b'] = 21 # 修改数据 print(s1) s1.replace(to_replace=21,value=22,inplace=True) # 将to_replace的值替换为value,inplace=True代表在原Series上进行修改。 print(s1)2、数据框DataFrame
DataFrame类似于NumPy的二维数组,同样可以使用NumPy数组的函数和方法。
此外还有数据排序、转置、缺失值处理等更灵活的操作应用。
(1)创建DataFrame
# 创建DataFrame df = pd.DataFrame({'A':[11,21,31,41],'B':[5,6,7,8],'C':[0,1,0,1]}) print(df) print('索引:', df.index) # 返回索引 print('列名:', df.columns) # 打印每一列特征的名字 print('类型:', df.dtypes) # 打印每一列的类型 print('取值:', df.values) # 直接取得数值矩阵 # DataFrame还可以通过二维数组直接创建,创建时会自动按列序号添加列名和索引 ar = np.array([[1,2,3],[4,5,6]]) dfm = pd.DataFrame(ar) print(dfm)(2)数据索引
# 数据索引 print(df['A']) # 按列名索引 print(df.head()) # 查看前5行数据 print(df.tail(3)) # 查看后3行数据 # 可以看到打印的数据中,最左侧会加入一列数字,这些在原始数据中是没有的,相当于给样本加上了索引。 # 默认情况下都是用数字来作为索引,可以将其中某列设为索引,也可以通过索引获取某一部分具体数据。 df1 = df.set_index('A') # 将A列设为索引 print('索引后:\n', df1.head()) print('A/C列:\n', df[['A','C']][:3]) # 通过索引获取前3行数据的A、C两列 print('第0行:\n', df.iloc[0]) # 根据位置获取第0行数据 print('A=21的数据:\n', df1.loc[21]) # A列值查找# 与Series类似,也可以通过iloc、loc、ix方法进行索引 df = pd.DataFrame({'A':[11,21,31,41],'B':[5,6,7,8],'C':[0,1,0,1]}) print(df) print('按行号列号索引:', df.iloc[1,0]) # 按行号列号查找 print('按标签索引:', df.loc[0,'B']) # 按标签查找 print(df.loc[df['A']>30,:]) # 可以通过条件语句索引数据# 不仅可以通过索引改值,还可以改索引,通过给index赋值或通过rename()函数来实现 print(s1) s1.index = ['aa','bb','cc','dd','ee'] print(s1) s1.rename(index ={'aa':'AA'}, inplace=True) # inplace=True代表在原Series上进行修改 print(s1.index)(3)增加索引可以通过append()等方式实现
注意:在新的pandas版本中,使用append()会有报错:
‘DataFrame’ object has no attribute ‘append’
‘Series’ object has no attribute ‘append’
这是因为append()改成了_append()
# 增加索引可以通过_append()等方式实现 ss1 = pd.Series({'a':10, 'b':20}) print(ss1) df = pd.DataFrame(ss1) print(df) s2 = pd.concat([df,df]) print(s2) s2['c'] = 40 print(s2) # 增加索引可以通过append()等方式实现 ss1 = pd.Series({'a':10, 'b':20}) print(ss1) df = pd.DataFrame(ss1) print(df) s2 = df._append(df) # 注意新版本pandas中_append()函数的写法 print(s2) s2['c'] = 40 print(s2) #对比以上df连接的方法ss1 = pd.Series({'a':10,'b':20}) s2 = ss1._append(ss1) s2['c'] = 40 print(s2)(4)数据的统计分析
# 数据的统计分析 df = pd.DataFrame({'A':[11,21,31,41],'B':[5,6,7,8],'C':[0,1,0,1]}) print(df) print(df.sum(axis=0)) # 指定维度计算总和,默认是按列计算 print(df['A'].value_counts()) # 统计该列所有属性的个数 print(df.describe()) # 指标统计(按列)使用cut()可以对数据进行分箱操作。
# 使用cut()进行分箱操作 ages = [15,18,20,21,22,34,41,52,63,79] bins = [10,40,80] bin_res = pd.cut(ages, bins) print(bin_res) grpnames = ['Youth', 'Old'] bin_res = pd.cut(ages,bins,labels=grpnames) print(bin_res)
(5)文件操作
1)to_csv()方法可以将DataFrame数据存入csv文件中。若不需要保存索引,设置index=None或False。
2)read_csv()方法可以读取csv文件
主要参数:filepath_or_buffer是文件路径或数据缓存地址;sep是指定分隔符,默认逗号分隔符;header指定行数作为列名,默认为0,当没有列名时设置为None。
(6)merge拼接
merge()方法用于两表拼接(数据列关联)。有左连接、右连接、外连接等,默认是内连接。
# merge()拼接 pd1 = pd.DataFrame({'key':['k0','k1','k2'],'A':['a0','a1','a2'],'B':['b0','b1','b2']}) pd2 = pd.DataFrame({'key':['k0','k1','k3'],'C':['c0','c1','c3'],'D':['d0','d1','d3']}) print(pd1) print(pd2) res1 = pd.merge(pd1,pd2,on='key') # 默认内连接,key值不一致的剔除掉了 print(res1) res2 = pd.merge(pd1,pd2,on='key',how='outer',indicator=True) # indicator=True显示详细的组合说明 print(res2)(7)排序
# 排序 data = pd.DataFrame({'group':['a','a','b','b','c','c'],'data':[4,3,12,3,5,7]}) print(data) data = data.sort_values(by=['group','data'],ascending=[False,True]) # 首先根据 group 列的值进行j降序,然后在每个 group 内部,再根据 data 列的值进行升序。 print(data)3、案例:读取数据创建DataFrame,统计并排序后打印
# 案例:使用Pandas展示苹果销量数据 # df_apple = pd.read_csv('./data/apple.csv') # print(df_apple) df_apple = pd.DataFrame({'year':[2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015,2016,2017,2018,2019,2020],'apple':[12.8,12.3,13.1,12.9,13.8,13.2,13.7,14.2,14.5,13.6,13.8,13.1,13.2,14.2,14.8,14.3,14.5,14.6,14.9,14.7,14.8],'price':[50.2,71.3,81,76.2,80.3,79.2,82.3,84.1,85.2,90.1,88.6,92.3,91.6,93.9,98.6,102.6,111.2,114.3,115.5,117.6,116.5],'income':[1606,1513,1567,1547,1646,4705,1798,1823,1812,1953,2105,2215,2301,2294,2415,2486,2512,2534,2605,2614,2623]}) print(df_apple) print('销量最大值:', df_apple['apple'].max()) print('销量最小值:', df_apple['apple'].min()) print('销量平均值:', df_apple['apple'].mean()) df_apple.describe() df1 = df_apple.sort_values(by=['apple','year']) print(df1) # df1.to_csv('./data/apple_sort.csv')(三)Matplotlib
Matplotlib是Python中最常用的可视化程序包,可以非常方便的创建海量类型的2D图表和一些基本的3D图表。
Matplotlib API函数都位于matplotlib.pyplot模块中。
需要设置正常显示中文和负号。Matplotlib默认情况下不支持中文,如果不设置中文字体则图形中的中文标签将不能正常显示。







