

目录
前言
开始
Keras工作流程
构建Keras模型的不同方法
序贯模型
函数式API
模型子类化
混合使用不同的组件
用正确的工具完成工作
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
我们开始一个全新的系列——Keras API。
通过这个系列的文章,您将了解到下面这几部分内容:
1)构建Keras模型的3种方法,即序贯模型、函数式API和模型子类化
2)使用Keras内置的训练循环和评估循环
3) 使用Keras回调函数来自定义训练
4) 使用TensorBoard监控训练指标和评估指标
5) 从头开始编写训练循环和评估循环

前言
TensorFlow的Keras API是一个高层次的神经网络API,用于构建和训练深度学习模型。Keras是一个开源的深度学习库,最初是作为一个独立的项目开发的,后来被集成到TensorFlow中。
Keras API提供了一组高级的函数和类,使得构建神经网络模型变得非常简单和直观。
使用Keras,可以通过几行代码定义一个神经网络模型,并使用各种模型层、激活函数和优化器来配置模型。
Keras API的设计目标是易用性和灵活性。
它提供了丰富的模型层,包括全连接层、卷积层、池化层、循环层等。此外,Keras还提供了各种激活函数、损失函数和优化器的选择。
用户可以根据自己的需求选择适合的模型层和配置参数。
Keras API还提供了方便的功能,使得模型的训练和评估变得非常简单。
用户可以使用fit()函数来训练模型,并使用evaluate()函数来评估模型在测试数据上的性能。Keras还支持自定义回调函数,可以在训练过程中执行各种操作,如保存模型、动态调整学习率等。
总之,TensorFlow的Keras API提供了一个简单而强大的工具来构建和训练深度学习模型。它的易用性和灵活性使得深度学习变得更加容易上手,并且可以满足各种复杂的需求。
开始
通过作者政安晨以前的文章,相信聪明如您已经掌握了一些Keras使用经验,已经熟悉序贯模型、Dense层,以及用于训练、评估和推断的内置API——compile()、fit()、evaluate()和predict()。
您还学习了如何通过继承Layer类来创建自定义层,以及如何使用TensorFlow的GradientTape来逐步实现一个训练循环。
在开始咱们这篇演绎之前,咱们先准备好环境,可以参考我在这篇文章里提到的搭建环境的部分:
政安晨的机器学习笔记——跟着演练快速理解TensorFlow(适合新手入门)![]() https://blog.csdn.net/snowdenkeke/article/details/135950931这篇文章里的演绎,我将在Windows系统中构建的Anaconda虚拟环境中的TensorFlow中进行。
https://blog.csdn.net/snowdenkeke/article/details/135950931这篇文章里的演绎,我将在Windows系统中构建的Anaconda虚拟环境中的TensorFlow中进行。

Keras工作流程
Keras API的设计原则是渐进式呈现复杂性(progressive disclosure of complexity):
易于上手,同时又可以处理非常复杂的用例,只需逐步渐进式学习。
简单的工作流程应该简单易懂,同时还有高级的工作流程:无论你的问题多么罕见、多么复杂,应该都有一条清晰的解决路径。这条路径是建立在简单工作流程的基础之上的。也就是说,你从初学者成长为专家,可以一直使用相同的工具,只是使用方式不同。
因此,Keras没有唯一“正确”的使用方式。
