

基准
- 本博客基于如下视频:
- 发票抬头信息抽取之环境搭建 - 基于飞浆开源项目
- 发票抬头信息抽取之数据标准+模型训练 - 基于飞浆开源项目
步骤
1、准备工作
- 下载python:【Python】Windows:Python 3.9.2 下载和安装(建议3.9)
- 升级pip:CMD窗口运行python -m pip install --upgrade pip
- 安装飞浆模型:CMD窗口运行python -m pip install paddlepaddle==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
2、使用默认模型尝试识别程序
2.1、创建项目,目录结构如下(model下为空文件夹)
2.2、uie_v1.py代码
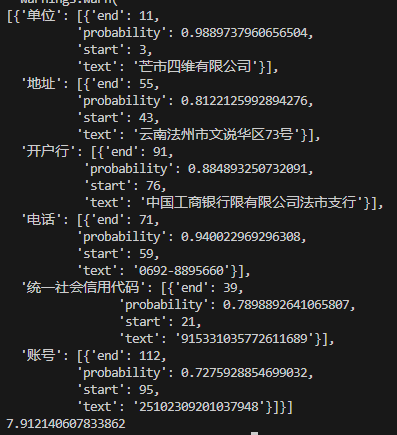
import time t1=time.time() from pprint import pprint from paddlenlp import Taskflow schema = ['单位', '统一社会信用代码', '地址', '电话', '开户行', '账号'] # Define the schema for entity extraction ie = Taskflow('information_extraction', schema=schema, task_path='./model') #注意这里的地址可改 pprint(ie("单位:芒市四维有限公司 统一社会信用代码:915331035772611689 地址:云南法州市文说华区73号 电话:0692-8895660 开户行:中国工商银行限有限公司法市支行 账号:25102309201037948")) # Better print results using pprint t2=time.time() print(t2-t1)2.3、识别结果
3、训练模型
3.1、准备训练数据(123.txt)
1、云南科禹建设管理咨询有限公司德宏分公司91533100MA6K35YB2C公司地址:云南省德宏州艺市白象街东侧(翠堤晓镇)06922212326开户行及:中国农业银行股份有限公司芒市支行账号:24139801040014503 2、单位:芒市四维有限公司统一社会信用代码:915331035772611689地址:云南法州市文说华区73号电活0692-8895660开户行:中国工商银行限有限公司法市支行账号:25102309201037948 3、单位名称税号注册:电话号码开户银行银行账号湖博康贝医疗器城有限公司913703047292704866博山区城东街道办事处良生三泉山 0533-4290668中国银行博山 支行206505422178 4、2020年09月28日芒市善彻金属结构制/部92533103MA6POKQ7X4云南宏州风平流门村民小13759201612 王云南艺市农村商业银行股份有限公司核支行55000156432370129 5、2020年10月21日市盘达汽车像理厂92533103MA6M4DKF5A云南省宏州艺市寨村(环东路旁)1598789707 李玉花中国农业银行股份有限公司德法青年分理处623190001810146
3.2、数据标注
- 本地安装并启动doccano,参考两篇文档:
- PaddleNLP信息抽取技术重磅升级!开放域信息抽取来了!三行代码用起来~
- 文本标注工具doccano的安装与使用
- 注意:使用python3.9(不要3.10,会报错)在cmd窗口创建虚拟环境,然后再下载和启动doccano
- 进入doccano:输入网址http://127.0.0.1:8000/进入doccano,输入自己设置的账号密码
