

[写在开头] 深度学习小白,如果有不对的地方请大家多指正,对说的就是你大佬!
论文名称: PHYSCENE: Physically Interactable 3D Scene Synthesis for Embodied AI
论文链接: PHYSCENE: Physically Interactable 3D Scene Synthesis for Embodied AI

MOTIVATION
主流的3D场景生成工作注重场景的逼真性与自然性,但忽略了场景的物理合理性和可交互性
CONTRIBUTION
- 为3D场景生成设计了一系列符合物理规律和可交互性的引导函数(guidance function)
- 提出了一个基于条件扩散的3D场景生成模型 PHYSCENE,并且在传统的场景生成指标上超过了sota
PHYSCENE
主流的3D场景生成数据集存在一系列不符合物理规律的现象,如3D-FRONT

为了准确地建模物理合理性和交互性,论文提出了3种关键约束:
collision avoidance,object layouts,reachability
Collision avoidance
假设场景中有 N N N个物体,记 b i b_i bi为物体 O i O_i Oi的3D BBOX,使用 3D IoU 计算物体 O i O_i Oi与物体 O j O_j Oj之间的重合,取负值是为了惩罚重合
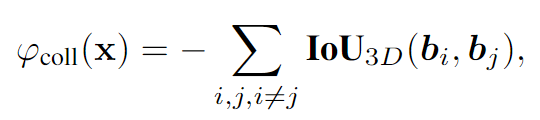
Object layouts
给定房间平面图 F F F,首先从平面图提取为一个多边形,作为场景的外围;在场景外围放置 W W W个无穷厚的障碍,得到一系列障碍物 BBOX { b w w a l l } w = 1 W \{b^{wall}_{w}\}^W_{w=1} {bwwall}w=1W
计算场景中的物体与外围障碍的 3D IoU,取负值是针对超出场景边界的物体进行惩罚
