

| 學院 | xxx | 适用專業 | xxx | ||
| 學生姓名 | xxx | 學号 | xxx | 學生班級 | xxx |
| 論文(設計)題目 | 高考志願推薦系統的設計與實現 | ||||
| 指導教師姓名 | xxx | 指導教師職稱 | xxx | ||
| 課題來源 | 生産或社會實際 | 課題類型 | 設計 | ||
| 說明:1、若課題來源于教師的科研項目,請填寫科研項目名稱,來源; 2、若課題來源于生産或社會實際,請寫明來源單位。 | |||||
| 畢業論文(設計)地點 | 六盤水師範學院 | 預計完成課題周數 | 14周 | ||
| 一、課題基本内容及要求 ㈠設計基本内容: 背景: 高考是中國的大學招生的學術資格考試,在目前看來,高考的考試類型有兩種,一種是文理分科,另一種是新高考模式。傳統的文理分科是将學生分成兩個類型,一種是文科,除了語數外三門課以外需要學習政史地,理科相對應的就需要學習物化生。根據學生的高考成績和每個大學在所對應省份的總體招生計劃來分梯度劃線,也就是我們常說的重本線,二本線和專科線。 高考填報志願對每個考生都非常重要,每年全國有數百萬家庭使用網絡了解高考支援志願信息并推薦填報志願。對于很大一部分考生和家長來說,短時間了解全國數千所高等院校的招生标準、曆史錄取分數、專業要求等信息非常困難。往往由于信息的缺失或錯誤造成高考志願與考生成績之間的較大差異,對考生造成不可挽回的損失。 因此,我們使用軟件工程面向對象的思想,開發一個高考志願填報推薦系統,爲高考結束的學生提供智能化推薦服務、往年報考信息可視化統計等,提高學生志願填報的準确度,加深學生對往年報考信息的認識深度,有助于志願的合理填報。 主要内容:
㈡設計基本要求:
㈢論文或設計說明書要求
以Java、Python、人工智能、軟件工程等基礎知識作爲論述依據,使用專業術語描述高考志願填報推薦系統開發所需要的背景、意義、需求分析、數據庫設計等論文模塊。 用UML建模語言對流程設計、ER圖、實體圖、數據庫表設計等進行完整圖表繪制,并且用專業知識撰寫成流暢描述語言,整合到論文中增添技術支持。 查詢知網同類系統參考文獻,多引用豐富的文獻素材,拓寬論文借鑒、創新的渠道。
提供關鍵部分代碼的清晰講解文字。 準确給出部署環境需要的機器配置、軟件版本、操作命令、步驟、腳本等。 給出軟件環境的下載鏈接如百度雲、阿裏雲等。 提供完整源代碼、數據庫建表語句的下載路徑。 提供演示地址、演示視頻、操作所需要的測試賬号、密碼等。
| |||||
| 二、課題特點(表現在符合專業培養目标上、表現在結合省情方面、表現在采用先進技術方面、表現在培養學生解決工程技術問題的能力上)
| |||||
| 三、此課題往屆是否做過?若已做過,寫明做過幾次,本屆有何新的要求? 此類題目屬于新題目,如果往屆有重複的話,本項目相對往屆項目有如下創新之處:
| |||||
| 四、課題的難易程度、工作量(論文字數或說明書字數、圖紙數量),以及對學生的知識、技能有何要求等 1.該課題屬于算法仿真類的課題,課題需要實現4種深度學習推薦算法、一種機器學習預測算法、一個知識圖譜關系圖的設計、高考志願填報業務等,難度适中。 2.需要查閱10-15篇中外高考推薦類系統的參考文獻,理清中外同類系統設計的優勢和劣勢,分析深層次技術設計的原理,結合我省高考的特點進行個性化定制設計。需要設計約20個功能模塊;編寫5-10萬行代碼實現;測試部分需要用單元測試完成,設計100-200個單元測試用例,邊開發邊單元測試自測可以降低統一測試的難度和節約測試時間。 3.解決以上問題需要掌握springboot+vue.js開發框架、mysql數據庫、深度學習算法知識、Python爬蟲等。 | |||||
| |||||
| 六、教學系審核意見: 該題目符合專業培養目标和教學基本要求原則,能使學生受到全面的專業基本訓練,選題緊密結合生産和社會實際,難度和工作量适當,具有學科性、專業性,能體現專業的主幹學科方向。 同意作爲畢業設計選題。 教學系主任(簽字): 2023年 月 日 | |||||
| 七、學院畢業論文(設計)工作領導小組審批意見: 經學院畢業論文(設計)工作領導小組審核,同意作爲畢業設計選題。 組長(簽字): 2023年 月 日 |




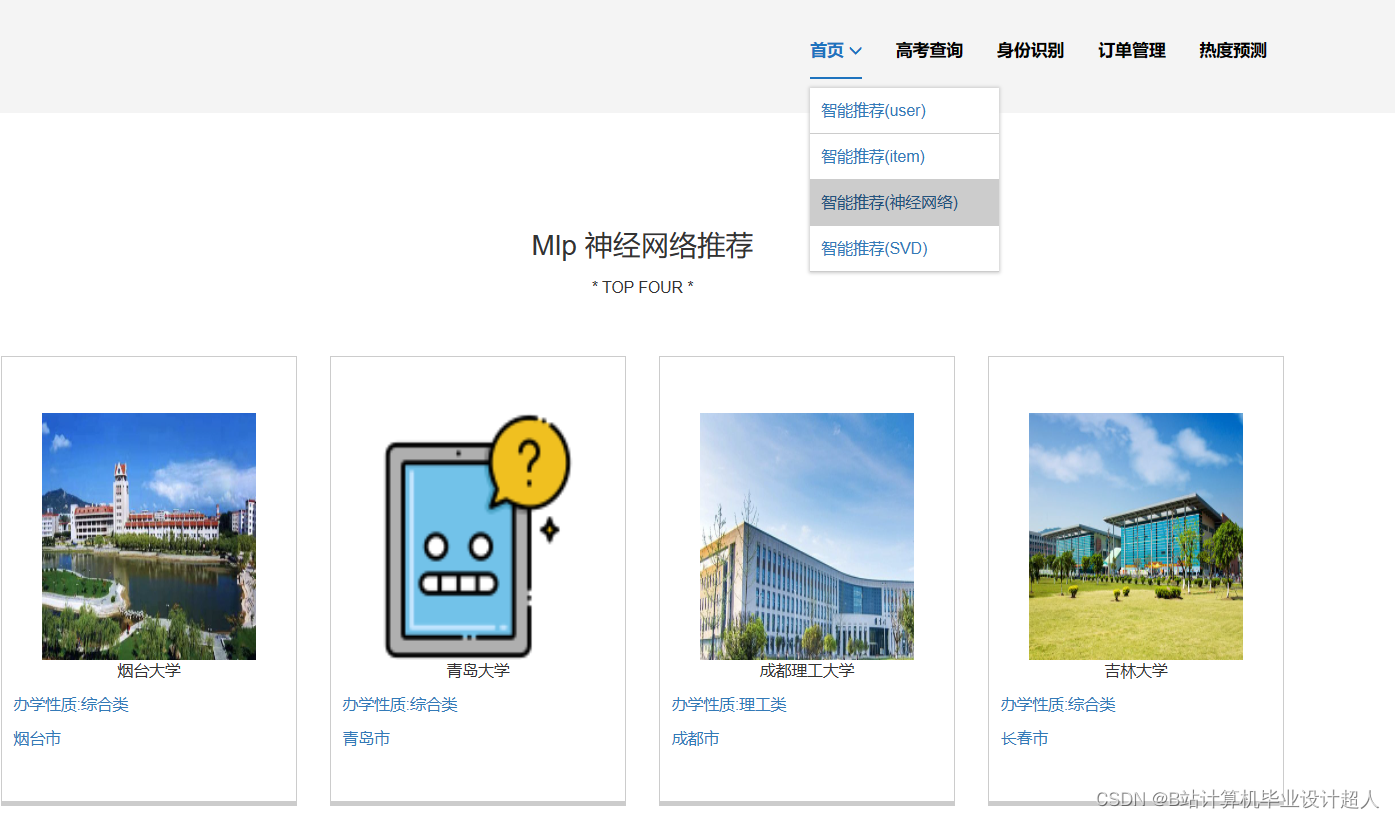
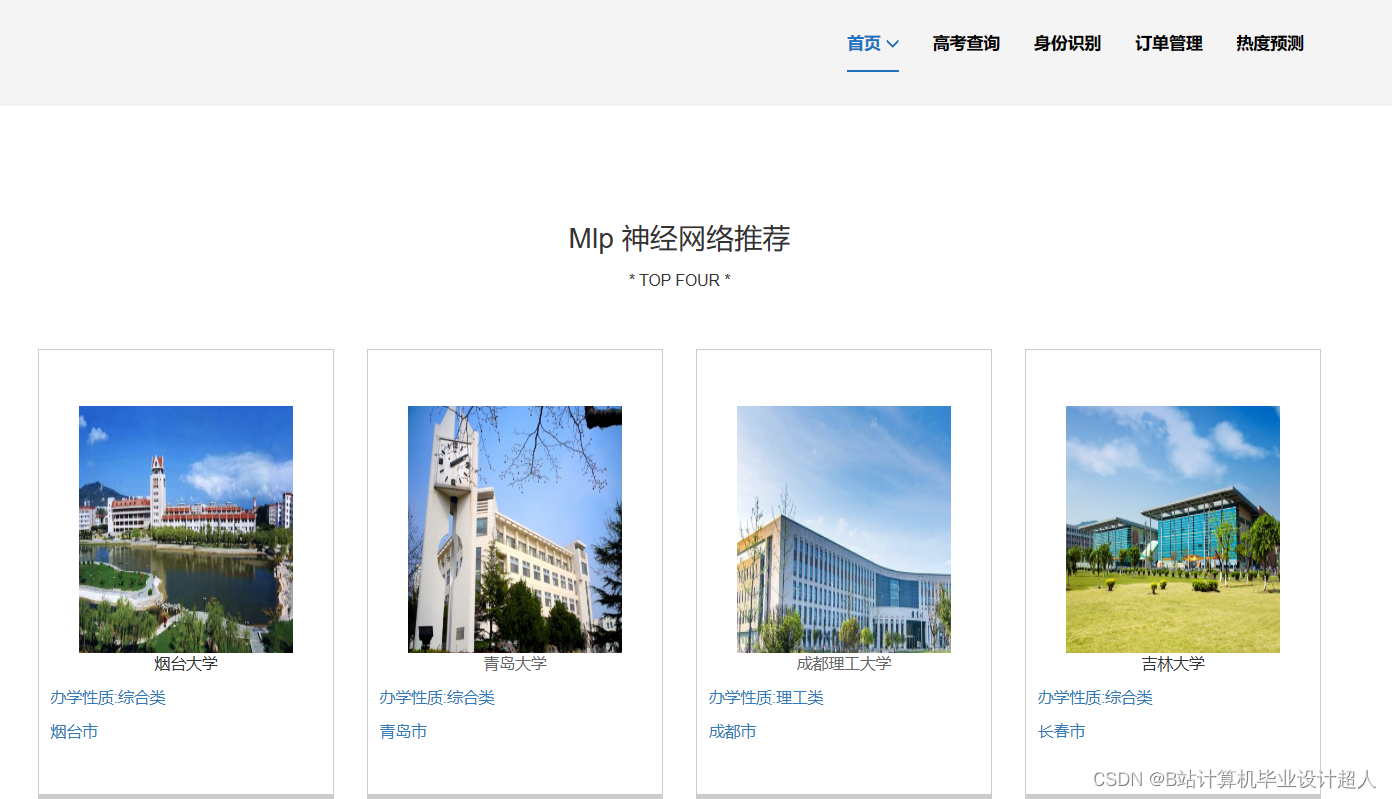
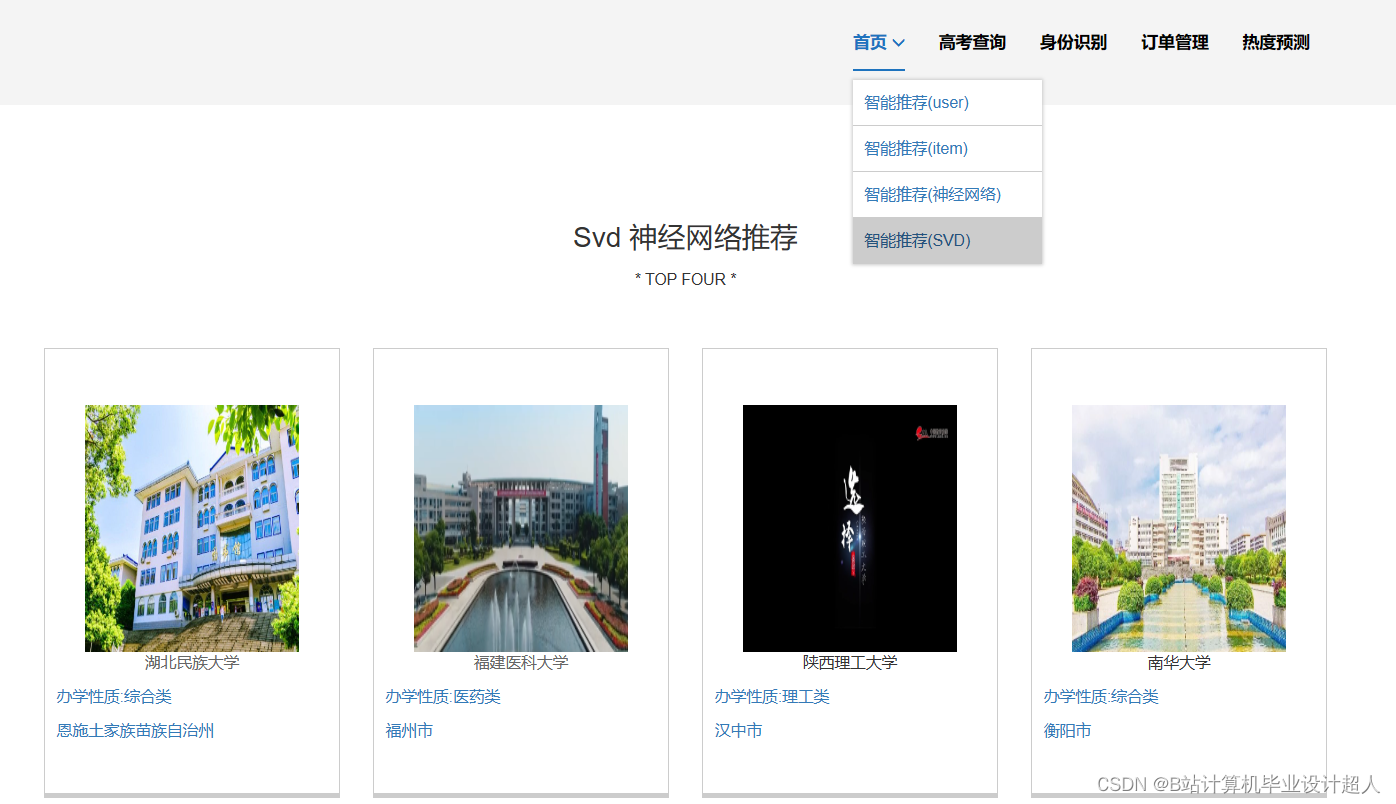
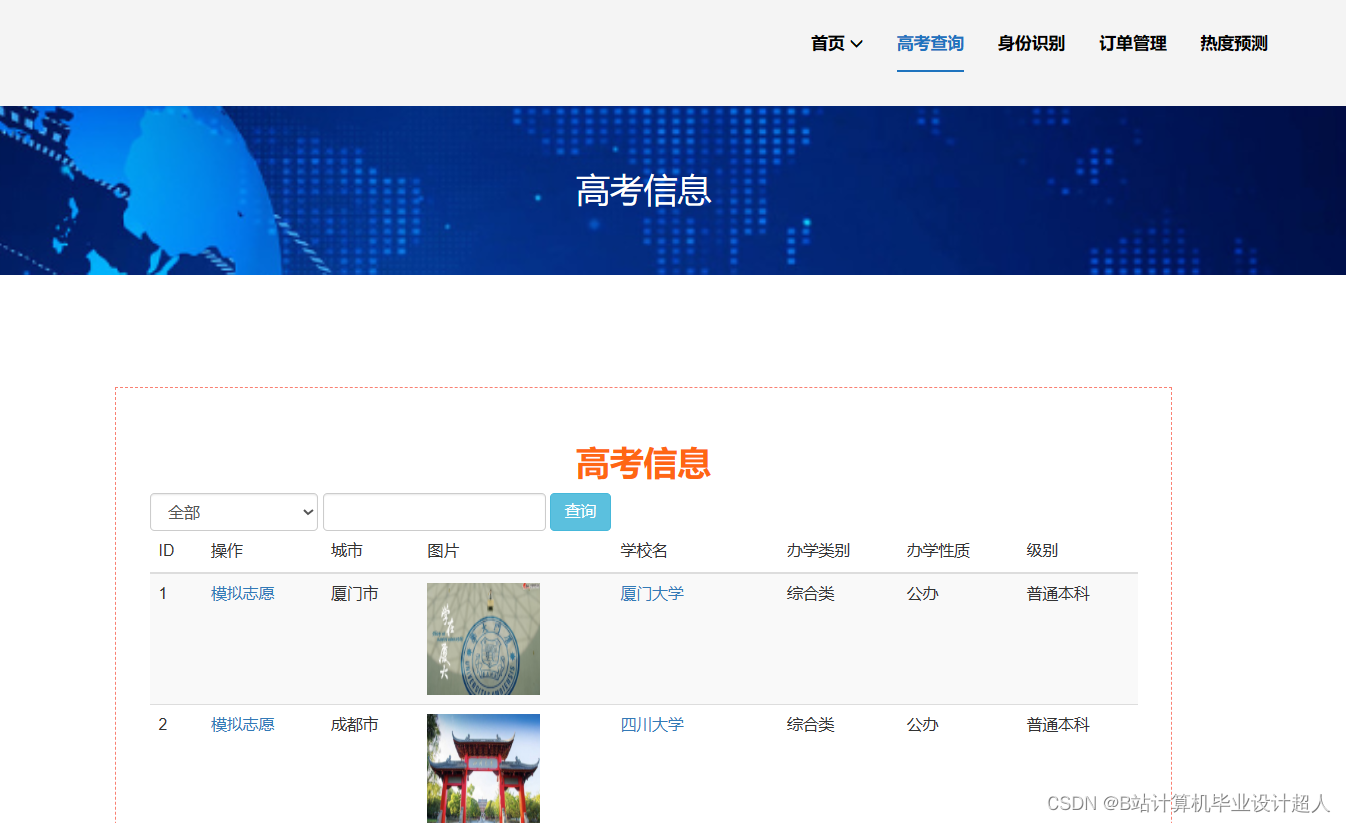



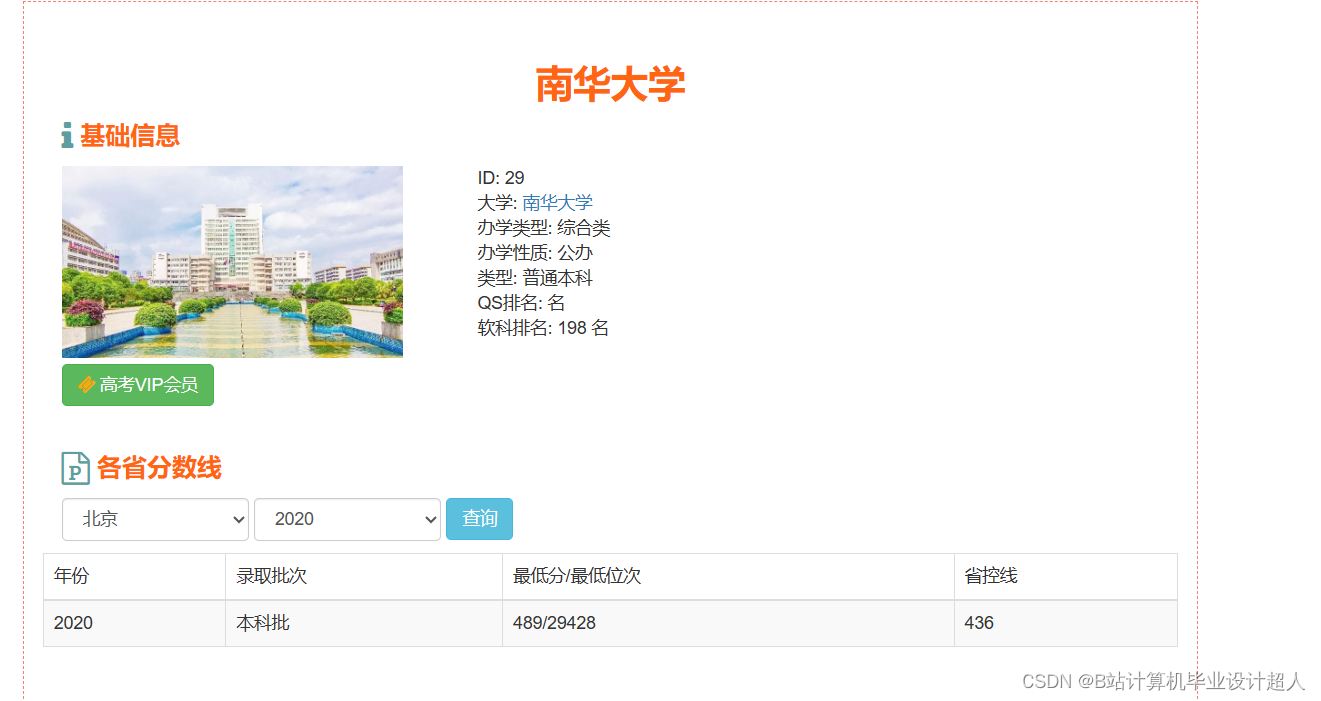
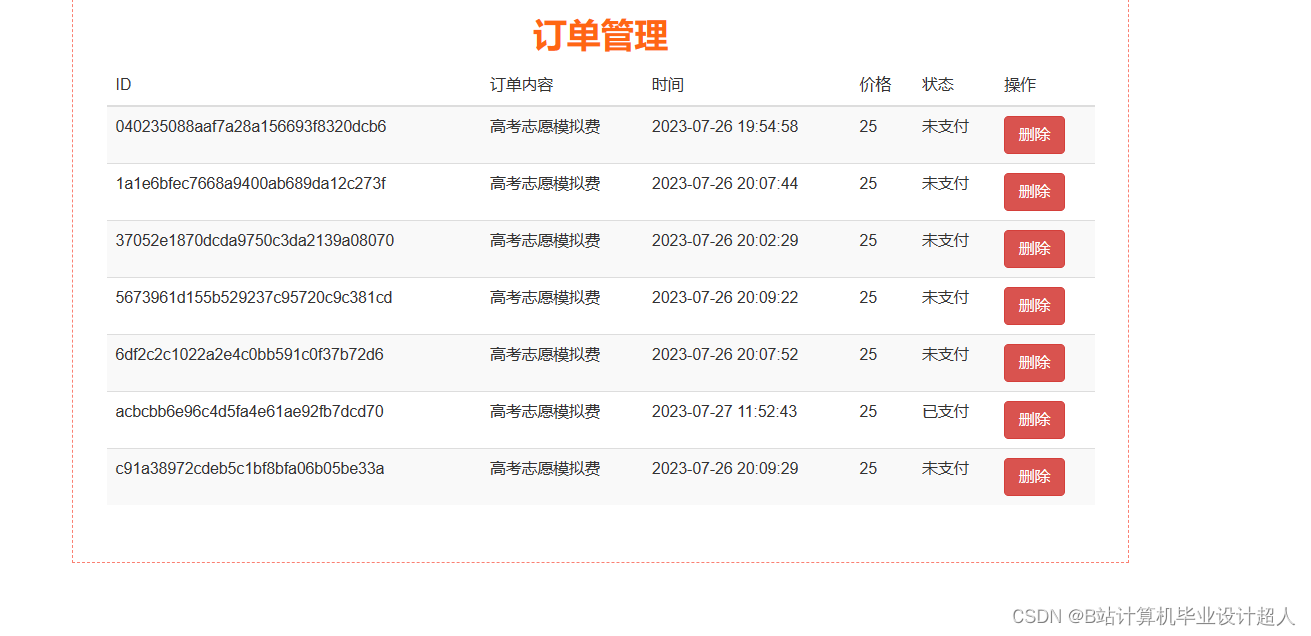
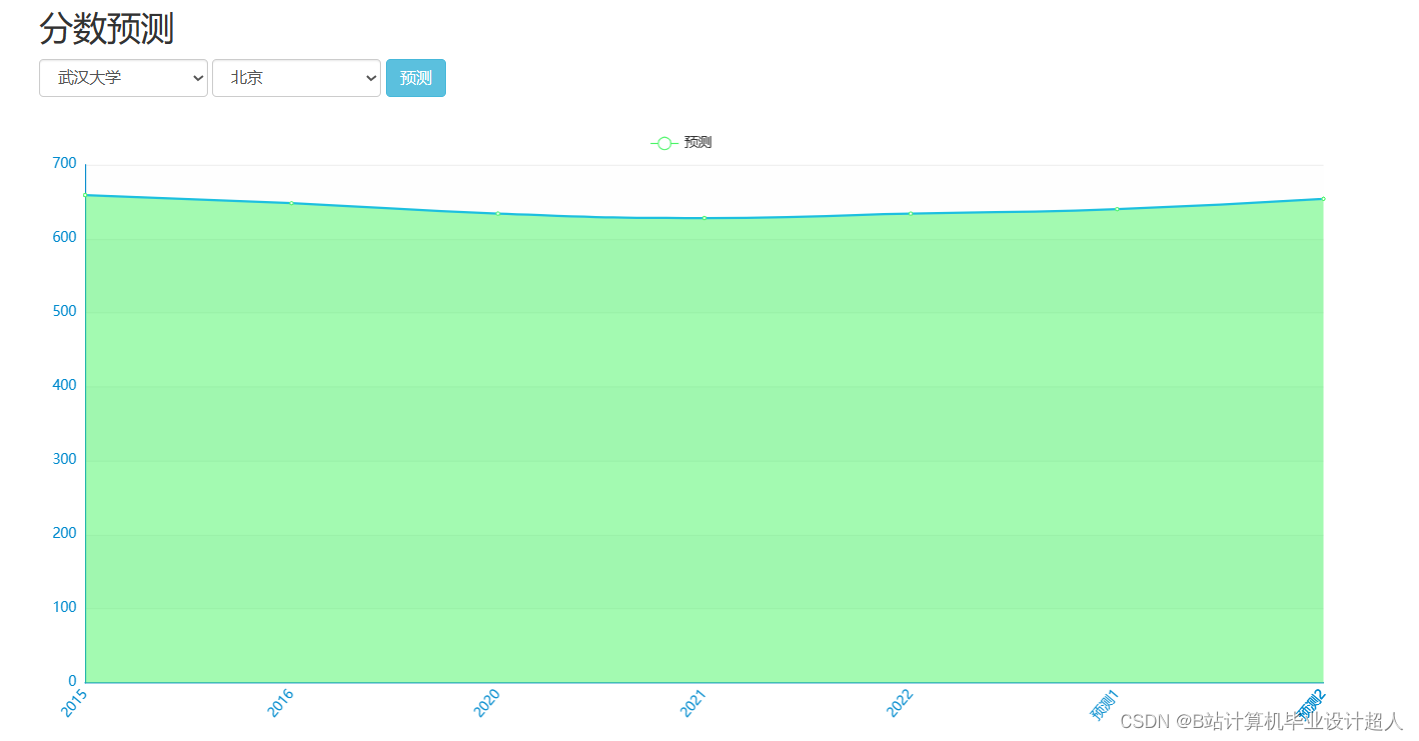
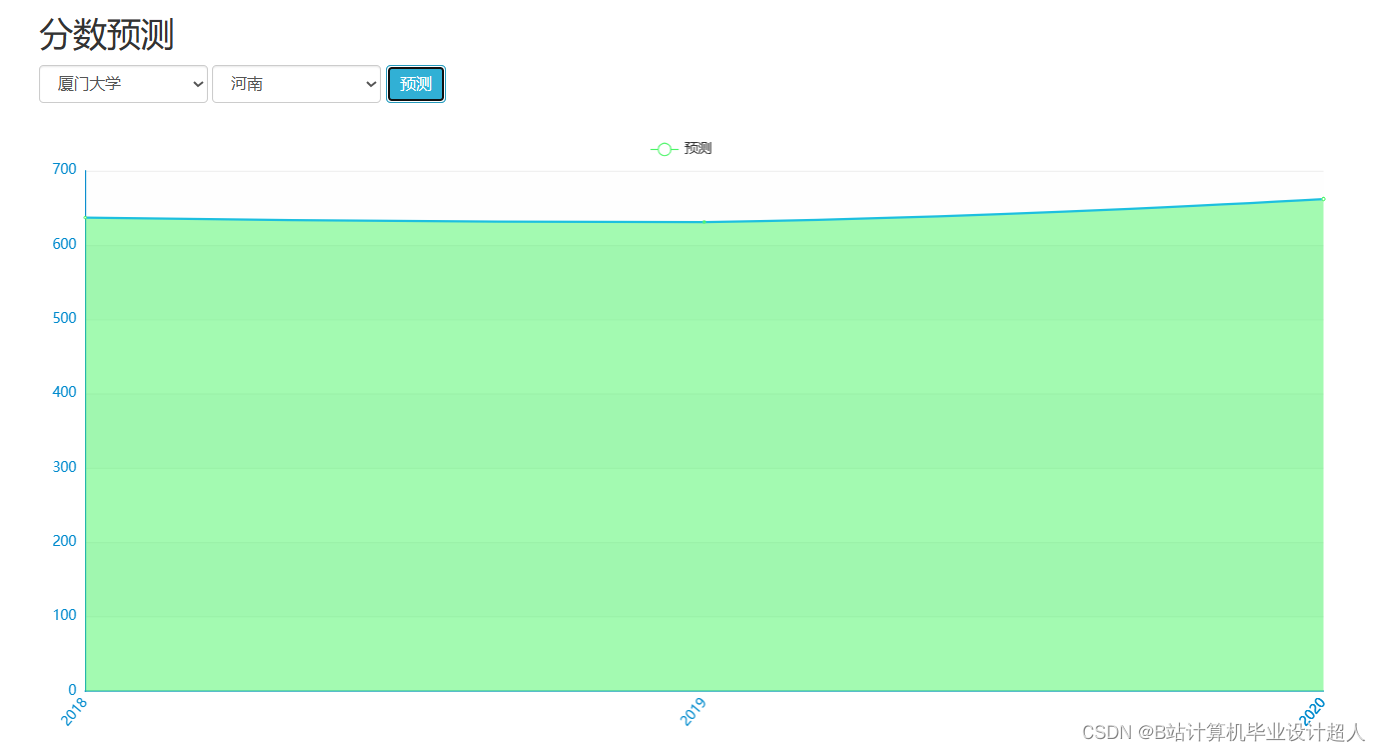






| 姓名 | 張三 | 學号 | 年級 | 班級 | |||
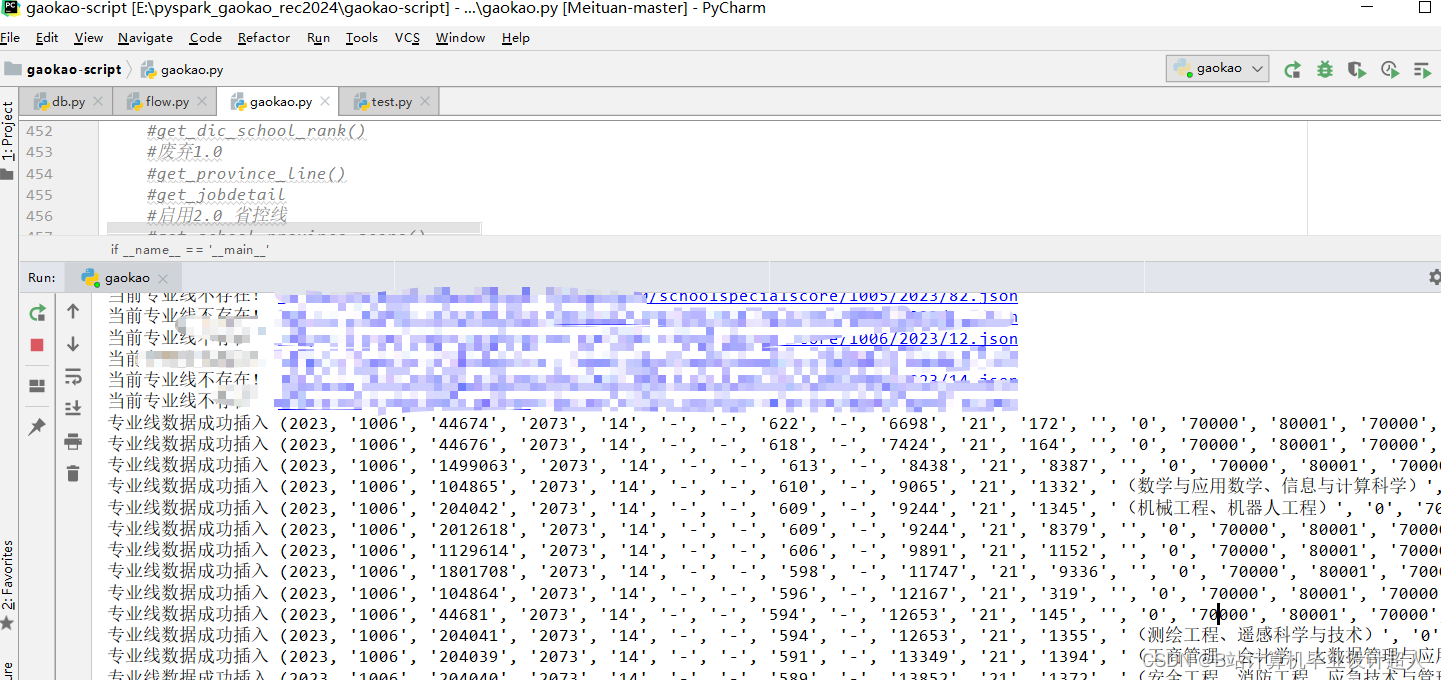
| 設計(論文) 題目 | 基于Spark的高考智能推薦系統 | ||||||
| 指導教師姓名 | 職稱 | ||||||
| 拟完成時間 | 2022年 1 月 15 日 | ||||||
| 設計(論文)類别
| þ項目設計制作類 ¨項目設計策劃類 ¨實踐操作類 ¨課堂教學與設計類 ¨學位論文類 | ||||||
| 命題來源 | þ教師命題 ¨學生自拟 ¨教師科研課題 | ||||||