相反,Keras提供了一系列工作流程,既有非常简单的工作流程,也有非常灵活的工作流程。
构建和训练Keras模型都有许多种方法,可以满足不同的需求。
所有这些工作流程都基于共享API,比如Layer和Model,所以任何一种工作流程的组件都可以用于其他工作流程,它们之间可以互相通信。
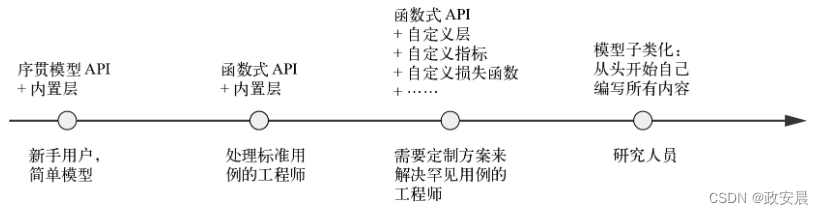
构建Keras模型的不同方法
在Keras中,构建模型可以使用以下3个API,如下图所示:
序贯模型(sequential model):这是最容易理解的API。它本质上是Python列表,仅限于层的简单堆叠。
函数式API(functional API):它专注于类似图的模型结构。它在可用性和灵活性之间找到了很好的平衡点,因此是构建模型最常用的API。
模型子类化(model subclassing):它是一个底层选项,你可以从头开始自己编写所有内容。如果你想控制每一个小细节,那么它是理想的选择。但是这样就无法使用Keras内置的许多特性,而且更容易犯错误。
(对于构建模型,渐进式呈现复杂性)
序贯模型
要构建Keras模型,最简单的方法就是使用序贯模型(Sequential类),代码如下所示:
先看一下Sequential类:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax")
])
请注意,还可以使用add()方法逐步构建相同的模型,代码如下所示:
(它类似于Python列表的append()方法)
逐步构建序贯模型:
model = keras.Sequential() model.add(layers.Dense(64, activation="relu")) model.add(layers.Dense(10, activation="softmax"))
只有在第一次调用层时,层才会被构建(创建层权重)。这是因为层权重的形状取决于输入形状,只有知道输入形状之后才能创建权重。
因此,前面的序贯模型是没有权重的,演绎如下所示:
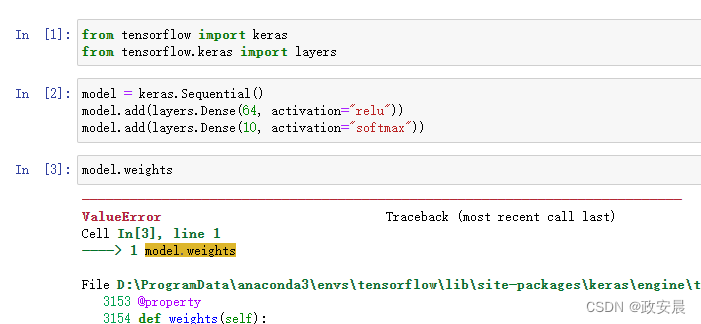
(这时模型还没有完成构建)
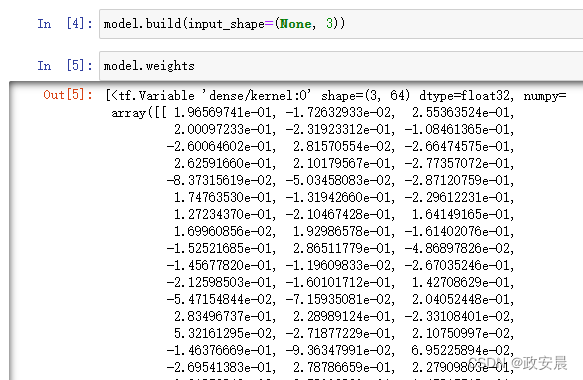
只有在数据上调用模型,或者调用模型的build()方法并给定输入形状时,模型才具有权重,代码如下所示(通过第一次调用模型来完成构建):
# 现在可以检索模型权重 model.build(input_shape=(None, 3)) # 调用模型的build()方法。模型样本形状应该是(3,)。输入形状中的None表示批量可以是任意大小 model.weights
演绎如下:
模型构建完成之后,可以用summary()方法显示模型内容,这对调试很有帮助,演绎如下:

可以看到,这个模型刚好被命名为sequential_1。你可以对Keras中的所有对象命名,包括每个模型和每一层,代码如下所示(利用name参数命名模型和层):
model = keras.Sequential(name="my_example_model") model.add(layers.Dense(64, activation="relu", name="my_first_layer")) model.add(layers.Dense(10, activation="softmax", name="my_last_layer")) model.build((None, 3)) model.summary()
演绎如下:
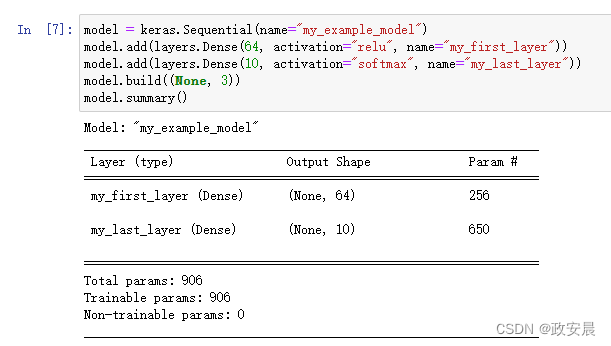
