

常年技术圈无人问津的甲骨文可能自己也没有想到,它的“出圈”会是因为一届数学建模竞赛,随着今天铺天盖地的咨询留言过来我就意识到必有反常事情得发生,查了一下发现原来是第十四届数学建模竞赛开始了,2024年第十四届MathorCup数学应用挑战赛【原数学建模挑战赛】如下:

一共提供了ABCD四道题目,其中B题就是甲骨文检测识别的任务,从这道题目的命题中不难分析出来这也是一个趋势,更是主办方和文物研究院的合作尝试,本文甲骨文这种远古时期文字的破译就是比较困难的工作,能够结合现代科技的力量来做一点尝试呢?是否能得到不一样的结果呢?这个我们不得而知,从技术的层面来讲这个题目的主要内容就是要做一个目标检测模型,这块相关的内容可以参考我前面的系列博文,甲骨文的实践内容全网之下我前面应该也是做的最多的了:
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
《紧接上文,基于轻量级yolov5s模型开发构建手写甲骨文检测识别系统》
《python基于yolov7开发构建手写甲骨文检测识别系统》
《探索考古文字场景,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探索考古文字场景,基于YOLOv9全系列【gelan/gelan-c/gelan-e/yolov9/yolov9-c/yolov9-e】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探寻殷墟文化,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建殷墟考古场景下的甲骨文字符检测识别分析系统》
《探索考古文字场景,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
《探索考古文字场景,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建文本考古场景下的甲骨文字符图像检测识别系统》
甲骨文,又称“契文”、“甲骨卜辞”、“殷墟文字”或“龟甲兽骨文”,是中国的一种古老文字,也是中国发现的最早的成熟文字系统。它主要指中国商朝晚期王室用于记事而在龟甲或兽骨上契刻的文字,是汉字的源头和中华优秀传统文化的根脉。
