

网址:蓝桥杯直通国赛班(人工智能组)_蓝桥杯 - 蓝桥云课
pandas百题:Pandas 百题大冲关_机器学习 - 蓝桥云课
1、Scipy生态
Scipy 生态是指与Python科学计算库Scipy相关的一系列附加模块和工具。Scipy 是一个开源的Python库,提供了许多用于科学计算的功能,包括数值积分、优化、统计和线性代数等。Scipy 生态系统包括了许多与Scipy库配合使用的其他库和工具,例如NumPy、Matplotlib、Pandas等,这些库共同构成了Python科学计算领域的重要组成部分。通过这些工具的整合,用户可以方便地进行各种科学计算任务,从数据处理到模拟和可视化等。Scipy生态系统的不断发展和完善使得Python在科学计算领域的应用变得更加强大和丰富。
2、ndarray多维数组对象
NumPy(Numerical Python)是Python中用于科学计算的一个重要库,其中的核心数据结构是ndarray(N-dimensional array,多维数组)对象。ndarray对象是NumPy中最重要的数据结构之一,它表示具有相同类型和大小的元素的多维数组,可以进行高效的数值运算和数据处理。
以下是ndarray对象的一些重要特性和用法:
1. **多维数组**: ndarray可以是任意维数的数组,从一维数组到多维数组均可表示。
2. **数据类型**: ndarray中所有元素的数据类型必须是相同的,通常是数值类型(例如整数、浮点数)或者布尔类型。
3. **形状和尺寸**: ndarray具有shape属性,用于表示数组的维度,以及size属性,表示数组中元素的总个数。
4. **索引和切片**: 可以通过索引和切片访问ndarray对象中的元素,类似于Python中的列表操作。
5. **数学运算**: NumPy提供了丰富的数学函数和运算符,可以对ndarray对象进行各种数学运算,如加法、减法、乘法、除法等。
6. **广播功能**: NumPy的广播功能允许对不同形状的数组进行数学运算,使得代码更加简洁和高效。
7. **高效性能**: ndarray对象在内部实现上是连续内存块,因此能够实现高效的数值计算和向量化操作。
通过使用ndarray对象,NumPy使得Python在科学计算领域具有了与传统数值计算软件(如MATLAB、R等)相媲美的性能和功能,成为了科学计算和数据处理的首选工具之一。
3、%matplotlib inline
`%matplotlib inline`是一个IPython魔法命令,用于在Jupyter Notebook或者Jupyter Lab中内联显示Matplotlib绘制的图形。这个命令告诉Jupyter将Matplotlib图形嵌入到Notebook中的输出单元格中,而不是弹出一个新窗口显示图形。这样做使得图形能够直接在Notebook中展示,方便分析和可视化数据。
在使用`%matplotlib inline`之后,通过导入Pandas库并创建一个Series对象(类似于字典),你可以在Notebook中显示这个Series对象的内容。这样结合使用Pandas和Matplotlib,你可以方便地进行数据处理和可视化,从而更好地理解和分析数据。
4、s = pd.Series(np.random.randn(5))
这行代码创建了一个Pandas Series对象`s`,其中包含了5个由NumPy的`np.random.randn(5)`函数生成的随机数。具体解释如下:
- `np.random.randn(5)`: 这部分使用NumPy库中的`random.randn()`函数生成一个包含5个服从标准正态分布(均值为0,方差为1)的随机数的NumPy数组。