逐步构建序贯模型时,每添加一层就打印出当前模型的概述信息,这是非常有用的。但在模型构建完成之前是无法打印概述信息的。
有一种方法可以实时构建序贯模型:只需提前声明模型的输入形状。你可以通过Input类来做到这一点,代码如下所示(提前声明模型的输入形状):
model = keras.Sequential() # 利用Input声明输入形状。请注意,shape参数应该是单个样本的形状,而不是批量的形状 model.add(keras.Input(shape=(3,))) model.add(layers.Dense(64, activation="relu"))
现在你可以使用summary()来跟踪观察,添加更多层之后模型的输出形状是如何变化的,代码如下(使用summary()跟踪模型输出形状的变化):

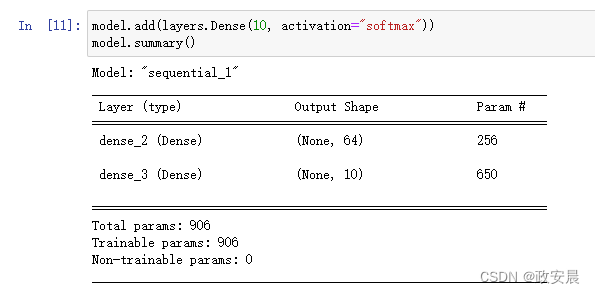
这是一种常用的调试工作流程,用于处理那些对输入进行复杂变换的层。
函数式API
序贯模型易于使用,但适用范围非常有限:它只能表示具有单一输入和单一输出的模型,按顺序逐层进行处理。
我们在实践中经常会遇到其他类型的模型,比如多输入模型(如图像及其元数据)、多输出模型(预测数据的不同方面)或具有非线性拓扑结构的模型。
在这种情况下,你可以使用函数式API构建模型。
你在现实世界中遇到的大多数Keras模型属于这种类型。它很强大,也很有趣,就像拼乐高积木一样。
简单示例
我们先来看一个简单的示例,即上面提到的两层堆叠。这个例子也可以用函数式API来实现,代码如下所示:
(带有两个Dense层的简单函数式模型)
inputs = keras.Input(shape=(3,), name="my_input") features = layers.Dense(64, activation="relu")(inputs) outputs = layers.Dense(10, activation="softmax")(features) model = keras.Model(inputs=inputs, outputs=outputs)
我们来逐行解释一下。
首先声明一个Input(注意,你也可以对输入对象命名,就像对其他对象一样)。
inputs = keras.Input(shape=(3,), name="my_input")
这个inputs对象保存了关于模型将处理的数据的形状和数据类型的信息。
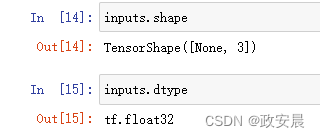
对于这个模型处理的批量,每个样本的形状为(3,),每个批量的样本数量是可变的(代码中的批量大小为None),数据批量的数据类型为float32 float32
我们将这样的对象叫作符号张量(symbolic tensor)。它不包含任何实际数据,但编码了调用模型时实际数据张量的详细信息。它代表的是未来的数据张量。
接下来,我们创建了一个层,并在输入上调用该层。
features = layers.Dense(64, activation="relu")(inputs)
所有Keras层都可以在真实的数据张量与这种符号张量上调用。对于后一种情况,层返回的是一个新的符号张量,其中包含更新后的形状和数据类型信息。
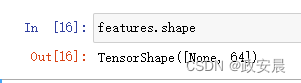
得到最终输出之后,我们在Model构造函数中指定输入和输出,将模型实例化。
outputs = layers.Dense(10, activation="softmax")(features) model = keras.Model(inputs=inputs, outputs=outputs)