甲骨文最早在1899年被清朝人王懿荣发现,此后在安阳殷墟、陕西、山东等地出土了大量商代和西周甲骨。至今已有超过16万片甲骨被发现,其中商代有字的甲骨10余万片,单字数量达到4500个左右,已经识别的有1500多字。甲骨文以其详实、生动的记载,展现了当时社会的发展、变化和进步,为后来历史的研究提供了弥足珍贵的资料。
甲骨文的特点有图画性强、笔画繁多、线条细瘦、笔画多放折等。由于甲骨文是用刀刻成的,而刀有锐有钝,骨质有细有粗,有硬有软,所以刻出的笔画粗细不一,甚至有的纤细如发,笔画的连接处又有剥落,浑厚粗重。其用笔线条严整瘦劲,曲直粗细均备,笔画多方折,对后世篆刻的用笔用刀产生了影响。从字形构成、符号化程度、书写形式和使用功能等方面可以看出,商代晚期的甲骨文是一种经历了较长时间发展、结构成熟、功能完备的文字符号体系,是可以确定的汉字进入成熟阶段的体系完整的文字样本。
甲骨文的内容涉及广泛,包括祭祀、战争、农牧业、官制、刑法、医药、天文历法等,反映了商代晚期社会的生产、生活和文化特征。甲骨文不仅是中国古文化遗产的重要组成部分,更是研究中国古代历史和文化的重要资料。它以其独特的文化内涵、思想观念、道德伦理等方面的信息,对后世文化的演进和发展,以及人类文明的进程产生了深远的影响。甲骨文作为中国最早的成熟文字系统,具有极高的历史和文化价值。它为我们了解商代晚期社会、文化和思想提供了宝贵的资料,同时也对研究中国古代历史和文化具有重要意义。
个人也是觉得这个题目比较有意思,所以也想实际做一下,当然了我自己就不是参加比赛的性质了,初步看了下赛题大概提供了不到7k的数据量,这块的数据量主要是用于检测模型的开发的,然后识别的块主要提供了76的单字符的数据集,说句客观化我个人觉得最复杂的部分可能就是最后一问也就是识别的问题,其实对于那些专家来说可能自己也不知道一共包含了多少种不同的字符,所以这个也就不是一个单纯的识别问题。
这里呢暂时没有去拿赛题的数据来开发模型,因为在前面的一段时间里面我自己闲暇时间构建了一批手写甲骨文的数据集,自己也花了很多时间去进行对应的处理、研究和标注工作,本文作为开篇主要目的就是基于我自己的这批数据集来开发构建一个甲骨文检测识别系统,首先看下实例效果:
接下来简单看下实例数据:


我的数据集和赛题数据集相比更偏理想化的实验数据集,赛题数据集更偏真实场景。
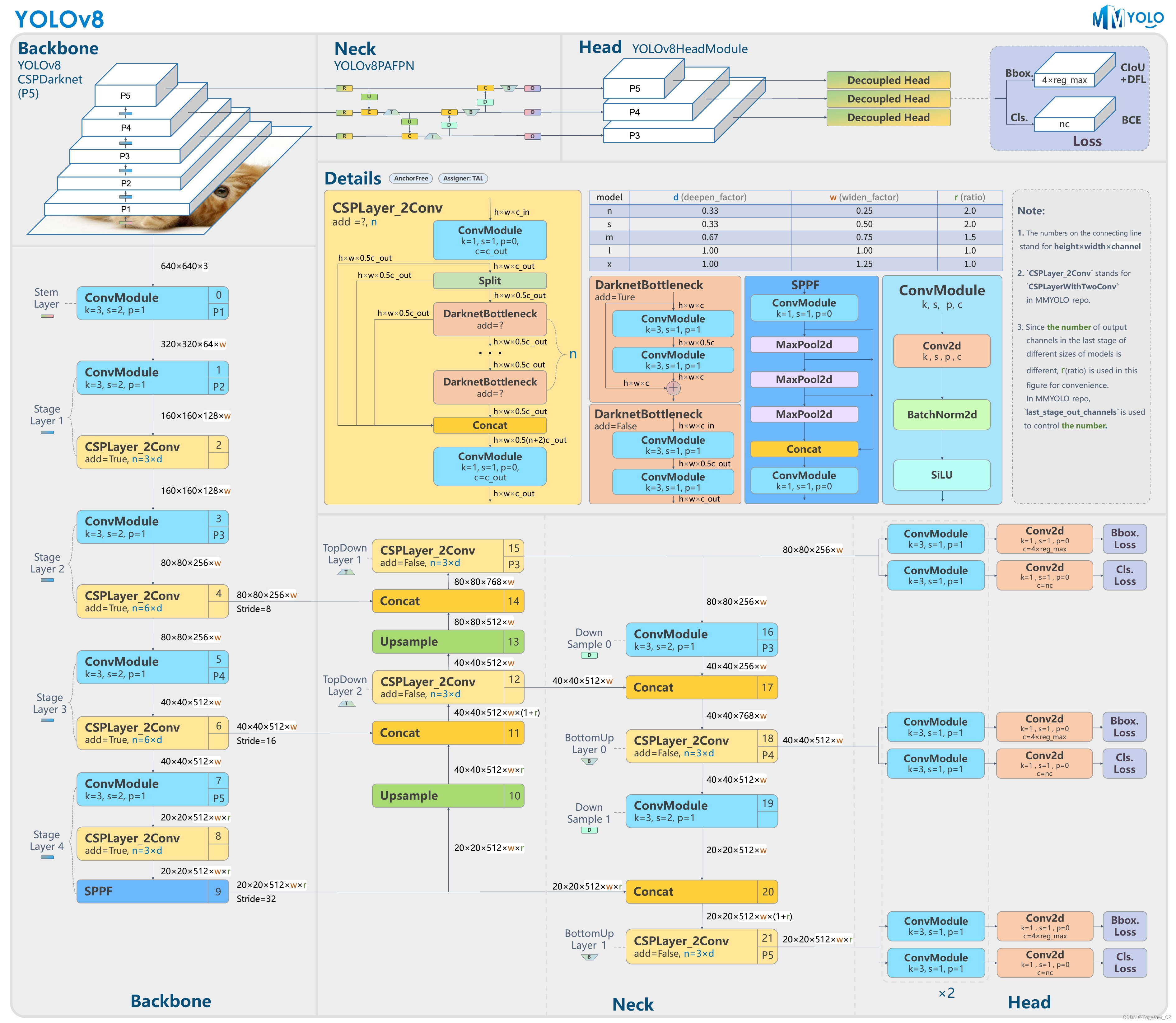
