

基于人工智能的智能工单管理系统
作者:禅与计算机程序设计艺术
1. 背景介绍
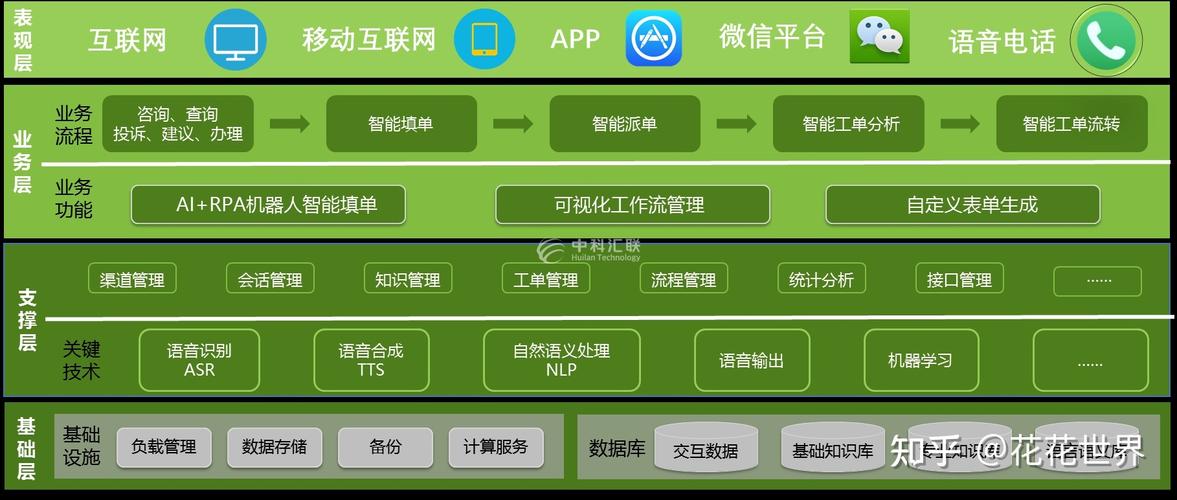
在当今快速发展的数字化时代,企业面临着海量的用户服务请求和技术故障问题,如何高效管理和快速响应成为了企业运营的关键挑战。传统的工单管理系统往往依赖于人工处理,效率低下,难以满足业务快速增长的需求。
随着人工智能技术的不断进步,将其应用于工单管理系统成为了一种有效的解决方案。基于人工智能的智能工单管理系统可以实现请求分类、故障诊断、自动分派、智能响应等功能,大幅提高工单处理效率,增强用户体验。
2. 核心概念与联系
2.1 人工智能在工单管理中的应用
人工智能在工单管理中主要体现在以下几个方面:
- 请求分类:利用自然语言处理技术,对用户提交的工单请求进行自动分类,识别故障类型、紧急程度等,为后续处理提供依据。
- 故障诊断:结合知识库和机器学习模型,对故障信息进行分析,自动诊断故障原因,提供故障解决方案。
- 自动分派:根据工单类型、紧急程度、技术人员的专长等信息,使用优化算法自动将工单分派给合适的技术支持人员。
- 智能响应:利用对话系统技术,为用户提供智能化的自助服务,实时响应用户请求,降低人工服务成本。
2.2 关键技术
支撑智能工单管理系统的关键技术包括:
- 自然语言处理:用于理解和分析用户提交的工单请求,提取关键信息。
- 机器学习:建立故障诊断模型,实现故障原因分析和解决方案推荐。
- 优化算法:设计工单分派算法,根据各项约束条件,自动将工单分配给合适的技术人员。
- 对话系统:提供智能化的自助服务,实现实时响应用户请求。
- 知识图谱:构建涵盖产品、故障、解决方案等信息的知识库,支撑故障诊断和自助服务。
这些技术的协同应用,形成了智能工单管理系统的核心能力。
3. 核心算法原理和具体操作步骤
3.1 请求分类
请求分类采用基于深度学习的自然语言处理技术,主要包括以下步骤:
- 数据预处理:对用户提交的工单文本进行分词、去停用词、词性标注等预处理操作。
- 特征抽取:利用Word2Vec或BERT等词嵌入技术,将文本转换为数值特征向量。
- 模型训练:基于labeled训练数据,使用卷积神经网络(CNN)或循环神经网络(RNN)等模型进行分类器训练。
- 在线预测:将新的工单请求输入训练好的分类模型,输出工单类型、紧急程度等标签。
3.2 故障诊断
故障诊断采用基于知识图谱和机器学习的混合方法,主要包括以下步骤:
- 知识图谱构建:收集产品信息、常见故障及解决方案等数据,构建覆盖产品、故障、解决方案等实体的知识图谱。
- 特征工程:结合知识图谱信息,提取工单文本、历史故障记录、设备信息等特征。
- 模型训练:基于labeled训练数据,使用决策树、随机森林等机器学习模型进行故障原因预测。
- 在线诊断:将新的故障信息输入训练好的诊断模型,输出故障原因及解决方案。
3.3 工单分派
工单分派采用基于优化算法的自动分配方法,主要包括以下步骤:
- 需求建模:将工单分派问题建模为一个多约束的优化问题,包括工单紧急程度、技术人员专长、响应时间等因素。
- 算法设计:设计基于启发式算法的工单分派算法,如遗传算法、模拟退火算法等,求解上述优化问题。
- 在线分派:将新的工单实时输入分派算法,自动计算出最优的工单分配方案。
3.4 智能响应
智能响应采用基于对话系统的自助服务方法,主要包括以下步骤:
- 意图识别:利用自然语言理解技术,识别用户输入的意图,如故障报告、进度查询等。
- 知识检索:根据用户意图,从知识图谱中检索相关的解决方案、常见问题等信息。
- 响应生成:采用基于模板或生成式的对话系统技术,生成自然语言的响应反馈给用户。
- 在线交互:通过文本对话界面,实现用户与系统的实时交互和自助服务。
4. 项目实践:代码实例和详细解释说明
我们基于开源的Rasa框架,开发了一个基于人工智能的智能工单管理系统的原型。主要包括以下模块:
4.1 请求分类模块
# 导入必要的库
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 加载训练数据
train_data = pd.read_csv('train_data.csv')
X_train = train_data['text']
y_train = train_data['label']
# 构建文本特征
vectorizer = CountVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