演绎如下:

多输入、多输出模型
与上述简单模型不同,大多数深度学习模型看起来不像列表,而像图。比如,模型可能有多个输入或多个输出。正是对于这种模型,函数式API才真正表现出色。
假设你要构建一个系统,按优先级对客户支持工单进行排序,并将工单转给相应的部门。
这个模型有3个输入:
工单标题(文本输入)
工单的文本正文(文本输入)
用户添加的标签(分类输入,假定为one-hot编码)
我们可以将文本输入编码为由1和0组成的数组,数组大小为vocabulary_size
模型还有2个输出:
工单的优先级分数,它是介于0和1之间的标量(sigmoid输出)
应处理工单的部门(对所有部门做softmax)
利用函数式API,仅凭几行代码就可以构建这个模型,代码如下所示:
(多输入、多输出的函数式模型)
vocabulary_size = 10000
num_tags = 100
num_departments = 4
# (本行及以下2行)定义模型输入
title = keras.Input(shape=(vocabulary_size,), name="title")
text_body = keras.Input(shape=(vocabulary_size,), name="text_body")
tags = keras.Input(shape=(num_tags,), name="tags")
# 通过拼接将输入特征组合成张量features
features = layers.Concatenate()([title, text_body, tags])
# 利用中间层,将输入特征重组为更加丰富的表示
features = layers.Dense(64, activation="relu")(features)
# 定义模型输出
priority = layers.Dense(1, activation="sigmoid", name="priority")(features)
department = layers.Dense(
# 定义模型输出
num_departments, activation="softmax", name="department")(features)
# (本行及以下1行)通过指定输入和输出来创建模型
model = keras.Model(inputs=[title, text_body, tags],
outputs=[priority, department])
函数式API很简单,就像拼乐高积木一样,可以非常灵活地定义由层构成的图。
训练一个多输入、多输出模型
这种模型的训练方法与序贯模型相同,都是对输入数据和输出数据组成的列表调用fit()。
这些数据列表的顺序应该与传入Model构造函数的inputs的顺序相同,代码如下所示:
(通过给定输入和目标组成的列表来训练模型)
import numpy as np
num_samples = 1280
# (本行及以下2行)虚构的输入数据
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
# (本行及以下1行)虚构的目标数据
priority_data = np.random.random(size=(num_samples, 1))
department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data],
epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict(
[title_data, text_body_data, tags_data])
