

账号风险评估
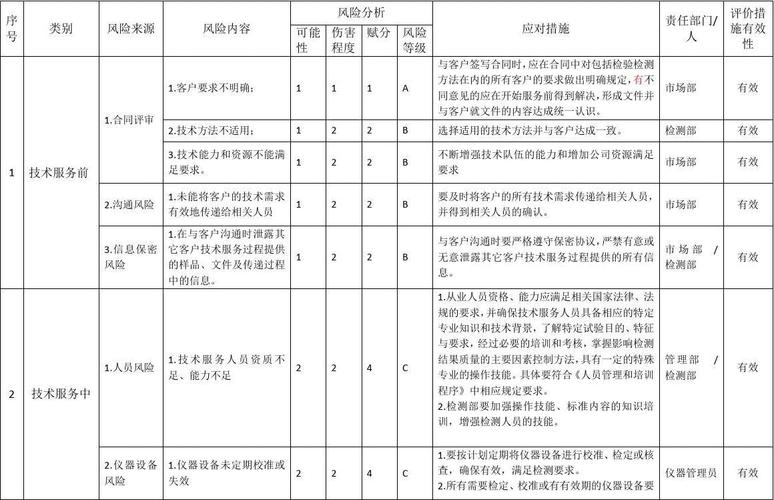
介绍
账号风险评估有助于提高用户在新媒体平台上的体验。通过筛选和过滤风险账号,可以减少用户接触到不良内容、垃圾信息或恶意攻击的可能性,提供一个更安全、健康和友好的平台环境。本任务将基于相关数据集构建一个简单的分类模型,识别风险账号。
(图片来源网络,侵删)
准备
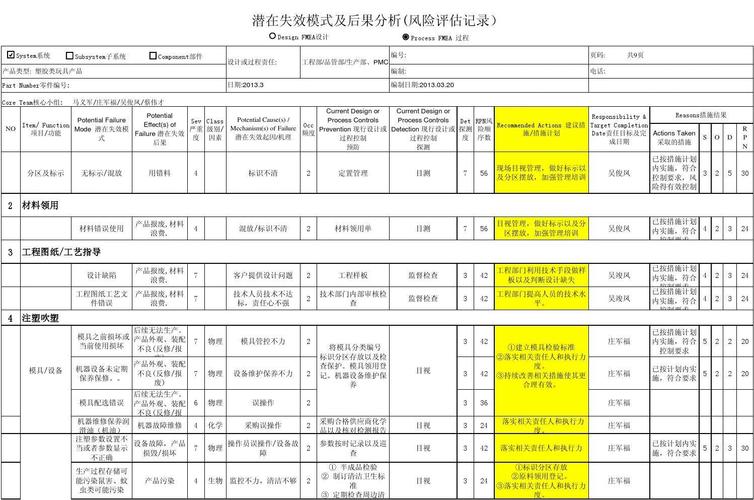
开始答题前,请确认 /home/project 目录下包含以下文件:
-
data_user.csv,是任务提供的数据集。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
task.py,是你后续答题过程中编写代码的地方。
目标
请在 task.py 文件中根据以下要求编写函数代码。
logistic_regression_model 函数
-
函数功能
-
参数
-
返回值
-
f1_sc:Float 类型,F1 得分。
基于以下代码补充 #TODO 处的函数代码,并执行 main() 函数,确保能够实现以下目标:
-
正确训练一个逻辑回归模型,并保存在 /home/project 目录下,命名为 lr_model.pkl。
-
逻辑回归模型在测试集上的 F1 得分不低于 0.85。
提示:点击代码块右上方的 copy 按钮,将代码完整复制到右侧环境中后开始编码。
import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.linear_model import LogisticRegression import pickle def load_data(file_path): data = pd.read_csv(file_path) y = data['target'] X = data.drop('target', axis=1) return X, y def preprocess_data(X_train, X_test): scale = StandardScaler() X_train = scale.fit_transform(X_train) X_test = scale.transform(X_test) return X_train, X_test def logistic_regression_model(X_train, y_train, X_test, y_test, dist): #TODO def main(): X, y = load_data('data_user.csv') X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) X_train, X_test = preprocess_data(X_train, X_test) f1 = logistic_regression_model(X_train, y_train, X_test, y_test,'./lr_model.pkl') print('%.2f'% f1) if __name__ == '__main__': main()规定
-
务必在 #TODO 所在的函数范围内编写代码,以免造成判题不通过。
-
切勿修改任务中默认提供的文件名称、函数名称等,以免造成判题不通过。
判分标准
-
实现目标,该题得 15 分
-
未实现目标,该题得 0 分。
代码:
def logistic_regression_model(X_train, y_train, X_test, y_test, dist): #TODO model = LogisticRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test) f1_sc = f1_score(y_test, y_pred) with open(dist, 'wb') as f: pickle.dump(model, f) return f1_sc
-
-
-
-