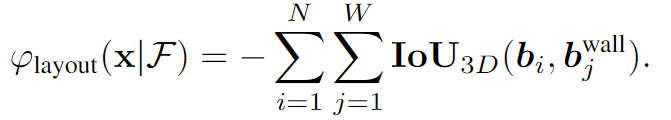
Reachability
给定房间平面图 F F F,记智能体的BBOX为 b a g e n t b^{agent} bagent;将3D场景俯视投影到2D平面,生成代价地图;以两个最大且相连的区域的中心为起点和终点,使用A*搜索算法搜索出最短路径;在这条最短路径上选择 L L L个智能体的位置 { b 1 a g n e t , . . . , b L a g e n t } \{b^{agnet}_1,...,b^{agent}_L\} {b1agnet,...,bLagent},
计算 L L L个智能体与场景中所有物体的 3D IoU,取负值是为了惩罚物体间距太窄、智能体无法通过
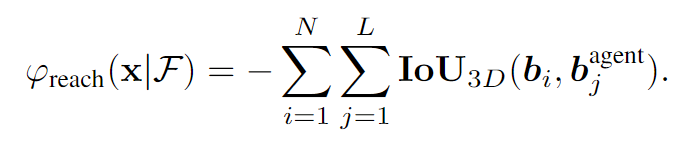
Conditional diffusion
扩散模型是一个“加噪+去噪”的过程
前向加噪:给定初始房间布局 X 0 X_0 X0,逐步添加高斯噪声 q ( X t + 1 ; X t ) q(X_{t+1};X_t) q(Xt+1;Xt), T T T时间步后得到近似高斯噪声 X T X_T XT
反向去噪:网络参数为 θ \theta θ,逐步去除噪声 p θ ( X t ; X t + 1 ) p_{\theta}(X_{t};X_{t+1}) pθ(Xt;Xt+1),最终重构得到 X 0 X_0 X0
因为加噪的时候添加的是高斯噪声,(Denoising Diffusion Probabilistic Models)假设去除的也是高斯噪声
使用 μ θ ( X t , t , F ) \mu_{\theta}(X_t,t,F) μθ(Xt,t,F)表示二维高斯分布均值, ∑ θ ( X t , t , F ) \sum _{\theta}(X_t,t,F) ∑θ(Xt,t,F)代表二维高斯分布方差,则
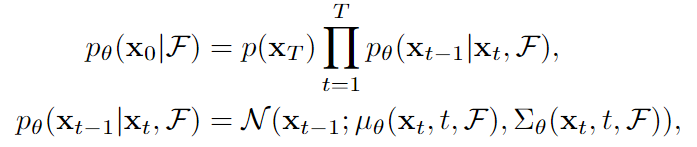
