

《当人工智能遇上安全》系列将详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
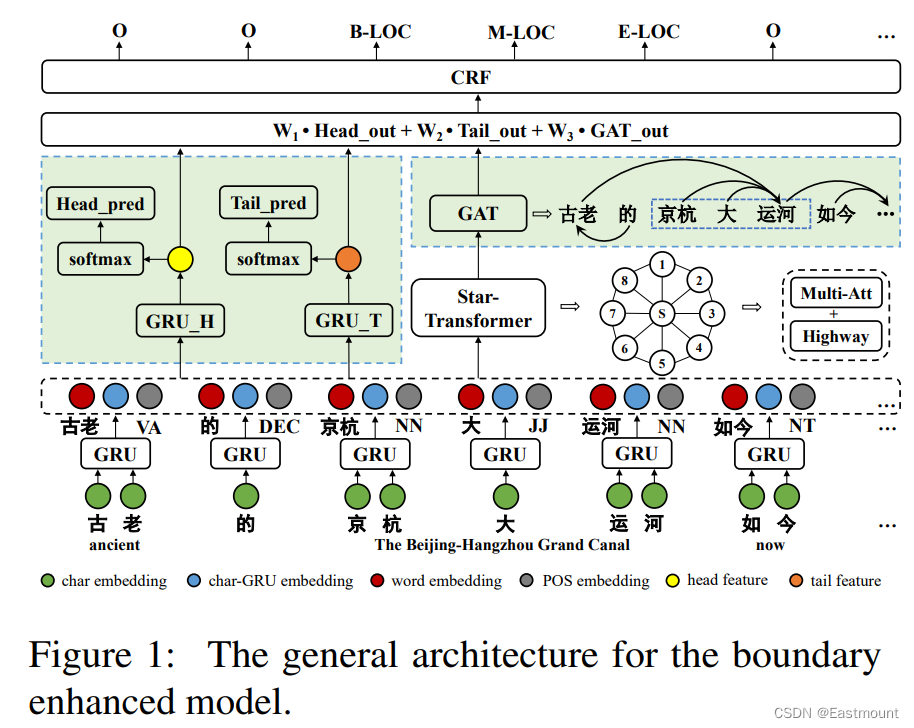
前文讲解如何实现威胁情报实体识别,利用BiLSTM-CRF算法实现对ATT&CK相关的技战术实体进行提取,是安全知识图谱构建的重要支撑。这篇文章将详细结合如何利用keras和tensorflow构建基于注意力机制的CNN-BiLSTM-ATT-CRF模型,并实现中文实体识别研究,同时对注意力机制构建常见错误进行探讨。基础性文章,希望对您有帮助,如果存在错误或不足之处,还请海涵。且看且珍惜!
- 版本信息:python 3.7,tf 2.2.0,keras 2.3.1,bert4keras 0.11.5,keras-contrib=2.0.8
文章目录
- 一.ATT&CK数据采集
- 二.数据预处理
- 三.安装环境
- 1.安装keras-contrib
- 2.安装keras
- 四.CNN-BiLSTM-ATT-CRF模型构建
- 五.完整代码及实验结果
- 六.Attention构建及兼容问题
- 七.总结
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
前文推荐:
- [当人工智能遇上安全] 1.人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [当人工智能遇上安全] 2.清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [当人工智能遇上安全] 3.安全领域中的机器学习及机器学习恶意请求识别案例分享
- [当人工智能遇上安全] 4.基于机器学习的恶意代码检测技术详解
- [当人工智能遇上安全] 5.基于机器学习算法的主机恶意代码识别研究
- [当人工智能遇上安全] 6.基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
- [当人工智能遇上安全] 7.基于机器学习的安全数据集总结
- [当人工智能遇上安全] 8.基于API序列和机器学习的恶意家族分类实例详解
- [当人工智能遇上安全] 9.基于API序列和深度学习的恶意家族分类实例详解
- [当人工智能遇上安全] 10.威胁情报实体识别之基于BiLSTM-CRF的实体识别万字详解
- [当人工智能遇上安全] 11.威胁情报实体识别 (2)基于BiGRU-CRF的中文实体识别万字详解