| 是否在實驗實訓、實習、工程實踐和社會調查等社會實踐中完成 | þ是 ¨否 | ||||||
| 一、選題依據及意義(不少于300字) 依據 高考是中國的大學招生的學術資格考試,在目前看來,高考的考試類型有兩種,一種是文理分科,另一種是新高考模式[1]。傳統的文理分科是将學生分成兩個類型,一種是文科,除了語數外三門課以外需要學習政史地,理科相對應的就需要學習物化生。根據學生的高考成績和每個大學在所對應省份的總體招生計劃來分梯度劃線,也就是我們常說的重本線,二本線和專科線[2]。 高考填報志願對每個考生都非常重要,每年全國有數百萬家庭使用網絡了解高考支援志願信息并推薦填報志願[3]。對于很大一部分考生和家長來說,短時間了解全國數千所高等院校的招生标準、曆史錄取分數、專業要求等信息非常困難。往往由于信息的缺失或錯誤造成高考志願與考生成績之間的較大差異,對考生造成不可挽回的損失。 意義 目前高考志願填報,湧現很多沒有結合自身實際、盲目跟風的不良現象,最常見的跟風是過度依賴智能系統,很多家長、考生缺乏高考志願相關專業知識,又沒有太多時間去研究,面對浩如煙海的數據産生焦慮情緒,希望找到一種性價比高的方式,解決填報志願時遇到的各種難題,最好能省心省事直接生成填報方案[4]。在龐大用戶需求量和高額利潤誘惑下,高考志願智能輔助系統軟件的市場近年來變得非常火爆,有些商家抓住客戶着急心理和對行情信息不了解的情況,做出虛假、過分誇大宣傳。大部分家長不能從專業角度去甄别智能系統,盲目跟風繳費升級會員,過分迷信權威金牌專家、内部來源數據、人工智能一鍵生成方案等,很多考生三年備考、三分鍾報考,錄取去向滿意度不高。 在當今時代,互聯網的高度普及以及信息技術的飛速發展都使得數據呈現爆炸式增長,海量的數據然已成爲一種“藏”[5]。與此同時,社會出現了大量的“據金者”在數據的海洋裏挖掘、采集、提煉、分析,想要發掘有價值的信息。據了解,大數據目前主要應用于互聯網、電商、視頻門戶網站等企業領域,對于教育領域則運用的較少高考是教育領域中最引人注目的大事件,中國作爲高考大國,在高考招生的信息化建設中,積累了非常豐富的高考信息數據資源,包括曆年的報名庫、志願庫、錄取庫、成績庫等等,且數據大多爲原始數據未經過處理。面對這些數據,考生在填報志願時往往無所适從,導緻高考數據沒能充分體現其價值,面對大數據時代所帶來的數據過載等問題,推薦系統列和搜索引應運而生,相比于後者的信息被動選擇模式,推薦系統是基于機器學習+深度學習自動的幫助用戶過濾掉一些無用或不喜歡的内容,直接替用戶完成了自我篩選的過程[6]。其極大的縮短了用戶在信息選擇上的時間,同時也提高了用戶相關行爲數據的利用率。 | |||||||
| 二、研究目的與主要内容(含設計(論文)提綱,不少于500字) 研究目的
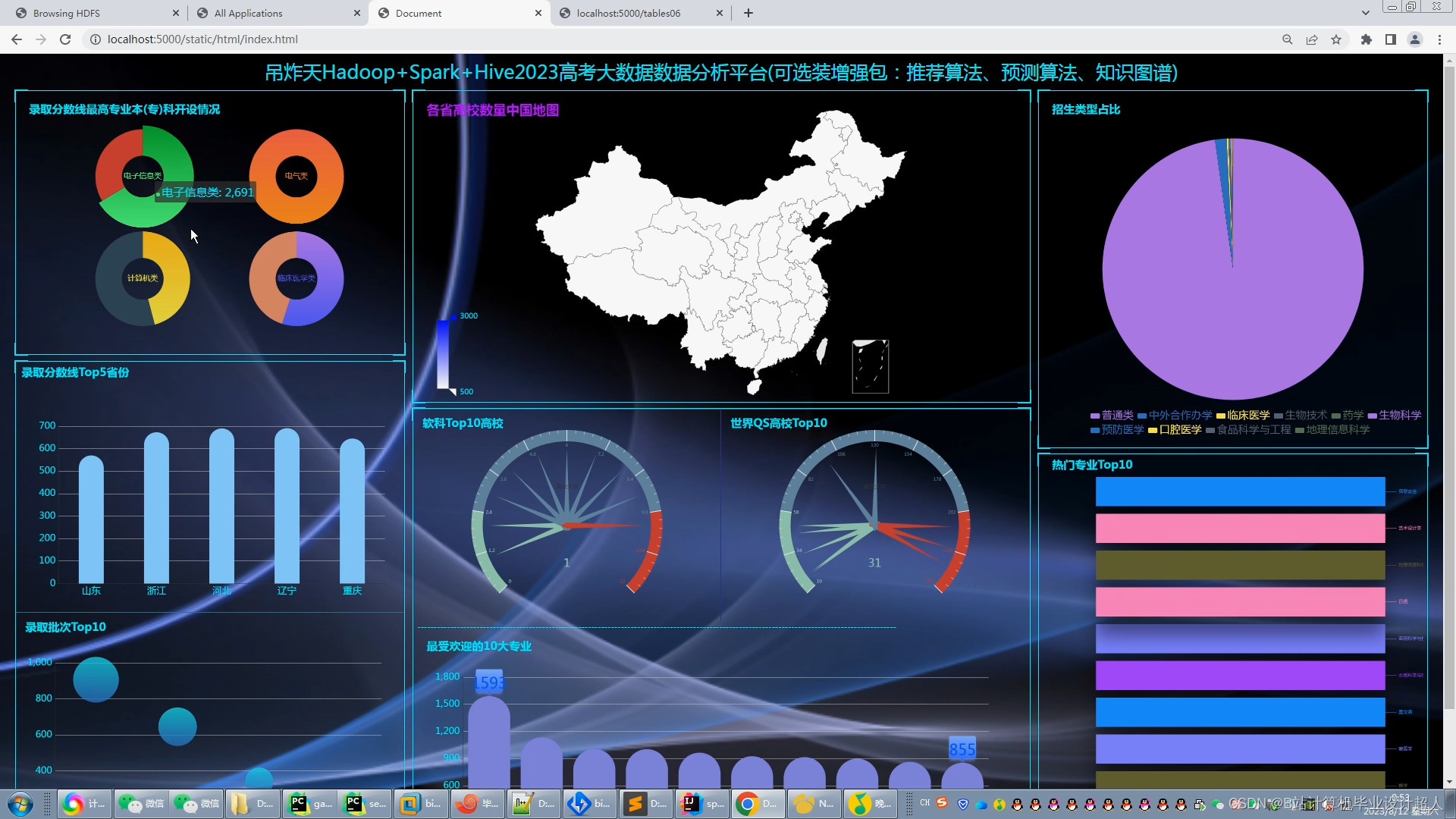