- `pd.Series()`: 这部分将NumPy数组转换为Pandas Series对象。Pandas Series是一种带有标签的一维数组结构,类似于Python中的字典,其中每个元素都有一个索引(标签)与之关联。
5、random随机
`rand` 是 `random` 模块中的一个函数,用于生成指定形状的均匀分布的随机数组。
`np.random.randn(5)` 中的 `randn` 是 NumPy 库中的一个函数,用于生成指定形状的服从标准正态分布(均值为0,标准差为1)的随机数。
具体来说,`np.random.randn(5)` 会生成一个包含5个随机数的一维数组,这些随机数都是从标准正态分布中随机抽样得到的。您可以通过传递不同的参数来生成不同形状和大小的随机数组。
如果您需要生成服从不同分布的随机数,NumPy 库中还提供了其他随机数生成函数,如 `np.random.rand()`(生成0到1之间的随机数)、`np.random.randint()`(生成指定范围内的随机整数)等。
6、enumerate()
(一期模拟第三题)
在Python中,`enumerate()` 函数用于同时获取数据的索引和值,通常在需要遍历列表或其他可迭代对象时使用。
下面是一个简单的示例,展示了如何使用 `enumerate()` 函数:
```python
# 示例列表
my_list = ['apple', 'banana', 'cherry', 'date']
# 使用 enumerate() 遍历列表并获取索引和值
for index, item in enumerate(my_list):
print(f"Index: {index}, Value: {item}")
```
在这个示例中:
- `enumerate(my_list)` 返回一个可迭代的对象,每次迭代会返回包含索引和值的元组。
- 在 `for` 循环中,`index` 变量用于存储当前迭代的索引,`item` 变量用于存储当前迭代的值。
所以,对于你提供的代码片段,`for index, item in enumerate(self.locs)` 将会遍历 `self.locs` 中的值,并且同时获取每个值的索引和值。在每次循环中,`index` 将存储当前值的索引,`item` 将存储当前值。
7、字典赋值
(一期模拟第三题)
在Python中,字典赋值是通过键来进行的。你可以使用键来访问字典中的值,并将新值赋给这个键。下面是一个示例:
```python
# 创建一个空字典
my_dict = {}
# 向字典中添加键值对
my_dict['key1'] = 'value1'
my_dict['key2'] = 'value2'
# 打印字典
print(my_dict)
# 修改现有键的值
my_dict['key1'] = 'new_value1'
# 打印修改后的字典
print(my_dict)
```
在这个示例中:
- 我们首先创建了一个空字典 `my_dict`。
- 使用 `my_dict['key'] = 'value'` 的语法向字典中添加键值对。
- 通过 `my_dict['key'] = 'new_value'` 的语法来修改字典中现有键的值。
通过这种方式,你可以向字典中添加新的键值对,也可以修改现有键的值。
8、中心裁剪原理
(一期模拟第一题)
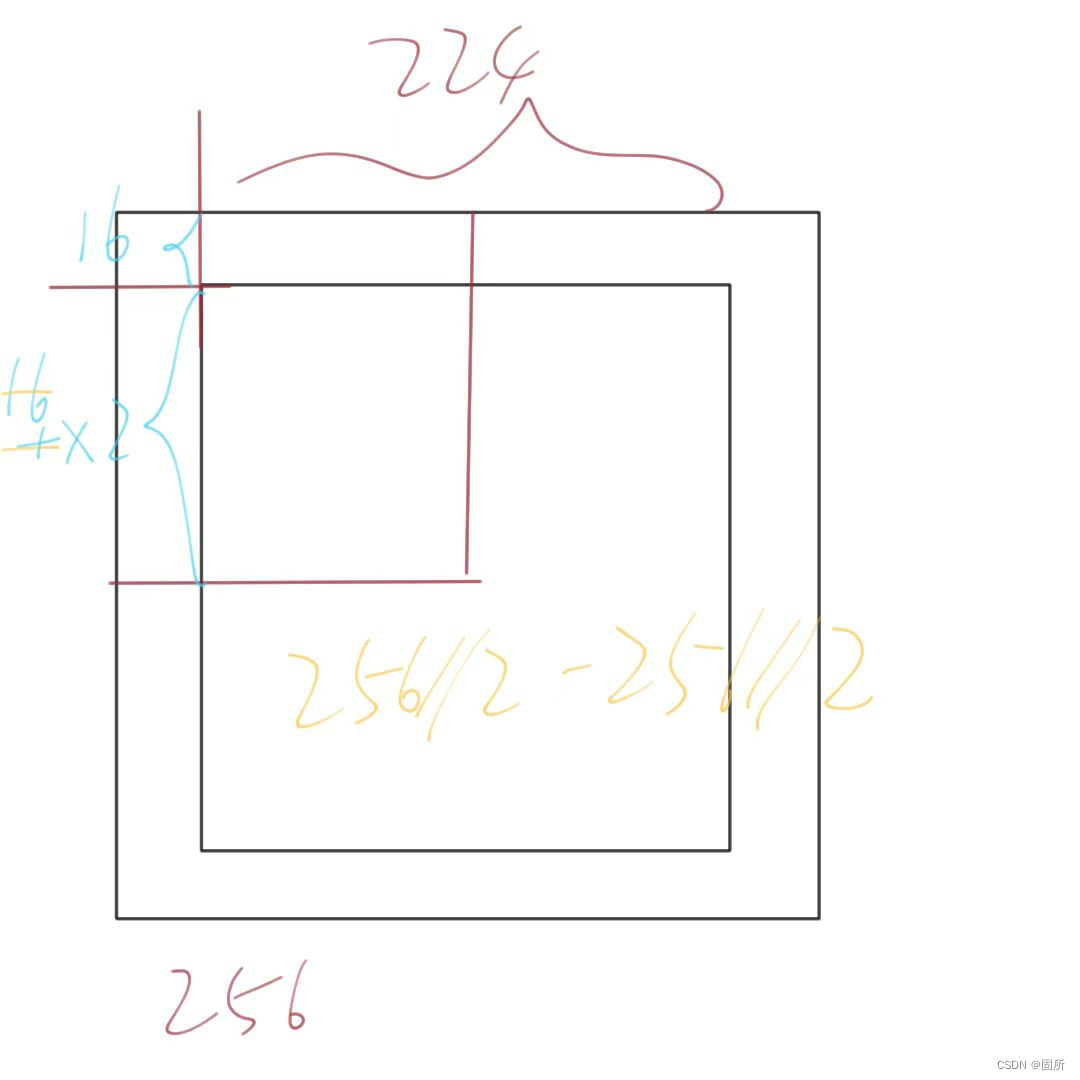
9、缺失值拟合(百题88)
这段代码涉及到了对一个DataFrame的操作,主要包括数据的创建、插值处理和数据类型转换。