这里我选择的是轻量级的yolov8n模型,模型文件如下所示:
# Ultralytics YOLO 🚀, AGPL-3.0 license # YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect # Parameters nc: 80 # number of classes scales: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs # YOLOv8.0n backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 6, C2f, [256, True]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 6, C2f, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 3, C2f, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 # YOLOv8.0n head head: - [-1, 1, nn.Upsample, [None, 2, 'nearest']] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 3, C2f, [512]] # 12 - [-1, 1, nn.Upsample, [None, 2, 'nearest']] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 3, C2f, [256]] # 15 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 12], 1, Concat, [1]] # cat head P4 - [-1, 3, C2f, [512]] # 18 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 9], 1, Concat, [1]] # cat head P5 - [-1, 3, C2f, [1024]] # 21 (P5/32-large) - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
模型结构如下:
这批数据集中共包含了常见的80个汉字,如下所示:
{
"下": "0",
"0": "下",
"丝": "1",
"1": "丝",
"之": "2",
"2": "之",
"乳": "3",
"3": "乳",
"五": "4",
"4": "五",
"亢": "5",
"5": "亢",
"伊": "6",
"6": "伊",
"伏": "7",
"7": "伏",
"依": "8",
"8": "依",
"刚": "9",
"9": "刚",
"利": "10",
"10": "利",
"剐": "11",
"11": "剐",
"劦": "12",
"12": "劦",
"区": "13",
"13": "区",
"千": "14",
"14": "千",
"厚": "15",
"15": "厚",
"取": "16",
"16": "取",
"土": "17",
"17": "土",
"埜": "18",
"18": "埜",
"壶": "19",
"19": "壶",
"大": "20",
"20": "大",
"奻": "21",
"21": "奻",
"姓": "22",
"22": "姓",
"娕": "23",
"23": "娕",
"寍": "24",
"24": "寍",
"年": "25",
"25": "年",
"并": "26",
"26": "并",
"我": "27",
"27": "我",
"才": "28",
"28": "才",
"折": "29",
"29": "折",
"族": "30",
"30": "族",
"昜": "31",
"31": "昜",
"星": "32",
"32": "星",
"曰": "33",
"33": "曰",
"曲": "34",
"34": "曲",
"朊": "35",
"35": "朊",
"望": "36",
"36": "望",
"朝": "37",
"37": "朝",
"李": "38",
"38": "李",
"杏": "39",
"39": "杏",
"果": "40",
"40": "果",
"栎": "41",
"41": "栎",
"棋": "42",
"42": "棋",
"櫅": "43",
"43": "櫅",
