

文章目录
- RBD接口
- 1.基础知识
- 1.1 基础知识
- 1.2 简单实践
- 1.3 小结
- 2.镜像管理
- 2.1 基础知识
- 2.2 简单实践
- 2.3 小结
- 3.镜像实践
- 3.1 基础知识
- 3.2 简单实践
- 3.3 小结
- 4.容量管理
- 4.1 基础知识
- 4.2 简单实践
- 4.3 小结
- 5.快照管理
- 5.1 基础知识
- 5.2 简单实践
- 5.3 小结
- 6.快照分层
- 6.1 基础知识
- 6.2 简单实践
- 6.3 小结
- 7.RBD实践
- 7.1 基础知识
- 7.2 简单实践
- 7.3 小结
RBD接口
1.基础知识
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
1.1 基础知识
简介
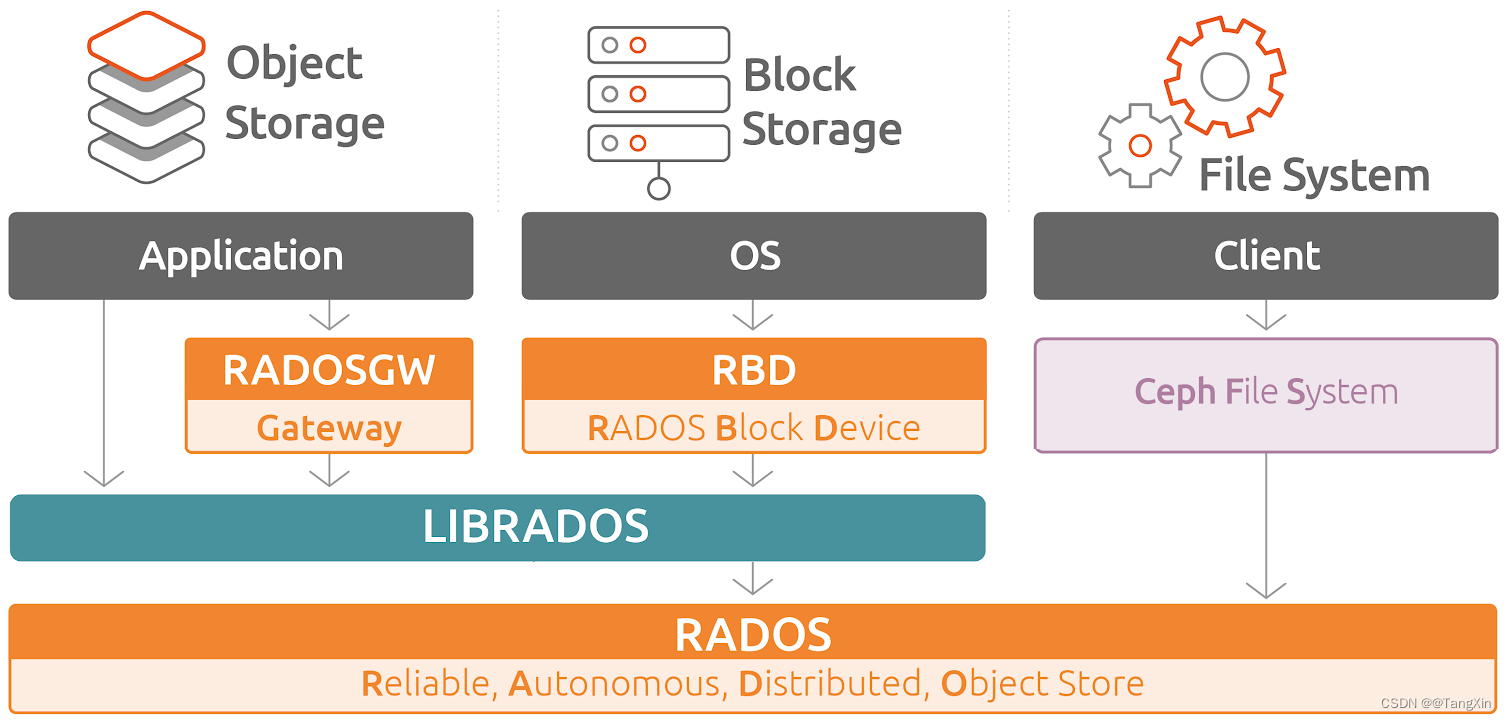
Ceph块设备,也称为RADOS块设备(简称RBD),是一种基于RADOS存储系统支持超配(thin-provisioned)、 可伸缩的条带化数据存储系统,它通过librbd库与OSD进行交互。 RBD为KVM等虚拟化技术和云OS(如OpenStack和CloudStack)提供高性能和无限可扩展性的存储后端, 这些系统依赖于libvirt和QEMU实用程序与RBD进行集成。
RBD
RBD,全称 RADOS Block Devices,是一种建构在 RADOS 存储集群之上为客户端提供块设备接口的存储服务中间层。 - 这类的客户端包括虚拟化程序KVM(结合qemu)和云的计算操作系统OpenStack和CloudStack等 RBD 基于 RADOS 存储集群中的多个 OSD 进行条带化,支持存储空间的简配(thinprovisioning) 和动态扩容等特性,并能够借助于 RADOS 集群实现快照、副本和一致性。同时,RBD 自身也是 RADOS 存储集群的客户端,它通过将存储池提供的存储服务抽象为一到多个 image(表现为块设备) 向客户端提供块级别的存储接口。 - RBD 支持两种格式的 image,不过 v1 格式因特性较少等原因已经处于废弃状态 - 当前默认使用的为 v2 格式
客户端访问 RBD 设备的方式有两种: - 通过内核模块 rbd.ko 将 image 映射为节点本地的块设备,相关的设备文件一般为 /dev/rdb#(#为设备编号,例如rdb0等) - 通过 librbd 提供的 API 接口,它支持 C/C++和Python 等编程语言, qemu 即是此类接口的客户端
操作逻辑
RBD 接口在 ceph 环境创建完毕后,就在服务端自动提供了; 客户端基于 librbd 库即可将 RADOS 存储集群用作块设备。 不过,RADOS 集群体用块设备需要经过一系列的 "额外操作" 才能够为客户端提供正常的存储功能。 这个过程步骤,主要有以下几步: - 1 创建一个专用的存储池: ceph osd pool create {pool-name} {pg-num} {pgp-num} - 2 对存储池启用 rbd 功能: ceph osd pool application enable {pool-name} rbd - 3 对存储池进行环境初始化: rbd pool init -p {pool-name} - 4 基于存储池创建专用的磁盘镜像: rbd create --size --pool其他命令: 存储池中的各 image 名称需要惟一,"rbd ls" 命令能够列出指定存储池中的 image rbd ls [-p ] [--format json|xml] [--pretty-format] 要获取指定 image 的详细信息,则通常使用 "rbd info" 命令 rbd info [--pool ] [--image ] [--format ] ...