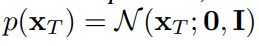
p θ ( X 0 ∣ F ) p_{\theta}(X_0|F) pθ(X0∣F)代表 X 0 X_0 X0的概率分布
p θ ( X t ∣ F ) = p ( X T ) ∏ k = t + 1 T p θ ( X k − 1 ∣ X k , F ) p_{\theta}(X_t|F)=p(X_T)\prod_{k=t+1}^{T}p_{\theta}(X_{k-1}|X_k,F) pθ(Xt∣F)=p(XT)∏k=t+1Tpθ(Xk−1∣Xk,F)代表 X t X_t Xt的概率分布
论文将逐步去噪的过程表述为概率优化问题,记 O O O服从伯努利分布,表示去噪得到的 X t X_t Xt是否服从约束函数,则
p ( X t ∣ F , O = 1 ) ∝ p θ ( X t ∣ F ) p ( O = 1 ∣ X t , F ) p(X_t|F,O=1)\propto p_{\theta}(X_t|F)p(O=1|X_t,F) p(Xt∣F,O=1)∝pθ(Xt∣F)p(O=1∣Xt,F)
用约束函数替换 O O O,则
p ( X t ∣ F , O = 1 ) ∝ p θ ( X t ∣ F ) exp ( ∑ φ i ( X t , F ) ) p(X_t|F,O=1)\propto p_{\theta}(X_t|F)\exp (\sum\varphi_i (X_t,F)) p(Xt∣F,O=1)∝pθ(Xt∣F)exp(∑φi(Xt,F))
log p ( O = 1 ∣ X t , F ) \log p(O=1|X_t,F) logp(O=1∣Xt,F)是关于 X t X_t Xt的函数,记 μ = μ θ ( X t , t , F ) \mu=\mu_{\theta}(X_t,t,F) μ=μθ(Xt,t,F)在 X t = μ X_t=\mu Xt=μ处作一阶泰勒展开,则