"永": "44",
"44": "永",
"汜": "45",
"45": "汜",
"汫": "46",
"46": "汫",
"洀": "47",
"47": "洀",
"涉": "48",
"48": "涉",
"焚": "49",
"49": "焚",
"爵": "50",
"50": "爵",
"牢": "51",
"51": "牢",
"男": "52",
"52": "男",
"癸": "53",
"53": "癸",
"盉": "54",
"54": "盉",
"祊": "55",
"55": "祊",
"稠": "56",
"56": "稠",
"竽": "57",
"57": "竽",
"纟": "58",
"58": "纟",
"翟": "59",
"59": "翟",
"肉": "60",
"60": "肉",
"脽": "61",
"61": "脽",
"臭": "62",
"62": "臭",
"舞": "63",
"63": "舞",
"萑": "64",
"64": "萑",
"蔑": "65",
"65": "蔑",
"豕": "66",
"66": "豕",
"象": "67",
"67": "象",
"责": "68",
"68": "责",
"逆": "69",
"69": "逆",
"郁": "70",
"70": "郁",
"采": "71",
"71": "采",
"阜": "72",
"72": "阜",
"雈": "73",
"73": "雈",
"韦": "74",
"74": "韦",
"首": "75",
"75": "首",
"骑": "76",
"76": "骑",
"麓": "77",
"77": "麓",
"鼎": "78",
"78": "鼎",
"龋": "79",
"79": "龋"
}
因为汉字作为标签的话会出现一些编码类的问题,所以这里我选择对其做了数字的转化处理。
训练数据配置文件如下:
# path train: /data/oracle/dataset/images/train/ val: /data/oracle/dataset/images/test/ # number of classes nc: 80 # class names names: ['O0', 'O1', 'O2', 'O3', 'O4', 'O5', 'O6', 