- [当人工智能遇上安全] 12.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
作者的github资源:
- https://github.com/eastmountyxz/When-AI-meet-Security
- https://github.com/eastmountyxz/AI-Security-Paper
- https://github.com/eastmountyxz/AI-for-Keras
一.ATT&CK数据采集
了解威胁情报的同学,应该都熟悉Mitre的ATT&CK网站,前文已介绍如何采集该网站APT组织的攻击技战术数据。网址如下:
- http://attack.mitre.org
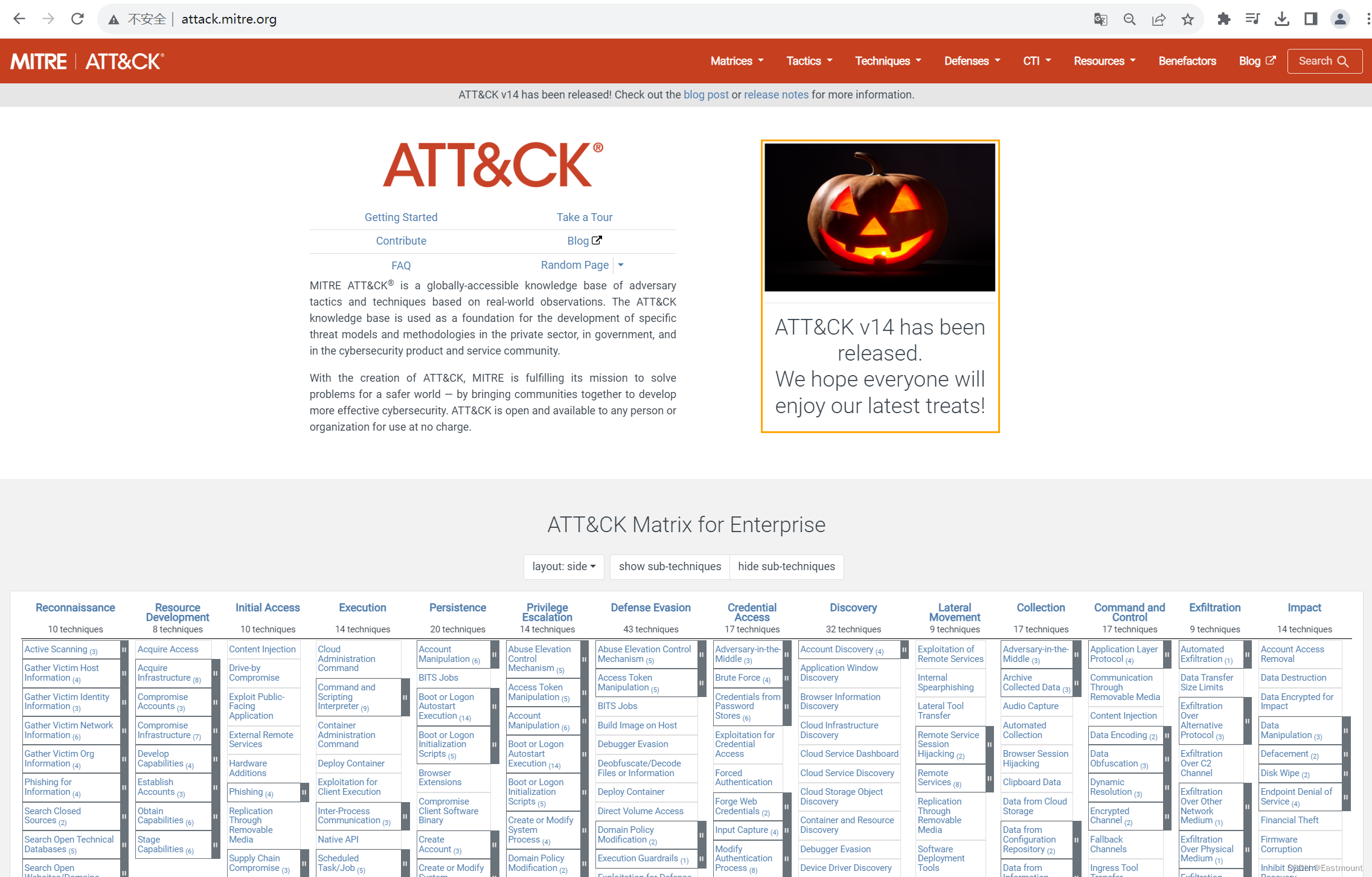
第一步,通过ATT&CK网站源码分析定位APT组织名称,并进行系统采集。
安装BeautifulSoup扩展包,该部分代码如下所示:
01-get-aptentity.py
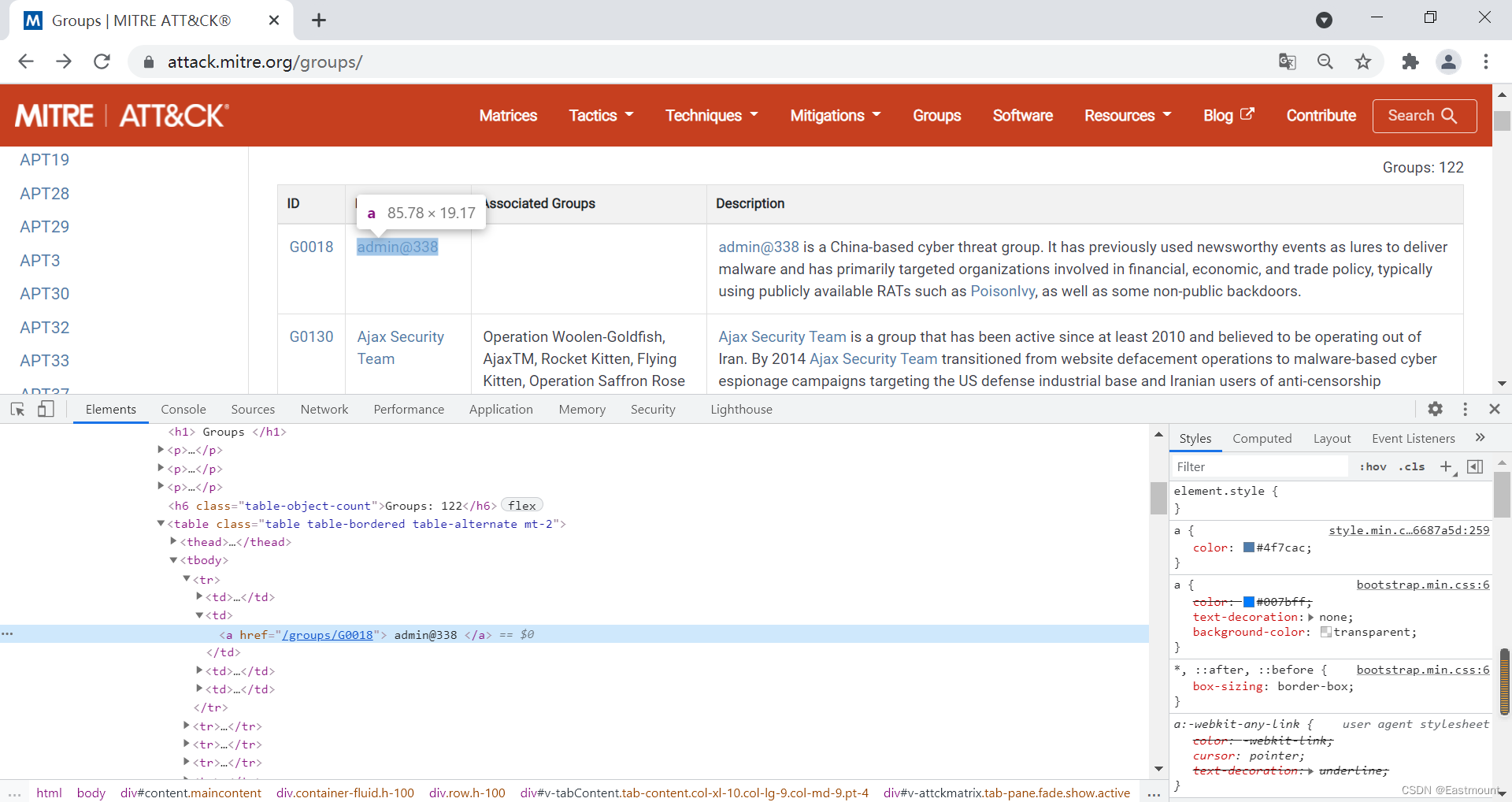
#encoding:utf-8 #By:Eastmount CSDN import re import requests from lxml import etree from bs4 import BeautifulSoup import urllib.request #------------------------------------------------------------------------------------------- #获取APT组织名称及链接 #设置浏览器代理,它是一个字典 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = 'https://attack.mitre.org/groups/' #向服务器发出请求 r = requests.get(url = url, headers = headers).text #解析DOM树结构 html_etree = etree.HTML(r) names = html_etree.xpath('//*[@]/tbody/tr/td[2]/a/text()') print (names) print(len(names),names[0]) filename = [] for name in names: filename.append(name.strip()) print(filename) #链接 urls = html_etree.xpath('//*[@]/tbody/tr/td[2]/a/@href') print(urls) print(len(urls), urls[0]) print("\n")此时输出结果如下图所示,包括APT组织名称及对应的URL网址。
第二步,访问APT组织对应的URL,采集详细信息(正文描述)。
第三步,采集对应的技战术TTPs信息,其源码定位如下图所示。
第四步,编写代码完成威胁情报数据采集。01-spider-mitre.py 完整代码如下:
#encoding:utf-8 #By:Eastmount CSDN import re import requests from lxml import etree from bs4 import BeautifulSoup import urllib.request #------------------------------------------------------------------------------------------- #获取APT组织名称及链接 #设置浏览器代理,它是一个字典 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = 'https://attack.mitre.org/groups/' #向服务器发出请求 r = requests.get(url = url, headers = headers).text #解析DOM树结构 html_etree = etree.HTML(r) names = html_etree.xpath('//*[@]/tbody/tr/td[2]/a/text()') print (names) print(len(names),names[0]) #链接 urls = html_etree.xpath('//*[@]/tbody/tr/td[2]/a/@href') print(urls) print(len(urls), urls[0]) print("\n") #------------------------------------------------------------------------------------------- #获取详细信息 k = 0 while k"class":"description-body"}): #contents = tag.find("p").get_text() contents = tag.find_all("p") for con in contents: content += con.get_text().strip() + "###\n" #标记句子结束(第二部分分句用) #print(content) #获取表格中的技术信息 for tag in soup.find_all(attrs={"class":"table techniques-used table-bordered mt-2"}): contents = tag.find("tbody").find_all("tr") for con in contents: value = con.find("p").get_text() #存在4列或5列 故获取p值 #print(value) content += value.strip() + "###\n" #标记句子结束(第二部分分句用) #删除内容中的参考文献括号 [n] result = re.sub(u"\\[.*?]", "", content) print(result) #文件写入 filename = "Mitre//" + filename print(filename) f = open(filename, "w", encoding="utf-8") f.write(result) f.close() k += 1 'O': 0, 'S-LOC': 1, 'B-LOC': 2, 'I-LOC': 3, 'E-LOC': 4, 'S-PER': 5, 'B-PER': 6, 'I-PER': 7, 'E-PER': 8, 'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12 } print(label2idx) #{'S-LOC': 0, 'B-PER': 1, 'I-PER': 2, ...., 'I-TIM': 11, 'I-LOC': 12} #索引和BIO标签对应 idx2label = {idx: label for label, idx in label2idx.items()} print(idx2label) #{0: 'S-LOC', 1: 'B-PER', 2: 'I-PER', ...., 11: 'I-TIM', 12: 'I-LOC'} #读取字符词典文件 with open(char_vocab_path, "r", encoding="utf8") as fo: char_vocabs = [line.strip() for line in fo] char_vocabs = special_words + char_vocabs print(char_vocabs) #['
- http://attack.mitre.org