log p ( O = 1 ∣ X t , F ) ≈ C + ( X t − μ ) ∇ X t log p ( O = 1 ∣ X t , F ) ∣ X t = μ \log p(O=1|X_t,F)\approx C+(X_t-\mu)\nabla_{X_t}\log p(O=1|X_t,F)|_{X_t=\mu} logp(O=1∣Xt,F)≈C+(Xt−μ)∇Xtlogp(O=1∣Xt,F)∣Xt=μ
用约束函数替换 O O O,则
∇ X t log p ( O = 1 ∣ X t , F ) ∣ X t = μ = ∇ X t log ( exp ( ∑ φ i ( X t , F ) ) ) ∣ X t = μ = ∇ X t ∑ φ i ( X t , F ) ∣ X t = μ \nabla_{X_t}\log p(O=1|X_t,F)|_{X_t=\mu}=\nabla_{X_t}\log (\exp (\sum\varphi_i (X_t,F)))|_{X_t=\mu}=\nabla_{X_t}\sum\varphi_i (X_t,F)|_{X_t=\mu} ∇Xtlogp(O=1∣Xt,F)∣Xt=μ=∇Xtlog(exp(∑φi(Xt,F)))∣Xt=μ=∇Xt∑φi(Xt,F)∣Xt=μ
记 g = ∇ X t φ i ( X t , F ) ∣ X t = μ g=\nabla_{X_t}\varphi_i(X_t,F)|_{X_t=\mu} g=∇Xtφi(Xt,F)∣Xt=μ,则
log p ( O = 1 ∣ X t , F ) ≈ C + ( X t − μ ) ∑ g \log p(O=1|X_t,F)\approx C+(X_t-\mu)\sum g logp(O=1∣Xt,F)≈C+(Xt−μ)∑g
没加约束函数时,逐步去噪过程可以表述为如下高斯分布:
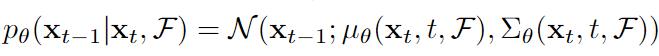