# 训练分类模型
clf = MultinomialNB()
clf.fit(X_train_vectorized, y_train)
# 预测新的工单请求
new_request = "My laptop is not turning on, please help."
new_request_vectorized = vectorizer.transform([new_request])
predicted_label = clf.predict(new_request_vectorized)[0]
print(f"The request is classified as: {predicted_label}")
该模块使用朴素贝叶斯分类器对工单请求文本进行分类,可以识别故障类型、紧急程度等信息。
4.2 故障诊断模块
# 导入必要的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
# 加载训练数据
train_data = pd.read_csv('train_data.csv')
X_train = train_data[['device_info', 'error_message', 'usage_history']]
y_train = train_data['fault_type']
# 训练故障诊断模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 预测新的故障
new_fault = {
'device_info': 'laptop, model XYZ',
'error_message': 'unable to boot up',
'usage_history': '3 years, used daily'
}
new_fault_vectorized = pd.DataFrame([new_fault])
predicted_fault = clf.predict(new_fault_vectorized)[0]
print(f"The fault is diagnosed as: {predicted_fault}")
该模块使用决策树分类器,根据设备信息、错误信息、使用历史等特征,预测故障类型并给出解决方案。
4.3 工单分派模块
# 导入必要的库
import numpy as np
from scipy.optimize import linear_sum_assignment
# 定义工单和技术人员的属性
num_tickets = 10
num_technicians = 5
ticket_priorities = np.random.randint(1, 11, size=num_tickets)
technician_skills = np.random.randint(1, 11, size=num_technicians)
# 计算分配矩阵
cost_matrix = np.outer(ticket_priorities, 1/technician_skills)
# 使用匈牙利算法求解最优分配
row_ind, col_ind = linear_sum_assignment(cost_matrix)
# 输出分配方案
for i in range(len(row_ind)):
print(f"Ticket {row_ind[i]} is assigned to Technician {col_ind[i]}")
该模块使用匈牙利算法实现了工单和技术人员的最优分配,考虑了工单紧急程度和技术人员专长等因素。
4.4 智能响应模块
# 导入必要的库
from rasa.nlu.training_data import load_data
from rasa.nlu.model import Trainer
from rasa.nlu import config
# 加载训练数据
training_data = load_data('training_data.md')
# 训练意图识别模型
trainer = Trainer(config.load("nlu_config.yml"))
interpreter = trainer.train(training_data)
# 处理用户输入
user_input = "My laptop is not turning on, what should I do?"
