

1.背景介绍
自然语言处理(NLP)是人工智能领域的一个重要分支,其主要目标是让计算机能够理解、生成和处理人类语言。语义分析是NLP的一个关键技术,它涉及到词汇、语法和语境等多种方面,以便计算机能够理解语言的含义。知识图谱则是一种结构化的数据库,用于存储实体、关系和属性等信息,以便计算机能够理解和推理。
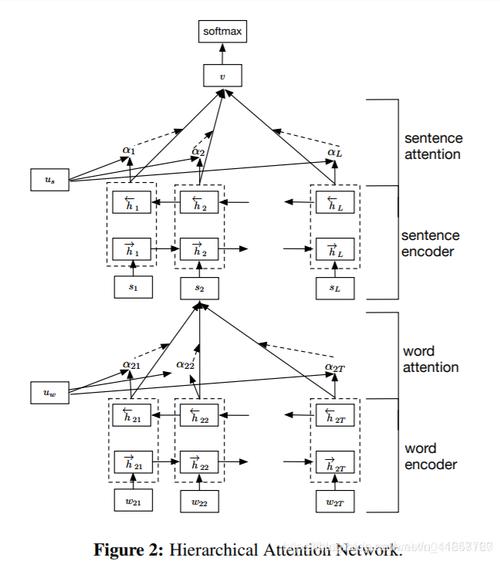
在过去的几年里,语义分析和知识图谱构建技术得到了很大的发展,尤其是随着大数据技术的发展,这些技术在各个领域得到了广泛的应用。例如,在自然语言理解、机器翻译、情感分析、问答系统等方面,语义分析和知识图谱构建技术都发挥了重要作用。
本文将从以下六个方面进行全面的介绍:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
2.核心概念与联系
2.1 自然语言处理(NLP)
自然语言处理(NLP)是计算机科学与人工智能领域的一个分支,旨在让计算机理解、生成和处理人类语言。NLP的主要任务包括:文本分类、情感分析、命名实体识别、语义角色标注、语义解析等。
2.2 语义分析
语义分析是NLP的一个关键技术,它旨在从文本中抽取出语义信息,以便计算机能够理解语言的含义。语义分析可以分为以下几个方面:
- 词义分析:旨在理解词汇的不同含义。
- 语法分析:旨在理解句子的结构和关系。
- 语境分析:旨在理解词汇和句子在特定语境中的含义。
2.3 知识图谱(Knowledge Graph)
知识图谱是一种结构化的数据库,用于存储实体、关系和属性等信息。知识图谱可以帮助计算机理解和推理,并且可以用于各种应用,如问答系统、推荐系统、语义搜索等。知识图谱的主要组成元素包括:
- 实体:表示人、地点、组织等实体。
- 关系:表示实体之间的关系,如属于、属性等。
- 属性:表示实体的特征,如名字、年龄等。
2.4 语义分析与知识图谱构建的联系
语义分析和知识图谱构建是两个相互关联的技术,它们可以相互辅助,以便更好地理解和处理人类语言。具体来说,语义分析可以帮助构建知识图谱,因为它可以从文本中抽取出有意义的信息,并且为实体和关系提供有意义的描述。而知识图谱则可以帮助语义分析,因为它可以提供结构化的信息,以便计算机更好地理解语言的含义。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 词义分析
词义分析是理解词汇的不同含义的过程。常见的词义分析方法包括:
- 统计学方法:通过计算词汇在不同上下文中的出现频率,以便理解其不同含义。
- 规则引擎方法:通过定义规则来描述词汇的不同含义。
- 机器学习方法:通过训练模型来预测词汇在不同上下文中的含义。
3.1.1 统计学方法
统计学方法主要通过计算词汇在不同上下文中的出现频率,以便理解其不同含义。例如,可以使用TF-IDF(Term Frequency-Inverse Document Frequency)来计算词汇在文本中的重要性。TF-IDF公式如下:
$$ TF-IDF(t,d) = tf(t,d) \times \log \frac{N}{n(t)} $$
其中,$t$表示词汇,$d$表示文本,$N$表示文本集合,$n(t)$表示包含词汇$t$的文本数量。