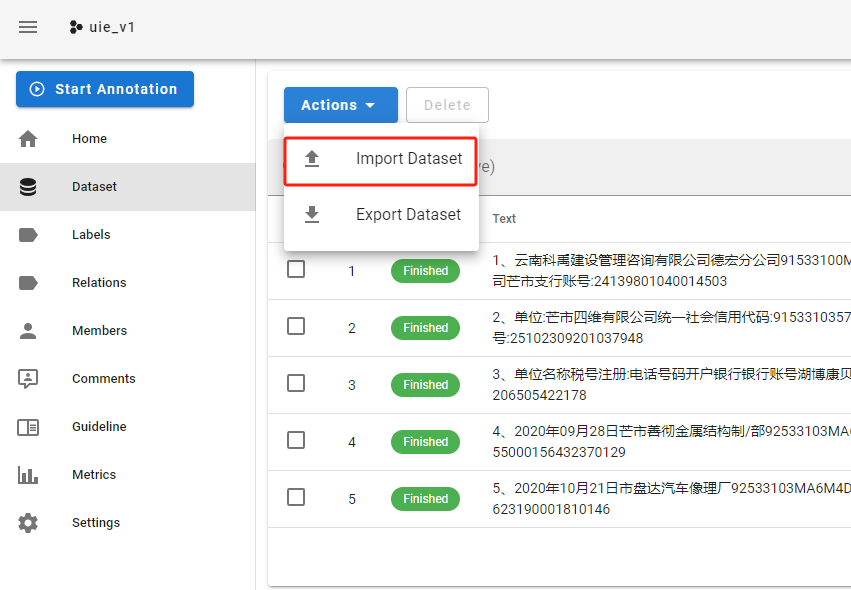
- 上传数据集:123.txt就是上面的训练数据

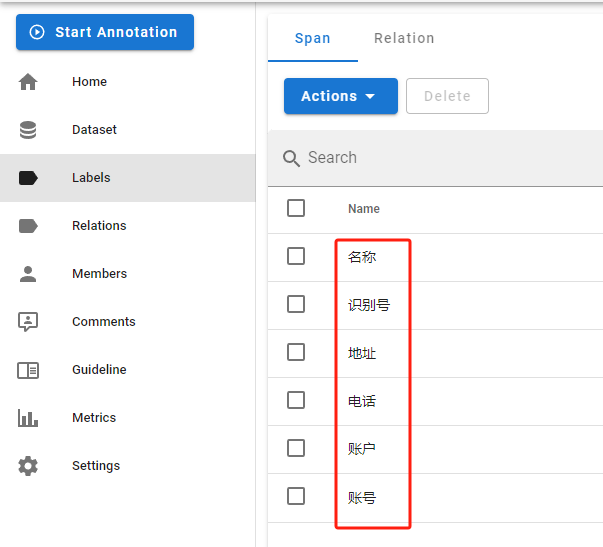
- 添加标签
- 在数据集中进行数据标注

- 导出数据:选择jsonl,并勾选选项
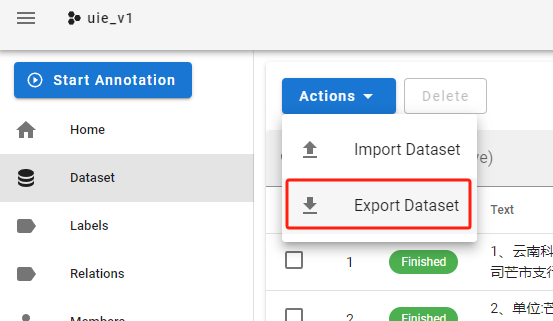
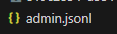
3.3、模型训练
- 新建项目:在官网上登录,新建如下项目并启动
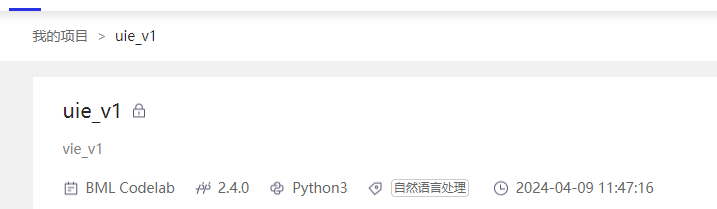
- 准备工作:
- 更新pip:pip install --upgrade pip
- 更新protobuf:pip install protobuf==3.19.0
- 更新PaddleNLP:pip install paddlenlp==2.5.2(不要升级到最新的,不兼容)
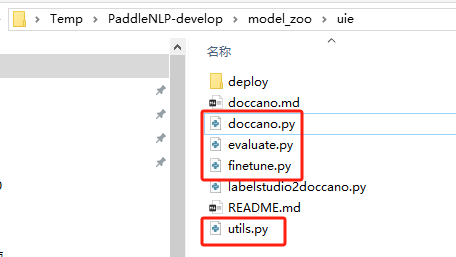
- 放入文件:从官方源代码中摘取如下文件放到根目录,然后将标注后的jsonl文件放入data文件夹中,最终目录如下
- 官方项目开放源代码:UIE模型
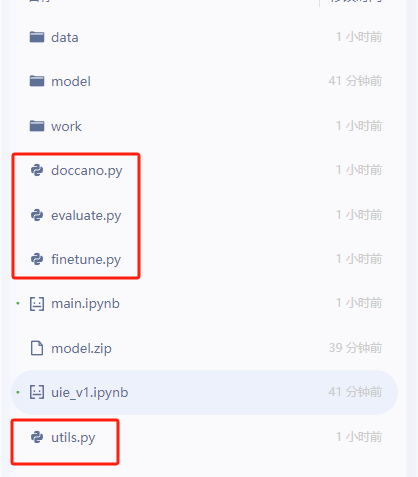
- 数据转换:执行后会在./data目录下生成训练/验证/测试集文件
!python doccano.py \ --doccano_file ./data/admin.jsonl \ --task_type ext \ --save_dir ./data \ --splits 0.8 0.2 0 \ --schema_lang ch- 模型微调:使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至./model中
- 如果是基于已有模型进行微调,修改model_name_or_path后面的参数,修改为模型地址./model
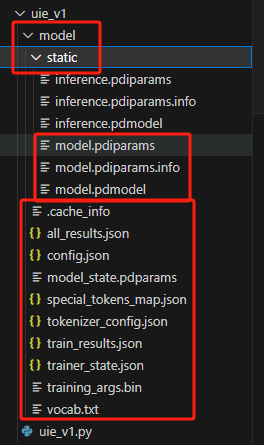
!python finetune.py \ --device gpu \ --logging_steps 10 \ --save_steps 100 \ --eval_steps 100 \ --seed 42 \ --model_name_or_path uie-base \ --output_dir ./model \ --train_path data/train.txt \ --dev_path data/dev.txt \ --max_seq_length 512 \ --per_device_eval_batch_size 6 \ --per_device_train_batch_size 6 \ --num_train_epochs 20 \ --learning_rate 1e-5 \ --label_names "start_positions" "end_positions" \ --do_train \ --do_eval \ --do_export \ --export_model_dir ./model \ --overwrite_output_dir \ --disable_tqdm True \ --metric_for_best_model eval_f1 \ --load_best_model_at_end True \ --save_total_limit 1- 取出模型文件,替换默认的模型(注:有三个文件在static文件夹里)
3.4 验证模型
- 依据训练好的高精度模型进行识别,执行如下脚本