'O7', 'O8', 'O9', 'O10', 'O11', 'O12', 'O13', 'O14', 'O15', 'O16', 'O17', 'O18', 'O19', 'O20', 'O21', 'O22', 'O23', 'O24', 'O25', 'O26', 'O27', 'O28', 'O29', 'O30', 'O31', 'O32', 'O33', 'O34', 'O35', 'O36', 'O37', 'O38', 'O39', 'O40', 'O41', 'O42', 'O43', 'O44', 'O45', 'O46', 'O47', 'O48', 'O49', 'O50', 'O51', 'O52', 'O53', 'O54', 'O55', 'O56', 'O57', 'O58', 'O59', 'O60', 'O61', 'O62', 'O63', 'O64', 'O65', 'O66', 'O67', 'O68', 'O69', 'O70', 'O71', 'O72', 'O73', 'O74', 'O75', 'O76', 'O77', 'O78', 'O79']
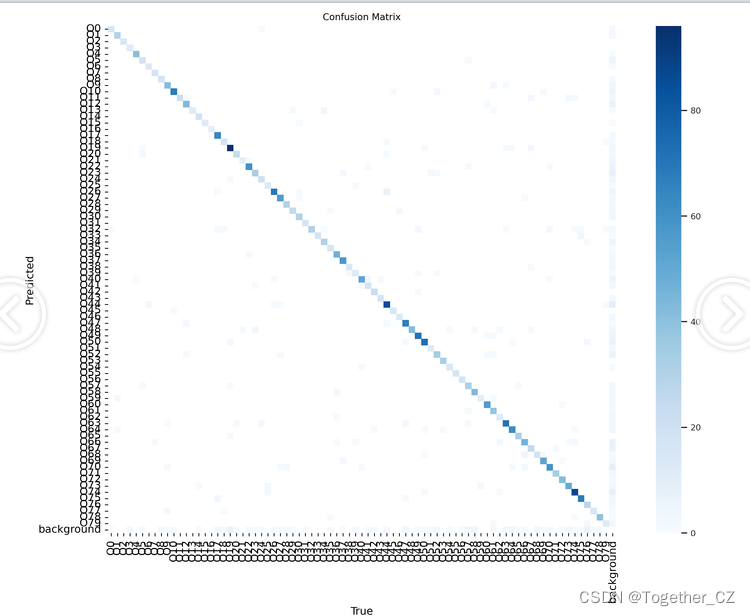
因为模型选择的是最为轻量级的n系列的模型,所以训练整体比较快,等待训练完成后我们整体看下训练结果:
【混淆矩阵】
【F1值曲线】
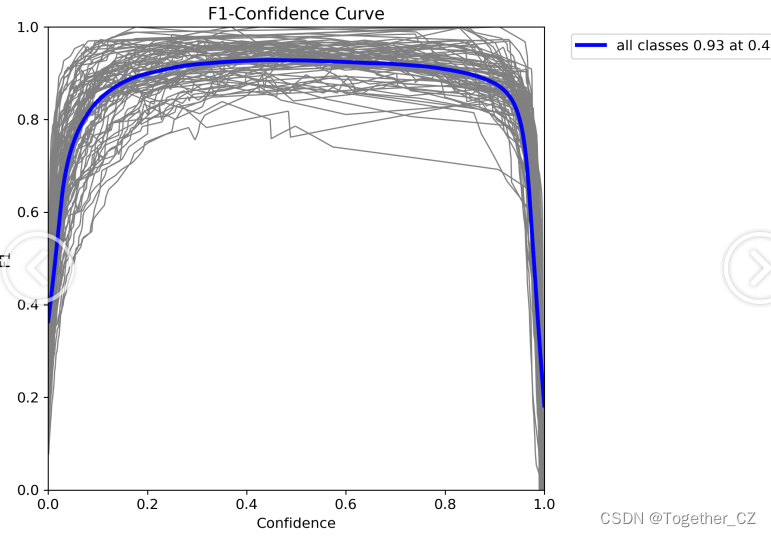
【Precision曲线】
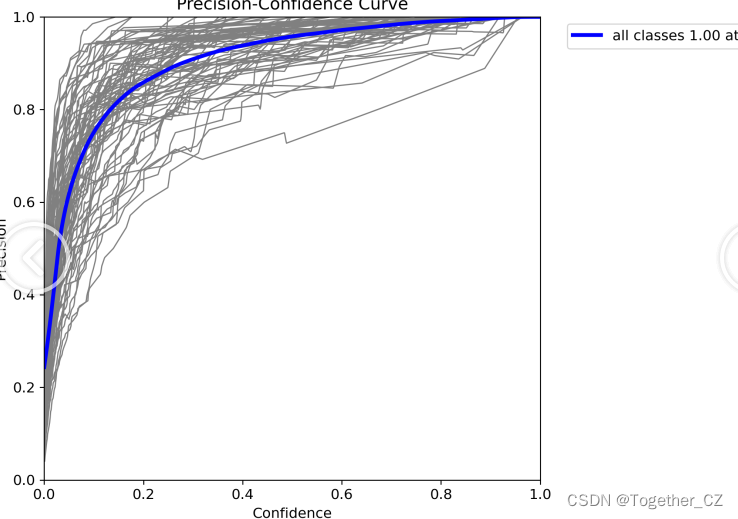
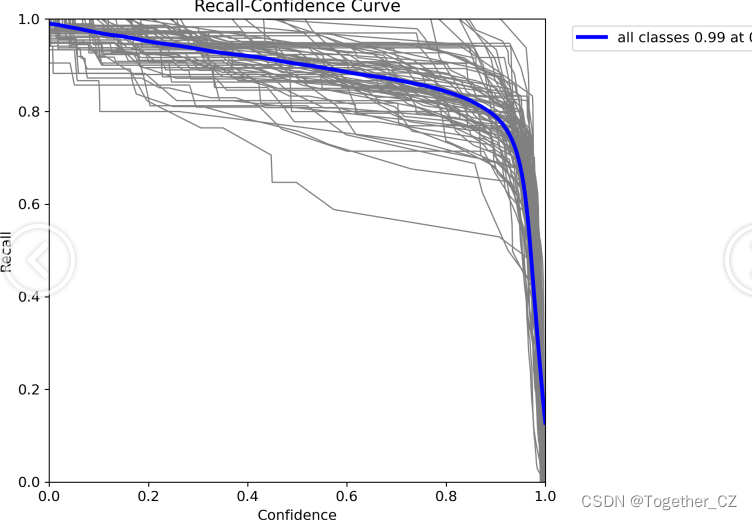
【PR曲线】

【Recall曲线】
【训练可视化】
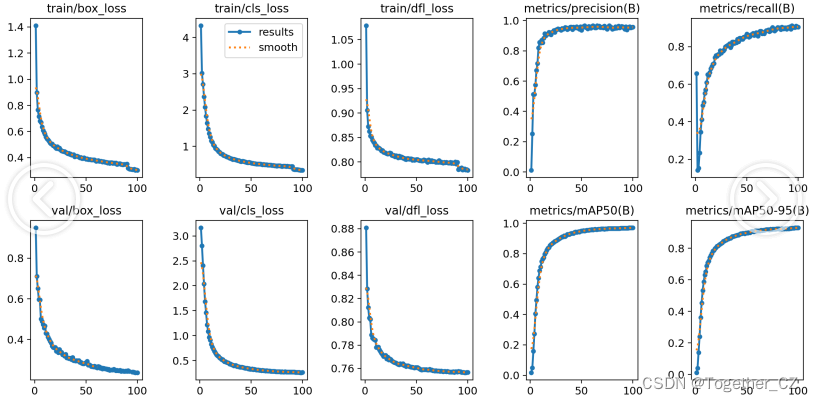
【Batch实例】

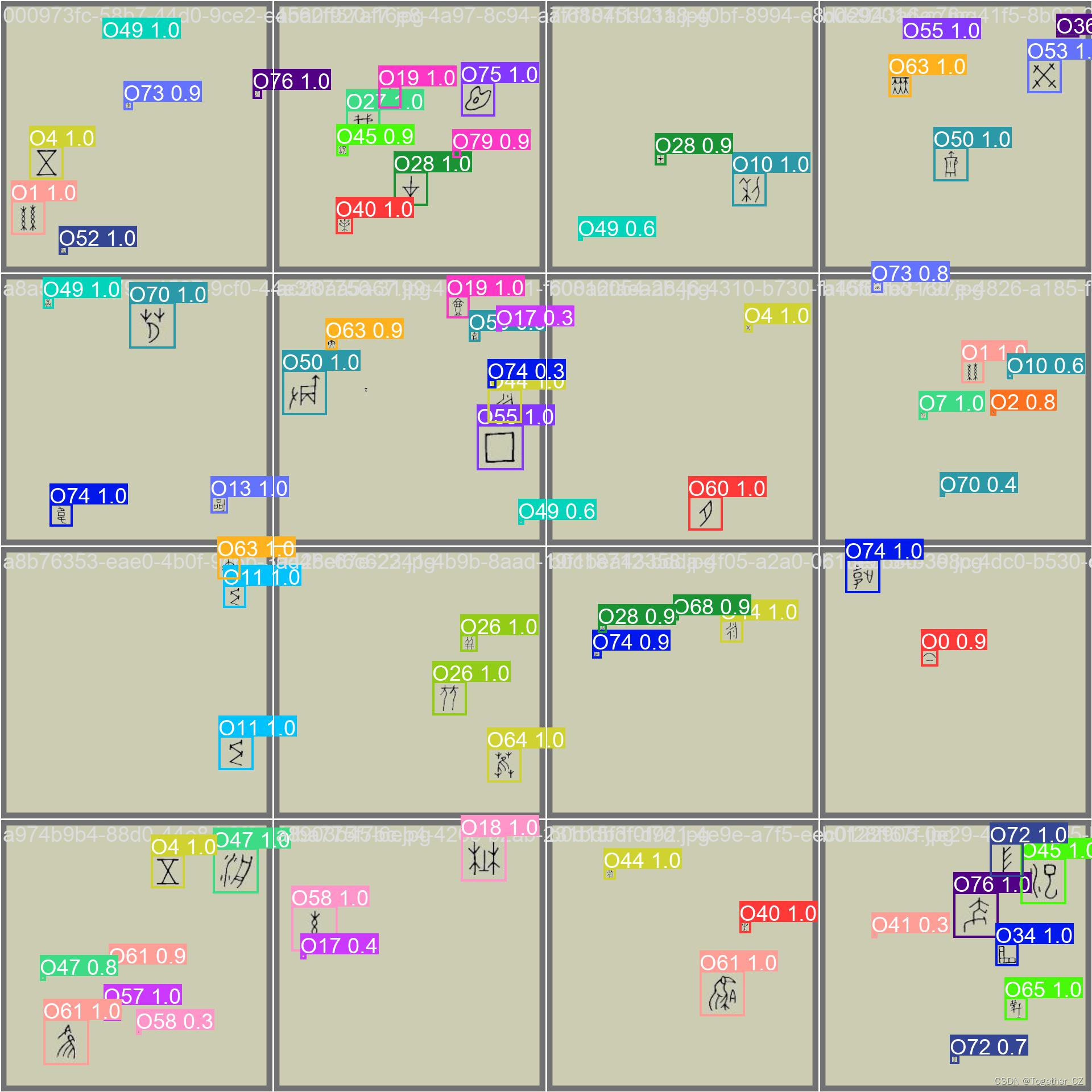
在我以往的文章实践中,没有办法将甲骨文字符和具体代表的汉字相对应起来,在这里我们已经实现了完全的统一对应,这也是这段时间里面花费了很多人心血完成的事情。
这里作为开篇主要的目的一是借本次赛题的东风,介绍下近期工作的成果,另一方面作为赛题的开篇,接下来还会有对应的开发工作开始陆续介绍。