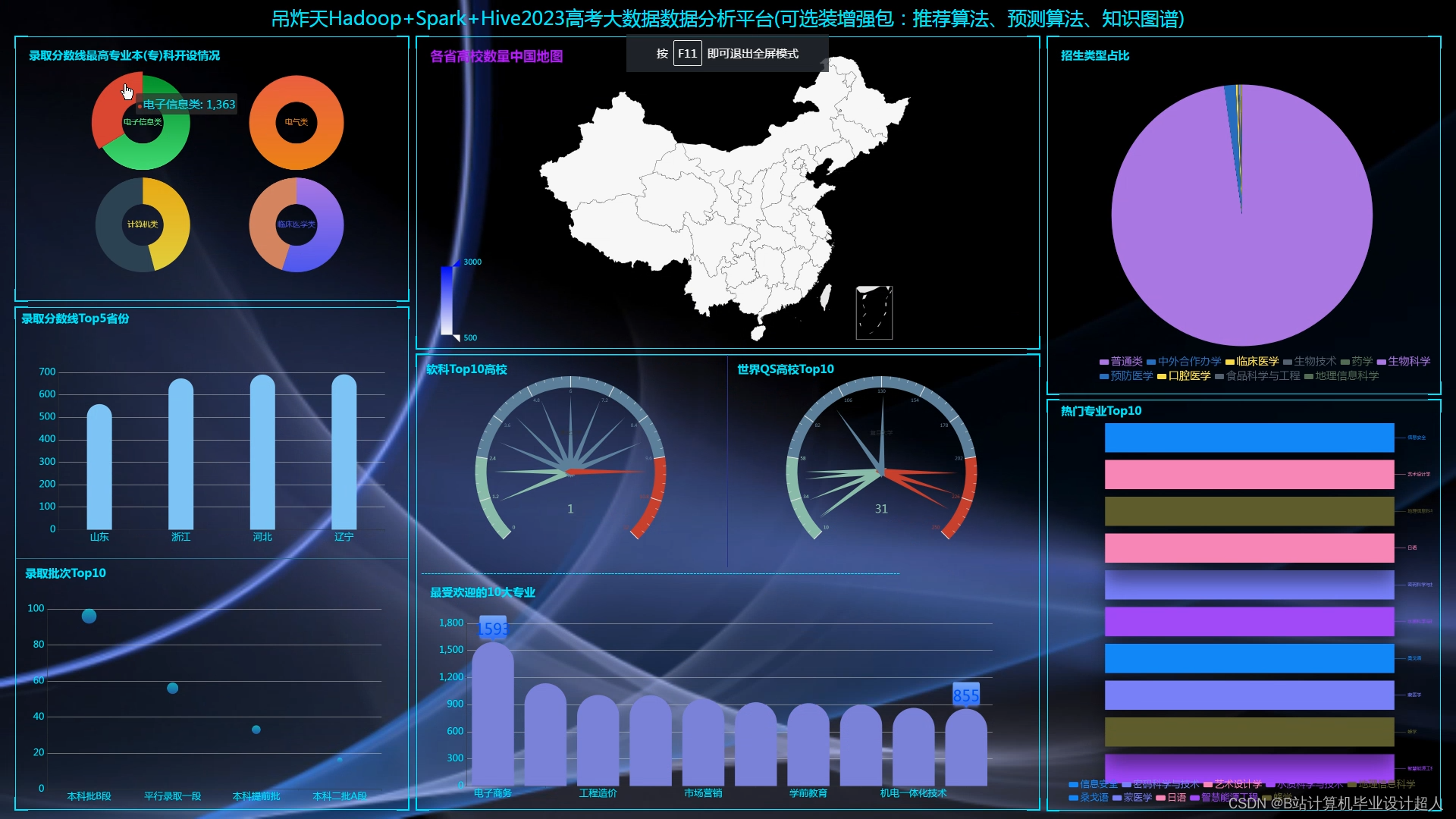
主要内容 1、推薦系統:包含協同過濾算法的兩種實現(基于用戶、基于物品)、基礎業務功能; 2、後台管理系統:數據管理; 3、爬蟲:爬取曆年高考分數、高考院校信息,并可以實時更新; 4、數據大屏駕駛艙:使用Spark+Hadoop+Hive實時計算框架+離線數倉完成數據統計,以flask+echarts形式進行可視化顯示; 設計(論文)提綱 1、論文提綱 摘要 英文摘要 1 引言
1.3 國内外研究現狀 1.4 研究主要内容與技術 1.4.1研究内容 1.4.2研究技術 2 基于python爬蟲的數據爬取和數據庫的建立 2.1 高考信息表 2.5 數據庫的建立 3 數據進行展示、科學分析和預測 3.1 基于spark+echarts進行可視化展示 3.2 推薦算法 3.4 情感分析 4 系統的建立和展示 4.1 基于springboot+mybatis後端開發 4.2 基于html、echarts、vue前端開發 4.3 系統的最終調試 5 結束語 參考文獻 緻謝 附錄 | |||||||
| 三、研究方法和手段 研究方法 1、按照設計題目要求設計畢業設計方案,配合指導教師進行設計; 2、明确數據的來源,查找數據的途徑,确保數據的穩定性; 3、接受指導教師指導,定時彙報工作内容,并就相關問題進行讨論; 4、理論聯系實際,培養正确的工作方法和嚴謹的科學态度; 5、按照進度計劃完成畢業設計并書寫畢業論文。 研究手段
| |||||||
| 四、文獻綜述(在對選題涉及的研究領域的文獻進行廣泛閱讀或調查的基礎上,對該領域的研究現狀、發展動态等内容進行綜述,并提出自己的見解和研究思路。不少于700字) 1、傳統填報方法效率低、效果差。 目前,全國大部分省(自治區、直轄市)都是高考成績公布後開始填報志願,大部分家長和考生僅僅利用招生考試機構公布志願填報日程幾天時間,從近2700所高校和500多個專業中做出選擇,對很多毫無經驗的家長和考生來說“難于上青天”。因爲影響高考志願因素太多,如考生職業生涯規劃、個人和家庭情況、分數、院校、專業、城市、高考志願政策規則、填報策略技巧、近3到5年錄取數據、錄取概率測算、就業情況等,如果僅在幾天内通過傳統手段,以手工查閱書籍材料,往往會因爲資料難找、耗時長、易疲勞出錯等原因,填報志願和最終錄取去向往往不盡如人意[9]。 2、填報方案不科學,錄取不滿意案例多。 《中國青年報》社會調查中心發起的一項10萬人參加的抽樣調查,超過71.2%的人後悔當年的高考志願。我們可以在新聞媒體或網絡上看到很多志願填報不科學的典型案例,其中很多是高材生。 2008年周某以青海省第三名的成績被北京大學生命科學學院錄取,兩年後周某選擇轉學到了北京工業技師學院。