1.2 简单实践
创建专用存储池
[cephadm@admin ceph-cluster]$ ceph osd pool create rbddata 64 pool 'rbddata' created 注意: 这里面的pg数量,我们定制为64个
对存储池启用rbd功能
启用存储池的rbd功能 [cephadm@admin ceph-cluster]$ ceph osd pool application enable rbddata rbd enabled application 'rbd' on pool 'rbddata' 注意: 如果关闭应用的话,使用disable 查看rbc的效果 [cephadm@admin ceph-cluster]$ ceph osd pool application get rbddata { "rbd": {} }对存储池进行环境初始化
环境初始化 [cephadm@admin ceph-cluster]$ rbd pool init -p rbddata 查看效果 [cephadm@admin ceph-cluster]$ rbd pool stats rbddata Total Images: 0 Total Snapshots: 0 Provisioned Size: 0 B
基于存储池创建专用的磁盘镜像
创建镜像 [cephadm@admin ceph-cluster]$ rbd create img1 --size 1024 --pool rbddata [cephadm@admin ceph-cluster]$ rbd ls -p rbddata img1 查看状态 [cephadm@admin ceph-cluster]$ rbd pool stats rbddata Total Images: 1 Total Snapshots: 0 Provisioned Size: 1 GiB
注意: 这个时候,我们创建出来的磁盘影响文件,就可以在客户端上,通过内核机制,直接导入到内核中,在内核中被当成一个磁盘设备来进行使用,样式就是 /dev/xxx,然后就可以针对这个rdb磁盘设备,进行各种后续分区、格式化等操作。
查看磁盘信息
查看方法1: [cephadm@admin ceph-cluster]$ rbd info rbddata/img1 rbd image 'img1': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58eae59a42b19 block_name_prefix: rbd_data.58eae59a42b19 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Fri Apr 19 13:54:44 2024 access_timestamp: Fri Apr 19 13:54:44 2024 modify_timestamp: Fri Apr 19 13:54:44 2024 [cephadm@admin ceph-cluster]$ rbd --image img1 --pool rbddata info rbd image 'img1': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58eae59a42b19 block_name_prefix: rbd_data.58eae59a42b19 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Fri Apr 19 13:54:44 2024 access_timestamp: Fri Apr 19 13:54:44 2024 modify_timestamp: Fri Apr 19 13:54:44 2024size : 就是这个块的大小,即1024MB=1G,1024MB/256 = 4M,共分成了256个对象(object),每个对象4M。 order 22: 有效范围为12-25。22是个幂编号,4M是22, 8M是23,也就是2^22 bytes = 4MB, 2^23 bytes = 8MB block_name_prefix : 这个是块的最重要的属性了,这是每个块在ceph中的唯一前缀编号,有了这个前缀,把主机上的OSD都拔下来带回家,就能复活所有的VM了 format : 格式有两种,1和2 features:当前image启用的功能特性,其值是一个以逗号分隔的字符串列表,例如 layering, exclusive-lock, object-map op_features:可选的功能特性;磁盘设备的删除
删除设备 [cephadm@admin ceph-cluster]$ rbd rm rbddata/img1 Removing image: 100% complete...done. 查看效果 [cephadm@admin ceph-cluster]$ rbd ls -p rbddata [cephadm@admin ceph-cluster]$ rbd pool stats rbddata Total Images: 0 Total Snapshots: 0 Provisioned Size: 0 B 删除存储池 [cephadm@admin ceph-cluster]$ ceph osd pool rm rbddata rbddata --yes-i-really-really-mean-it pool 'rbddata' removed
1.3 小结
2.镜像管理
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
2.1 基础知识
镜像属性
属性 解析 layering 分层克隆机制,磁盘的数据分层获取克隆机制 striping 是否支持数据对象间的数据条带化 exclusive-lock 排它锁的机制,磁盘应用于多路读写机制场景。限制同时仅能有一个客户端访问当前image object-map 对象位图机制,主要用于加速导入、导出及已用容量统计等操作,依赖于exclusive-lock特性 fast-diff 快照定制机制,快速对比数据差异,便于做快照管理,依赖于object-map特性 deep-flatten 数据处理机制,解除父子image及快照的依赖关系 journaling 磁盘日志机制,将image的所有修改操作进行日志化,便于异地备份,依赖于exclusive-lock特性 data-pool 是否支持将image的数据对象存储于纠删码存储池,主要用于将image的元数据与数据放置于不同的存储池; 属性操作
镜像功能命令 [cephadm@admin ceph-cluster]$ rbd --help | grep feature feature disable Disable the specified image feature. feature enable Enable the specified image feature.2.2 简单实践
准备工作
创建存储池 [cephadm@admin ceph-cluster]$ ceph osd pool create kube 64 64 pool 'kube' created [cephadm@admin ceph-cluster]$ ceph osd pool ls kube 启动rbd功能 [cephadm@admin ceph-cluster]$ ceph osd pool application enable kube rbd enabled application 'rbd' on pool 'kube' rbd环境初始化 [cephadm@admin ceph-cluster]$ rbd pool init kube
创建镜像
方法2:通过参数属性方式,创建一个2G的镜像文件 [cephadm@admin ceph-cluster]$ rbd create --pool kube --size 2G --image vol01 查看镜像 [cephadm@admin ceph-cluster]$ rbd ls --pool kube vol01
方法2:通过方式,创建一个2G的镜像文件 [cephadm@admin ceph-cluster]$ rbd create --size 2G kube/vol02 查看镜像 [cephadm@admin ceph-cluster]$ rbd ls --pool kube vol01 vol02
查看详情信息 -l [cephadm@admin ceph-cluster]$ rbd ls --pool kube -l NAME SIZE PARENT FMT PROT LOCK vol01 2 GiB 2 vol02 2 GiB 2 以json格式查看详情 --format json --pretty-format [cephadm@admin ceph-cluster]$ rbd ls --pool kube -l --format json --pretty-format [ { "image": "vol01", "size": 2147483648, "format": 2 }, { "image": "vol02", "size": 2147483648, "format": 2 } ]查看镜像属性 [cephadm@admin ceph-cluster]$ rbd info kube/vol01 rbd image 'vol01': size 2 GiB in 512 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58f0d7dd2ab32 block_name_prefix: rbd_data.58f0d7dd2ab32 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Fri Apr 19 14:05:53 2024 access_timestamp: Fri Apr 19 14:05:53 2024 modify_timestamp: Fri Apr 19 14:05:53 2024镜像属性
禁用磁盘镜像功能 [cephadm@admin ceph-cluster]$ rbd feature disable kube/vol01 object-map fast-diff deep-flatten [cephadm@admin ceph-cluster]$ rbd info --pool kube --image vol01 rbd image 'vol01': size 2 GiB in 512 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58f0d7dd2ab32 block_name_prefix: rbd_data.58f0d7dd2ab32 format: 2 features: layering, exclusive-lock # 关注此字段 op_features: flags: create_timestamp: Fri Apr 19 14:05:53 2024 access_timestamp: Fri Apr 19 14:05:53 2024 modify_timestamp: Fri Apr 19 14:05:53 2024启用磁盘镜像功能 [cephadm@admin ceph-cluster]$ rbd feature enable kube/vol01 object-map fast-diff [cephadm@admin ceph-cluster]$ rbd info --pool kube --image vol01 rbd image 'vol01': size 2 GiB in 512 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58f0d7dd2ab32 block_name_prefix: rbd_data.58f0d7dd2ab32 format: 2 features: layering, exclusive-lock, object-map, fast-diff op_features: flags: object map invalid, fast diff invalid # 关注此字段 create_timestamp: Fri Apr 19 14:05:53 2024 access_timestamp: Fri Apr 19 14:05:53 2024 modify_timestamp: Fri Apr 19 14:05:53 20242.3 小结
3.镜像实践
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
3.1 基础知识
磁盘使用
使用方法1:通过内核级别的ceph模块,将rdb设备提供给相关主机使用 初始化存储池后,创建image 最好禁用 object-map,fast-diff,deep-flatten功能 需要直接与monitor角色进行通信 - 若存储集群端启用了CephX认证,还需要指定用户名和keyring文件 使用rdb命令的map子命令,进行磁盘文件的映射 注意: 在客户端上可以通过 rbd showmapped 查看已经映射的image 在客户端上可以通过 rbd unmap 命令断开已经映射的image
admin主机管理image镜像文件的权限
禁用无效的属性 [cephadm@admin ceph-cluster]$ rbd feature disable kube/vol01 object-map fast-diff [cephadm@admin ceph-cluster]$ rbd info --pool kube --image vol01 rbd image 'vol01': size 2 GiB in 512 objects order 22 (4 MiB objects) snapshot_count: 0 id: 58f0d7dd2ab32 block_name_prefix: rbd_data.58f0d7dd2ab32 format: 2 features: layering, exclusive-lock # 观察此字段的变化 op_features: flags: create_timestamp: Fri Apr 19 14:05:53 2024 access_timestamp: Fri Apr 19 14:05:53 2024 modify_timestamp: Fri Apr 19 14:05:53 2024映射命令的帮助
[cephadm@admin ceph-cluster]$ rbd help map usage: rbd map [--device-type ] [--pool ] [--namespace ] [--image ] [--snap ] [--read-only] [--exclusive] [--options ] Map an image to a block device. Positional arguments image or snapshot specification (example: [/[/]][@ ]) Optional arguments -t [ --device-type ] arg device type [ggate, krbd (default), nbd] -p [ --pool ] arg pool name --namespace arg namespace name --image arg image name --snap arg snapshot name --read-only map read-only --exclusive disable automatic exclusive lock transitions -o [ --options ] arg device specific options3.2 简单实践
客户端主机安装基本环境,在stor26节点执行
客户端主机安装环境 [root@stor26 ~]# yum install ceph ceph-common -y
查看模块效果 [root@stor26 ~]# modinfo ceph filename: /lib/modules/3.10.0-693.el7.x86_64/kernel/fs/ceph/ceph.ko.xz license: GPL description: Ceph filesystem for Linux author: Patience Warnick author: Yehuda Sadeh author: Sage Weil alias: fs-ceph rhelversion: 7.4 srcversion: B4988BF5091B60FCF15B003 depends: libceph intree: Y vermagic: 3.10.0-693.el7.x86_64 SMP mod_unload modversions signer: CentOS Linux kernel signing key sig_key: DA:18:7D:CA:7D:BE:53:AB:05:BD:13:BD:0C:4E:21:F4:22:B6:A4:9C sig_hashalgo: sha256
管理端主机传递相关文件
查看认证信息 [cephadm@admin ceph-cluster]$ ceph auth get client.kube [client.kube] key = AQC3lhxmGSQyEBAAbYyBL8PE6N753KsxU5Bp+g== caps mon = "allow r" caps osd = "allow * pool=kube" exported keyring for client.kube [cephadm@admin ceph-cluster]$ ls *kube* ceph.client.kube.keyring 传递认证文件 [cephadm@admin ceph-cluster]$ sudo scp ceph.client.kube.keyring root@stor26:/etc/ceph/ ceph.client.kube.keyring 100% 116 7.5KB/s 00:00传递正常的ceph集群的配置文件 [cephadm@admin ceph-cluster]$ sudo scp ceph.conf root@stor26:/etc/ceph/ ceph.conf 100% 343 3.7KB/s 00:00
客户端简单使用
默认情况下,是无法正常连接ceph集群的 [root@stor26 ~]# ceph -s 2024-04-19 14:24:34.411 7f87f2632700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory ...... [errno 2] error connecting to the cluster 结果显示: 默认采用的认证用户是 client.admin账号,而我们没有。 通过--user参数,使用指定的用户来访问ceph [root@stor26 ~]# ceph --user kube -s cluster: id: 76cc0714-0bd7-43f7-b7c3-ec8cae2819e7 health: HEALTH_OK services: mon: 3 daemons, quorum mon01,mon02,mon03 (age 38m) mgr: mon01(active, since 4h), standbys: mon02 osd: 6 osds: 6 up (since 4h), 6 in (since 9d) data: pools: 1 pools, 64 pgs objects: 7 objects, 215 B usage: 6.1 GiB used, 114 GiB / 120 GiB avail pgs: 64 active+cleanrdb文件的使用
查看当前的系统磁盘效果 [root@stor26 ~]# fdisk -l | grep 'Disk /dev/sd*' Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
映射远程ceph的磁盘文件到本地 [root@stor26 ~]# rbd --user kube map kube/vol01 /dev/rbd0 查看效果 [root@stor26 ~]# fdisk -l | grep 'Disk /dev/rbd*' Disk /dev/rbd0: 2147 MB, 2147483648 bytes, 4194304 sectors
格式化磁盘 [root@stor26 ~]# mkfs.ext4 /dev/rbd0 mke2fs 1.42.9 (28-Dec-2013) Discarding device blocks: done Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=1024 blocks, Stripe width=1024 blocks 131072 inodes, 524288 blocks 26214 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=536870912 16 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done 写入超级块和文件系统账户统计信息: 已完成
挂载操作 [root@stor26 ~]# mount /dev/rbd0 /mnt [root@stor26 ~]# mount | grep rbd /dev/rbd0 on /mnt type ext4 (rw,relatime,seclabel,stripe=1024,data=ordered) 尝试使用磁盘文件 [root@stor26 ~]# cp /etc/issue /mnt/ [root@stor26 ~]# cat /mnt/issue \S Kernel \r on an \m
卸载操作 [root@stor26 ~]# umount /mnt/
我们还可以在客户端上,使用 rbd命令对rbd设备进行管理
客户端挂载操作 [root@stor26 ~]# mount /dev/rbd0 /mnt/ 确认效果 [root@stor26 ~]# rbd showmapped id pool namespace image snap device 0 kube vol01 - /dev/rbd0
主服务器上,查看挂载效果 [cephadm@admin ceph-cluster]$ rbd ls --pool kube -l NAME SIZE PARENT FMT PROT LOCK vol01 2 GiB 2 excl vol02 2 GiB 2
磁盘卸载操作
卸载操作 [root@stor26 ~]# rbd unmap /dev/rbd0 rbd: sysfs write failed rbd: unmap failed: (16) Device or resource busy 卸载磁盘 [root@stor26 ~]# umount /mnt [root@stor26 ~]# rbd unmap /dev/rbd0 查看挂载效果 [root@stor26 ~]# rbd showmapped 主节点查看挂载效果 [cephadm@admin ceph-cluster]$ rbd ls --pool kube -l NAME SIZE PARENT FMT PROT LOCK vol01 2 GiB 2 vol02 2 GiB 2
3.3 小结
4.容量管理
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
4.1 基础知识
容量
如果有必要的话,我们可以针对镜像文件的大小进行容量的调整。 [cephadm@admin ceph-cluster]$ rbd help resize usage: rbd resize [--pool ] [--namespace ] [--image ] --size [--allow-shrink] [--no-progress] Resize (expand or shrink) image. Positional arguments image specification (example: [/[/]]) Optional arguments -p [ --pool ] arg pool name --namespace arg namespace name --image arg image name -s [ --size ] arg image size (in M/G/T) [default: M] --allow-shrink permit shrinking --no-progress disable progress output调整image的大小
增大: rbd resize [--pool ] [--image ] --size 减少: rbd resize [--pool ] [--image ] --size [--allow-shrink]
删除image
命令格式 rbd remove [--pool ] [--image ] ... 注意: 删除image会导致数据丢失,且不可恢复;
如果删除一些敏感的image,为了保险,推荐使用回收站功能trash,确定不再需要时再从trash中删除; 命令格式: rbd trash {list|move|purge|remove|restore}4.2 简单实践
image的容量扩展
查看当前的image容量 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l NAME SIZE PARENT FMT PROT LOCK vol01 2 GiB 2 vol02 2 GiB 2 调整image容量 [cephadm@admin ceph-cluster]$ rbd resize -s 5G kube/vol01 Resizing image: 100% complete...done. 再次确认image容量大小 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l NAME SIZE PARENT FMT PROT LOCK vol01 5 GiB 2 vol02 2 GiB 2
image容量的缩小
调整image容量 [cephadm@admin ceph-cluster]$ rbd resize -s 3G kube/vol01 --allow-shrink Resizing image: 100% complete...done. 再次确认image容量大小 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l NAME SIZE PARENT FMT PROT LOCK vol01 3 GiB 2 vol02 2 GiB 2
删除image文件
删除image文件 [cephadm@admin ceph-cluster]$ rbd rm kube/vol02 Removing image: 100% complete...done. 查看image文件效果 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l NAME SIZE PARENT FMT PROT LOCK vol01 3 GiB 2 注意: image文件的删除是不可修复的
image文件恢复
查看trash命令帮助 [cephadm@admin ceph-cluster]$ rbd trash --help | grep trash trash list (trash ls) List trash images. trash move (trash mv) Move an image to the trash. trash purge Remove all expired images from trash. trash remove (trash rm) Remove an image from trash. trash restore Restore an image from trash.简介
查看回收站 [cephadm@admin ceph-cluster]$ rbd trash ls -p kube 移动文件到回收站 [cephadm@admin ceph-cluster]$ rbd trash move kube/vol01 查看回收站 [cephadm@admin ceph-cluster]$ rbd trash ls -p kube 58f0d7dd2ab32 vol01 查看文件 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l
恢复image文件 [cephadm@admin ceph-cluster]$ rbd trash restore -p kube --image vol01 --image-id 58f0d7dd2ab32 查看回收站 [cephadm@admin ceph-cluster]$ rbd trash ls -p kube 查看image文件 [cephadm@admin ceph-cluster]$ rbd ls -p kube -l NAME SIZE PARENT FMT PROT LOCK vol01 3 GiB 2
4.3 小结
5.快照管理
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
5.1 基础知识
快照
RBD支持image快照技术,借助于快照可以保留image的状态历史。 Ceph还支持快照“分层”机制,从而可实现快速克隆VM映像。
常见命令
创建快照 rbd snap create [--pool ] --image --snap 或者 rbd snap create [/]@ 注意: 在创建映像快照之前应停止image上的IO操作,且image上存在文件系统时,还要确保其处于一致状态;
列出快照 rbd snap ls [--pool ] --image ...
回滚快照 rbd snap rollback [--pool ] --image --snap ... 注意: 意味着会使用快照中的数据重写当前版本的image,回滚所需的时间将随映像大小的增加而延长
限制快照数量 快照数量过多,必然会导致image上的原有数据第一次修改时的IO压力恶化 rbd snap limit set [--pool ] [--image ] ... 解除限制 rbd snap limit clear [--pool ] [--image ]
删除快照 rbd snap rm [--pool ] [--image ] [--snap ] [--no-progress] [--force] 提示: Ceph OSD会以异步方式删除数据,因此删除快照并不能立即释放磁盘空间;
清理快照 删除一个image的所有快照,可以使用rbd snap purge命令 rbd snap purge [--pool ] --image [--no-progress]
5.2 简单实践
查看快照命令
[cephadm@admin ceph-cluster]$ rbd --help | grep ' snap ' snap create (snap add) Create a snapshot. snap limit clear Remove snapshot limit. snap limit set Limit the number of snapshots. snap list (snap ls) Dump list of image snapshots. snap protect Prevent a snapshot from being deleted. snap purge Delete all unprotected snapshots. snap remove (snap rm) Delete a snapshot. snap rename Rename a snapshot. snap rollback (snap revert) Rollback image to snapshot. snap unprotect Allow a snapshot to be deleted.客户端准备rbd文件
客户端挂载rbd文件 [root@stor26 ~]# rbd --user kube map kube/vol01 /dev/rbd0 查看效果 [root@stor26 ~]# rbd showmapped id pool namespace image snap device 0 kube vol01 - /dev/rbd0 挂载操作 [root@stor26 ~]# mount /dev/rbd0 /mnt [root@stor26 ~]# ls /mnt/ issue lost+found 结果显示: 虽然容量调整过了,但是就有的文件仍然存在
管理端创建快照
查看快照 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01 创建快照 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap01 查看快照 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01 SNAPID NAME SIZE PROTECTED TIMESTAMP 4 snap01 3 GiB Fri Apr 19 14:55:27 2024恢复快照动作
客户端将文件删除 [root@stor26 ~]# ls /mnt/ issue lost+found [root@stor26 ~]# rm -f /mnt/issue [root@stor26 ~]# ls /mnt/ lost+found 客户端解除磁盘的占用 [root@stor26 ~]# umount /mnt/ [root@stor26 ~]# rbd unmap /dev/rbd0 [root@stor26 ~]# rbd showmapped
服务端恢复快照 [cephadm@admin ceph-cluster]$ rbd snap rollback kube/vol01@snap01 Rolling back to snapshot: 100% complete...done. 客户端重新加载磁盘文件 [root@stor26 ~]# rbd --user kube map kube/vol01 /dev/rbd0 [root@stor26 ~]# mount /dev/rbd0 /mnt [root@stor26 ~]# ls /mnt/ issue lost+found 结果显示: 快照数据恢复过来了
删除快照
