目录
实验目的:
实验要求:
实验内容及原理:
参考代码:
实验结果:
实验目的:
加深对汉语文本信息处理基础理论及方法的认识和了解,锻炼和提高分析问题、解决问题的能力。通过对具体项目的任务分析、数据准备、算法设计和编码实现以及测试评价几个环节的练习,基本掌握实现一个自然语言处理系统的基本过程。
实验要求:
1.基于文档频率的特征选择方法
2.基于互信息/信息增益的特征选择方法
实验内容及原理:
该子任务利用特征选择算法从给定带有类别标签的句子集中抽取具有最具代表性的N个词作为特征集。
要求分别实现:基于文档频率DF的特征选择方法,以及基于互信息、信息增益两种方法中的任意一种,推荐使用信息增益方法。
主要流程如下:
1)从给定的语料集中提取出带有类别标签的句子并进行预处理(分词、去除停用词),构建候选特征词集S。
2)对候选特征词集S中的所有词汇w,计算其特征得分s(w),计算方法分别使用文档频率、互信息、信息增益三种方法实现。三种方法的计算公式如下所示:
文档频率:通过计算特征词条t在各文档中出现的文档频率来完成提取。对所有词条计算其出现的文档频数,从大到小进行排序,取前K~K+N个词语作为文本特征集合。
互信息:通过计算特征词条t和类别c之间的相关性来完成提取。
如果用A表示包含特征词条t且属于类别c的文档频数,B为包含t但是不属于c的文档频数,C表示属于c但不包含t的文档频数,N表示语料中文档的总数,可构建如图1所示的矩阵形式,t和c的互信息可由下式计算:

对多个类别的特征选择,可采用两种方式选择特征词,并体会其结果差异:
a)计算各个类别下的互信息的平均值作为该词条的互信息值,计算公式为:
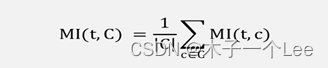
b)对每个类别按照特征词与类别的共现概率计算期望值,计算公式为:
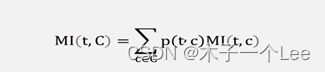
信息增益:对于特征词条t和文档类别c,IG考察c中出现和不出现t的文档频数来衡量t对于c的信息增益,定义如下:
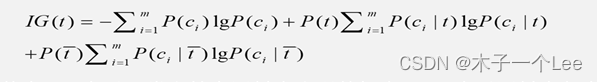
其中P(c)表示ci类文档在语料中出现的概率,Pt表示语料中包含特征词条t的文档的概率,P(c, l 八)表示文档包含特征词条t时属于ci类的条件概率,P()表示语料中不包含特征词条t的文档的概率,P(c, l)表示文档不包含特征词条t时属于ci类的条件概率,m表示文档类别数。
如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征。
3)依据候选特征词集S中词汇w的特征得分s(w)进行排序,选择得分最大的前N=1000个词作为文本的表示特征集。存储到文件当中。
存储格式:一行为一个特征词,以utf-8进行编码。
实验数据采用htl_del_4000宾馆情感分析数据进行处理,所有数据已按照情感极性划分为褒(pos)贬(neg)两类,各2000篇,每个文本文件为一篇文章,实验数据需要先进行分词,分词方法不限。
统计频数时按照篇章级共现进行计算。
停用词表采用中文通用停用词表,文件名为
“cn stopwords.txt”,可用于数据预处理中的去除停用词。
参考代码:
#任务1
import jieba
import os
dictionary = {}
dic={}
def fun(d):
if d!={}:
pass
class DF:
def __init__(self):
self.files = {}
self.stop_words = set(())
fun(dic)
content = open('cn_stopwords.txt', 'r',encoding='utf-8').read()
for sl in content.splitlines():
self.stop_words.add(sl)
def add_file(self, file_name):
# Load data and cut #加载
if(os.path.exists('./中文信息处理技术实验数据/htl_del_4000/'+ file_name)):
content = open(file_name, 'rb').read() if file_name[0] == '/' or file_name[0] == 'C' else open('./中文信息处理技术实验数据/htl_del_4000/'+ file_name, 'rb').read()
words = jieba.cut(content)
else:
return
se = set()
for w in words:
if len(w.strip())
实验结果:
1. 基于文档频率的特征选择方法
2. 基于互信息的特征选择方法