2017年李某從中國科學技術大學退學補習,2018年高考以雲南省理科第8名的好成績拒絕清華大學和北京大學發出的邀請,選擇了四川大學口腔專業。2017年廣西理科高考第3名考生,填錯高考志願批次,最後通過征集獲得錄取。2017年浙江省646高分考生竟報考獨立學院,全省被獨立學院錄取的600分以上考生多達9人。 現實中,還有很多高考過來人默默承受着高考志願填報失誤帶來的痛,比如對專業不滿意、對院校不滿意、填錯批次、錯過填報時間、被退檔、畢業後從事與自己所學專業毫無關聯的工作等。 在本項目中主要研究的是傳統文理分科的高考模式,因爲這種模式有着大量的數據支撐,提供訓練,能夠高精度地做出預測。而新考高模式剛剛施行,其數據是不足以支撐訓練,從而做出預測。高考錄取填報推薦志願方式,梯度志願和混合錄取,經過不斷優化,平行志願已成爲了高考錄取的主流,大部分省份都采取平行志願,所以本次項目也就平行志願的錄取方式來進行研究。即分數優先,滿足偏好的方式,所以本項目着重對學生位次進行研究。針對高考這一熱門話題,國内外都有着不少的專家學者對其進行研究,在過去的實踐中,人們往往選用經典的時間序列方法來解決預測高校錄取問題,即利用近5年高校錄取的分數線,名次求平均值來預測當年的分數線,但是利用時間序列預測,就必須保證時間序列的過去值、當前值、和未來值之間存在着某種确定的函數關系。所以這養的預測是不夠精确,不夠完善的。除了基于時間序列的預測以外,還有人通過錄取線差法來對高考錄取進行研究,所謂錄取線差是指考生意向院校當年平均錄取分數與其所在招生批次錄取控制分數線的差值。但是,每年高考試卷難度有别,造成了各個院校各年度的錄取分數可能發生較大的變化。 綜合來看,基于Spark的高考志願推薦系統的相關研究在國内外都不多,未來的發展空間都很大。在未來的研究中可以結合數據分析、規劃優化、機器學習和推薦算法等領域的相關方法,利用Spark的大數據處理能力,設計和實現一套可行的高考志願推薦系統。這将爲考生提供更好的填報建議,提升高考志願填報的準确性和個性化程度。 | |||||||
| 五、參考文獻(作者、書名或設計(論文)題目、出版社或刊号、出版年月或出版期号) [1]孫浩然,武雪明,吉雪芸.高考志願智能推薦系統的設計與實現[J].電腦知識與技術,2023,19(09):41-45.DOI:10.14004/j.cnki.ckt.2023.0427. [2]白俊傑. 基于混合推薦的高考志願推薦系統的設計與實現[D].内蒙古大學,2022.DOI:10.27224/d.cnki.gnmdu.2022.001490. [3]孟真. 基于Spark的高考推薦系統設計與實現[D].山東師範大學,2017. [4]銀虹宇. 基于大數據的高考志願推薦系統的設計與實現[D].電子科技大學,2018. [5]謝雷,唐旭,鍾立國. 基于Spark的高考志願填報系統設計與實現[J]. 