删除之前查看效果 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01 SNAPID NAME SIZE PROTECTED TIMESTAMP 4 snap01 3 GiB Fri Apr 19 14:55:27 2024 删除快照 [cephadm@admin ceph-cluster]$ rbd snap rm kube/vol01@snap01 Removing snap: 100% complete...done. 确认删除效果 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01快照数量的限制
设定快照数量的限制 [cephadm@admin ceph-cluster]$ rbd snap limit set --pool kube --image vol01 --limit 5 确认效果 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap01 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap02 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap03 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap04 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap05 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap06 rbd: failed to create snapshot: (122) Disk quota exceeded 解除快照限制 [cephadm@admin ceph-cluster]$ rbd snap limit clear --pool kube --image vol01 确认效果 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@snap06 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01 SNAPID NAME SIZE PROTECTED TIMESTAMP 6 snap01 3 GiB Fri Apr 19 15:01:11 2024 7 snap02 3 GiB Fri Apr 19 15:01:32 2024 8 snap03 3 GiB Fri Apr 19 15:01:34 2024 9 snap04 3 GiB Fri Apr 19 15:01:36 2024 10 snap05 3 GiB Fri Apr 19 15:01:38 2024 13 snap06 3 GiB Fri Apr 19 15:02:31 2024清理所有快照
清理所有快照 [cephadm@admin ceph-cluster]$ rbd snap purge --pool kube --image vol01 Removing all snapshots: 100% complete...done. 确认效果 [cephadm@admin ceph-cluster]$ rbd snap list kube/vol01
5.3 小结
6.快照分层
学习目标:这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
6.1 基础知识
简介
Ceph支持在一个块设备快照的基础上创建一到多个COW或COR(Copy-On-Read)类型的克隆, 这种中间快照层机制提了一种极速创建image的方式。 用户可以创建一个基础image并为其创建一个只读快照层, 而后可以在此快照层上创建任意个克隆进行读写操作,甚至能够进行多级克隆。 例如: 实践中可以为Qemu虚拟机创建一个image并安装好基础操作系统环境作为模板, 对其创建创建快照层后,便可按需创建任意多个克隆作为image提供给多个不同的VM(虚拟机)使用, 或者每创建一个克隆后进行按需修改,而后对其再次创建下游的克隆.
通过克隆生成的image在其功能上与直接创建的image几乎完全相同, 它同样支持读、写、克隆、空间扩缩容等功能,惟一的不同之处是克隆引用了一个只读的上游快照, 而且此快照必须要置于“保护”模式之下。
Ceph的快照支持COW和COR两种类型: COW是为默认的类型,仅在数据首次写入时才需要将它复制到克隆的image中 COR则是在数据首次被读取时复制到当前克隆中,随后的读写操作都将直接基于此克隆中的对象进行
分层快照使用
在RBD上使用分层克隆的方法非常简单: 创建一个image,对image创建一个快照并将其置入保护模式,而克隆此快照即可 创建克隆的image时, 需要指定引用的存储池、镜像和镜像快照,以及克隆的目标image的存储池和镜像名称, 因此,克隆镜像支持跨存储池进行
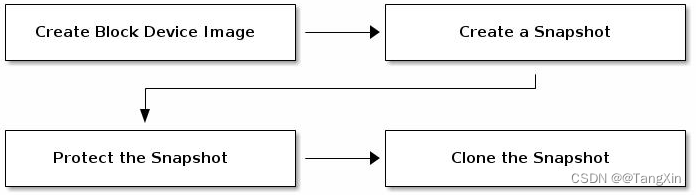
简单来说,这里的快照分层,主要说的就是: 基础的模板快照和特有应用快照
命令实践
保护上游的原始快照: 下游image需要引用上游快照中的数据,快照的意外删除必将导致数据服务的中止, 因此在克隆操作之外,必须将上游的快照置于保护模式 rbd snap protect [--pool ] --image --snap
克隆快照 rbd clone [--pool ] --image --snap --dest-pool rbd clone [/]@ [/]
列出快照的子项 rbd children [--pool ] --image --snap
展平克隆的image: 克隆的映像会保留对父快照的引用,删除子克隆对父快照的引用时,可通过将信息从快照复制到克隆,进行image的“展平”操作: 展平克隆所需的时间随着映像大小的增加而延长 要删除某拥有克隆子项的快照,必须先平展其子image 命令: rbd flatten [--pool ] --image --no-progress
取消快照保护: 必须先取消保护快照,然后才能删除它 用户无法删除克隆所引用的快照,需要先平展其每个克隆,然后才能删除快照 命令:rbd snap unprotect [--pool ] --image --snap
6.2 简单实践
清理环境
在客户端将磁盘取消应用 [root@stor26 ~]# umount /mnt [root@stor26 ~]# rbd unmap /dev/rbd0 [root@stor26 ~]# rbd showmapped
服务端定制基础快照
定制基础快照 [cephadm@admin ceph-cluster]$ rbd snap create kube/vol01@clonetpl01 [cephadm@admin ceph-cluster]$ rbd snap ls kube/vol01 SNAPID NAME SIZE PROTECTED TIMESTAMP 20 clonetpl01 3 GiB Fri Apr 19 15:10:32 2024将快照置于保护模式 [cephadm@admin ceph-cluster]$ rbd snap protect kube/vol01@clonetpl01 [cephadm@admin ceph-cluster]$ rbd snap ls kube/vol01 SNAPID NAME SIZE PROTECTED TIMESTAMP 20 clonetpl01 3 GiB yes Fri Apr 19 15:10:32 2024 结果显示: 该快照已经被处于保护模式了基于快照来进行克隆操作
基于基础模板克隆一个镜像 [cephadm@admin ceph-cluster]$ rbd clone kube/vol01@clonetpl01 kube/myimg01 [cephadm@admin ceph-cluster]$ rbd clone kube/vol01@clonetpl01 kube/myimg02 查看效果 [cephadm@admin ceph-cluster]$ rbd ls -p kube myimg01 myimg02 vol01 查看模板镜像的所有子镜像文件 [cephadm@admin ceph-cluster]$ rbd children kube/vol01@clonetpl01 kube/myimg01 kube/myimg02
客户端尝试应用一下clone文件 [root@stor26 ~]# rbd --user kube map kube/vol01 /dev/rbd0 查看效果 [root@stor26 ~]# rbd showmapped id pool namespace image snap device 0 kube vol01 - /dev/rbd0 挂载操作 [root@stor26 ~]# mount /dev/rbd0 /mnt/ [root@stor26 ~]# ls /mnt/ issue lost+found [root@stor26 ~]# echo myimg1 >> /mnt/issue 结果显示: 该clone镜像文件可以正常的使用
客户端再次应用clone文件 [root@stor26 ~]# rbd --user kube map kube/myimg02 /dev/rbd1 查看效果 [root@stor26 ~]# rbd showmapped id pool namespace image snap device 0 kube vol01 - /dev/rbd0 1 kube myimg02 - /dev/rbd1 挂载操作 [root@stor26 ~]# mkdir /mnt1 [root@stor26 ~]# mount /dev/rbd1 /mnt1 [root@stor26 ~]# cat /mnt1/issue \S Kernel \r on an \m 结果显示: 多个clone镜像文件可以独立的正常使用
卸载操作
客户端卸载myimg02 [root@stor26 ~]# umount /mnt1 [root@stor26 ~]# rbd unmap kube/myimg02 管理端删除image镜像 [cephadm@admin ceph-cluster]$ rbd rm kube/myimg02 Removing image: 100% complete...done. [cephadm@admin ceph-cluster]$ rbd children kube/vol01@clonetpl01 kube/myimg01
展平快照文件
如果我们要删除底层的模板快照文件,为了避免对上层镜像的文件产生不好的影响, 我们可以将底层快照的文件转移到上层clone文件中一份,这个动作叫展平快照文件
展平数据 [cephadm@admin ceph-cluster]$ rbd flatten kube/myimg01 Image flatten: 100% complete...done. 取消保护基础快照模板文件 [cephadm@admin ceph-cluster]$ rbd snap unprotect kube/vol01@clonetpl01 移除底层的模板文件 [cephadm@admin ceph-cluster]$ rbd snap rm kube/vol01@clonetpl01 Removing snap: 100% complete...done. 查看效果 [cephadm@admin ceph-cluster]$ rbd snap ls kube/vol01
在客户端上不影响子clone文件的操作 [root@stor26 ~]# ls /mnt issue lost+found [root@stor26 ~]# cat /mntiss cat: /mntiss: No such file or directory [root@stor26 ~]# cat /mnt/issue \S Kernel \r on an \m myimg1
6.3 小结
7.RBD实践
学习目标:这一节,我们从 案例需求、简单实践、小结 三个方面来学习。
7.1 基础知识
简介
ceph提供的块存储能够可以为其他虚拟机提供磁盘设备来进行使用, 所以接下来我们准备将ceph的磁盘文件提供给kvm进行使用。
我们需要按照如下的步骤来进行相关的实践: 1 kvm环境和ceph环境准备 2 ceph和kvm认证集成 3 kvm到ceph中创建镜像文件 4 启动KVM虚拟机测试ceph磁盘使用效果
准备系统文件
获取镜像文件,切换到stor25节点 [root@stor25 ~]# mkdir /data/images/ && cd /data/images/ [root@stor25 images]# wget http://download.cirros-cloud.net/0.5.2/cirros-0.5.2-x86_64-disk.img
部署kvm环境
判断CPU是否支持硬件虚拟化 [root@stor25 images]# egrep '(vmx|svm)' --color=always /proc/cpuinfo | wc -l 0 检查kvm模块是否加载 [root@stor25 images]# lsmod | grep kvm
安装软件 [root@stor25 ~]# yum install -y virt-manager libvirt qemu-kvm kvm 注意: libvirt 虚拟机管理 virt 虚拟机安装克隆 qemu-kvm 管理虚拟机磁盘
启动服务 [root@stor25 images]# systemctl start libvirtd.service 确认效果 [root@stor25 images]# systemctl status libvirtd.service
查看虚拟网络 [root@stor25 images]# virsh net-list Name State Autostart Persistent ---------------------------------------------------------- default active yes yes 查看虚拟主机 [root@stor25 images]# virsh list Id Name State ----------------------------------------------------
部署ceph环境
安装ceph软件 [root@stor05 ~]# yum install ceph ceph-common -y
7.2 简单实践
确认kvm环境支持rdb磁盘
内置的qemu-kvm包已经支持RBD块设备 [root@stor25 images]# qemu-img --help | grep rbd Supported formats: vvfat vpc vmdk vhdx vdi ssh sheepdog rbd raw host_cdrom host_floppy host_device file qed qcow2 qcow parallels nbd iscsi gluster dmg tftp ftps ftp https http cloop bochs blkverify blkdebug [root@stor25 images]# ldd /usr/libexec/qemu-kvm | grep rbd librbd.so.1 => /lib64/librbd.so.1 (0x00007f67da273000) 结果显示: qemu-kvm具备访问RBD的能力。ceph创建专属的pool和秘钥
Ceph建立一个Pool, [cephadm@admin ~]$ ceph osd pool create superopsmsb 16 16 pool 'superopsmsb' created 启动rbd功能 [cephadm@admin ~]$ ceph osd pool application enable superopsmsb rbd enabled application 'rbd' on pool 'superopsmsb' rbd环境初始化 [cephadm@admin ~]$ rbd pool init superopsmsb
创建superopsmsb的pool专属认证权限 [cephadm@admin ~]$ ceph auth get-or-create client.superopsmsb mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=superopsmsb' [client.superopsmsb] key = AQDrHyJmRhjpHxAABpBeh0Kn6EKhh8NJgstCEw==创建专属用户的秘钥文件 [cephadm@admin ~]$ ceph auth get client.superopsmsb -o ceph.client.superopsmsb.keyring exported keyring for client.superopsmsb
传递认证文件 [cephadm@admin ceph-cluster]$ sudo scp ceph.client.superopsmsb.keyring root@stor25:/etc/ceph ceph.client.superopsmsb.keyring 100% 177 167.2KB/s 00:00 [cephadm@admin ceph-cluster]$ sudo scp ceph.client.admin.keyring root@stor25:/etc/ceph ceph.client.admin.keyring 100% 151 1.4KB/s 00:00 传递正常的ceph集群的配置文件 [cephadm@admin ceph-cluster]$ sudo scp ceph.conf root@stor25:/etc/ceph/ ceph.conf 100% 343 260.7KB/s 00:00