1. 创建DataFrame:
- 首先,通过字典的形式创建了一个DataFrame `df`,包括四列:'From_To', 'FlightNumber', 'RecentDelays', 'Airline'。
- 'From_To'列包含了航班起始地点信息,'FlightNumber'列包含了航班号,'RecentDelays'列包含了延误时间信息,'Airline'列包含了航空公司信息。
2. 插值处理:
- 接下来,对'FlightNumber'列进行了插值处理。`df['FlightNumber'].interpolate()` 使用插值方法填充缺失值,这里采用的是默认的线性插值方法。
- 插值处理可以填充缺失值,以便后续数据分析或可视化中能够更好地处理数据。
3. 数据类型转换:
- 最后,对'FlightNumber'列进行了数据类型转换,通过`.astype(int)` 将'FlightNumber'列的数据类型转换为整数类型。
- 这一步骤确保'FlightNumber'列中的数值都是整数类型,便于后续的数据分析和处理。
综上所述,这段代码的作用是将给定的DataFrame `df` 中'FlightNumber'列的缺失值进行插值处理,并将结果转换为整数类型,以便后续分析。
插值是一种常用的数据处理方法,用于估计在已知数据点之间的未知数值。在数据分析中,插值通常用于填充缺失值或生成连续的数据。具体到这个例子中,`df['FlightNumber'].interpolate()` 使用了插值方法填充了'FlightNumber'列中的缺失值。
常见的插值方法包括线性插值、多项式插值、样条插值等。在这里,由于没有指定具体的插值方法,默认情况下使用的是线性插值方法。
**线性插值**工作原理如下:
- 对于两个已知点 (x1, y1) 和 (x2, y2),线性插值可以通过公式估计两点之间的未知点的值
在这里,'FlightNumber'列中含有缺失值,通过线性插值,Pandas会根据已知的数据点来估计缺失值。具体地,对于每一个缺失值,Pandas会使用其前后最近的已知值进行线性插值计算。
插值处理有助于保持数据的连续性和完整性,以便在后续的数据分析或可视化中更好地处理数据。通过填充缺失值,可以避免由于数据缺失导致的分析结果不准确或可视化效果不佳的问题。

10、pd.date_range()生成日期范围
`pd.date_range('today', periods=6)` 用于生成一个包含6个日期的时间序列。这个时间序列可以被用作DataFrame或Series的索引。
具体来说,`pd.date_range()` 函数是Pandas中用于生成日期范围的函数,通过指定起始日期、周期数等参数可以创建一个日期序列。在这里,`'today'` 表示从今天开始,`periods=6` 表示生成6个连续的日期。
下面是一个简单的例子,演示如何将生成的时间序列作为DataFrame的索引:
```python
import pandas as pd
# 生成包含6个日期的时间序列
dates = pd.date_range('today', periods=6)
# 创建一个DataFrame,并将时间序列作为索引
df = pd.DataFrame(data=np.random.randn(6, 3), index=dates, columns=['A', 'B', 'C'])
print(df)
```
在这个例子中,`dates` 生成了一个包含6个连续日期的时间序列,然后我们将这个时间序列作为DataFrame `df` 的索引,这样就能够在DataFrame中使用这些日期作为索引。