添加约束函数后,逐步去噪过程可以表述为如下高斯分布,与约束函数的梯度有关:
p θ ( X t − 1 ∣ X t , F , O = 1 ) = N ( X t − 1 ; μ + λ ∑ g , ∑ θ ( X t , t , F ) ) p_{\theta}(X_{t-1}|X_t,F,O=1)=N(X_{t-1};\mu+\lambda\sum g,\sum _{\theta}(X_t,t,F)) pθ(Xt−1∣Xt,F,O=1)=N(Xt−1;μ+λ∑g,θ∑(Xt,t,F))
Framework
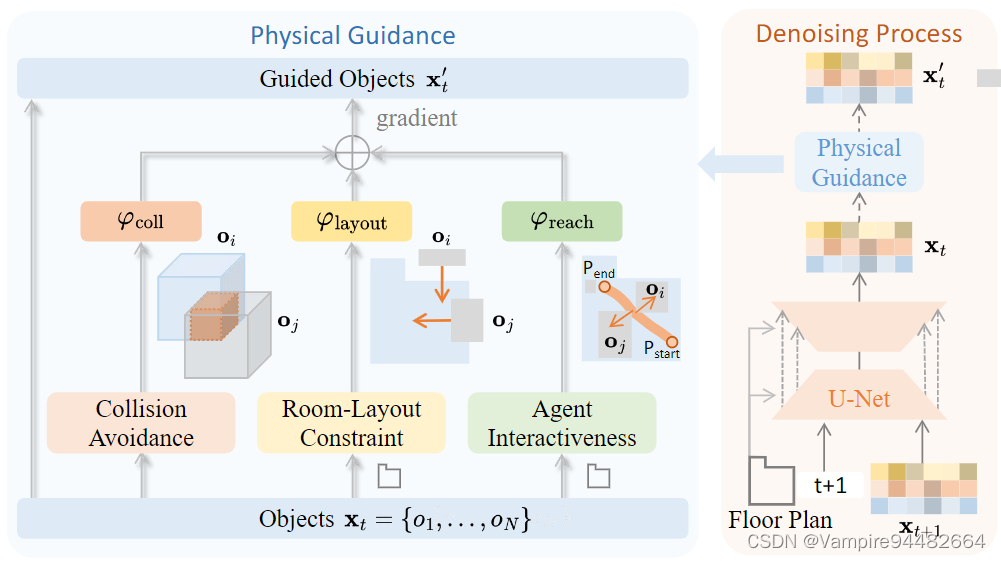
给定 t + 1 t+1 t+1时间步的图片 X t + 1 X_{t+1} Xt+1,使用带有注意力模块的U-Net建模去噪过程,得到 X t X_t Xt后计算约束函数的梯度,最终得到 X t ′ X_{t}' Xt′
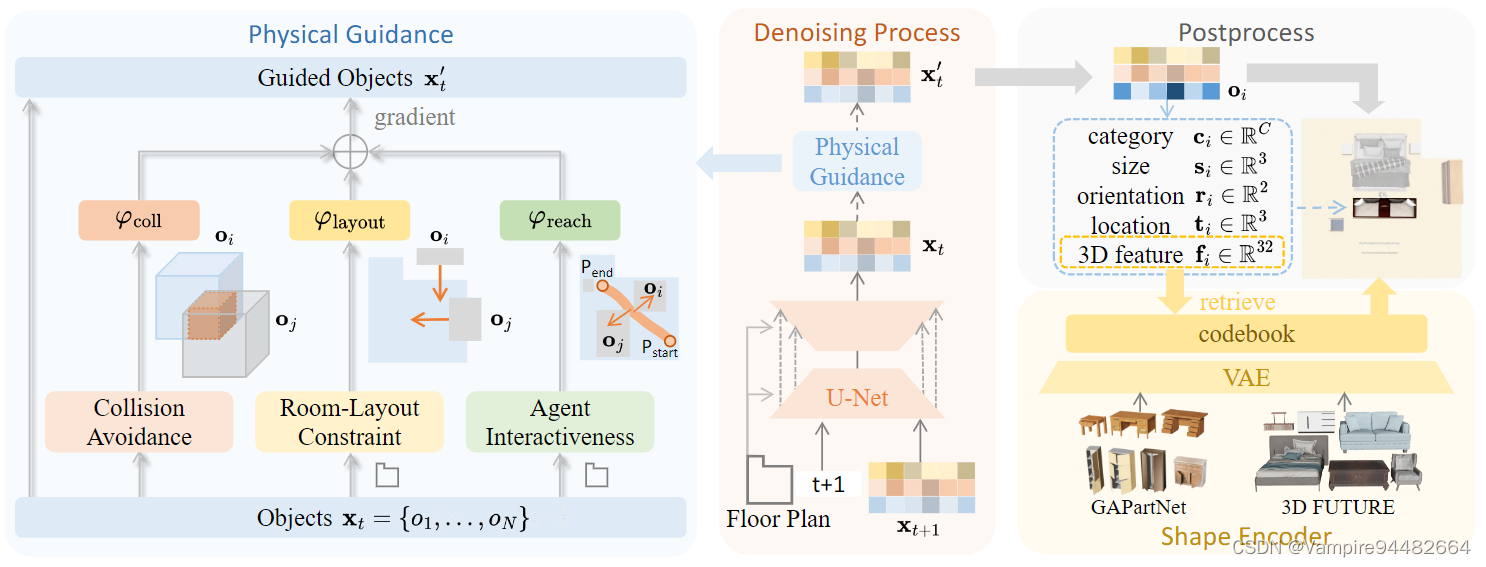
Articulated objects
为了增强场景的可交互性,作者将生成场景中的物体替换成可交互的物体。
可交互物体来源于3D-FUTURE和GAPartNet,里面包含物体的CAD模型等
场景中物体 O i Oi Oi的形状特征为 f i ∈ R 32 f_i\in R_{32} fi∈R32,使用形状特征在物体数据中检索,需要最匹配的物体进行替换

Experiment
论文进行了两组实验,一组是给定初始布局图 F F F(conditioned Scene Synthesis),另一组不给(Unconditioned Scene Synthesis)
实验数据集为3D-FRONT,比较模型为两个sota方法,ATISS和DiffuScene
Metric
Fréchet Inception Distance (FID)
Kernel Inception Distance (KID ×0.001)