計算機工程與設計, 2017, 38(9): 2461-2465. [6]唐旭,鍾立國,謝雷. 基于Spark的高考志願填報系統設計與實現[J]. 現代計算機, 2019, 40(8): 129-132. [7]李坤,田田. 基于Spark的高考志願填報系統設計與實現[J]. 電腦知識與技術, 2019, 15(3): 80-81. [8]陳娟,黃林偉. 基于Spark的高考志願填報系統設計與實現[J]. 現代電子技術, 2020, 43(4): 181-184. [9]基于Spark的高考志願填報系統設計與實現 作者:謝雷,唐旭,鍾立國 出處:《計算機工程與設計》,2017年,第38卷,第9期 [10]Guo, M., Zhang, J., Zhang, J., & Li, J. (2020). Research on Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Spark. In 2020 International Conference on Artificial Intelligence and Big Data (ICAIBD) (pp. 104-107). [11]Wang, Y., Liu, W., Zhu, M., Li, H., & Li, J. (2019). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Big Data Analysis. In 2019 2nd International Conference on Mathematics, Modeling, Simulation and Education Application (MMSEA) (pp. 1-4). [12]Wang, Z., & Guo, C. (2018). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Big Data Analysis. In 2018 IEEE International Conference on Big Data (Big Data) (pp. 4494-4496). [13]Zhang, Y., & Li, S. (2018). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Spark. In 2018 International Conference on Data Science and Advanced Analytics (DSAA) (pp. 535-539). [12] 王琴.基于Bootstrap技術的高校門戶網站設計與實現[J].哈爾濱師範大學自然科學學報,2023,33(03):43-48 [13]周寅,張振方,周振濤,張楊,基于Java Web的智慧醫療問診管理系統的設計與應用[J].