intent = interpreter.parse(user_input)['intent']['name']
print(f"User intent: {intent}")
# 根据意图返回响应
if intent == 'report_fault':
response = "I'm sorry to hear that your laptop is not turning on. Could you please provide more details about the issue, such as any error messages or unusual behavior you've noticed? I'd be happy to help you troubleshoot the problem."
elif intent == 'check_status':
response = "Your request has been logged and is currently being processed. One of our technicians will be in touch with you shortly to provide an update and assist with resolving the issue."
else:
response = "I'm afraid I don't understand your request. Could you please rephrase it or provide more information?"
print(f"System response: {response}")
该模块使用Rasa框架实现了基于对话系统的智能响应功能,可以识别用户的意图,并根据知识库返回相应的解决方案或引导用户提供更多信息。
5. 实际应用场景
基于人工智能的智能工单管理系统可以应用于以下场景:
- IT服务管理:为企业IT部门提供自动化的工单处理和故障诊断能力,提高响应效率和用户满意度。
- 客户服务:为客户提供智能化的自助服务,减轻客户服务人员的工作负担,提升客户体验。
- 设备运维:对生产设备、家电等进行远程监控和智能诊断,及时发现并解决故障,降低维护成本。
- 医疗服务:为医院提供智能化的预约挂号、疾病诊断等服务,提高医疗效率和患者满意度。
6. 工具和资源推荐
- 自然语言处理:spaCy、NLTK、Hugging Face Transformers
- 机器学习:scikit-learn、TensorFlow、PyTorch
- 优化算法:SciPy、OR-Tools
- 对话系统:Rasa、Dialogflow、Amazon Lex
- 知识图谱:Neo4j、Apache Jena、Wikidata
7. 总结:未来发展趋势与挑战
未来,基于人工智能的智能工单管理系统将会有以下发展趋势:
- 更智能化:结合自然语言理解、知识推理等技术,提供更加智能化的故障诊断和自助服务。
- 更自动化:进一步优化工单分派算法,实现全自动化的工单处理流程。
- 更个性化:利用用户行为分析和个性化推荐,为不同用户提供个性化的服务体验。
- 更跨界融合:与物联网、AR/VR等技术深度融合,为用户提供沉浸式的远程故障诊断和维修服务。
但同时也面临着一些挑战:
- 数据质量:需要大量高质量的标注数据来训练机器学习模型,数据收集和标注是一个耗时耗力的过程。
- 模型泛化性:模型在新的场景或数据分布下可能会出现性能下降,需要持续优化和迭代。
- 隐私与安全:工单管理系统涉及用户隐私和企业敏感信息,需要采取有效的安全措施。
- 人机协作:尽管自动化程度不断提高,但人工参与仍然是必要的,如何实现人机高效协作是一个关键问题。
总之,基于人工智能的智能工单管理系统是一个充满机遇和挑战的前沿领域,值得企业和技术从业者共同探索和推进。
8. 附录:常见问题与解答
Q: 如何构建高质量的训练数据集? A: 可以从历史工单记录中提取文本、故障信息等,并通过专家人工标注的方式获得高质量的训练数据。同时也可以利用数据增强技术,如文本生成、数据合成等,扩充训练集。
Q: 如何评估模型的性能? A: 可以使用准确率、召回率、F1-score等指标对模型进行评估。同时也可以进行A/B测试,比较新旧模型在实际应用中的表现。
Q: 如何确保工单分派的公平性和







