

1. 问题描述

出现原因:tensorflow版本与keras版本不对应
(图片是取自一位叫皮肤科大白的博主)如果两个版本不对应就会出现上述问题
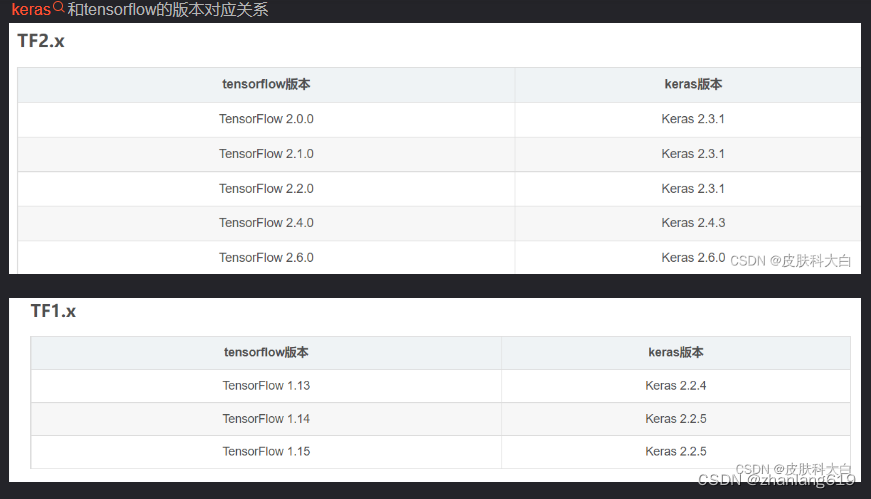
解决办法:查找自己tensorflow的版本号,根据tensorflow版本安装对应版本的keras
#查找tensorflow版本号 pip list #或者 conda list
2.问题描述

出现原因:在tensorflow2.X.X版本中,许多函数都与version 1.X.X不同,所以会造成此种情况
解决办法:在tensorflow2.X.X版本中直接调用version 1.X.X版本中的函数
#将之间的 import tensorflow as tf 换成如下 import tensorflow.compat.v1 as tf
3.问题描述

出现原因:是因为tensorflow版本更新问题,更新之后不再使用_parse_flag进行解析
解决办法:
#需将原始代码 FLAGS._parse_flags() #换为 print(FLAGS.flags.values.dict()) #或者换为 FLAGS.flag_values_dict()
4.问题描述
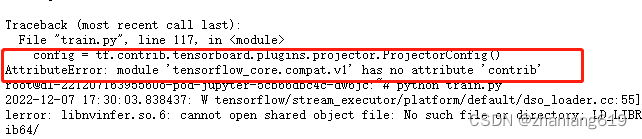
出现原因:在更新后的版本中并没有之前的contrib包,需要改成版本更新后的才可以正常运行
解决办法:
#笔者采用如下办法,导入tensorboard包与projector import tensorboard from tensorboard.plugins import projector #对应代码位置修改为 config = tensorboard.plugins.projector.ProjectorConfig() #引申:这里出现问题的是tf.contrib.tensorboard #对于contrib类问题,需要具体问题具体对待,不可一概而论
5.问题描述


出现原因:没有正确安装sklearn,而且普通pIP命令会出错
解决办法:
#采用管理员命令进行安装 pip install -U scikit-learn
6.问题描述

出现原因:与问题二类似
解决办法:
#与问题二类似 import tensorflow.compat.v1 as tf
7.问题描述

出现原因:词向量文件中的第一行是两个数字,第一个表示此文件中共有词多少,不是行数(因为这个数和词的数量对不上才报了上边的错);第二个是词向量的维度
解决办法:ctrl+End找到文件最底部,看看共有多少行,再减掉第一行,就是词的数量,把第一行的第一个数改成这个就好了
8.问题描述

出现原因:
解决办法:
https://blog.csdn.net/weixin_44843629/article/details/114632508
ModuleNotFoundError: No module named 'sklearn.cross_validation'
init() got an unexpected keyword argument ‘size‘ 错误的解决办法
init() got an unexpected keyword argument ‘iter’
https://blog.csdn.net/PIG_RABBIT/article/details/122910443
You must specify either total_examples or total_words, for proper learning-rate and progress calcula
https://blog.csdn.net/PIG_RABBIT/article/details/122915627

File “/root/utils/train.py”, line 60, in train_model
batch_x1 = torch.stack(batch_x1, dim=1)
RuntimeError: stack expects each tensor to be equal size, but got [64, 3, 224, 224] at entry 0 and [64, 128] at entry 1
(待完善)