3.1.2 规则引擎方法
规则引擎方法主要通过定义规则来描述词汇的不同含义。例如,可以使用正则表达式来描述词汇的不同形式,从而理解其不同含义。
3.1.3 机器学习方法
机器学习方法主要通过训练模型来预测词汇在不同上下文中的含义。例如,可以使用支持向量机(SVM)来分类词汇的不同含义。
3.2 语法分析
语法分析是理解句子结构和关系的过程。常见的语法分析方法包括:
- 规则引擎方法:通过定义规则来描述句子结构和关系。
- 机器学习方法:通过训练模型来预测句子结构和关系。
3.2.1 规则引擎方法
规则引擎方法主要通过定义规则来描述句子结构和关系。例如,可以使用正则表达式来描述句子结构,从而理解其关系。
3.2.2 机器学习方法
机器学习方法主要通过训练模型来预测句子结构和关系。例如,可以使用递归神经网络(RNN)来处理句子结构。
3.3 语境分析
语境分析是理解词汇和句子在特定语境中的含义的过程。常见的语境分析方法包括:
- 统计学方法:通过计算词汇在不同语境中的出现频率,以便理解其含义。
- 规则引擎方法:通过定义规则来描述语境。
- 机器学习方法:通过训练模型来预测语境。
3.3.1 统计学方法
统计学方法主要通过计算词汇在不同语境中的出现频率,以便理解其含义。例如,可以使用TF-IDF来计算词汇在不同语境中的重要性。
3.3.2 规则引擎方法
规则引擎方法主要通过定义规则来描述语境。例如,可以使用正则表达式来描述语境,从而理解词汇和句子的含义。
3.3.3 机器学习方法
机器学习方法主要通过训练模型来预测语境。例如,可以使用支持向量机(SVM)来分类语境。
4.具体代码实例和详细解释说明
在本节中,我们将通过一个具体的例子来说明语义分析和知识图谱构建的实现过程。假设我们要构建一个简单的知识图谱,其中包含以下实体和关系:
- 实体:人(Person)、地点(Place)、组织(Organization)
- 关系:属于(属性)、属性(Attribute)
首先,我们需要定义实体和关系的类别,并且为每个实体和关系分配一个唯一的ID。例如,我们可以为人分配ID为1,地点分配ID为2,组织分配ID为3,属于分配ID为4,属性分配ID为5。
接下来,我们需要定义实体和关系之间的属性。例如,人可能有名字、年龄等属性,地点可能有名字、所在国家等属性,组织可能有名字、成立年代等属性。
接下来,我们需要定义实体和关系之间的关系。例如,人可能属于某个地点,地点可能属于某个国家,组织可能位于某个地点。
最后,我们需要将这些实体、关系和属性存储在知识图谱中。例如,我们可以使用RDF(Resource Description Framework)格式来存储这些信息。
以下是一个简单的RDF示例:
``` @prefix rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# . @prefix ex: http://example.org/ .
ex:Person1 rdf:type ex:Person ; ex:Person1 rdf:attributes ex:Name "John" ; ex:Person1 rdf:attributes ex:Age 30 ; ex:Person1 ex:locatedIn ex:Place1 .
ex:Place1 rdf:type ex:Place ; ex:Place1 rdf:attributes ex:Name "New York" ; ex:Place1 rdf:attributes ex:Country "USA" ; ex:Place1 rdf:type ex:Organization . ```
在这个示例中,我们定义了一个名为“John”的人,他的年龄是30岁,所在地是名为“New York”的地点,这个地点是一个组织,属于“USA”国家。
5.未来发展趋势与挑战
随着大数据技术的发展,语义分析和知识图谱构建技术将会在各个领域得到更广泛的应用。未来的发展趋势和挑战包括:
- 更高效的算法:随着数据规模的增加,需要更高效的算法来处理大规模的语义分析和知识图谱构建任务。
- 更智能的系统:需要开发更智能的系统,以便更好地理解和处理人类语言,并且提供更准确的信息。
- 更强大的应用:语义分析和知识图谱构建技术将会在各个领域得到更广泛的应用,例如医疗、金融、教育等。
- 更好的隐私保护:随着数据的增多,隐私保护问题将会更加重要,需要开发更好的隐私保护技术。
- 更多的跨学科研究:语义分析和知识图谱构建技术将会与其他学科领域产生更多的交叉研究,例如人工智能、计算机视觉、自然语言处理等。
6.附录常见问题与解答
在本节中,我们将回答一些常见问题:
Q: 什么是自然语言处理(NLP)? A: 自然语言处理(NLP)是计算机科学与人工智能领域的一个分支,旨在让计算机理解、生成和处理人类语言。
Q: 什么是语义分析? A: 语义分析是NLP的一个关键技术,它旨在从文本中抽取出语义信息,以便计算机能够理解语言的含义。
Q: 什么是知识图谱(Knowledge Graph)? A: 知识图谱是一种结构化的数据库,用于存储实体、关系和属性等信息。知识图谱可以帮助计算机理解和推理,并且可以用于各种应用,如问答系统、推荐系统、语义搜索等。
Q: 语义分析与知识图谱构建的关系是什么? A: 语义分析和知识图谱构建是两个相互关联的技术,它们可以相互辅助,以便更好地理解和处理人类语言。
Q: 如何构建知识图谱? A: 构建知识图谱的过程包括以下几个步骤:
- 收集数据:收集需要存储在知识图谱中的信息。
- 清洗数据:对收集到的数据进行清洗和预处理,以便进行下一步的处理。
- 提取实体、关系和属性:从数据中提取出实体、关系和属性等信息。
- 存储数据:将提取出的信息存储在知识图谱中,以便进行查询和推理。
- 构建索引:构建索引,以便更快地查询知识图谱中的信息。
Q: 如何进行语义分析? A: 语义分析可以通过以下几种方法进行:
- 统计学方法:通过计算词汇在不同上下文中的出现频率,以便理解其不同含义。
- 规则引擎方法:通过定义规则来描述词汇的不同含义。
- 机器学习方法:通过训练模型来预测词汇在不同上下文中的含义。
Q: 如何进行知识图谱构建? A: 知识图谱构建可以通过以下几种方法进行:
- 手工构建:人工编辑知识图谱,这种方法通常用于小规模的知识图谱。
- 自动构建:使用算法自动构建知识图谱,这种方法通常用于大规模的知识图谱。
- 半自动构建:结合手工构建和自动构建的方法,这种方法通常用于中规模的知识图谱。
Q: 知识图谱与关系图的区别是什么? A: 知识图谱是一种结构化的数据库,用于存储实体、关系和属性等信息,而关系图是一种图形化的表示方式,用于表示实体之间的关系。知识图谱可以通过关系图进行可视化表示。
Q: 知识图谱与数据库的区别是什么? A: 知识图谱是一种结构化的数据库,用于存储实体、关系和属性等信息,而数据库是一种更一般的数据存储结构,可以存储各种类型的数据。知识图谱是一种特殊类型的数据库,用于存储和管理知识。
Q: 如何评估知识图谱的质量? A: 知识图谱的质量可以通过以下几个指标进行评估:
- 完整性:知识图谱中实体、关系和属性的准确性。
- 一致性:知识图谱中实体、关系和属性的一致性。
- 可扩展性:知识图谱的能力,能够随着数据的增加而扩展。
- 可用性:知识图谱的能力,能够满足不同用户的需求。
- 性能:知识图谱的查询和推理能力。
Q: 如何保护知识图谱的隐私? A: 知识图谱的隐私保护可以通过以下几种方法进行:
- 数据脱敏:对知识图谱中的敏感信息进行处理,以便保护用户的隐私。
- 访问控制:对知识图谱的访问进行控制,以便限制不同用户的访问权限。
- 数据加密:对知识图谱中的数据进行加密,以便保护数据的安全性。
- 数据擦除:对知识图谱中的数据进行擦除,以便删除不再需要的数据。
- 数据脱敏:对知识图谱中的敏感信息进行处理,以便保护用户的隐私。
摘要
本文介绍了自然语言处理(NLP)的基本概念和技术,特别关注了语义分析和知识图谱构建。我们通过了解了这些技术的原理和算法,并且通过一个具体的例子来说明其实现过程。最后,我们讨论了未来的发展趋势和挑战,以及一些常见问题的解答。我们希望这篇文章能够帮助读者更好地理解和应用语义分析和知识图谱构建技术。