11、pd.DataFrame(num_arr, index=dates, columns=columns)
1. `pd.DataFrame(num_arr, index=dates, columns=columns)`:
- `pd.DataFrame()` 是 Pandas 库中用于创建 DataFrame 的构造函数。
- `num_arr` 是用来填充 DataFrame 的数据,这可能是一个二维数组、列表、Series 或其他数据结构。
- `index=dates` 指定了 DataFrame 的行索引,这里的 `dates` 可能是一个包含日期或时间戳的时间序列。
- `columns` 参数用来指定列标签,它可以是一个列表,包含了 DataFrame 中每一列的列名。
2. 解释:
- `num_arr` 是要填充到 DataFrame 中的数据,这个数据可能是一个二维数组。每一行代表 DataFrame 中的一行数据。
- `index=dates` 设置了 DataFrame 的行索引,这意味着 DataFrame 的每一行都将以 `dates` 中的日期或时间戳作为索引标签。
- `columns` 参数用来指定 DataFrame 的列标签,即每一列的名称。
- 最终,通过这行代码,您创建了一个新的 DataFrame `df1`,其中包含了以 `dates` 为索引、以 `columns` 为列标签,填充了 `num_arr` 数据的内容。
所以,这段代码的作用是使用给定的数据 `num_arr`,指定的日期索引 `dates` 和列标签 `columns` 创建一个新的 DataFrame `df1`。
12、数据预处理顺序
(第一期模拟第一题)
正确的顺序应该是:处理缺失值 -> 处理异常值 -> 删除重复行 -> 保存数据集。
为什么特定顺序重要的原因:
-
处理缺失值:通常,我们会用填充缺失值的方法(如均值、中位数或众数)来补全缺失的数据。这个步骤是为了保持数据的完整性和避免在后续分析中出现偏差。
-
处理异常值:异常值是指数据集中与大多数其他数据不同的值,可能是由于测量错误或数据录入错误。在处理异常值时,我们可能会选择删除这些值、对其进行转换或用其他值替换它们。这个步骤是为了确保分析结果的准确性和可靠性。
-
删除重复行:重复行可能会导致分析结果不准确,因为它们可能会影响统计数据的计算。删除重复行是为了确保数据集的一致性和避免重复计算。
为什么顺序重要:
-
删除重复行后处理异常值的话:如果在删除重复行之前处理异常值,那么异常值可能会被重复行的其他值所“掩盖”,因为重复行会在删除操作中被保留。
因为删除重复行的标准通常是基于所有列的值进行比较。如果一个异常值被一个或多个重复行的“正常”值所包围,那么在基于列值进行比较时,这个异常值可能就不会被识别为重复,从而保留在数据集中。这样,在后续的分析中,异常值对结果的影响就可能被忽视,导致分析结果不准确。
因此,在处理数据时,一般建议先删除重复行,再处理异常值。这样做可以确保每个数值都是独立的,异常值不会因为重复行而被“平均”或“掩盖”。处理完缺失值和异常值后,可以进行进一步的数据分析,比如描述性统计、相关性分析、回归分析等,从而得到更为准确和可靠的结果。
-
处理异常值后删除重复行:如果在删除重复行之后处理异常值,那么异常值不会影响重复行的检测,因为重复行已经被删除。这样,我们就可以确保异常值不会被保留在数据集中,同时也不会影响数据的完整性和一致性。
总之,正确的顺序是先处理缺失值,然后处理异常值,最后删除重复行。这样可以确保数据集在分析前是干净、准确和一致的。