Scene Classification Accuracy (SCA)
Category KL divergence (CKL ×0.01)
论文自己定义了一些指标
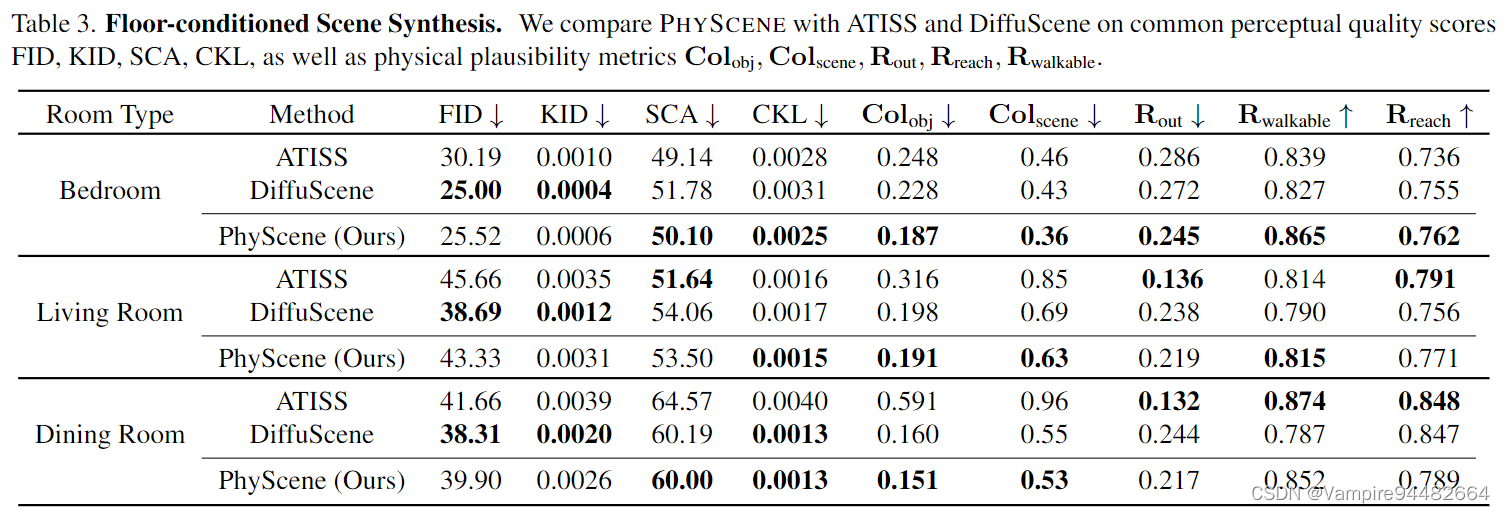
C o l o b j Col_{obj} Colobj,即生成的场景中,{存在重合的物体数量}/{所有物体数量},越低越好
C o l s c e n e Col_{scene} Colscene,即{存在物体重合的场景数量}/{所有场景数量},越低越好
R o u t R_{out} Rout,即生成场景中,{发生穿墙现象的物体数量}/{所有物体数量},越低越好
R r e a c h R_{reach} Rreach,即生成场景中,{智能体可交互的物体数量}/{所有物体数量},越高越好
R w a l k a b l e R_{walkable} Rwalkable,即生成场景中,{智能体可到达的区域面积}/{所有可行走的区域面积},越高越好
Unconditioned Scene Synthesis

Conditioned Scene Synthesis
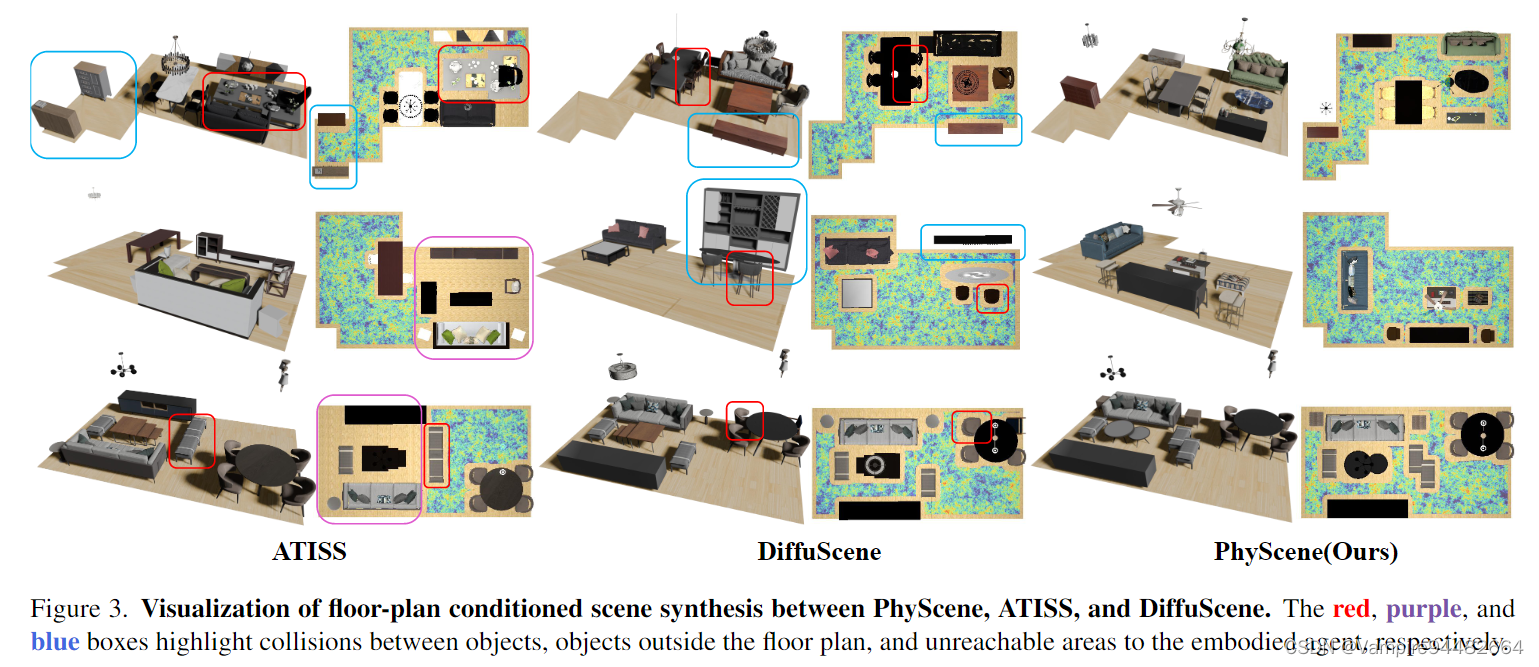
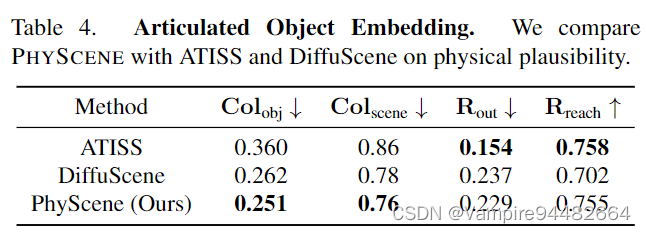
Ablation Study
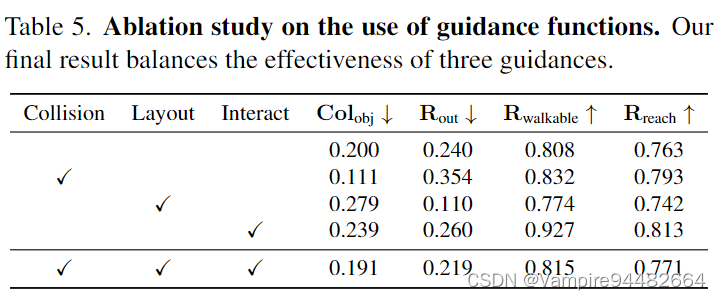
Articulated objects
在3D-FRONT数据集的living room setting
想法
- 论文在智能体可达性上提升没有太大
- 需要操作小物体的场景
以上就是这篇论文PHYSCENE: Physically Interactable 3D Scene Synthesis for Embodied AI的阅读笔记,大家可以去读一读。
创作不易,转载请注明出处。