#uie_v1.py import time t1=time.time() from pprint import pprint from paddlenlp import Taskflow schema = ['名称', '识别号', '地址', '电话', '账户', '账号'] # Define the schema for entity extraction ie = Taskflow('information_extraction', schema=schema, task_path='./model') pprint(ie("单位:芒市四维有限公司 统一社会信用代码:915331035772611689 地址:云南法州市文说华区73号 电话:0692-8895660 开户行:中国工商银行限有限公司法市支行 账号:25102309201037948")) # Better print results using pprint t2=time.time() print(t2-t1)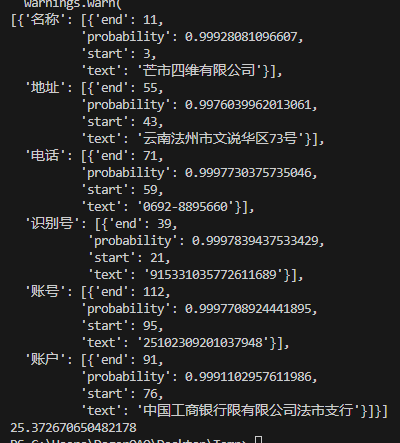
注意事项:
- ‘doccano’ 不是内部或外部命令,也不是可运行的程序或批处理文件:网上没有找到相关的原因,我费了半天劲发现可能是python版本的问题,用本地3.10安装doccano或者用3.10版本创建虚拟环境安装doccano会报上述问题,用3.9创建虚拟环境就可以
- 报错如下:执行pip install protobuf==3.19.0解决,若还报错,pip install --upgrade pip
TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: - Downgrade the protobuf package to 3.20.x or lower. - Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
- 报错如下:执行pip install paddlenlp==2.5.2
[paddle]ModuleNotFoundError: No module named ‘paddle.nn.layer.layers
- 如果第二次打开飞桨的项目环境报错,重新执行那三次更新操作即可
参考:
- ModuleNotFoundError: No module named ‘paddle.nn.layer.layers‘
- 解决:TypeError: Descriptors cannot not be created directly
- 文本标注工具doccano的安装与使用
- 通用信息抽取 UIE(Universal Information Extraction)
- PaddleNLP信息抽取技术重磅升级!开放域信息抽取来了!三行代码用起来~
- Windows 下的 PIP 安装
- 发票抬头信息抽取之环境搭建 - 基于飞浆开源项目
- 发票抬头信息抽取之数据标准+模型训练 - 基于飞浆开源项目
- 如果第二次打开飞桨的项目环境报错,重新执行那三次更新操作即可
- 报错如下:执行pip install paddlenlp==2.5.2
- 依据训练好的高精度模型进行识别,执行如下脚本
- 取出模型文件,替换默认的模型(注:有三个文件在static文件夹里)
- 如果是基于已有模型进行微调,修改model_name_or_path后面的参数,修改为模型地址./model
- 模型微调:使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至./model中
- 新建项目:在官网上登录,新建如下项目并启动
- 导出数据:选择jsonl,并勾选选项
- 本地安装并启动doccano,参考两篇文档:







