

- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
文章目录
- 0. 背景
- 1. 代码实现
- 1.1 加载网页数据
- 1.2 数据分块
- 1.3 数据向量化和存储
- 1.4 向量检索
- 1.5 组装Chain
- 1.6 运行
- 2. 加入Sources(答案来源)
- 2.1 代码修改
- 2.2 代码解释
- 3. 总结
0. 背景
目前为止,我们已经系统学习了一下内容:
- 【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用
(2)网页数据抓取
- 【AI大模型应用开发】【LangChain系列】实战案例2:通过URL加载网页内容 - LangChain对爬虫功能的封装
(3)langchain基本使用:
- 【AI大模型应用开发】【LangChain系列】1. 全面学习LangChain输入输出I/O模块:理论介绍+实战示例+细节注释
- 【AI大模型应用开发】【LangChain系列】2. 一文全览LangChain数据连接模块:从文档加载到向量检索RAG,理论+实战+细节
- 【AI大模型应用开发】【LangChain系列】4. 从Chain到LCEL:探索和实战LangChain的巧妙设计
今天,我们将综合以上技能,完成 网络数据+RAG 问答的实践,并且学习如何在返回结果中添加结果的来源(原文档)。
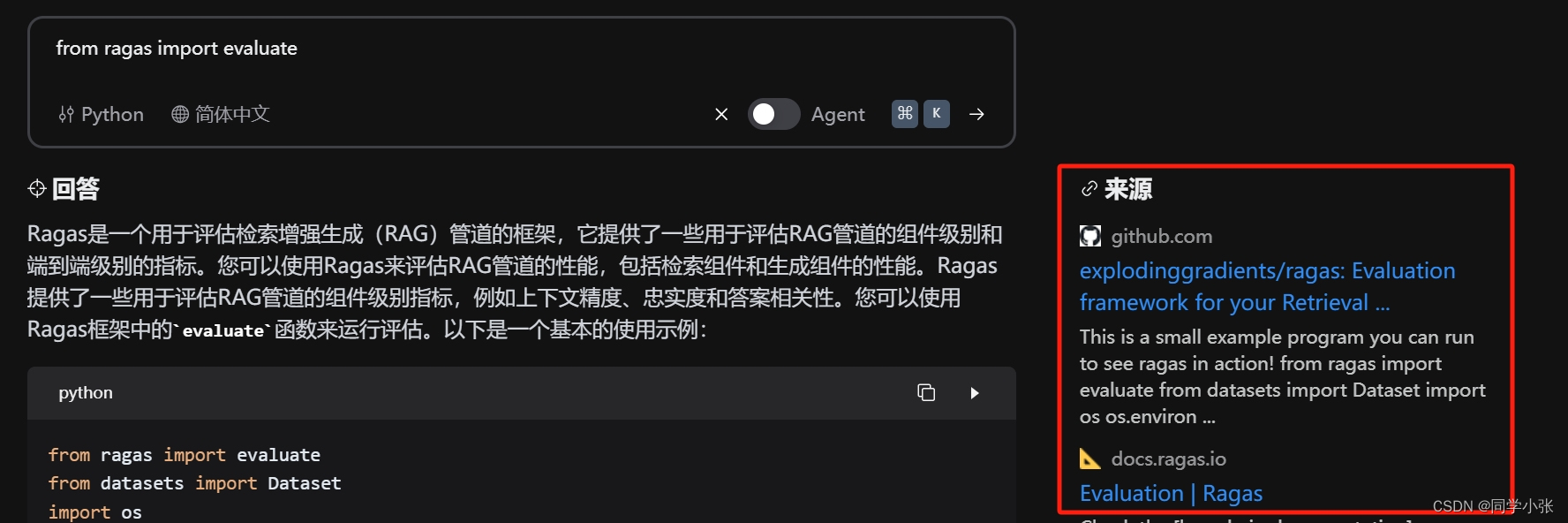
在结果中添加该结果的参考来源是RAG问答中非常重要的一环,一方面让我们更加了解答案的生成原理和参考内容,防止参考错误的文档,另一方面,可以展示给用户,我们的答案是有参考的,不是胡说,增加信任度。例如下面这个检索工具的展示,有了来源之后,显得更加专业和更高的可信度:
1. 代码实现
参考:
- https://python.langchain.com/docs/use_cases/question_answering/quickstart
- https://python.langchain.com/docs/use_cases/question_answering/sources
1.1 加载网页数据
loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ), ) docs = loader.load()代码中以加载 https://lilianweng.github.io/posts/2023-06-23-agent/ 链接的数据为例。
使用 WebBaseLoader 进行数据加载。WebBaseLoader 是LangChain封装的专门用于加载网页数据的类。其定义和初始化参数如下,原理就是利用 urllib 加载html页面,然后通过BeautifulSoup进行Html解析,找出其中指定tag的内容。以上代码中 class_=("post-content", "post-title", "post-header") 表明只提取HTML页面中这些tag的数据。
class WebBaseLoader(BaseLoader): """Load HTML pages using `urllib` and parse them with `BeautifulSoup'.""" def __init__( self, web_path: Union[str, Sequence[str]] = "", header_template: Optional[dict] = None, verify_ssl: bool = True, proxies: Optional[dict] = None, continue_on_failure: bool = False, autoset_encoding: bool = True, encoding: Optional[str] = None, web_paths: Sequence[str] = (), requests_per_second: int = 2, default_parser: str = "html.parser", requests_kwargs: Optional[Dict[str, Any]] = None, raise_for_status: bool = False, bs_get_text_kwargs: Optional[Dict[str, Any]] = None, bs_kwargs: Optional[Dict[str, Any]] = None, session: Any = None, ) -> None: """Initialize loader. Args: web_paths: Web paths to load from. requests_per_second: Max number of concurrent requests to make. default_parser: Default parser to use for BeautifulSoup. requests_kwargs: kwargs for requests raise_for_status: Raise an exception if http status code denotes an error. bs_get_text_kwargs: kwargs for beatifulsoup4 get_text bs_kwargs: kwargs for beatifulsoup4 web page parsing """怎么查看网页中想要提取的数据的tag?参考这篇文章:【提效】让GPT帮你写爬虫程序,不懂爬虫也能行
1.2 数据分块
指定分块方式:RecursiveCharacterTextSplitter,这个在之前咱们也介绍过(这篇文章),它就是将文本块分成 1000 字左右的段,相邻段之间有 200 字左右的重复,以保证相邻段之间的上下文连贯。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) splits = text_splitter.split_documents(docs)
1.3 数据向量化和存储
使用 Chroma 作为向量数据库,向量化计算采用 OpenAIEmbeddings 接口和模型。
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
1.4 向量检索
将向量数据库作为 retriever。
retriever = vectorstore.as_retriever()
1.5 组装Chain
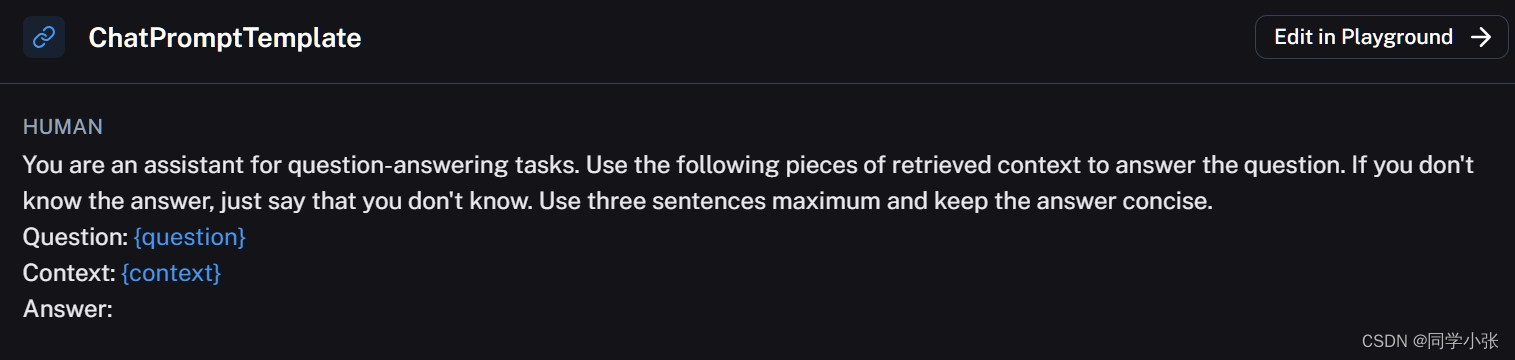
prompt = hub.pull("rlm/rag-prompt") llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs) rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() )(1)首先是Prompt,直接使用 hub.pull("rlm/rag-prompt") 加载一个Prompt模板,也可以自己写。加载到的Prompt模板内容:
(2)以上Prompt接收两个参数:context 和 question,所以chain组装的第一步就是传递这两个参数。
(3)整体解释下以上 rag_chain 的数据流:
- retriver先运行,检索回来信息
- 检索回来的信息给 format_docs,组装信息
- 组装信息后填到context Key里,连同 question Key内容一起给 prompt
- prompt 给 llm
- llm 结果给 StrOutputParser
1.6 运行
通过 invoke 函数运行。
result = rag_chain.invoke("What is Task Decomposition?") print(result)别忘了所有的依赖:
import bs4 from langchain import hub from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter
运行结果:

2. 加入Sources(答案来源)
2.1 代码修改
加入Sources很简单,主要改下 Chain 的组装:
from langchain_core.runnables import RunnableParallel rag_chain_from_docs = ( RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"]))) | prompt | llm | StrOutputParser() ) rag_chain_with_source = RunnableParallel( {"context": retriever, "question": RunnablePassthrough()} ).assign(answer=rag_chain_from_docs)先不管它是如何实现的,先运行看下结果:
result = rag_chain_with_source.invoke("What is Task Decomposition") print(result)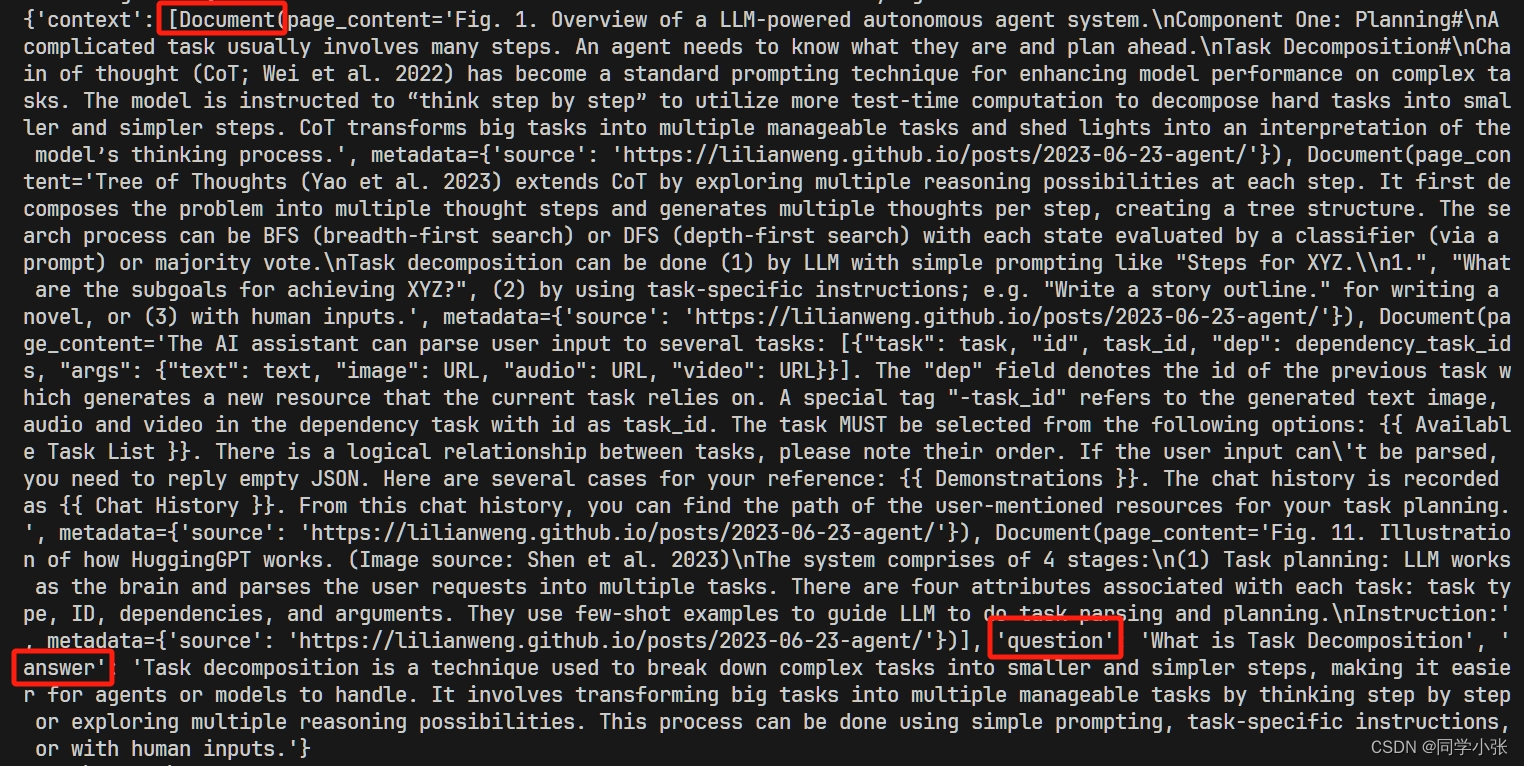
2.2 代码解释
看到结果后应该就对这段程序有了一个感性的认识。下面我们来看下这段程序是如何实现的。
从 rag_chain_with_source 开始看。
rag_chain_with_source = RunnableParallel( {"context": retriever, "question": RunnablePassthrough()} ).assign(answer=rag_chain_from_docs)它使用了 RunnableParallel 来传递 context 的值 和 question 的值。
RunnableParallel().assign() 实现的功能就是将以上{}的内容传递给assign函数的参数,也就是传递给rag_chain_from_docs。
那么rag_chain_from_docs中RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"]))),这里的x就知道是什么了:{"context":xxxx, "question":xxxx}。x["context"]也就是将检索出的文档进行组装。
然后rag_chain_from_docs的返回值:answer=rag_chain_from_docs,就是将返回值填到 "answer"为Key的值中。
最后,rag_chain_with_source的返回值就是刚开始的 "context", "question",再加上后面的 "answer"。
3. 总结
简单总结一下本文内容。
本文利用 LangChain 实现了一个完整的问答RAG应用。
其中RAG中的数据源采用加载网页数据的形式获取,而不是采用之前实践中传统的本地知识库(加载本地PDF文件)的方式。
然后我们还在RAG的返回中增加了参考文本的输出,这是之前我们没有实践过的,算是一点新知识。在实现这个功能的过程中,最主要的是学会使用 LangChain 中提供的 RunnablePassthrough 和 RunnableParallel 进行值的传递。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是 同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
- 【AI大模型应用开发】【LangChain系列】实战案例2:通过URL加载网页内容 - LangChain对爬虫功能的封装
- 【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用