如果不想依赖输入顺序(比如有多个输入或输出),你也可以为Input对象和输出层指定名称,通过字典传递数据,代码如下所示(通过给定输入和目标组成的字典来训练模型):
model.compile(optimizer="rmsprop",
loss={"priority": "mean_squared_error", "department":
"categorical_crossentropy"},
metrics={"priority": ["mean_absolute_error"], "department":
["accuracy"]})
model.fit({"title": title_data, "text_body": text_body_data,
"tags": tags_data},
{"priority": priority_data, "department": department_data},
epochs=1)
model.evaluate({"title": title_data, "text_body": text_body_data,
"tags": tags_data},
{"priority": priority_data, "department": department_data})
priority_preds, department_preds = model.predict(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
函数式API的强大之处:获取层的连接方式
函数式模型是一种图数据结构。
这便于我们查看层与层之间是如何连接的,并重复使用之前的图节点(层输出)作为新模型的一部分。它也很适合作为大多数研究人员在思考深度神经网络时使用的“思维模型”:由层构成的图。它有两个重要的用处:模型可视化与特征提取。
我们来可视化上述模型的连接方式(模型的拓扑结构)。你可以用plot_model()将函数式模型绘制成图,如下图所示:
keras.utils.plot_model(model, "ticket_classifier.png")
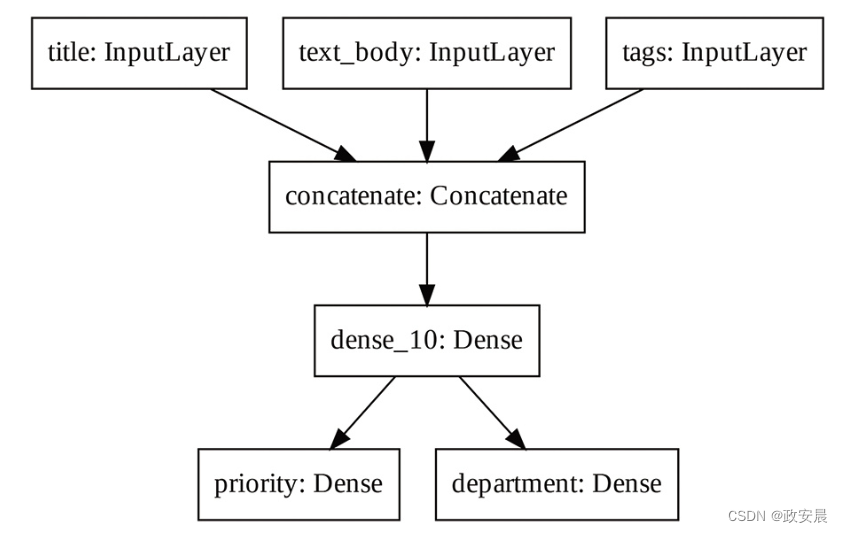
上图为将plot_model()应用于工单分类模型生成的图。
你可以将模型每一层的输入形状和输出形状添加到这张图中,这对调试很有帮助,如下图所示:
keras.utils.plot_model(
model, "ticket_classifier_with_shape_info.png", show_shapes=True)
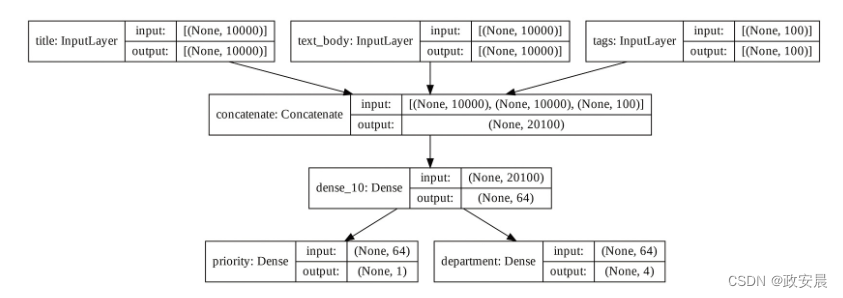
上图为添加形状信息后的模型图。
张量形状中的None表示批量大小,也就是说,该模型接收任意大小的批量。
获取层的连接方式,意味着你可以查看并重复使用图中的节点(层调用)。模型属性model.layers给出了构成模型的层的列表。对于每一层,你都可以查询layer.input和layer. output,代码如下所示(检索函数式模型某一层的输入或输出):
model.layers model.layers[3].input
这样一来,我们就可以进行特征提取,重复使用模型的中间特征来创建新模型。
假设你想对前一个模型增加一个输出——估算某个问题工单的解决时长,这是一种难度评分。实现方法是利用包含3个类别的分类层,这3个类别分别是“快速”“中等”和“困难”。你无须从头开始重新创建和训练模型。你可以从前一个模型的中间特征开始(这些中间特征是可以访问的),代码如下所示:(重复使用中间层的输出,创建一个新模型)