确认效果 [root@stor25 images]# ceph --user superopsmsb -s cluster: id: 76cc0714-0bd7-43f7-b7c3-ec8cae2819e7 health: HEALTH_OK services: mon: 3 daemons, quorum mon01,mon02,mon03 (age 117m) mgr: mon01(active, since 5h), standbys: mon02 osd: 6 osds: 6 up (since 5h), 6 in (since 9d) data: pools: 2 pools, 80 pgs objects: 41 objects, 103 MiB usage: 6.4 GiB used, 114 GiB / 120 GiB avail pgs: 80 active+cleankvm 集成ceph
[root@stor25 images]# mkdir /data/conf && cd /data/conf 创建认证文件 ceph-client-superopsmsb-secret.xml client.superopsmsb secret
使用virsh创建secret [root@stor25 conf]# virsh secret-define --file ceph-client-superopsmsb-secret.xml Secret cae1aa37-ff55-4fa9-83a0-9b14b18bf5d3 created
将ceph的client.superopsmsb的密钥导⼊secret中 [root@stor25 conf]# virsh secret-set-value --secret cae1aa37-ff55-4fa9-83a0-9b14b18bf5d3 --base64 $(ceph auth get-key client.superopsmsb) Secret value set 确认效果 [root@stor25 conf]# virsh secret-list UUID Usage -------------------------------------------------------------------------------- cae1aa37-ff55-4fa9-83a0-9b14b18bf5d3 ceph client.superopsmsb secret
镜像创建
创建空的image,或者导⼊已经的磁盘镜像内容 方法1:导入镜像 qemu-img convert -f qcow2 -O raw /path/to/image.img rbd:/ 方法2:创建镜像 qemu-img xxx create -f rbd rbd:/ size
创建镜像 [root@stor25 conf]# qemu-img create -f rbd rbd:superopsmsb/superopsmsb-image 1G Formatting 'rbd:superopsmsb/superopsmsb-image', fmt=rbd size=1073741824 cluster_size=0
确认镜像文件 [root@stor25 conf]# qemu-img info /data/images/cirros-0.5.2-x86_64-disk.img image: /data/images/cirros-0.5.2-x86_64-disk.img file format: qcow2 virtual size: 112M (117440512 bytes) disk size: 16M cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false ... 导入镜像文件到rdb [root@stor25 conf]# qemu-img convert -f qcow2 -O raw /data/images/cirros-0.5.2-x86_64-disk.img rbd:superopsmsb/cirros-0.5.2确认效果 [root@stor25 conf]# rbd --user superopsmsb ls superopsmsb -l NAME SIZE PARENT FMT PROT LOCK cirros-0.5.2 112 MiB 2 superopsmsb-image 1 GiB 2 注意: 因为是远程查看,所以信息展示有可能缓慢,我们可以直接在admin主机上进行快速查看
虚拟机创建
定制虚拟机配置文件 /data/conf/node1.xml node1 512000 512000 1 hvm /usr/libexec/qemu-kvm创建虚拟机 [root@stor25 conf]# virsh define node1.xml Domain node1 defined from node1.xml [root@stor25 conf]# virsh start node1 error: Failed to start domain node1 error: unsupported configuration: Domain requires KVM, but it is not available. Check that virtualization is enabled in the host BIOS, and host configuration is setup to load the kvm modules. # 如果是正常kvm [root@stor25 conf]# virsh start node1 域 node1 已开始
查看主机状态 [root@stor25 conf]# virsh list --all Id Name State ---------------------------------------------------- - node1 shut off(如果是正常lvm是running) 查看设备信息 [root@stor25 conf]# virsh domblklist node1 Target Source ------------------------------------------------ vda superopsmsb/cirros-0.5.2 可以借助于vnc viewer 连接到虚拟机查看效果 注意: 启动很慢,但是运行需要等待3分钟左右
磁盘挂载
关闭虚拟机 [root@stor25 conf]# virsh destroy node1 error: Failed to destroy domain node1 error: Requested operation is not valid: domain is not running # 如果是这正常的kvm如下 [root@stor25 conf]# virsh destroy node1 域 node1 被删除
编写专有设备文件 device.xml将设备追加到虚拟机中 [root@stor25 conf]# virsh attach-device node1 device.xml --persistent Device attached successfully 确认磁盘挂载效果 [root@stor25 conf]# virsh domblklist node1 Target Source ------------------------------------------------ vda superopsmsb/cirros-0.5.2 vdc superopsmsb/superopsmsb-image
环境还原
删除虚拟机 [root@stor25 conf]# virsh undefine node1 Domain node1 has been undefined
删除pool [cephadm@admin ceph-cluster]$ ceph osd pool rm superopsmsb superopsmsb --yes-i-really-really-mean-it pool 'superopsmsb' removed [cephadm@admin ceph-cluster]$ ceph osd pool rm kube kube --yes-i-really-really-mean-it pool 'kube' removed
7.3 小结