中國醫學裝備,2022,18(8):132-135. [14]王福東,程亮.基于傳統組态軟件與Java相結合的水位監測分析系統[J].自動化技術與應用,2021,40(9):24-28. [15] 佘青.利用Apache Jmeter進行Web性能測試的研究[J].智能與應用,2021,2(02):55-57 | |||||||
| 六、工作進度安排(時間、内容、步驟)
| |||||||
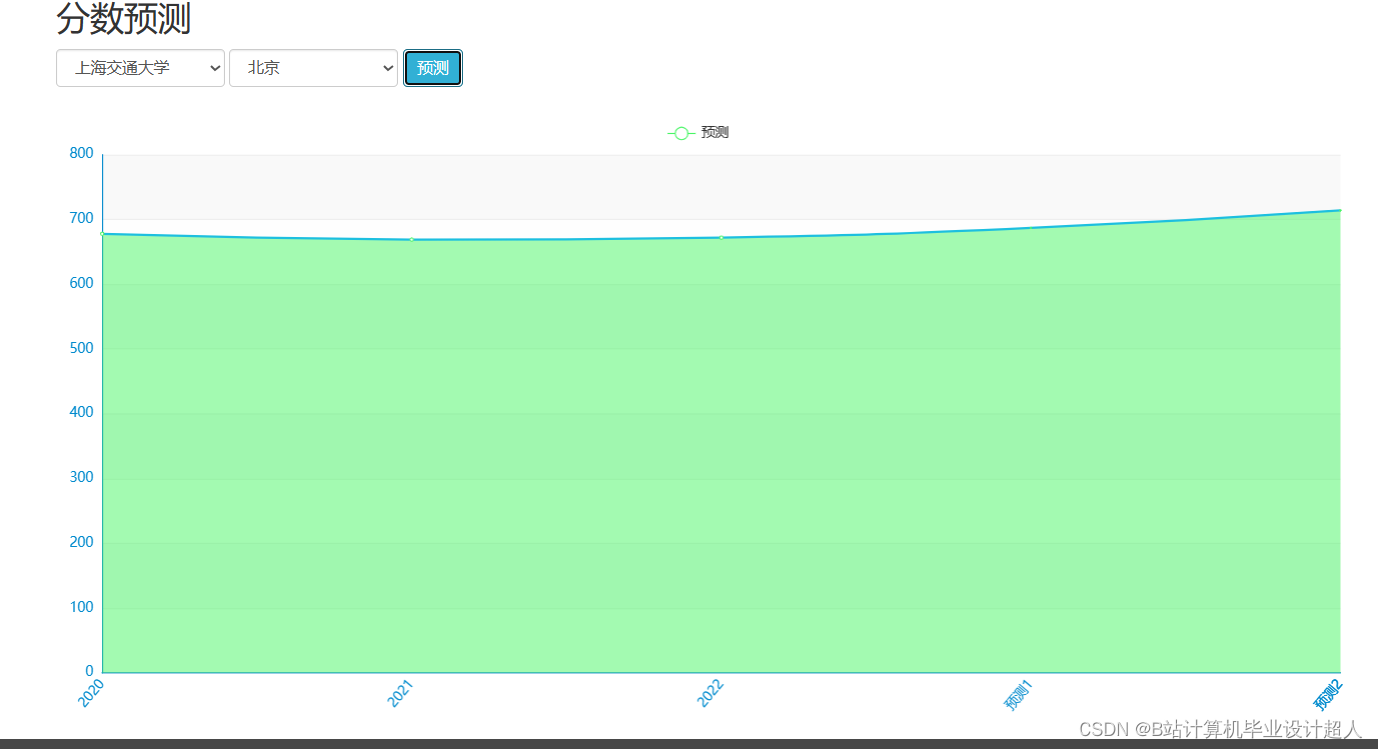
| 七、預期成果 完整的虛拟機文件含hadoop、spark、hive、mysql、sqoop等大數據環境; 有效的高考志願推薦算法,可以進行個性化推薦。有4種機器學習實現方法; 可以使用線性回歸算法進行高考分數預測; 使用hadoop+spark+hive進行離線、實時計算分析,呈現一張高考可視化大屏; Springboot+vue.js後台管理系統可以進行數據管理; Selenium采集大約10W+今年高考省控線、專業線、專業信息等數據集; | |||||||
| (以上内容在教師指導下由學生填寫) 學生簽名: 年 月 日 | |||||||
| 八、指導教師審核意見: 指導教師簽名: 年 月 日
|

高考志願推薦通常涉及到多個因素,比如學生的興趣愛好、成績、特長、職業規劃等。這裏給出一個簡單的示例,假設使用學生的成績作爲推薦的依據,基于 PyTorch 實現一個簡單的推薦算法:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設有5個學生和10個專業
num_students = 5
num_majors = 10
input_dim = 3 # 假設輸入特征爲3維,比如語文、數學、英語成績
# 模拟學生的成績數據(學生ID,語文成績,數學成績,英語成績,專業ID)
scores = torch.tensor([[0, 80, 75, 85, 1],
[1, 85, 78, 80, 3],
[2, 90, 82, 88, 5]], dtype=torch.float)
# 創建學生和專業的嵌入矩陣
student_embedding = nn.Embedding(num_students, input_dim)
major_embedding = nn.Embedding(num_majors, input_dim)
# 定義模型
class MajorRecommendation(nn.Module):
def __init__(self, num_students, num_majors, input_dim):
super(MajorRecommendation, self).__init__()