# layers[4]是中间的Dense层
features = model.layers[4].output
difficulty = layers.Dense(3, activation="softmax", name="difficulty")(features)
new_model = keras.Model(
inputs=[title, text_body, tags],
outputs=[priority, department, difficulty])
我们来绘制新模型的图,如下图所示:
keras.utils.plot_model(
new_model, "updated_ticket_classifier.png", show_shapes=True)
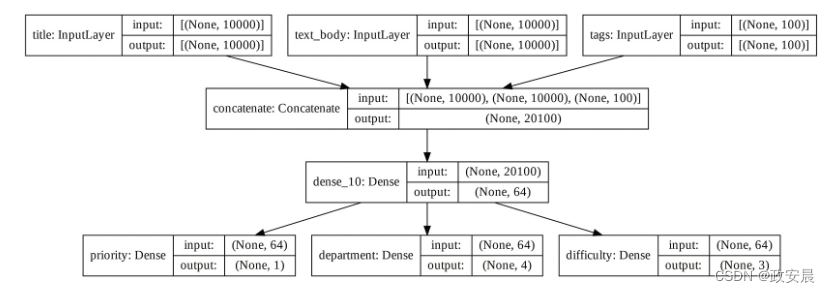
上图为新模型的图:
模型子类化
最后一种构建模型的方法是最高级的方法:模型子类化,也就是将Model类子类化。
咱们以前的文章中介绍过如何通过将Layer类子类化来创建自定义层,将Model类子类化的方法与其非常相似:
在__init__()方法中,定义模型将使用的层;
在call()方法中,定义模型的前向传播,重复使用之前创建的层;
将子类实例化,并在数据上调用,从而创建权重。
将前一个例子重新实现为Model子类
我们看一个简单的例子:使用Model子类重新实现客户支持工单管理模型,代码清单如下所示。
(简单的子类化模型)
class CustomerTicketModel(keras.Model):
def __init__(self, num_departments):
# 不要忘记调用super()构造函数!
super().__init__()
# (本行及以下3行)在构造函数中定义子层
self.concat_layer = layers.Concatenate()
self.mixing_layer = layers.Dense(64, activation="relu")
self.priority_scorer = layers.Dense(1, activation="sigmoid")
self.department_classifier = layers.Dense(
num_departments, activation="softmax")
# 在call()方法中定义前向传播
def call(self, inputs):
title = inputs["title"]
text_body = inputs["text_body"]
tags = inputs["tags"]
features = self.concat_layer([title, text_body, tags])
features = self.mixing_layer(features)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, department
定义好模型之后,就可以将模型实例化。
请注意,只有第一次在数据上调用模型时,模型才会创建权重,就像Layer子类一样。
model = CustomerTicketModel(num_departments=4)
priority, department = model(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
到目前为止,一切看起来都与Layer子类化非常相似,咱们以前已经讲过。那么,Layer子类和Model子类之间有什么区别呢?