self.student_embedding = nn.Embedding(num_students, input_dim)
self.major_embedding = nn.Embedding(num_majors, input_dim)
def forward(self, student_ids, major_ids):
student_emb = self.student_embedding(student_ids)
major_emb = self.major_embedding(major_ids)
# 計算學生和專業之間的内積作爲預測分數
preds = torch.sum(student_emb * major_emb, dim=1)
return preds
# 初始化模型和優化器
model = MajorRecommendation(num_students, num_majors, input_dim)
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 訓練模型
for epoch in range(100):
optimizer.zero_grad()
student_ids = scores[:, 0].long()
major_ids = scores[:, -1].long()
ratings = torch.sum(scores[:, 1:-1], dim=1) # 使用總分作爲評分
preds = model(student_ids, major_ids)
loss = nn.MSELoss()(preds, ratings)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
# 使用模型進行推薦
student_id = torch.tensor([0])
major_ids = torch.arange(num_majors)
predicted_scores = model(student_id, major_ids)
print('Predicted scores for student 0:')
print(predicted_scores)
在這個示例中,我們假設每個學生的成績是一個3維的向量(比如語文、數學、英語成績),然後使用學生和專業的 Embedding 層來學習學生和專業的表示。在訓練過程中,模型嘗試預測學生與專業之間的匹配程度,并通過均方誤差損失函數進行優化。最後,使用訓練好的模型進行推薦時,可以輸入學生ID,得到對所有專業的預測分數。
當然,實際的高考志願推薦涉及到更多複雜的因素,比如學生的興趣愛好、特長等,這個示例隻是一個簡單的起點。希望這個示例能對你有所幫助!如有任何問題,請随時提出。