答案很简单:“层”是用来创建模型的组件,而“模型”是高阶对象,用于训练、导出进行推理等。简而言之,Model有fit()、evaluate()和predict()等方法,而Layer则没有。除此之外,这两个类几乎相同。
你可以编译和训练Model子类,就像序贯模型或函数式模型一样。
model.compile(optimizer="rmsprop",
# (本行及以下1行)参数loss和metrics的结构必须与call()返回的内容完全匹配——这里是两个元素组成的列表
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
# (本行及以下2行)输入数据的结构必须与call()方法的输入完全匹配——这里是一个字典,字典的键是title、text_body和tags
model.fit({"title": title_data,
"text_body": text_body_data,
"tags": tags_data},
# 目标数据的结构必须与call()方法返回的内容完全匹配——这里是两个元素组成的列表
[priority_data, department_data],
epochs=1)
model.evaluate({"title": title_data,
"text_body": text_body_data,
"tags": tags_data},
[priority_data, department_data])
priority_preds, department_preds = model.predict({"title": title_data,
"text_body": text_body_data,
"tags": tags_data})
模型子类化是最灵活的模型构建方法。
它可以构建那些无法表示为层的有向无环图的模型,比如这样一个模型,其call()方法在for循环中使用层,甚至递归调用这些层。
注意:子类化模型不能做什么
这种自由是有代价的:对于子类化模型,你需要负责更多的模型逻辑,也就是说,你犯错的可能性会更大。因此,你需要做更多的调试工作。
你开发的是一个新的Python对象,而不仅仅是将乐高积木拼在一起。
函数式模型和子类化模型在本质上有很大区别。
函数式模型是一种数据结构——它是由层构成的图,你可以查看、检查和修改它。子类化模型是一段字节码——它是带有call()方法的Python类,其中包含原始代码。这是子类化工作流程具有灵活性的原因——你可以编写任何想要的功能,但它引入了新的限制。
举例来说,由于层与层之间的连接方式隐藏在call()方法中,因此你无法获取这些信息。调用summary()无法显示层的连接方式,利用plot_model()也无法绘制模型拓扑结构。同样,对于子类化模型,你也不能通过访问图的节点来做特征提取,因为根本就没有图。将模型实例化之后,前向传播就完全变成了黑盒子。
混合使用不同的组件
至关重要的是,选择序贯模型、函数式API和模型子类化中的某一种方法,并不会妨碍你使用其他方法。Keras API的所有模型之间都可以顺畅地交互,无论是序贯模型、函数式模型,还是从头编写的子类化模型。它们都是一系列工作流程的一部分。
举例来说,你可以在函数式模型中使用子类化的层或模型,创建一个包含子类化模型的函数式模型,代码如下:
class Classifier(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
if num_classes == 2:
num_units = 1
activation = "sigmoid"
else:
num_units = num_classes
activation = "softmax"
self.dense = layers.Dense(num_units, activation=activation)
def call(self, inputs):
return self.dense(inputs)
inputs = keras.Input(shape=(3,))
features = layers.Dense(64, activation="relu")(inputs)
outputs = Classifier(num_classes=10)(features)
model = keras.Model(inputs=inputs, outputs=outputs)
反过来,你也可以将函数式模型作为子类化层或模型的一部分,代码如下所示:
(创建一个包含函数式模型的子类化模型)
inputs = keras.Input(shape=(64,))
outputs = layers.Dense(1, activation="sigmoid")(inputs)
binary_classifier = keras.Model(inputs=inputs, outputs=outputs)
class MyModel(keras.Model):
def __init__(self, num_classes=2):
super().__init__()
self.dense = layers.Dense(64, activation="relu")
self.classifier = binary_classifier
def call(self, inputs):
features = self.dense(inputs)
return self.classifier(features)
model = MyModel()
用正确的工具完成工作
你已经了解了构建Keras模型的一系列工作流程,从最简单的工作流程(序贯模型)到最高级的工作流程(模型子类化)。应该选择哪一种呢?每一种都有自己的优缺点,你应该选择最适合手头工作的那一种。
一般来说,函数式API在易用性和灵活性之间实现了很好的平衡。它还可以直接获取层的连接方式,非常适合进行模型可视化或特征提取。如果你能够使用函数式API,也就是说,你的模型可以表示为层的有向无环图,那么我建议使用函数式API而不是模型子类化。
咱们这个系列的文章,后续所有示例都将使用函数式API,因为书中所有模型都可以表示为由层构成的图。但我们也会经常使用子类化的层。一般来说,使用包含子类化的层的函数式模型,可以实现两全其美的效果:既保留函数式API的优点,又具有较强的开发灵活性。







