

前言
23年7月,我在朋友圈评估Google的RT2说道:
- “大模型正在革新一切领域啊,超帅,通过大模型不仅能理解“人话”,还能对“人话”进行推理,并转变为机器人能理解的指令,从而分阶段完成任务。回头仔细看下论文”
- 当时便对大模型机器人印象深刻,一直想仔细研究下来着,但因为后来一直和团队忙于论文审稿GPT、企业知识库问答等项目,所以一直没抽出时间去深入研究
没成想,前几天,斯坦福的炒菜机器人火爆全网,再次让包括我在内的所有人目瞪口呆,再次在朋友圈评论道:
- 多模态 + 大模型 + AI agent可以全方位赋能机器人
一年前我决心彻底写清楚ChatGPT原理
一年前,因为对ChatGPT背后技术原理巨大的「好奇心」,加之极高的「分享热情」、以及想写一篇关于其原理最全面 最深入 最细致文章的「决心」,彻底改变了过去一年的轨迹最后,博客证明了技术研究能力,课程证明了教学教研能力,项目证明了带队开发能力
一年后的今天,我下定决心准备彻底研究下机器人
- 刚好今年q1本身要做一个AI agent小项目,希望q2起,有机会做这个机器人agent大项目,如能和某高校实验室或资本合作更好
说干就干
- 一方面,我组建了一个斯坦福机器人复现小组(里面有CMU机器人方向博士毕业的),准备复现斯坦福这个炒菜或家务机器人
- 二方面,我准备把大模型机器人的发展史以及其中涉及到的所有关键技术细节,全部都梳理一下(毕竟新闻稿只能看个大概,但想精准理解,必须结合一系列论文理解)
总之,不要看一篇新闻稿觉得很行,再看一篇 又觉得不行了,不要人云亦云 被新闻稿带节奏(比如,虽然其有些动作是被远程操控完成的,但还是有很多动作是其自主完成,比如对于一些简单的任务,Mobile ALOHA可以在50次学习之后达到90%的行动成功率),行与不行,得花几个月尝试下才可知,我们今年Q1之内的三个步骤:
- 先做技术准备
- 复现团队复现Mobile ALOHA
- 建后续迭代优化的机器人开发团队,作为我司的第4项目组
第一部分 纽约大学:Dobb·E——把机器人带回家
1.1 Dobb·E:基于预训练模型和微调的行为克隆
在这项工作中,纽约大学一研究团队通过引入Dobb-E(这是其论文:On Bringing Robots Home,Submitted on 27 Nov 2023),提出了家庭教学机器人的框架,其只需五分钟就能学会一项新任务,这要归功于用廉价零件和iphone制作的示范收集工具,具体来说,Dobb-E的关键组件包括:
- 硬件方面,主要使用了一种名为“棒”的演示收集工具(如下图A所示,相当于数据收集工具,然后可以在机器人上使用类似的设置,如下图C所示,最终机器人本身通过模仿人类的操作实现行为克隆,如下图D所示),该工具结合了3D打印组件和iPhone的可负担伸展抓取器。此外,将iPhone安装在机器人上,以便实现从棒直接传输数据,无需进行域适配
Hardware: The primary interface is our demonstration collection tool, termed the "Stick." It combines an affordable reacher-grabber with 3D printed components and an iPhone. Additionally,an iPhone mount on the robot facilitates direct data transfer from the Stick without needing domain adaptation.
- 预训练数据集:使用棒工具收集了一个为期13小时的数据集,名为纽约只家(HoNY),其中包含来自22个纽约家庭共216个环境的5620个演示。这些演示支持我们系统的适应性,并被用于Dobb-E预训练表示模型
Pretraining Dataset: Leveraging the Stick, we amass a 13 hour dataset called Homes of NewYork (HoNY), comprising 5620 demonstrations from 216 environments in 22 New York homes,bolstering our system's adaptability. This dataset serves to pretrain representation models forDobb-E. - 模型和算法:基于预训练数据集,我们成功构建了一种流线型视觉模型,即家庭预训练表示(HPR),并采用先进的自监督学习(SSL)技术进行训练。对于新任务而言,仅需进行24次迭代调整即可微调该视觉模型,并结合视觉和深度信息来实现3D推理
Models and algorithms: Given the pretraining dataset we train a streamlined vision model, called Home Pretrained Representations (HPR), employing cutting-edge self-supervised learning (SSL)techniques. For novel tasks, a mere 24 demonstrations sufficed to finetune this vision model,incorporating both visual and depth information to account for 3D reasoning. - 集成:我们的整体系统,封装硬件,模型和算法,以商用移动机器人为中心:Hello Robot Stretch
最终让Dobb-E在10个家庭中进行了为期30天的实验,在此期间,它尝试了109个任务,并成功学习了102个任务,其表现为50%,总体成功率为81%。同时,发现
- 简单方法的惊人效果:Dob-E采用了视觉模仿学习的简单行为克隆配方,利用ResNet模型[Deep residual learning for image recognition]进行视觉表示提取,并使用双层神经网络[The perceptron: a probabilistic model for information storage and organization in the brain,这竟然是1958年的一篇老论文,我是没想到的,^_^ ]进行动作预测
Surprising effectiveness of simple methods: Dobb-E follows a simple behavior cloning recipefor visual imitation learning using a ResNet model [5] for visual representation extraction anda two-layer neural network [6] for action prediction平均而言,仅通过收集每个任务在5分钟内91秒的数据,Dob-E能够在家中实现81%的成功率
- 有效SSL预训练对结果产生了影响:我们基于家庭数据训练的HPR基础视觉模型,在与其他基础视觉模型相比,在更大规模互联网数据集上训练时至少提高了23%任务成功率
Impact of effective SSL pretraining: Our foundational vision model, HPR trained on home dataimproves tasks success rate by at least 23% compared to other foundational vision models [7-9],which were trained on much larger internet datasets - 里程计、深度和专业知识:Dob-E的成功在很大程度上依赖于操纵杆提供高度准确的里程计和iPhone姿态与位置感应动作,以及iPhone激光雷达所提供的深度信息。此外,收集演示数据的易用性也使得使用操纵杆进行迭代研究问题变得更加快速、便捷
Odometry, depth, and expertise: The success of Dobb-E is heavily reliant on the Stick providinghighly accurate odometry and actions from the iPhones' pose and position sensing, and depthinformation from the iPhone's Lidar. Ease of collecting demonsrations also makes iterating onresearch problems with the Stick much faster and easier - 剩余挑战:机器人力量、范围和电池寿命等硬件限制限制了机器人可以解决物理任务的能力(详见第3.3.3节),而该策略框架则受到模糊感知和更复杂临时扩展任务等因素影响
本质上,Dob-E是一个行为克隆框架[10]。而行为克隆是模仿学习的一种形式,通过观察和模仿人类或其他专家代理的行为来学习执行任务。行为克隆涉及训练模型以模仿演示的动作或行为,并通常使用标记的训练数据将观察映射到期望的动作
- 在我们的方法中,我们首先对一个轻量级基础视觉模型进行预训练,在家庭演示数据集上进行实验
- 然后在新家庭中给定新任务时,收集了一些演示并微调我们的模型以解决该任务
整个方法可以分为4个阶段:
- 设计一个硬件设置,以便收集演示及其无缝转移到机器人身上
- 在不同的家庭中使用该硬件设置收集数据
- 对该数据上预训练基础模型(pretraining foundational models on this data)
- 将经过训练的模型部署到家庭中
1.1.1 硬件设计
该系统并未要求用户移动整个机器人,而是利用一款价格便宜的25美元可伸缩末端执行器创建了一个“你好机器人”的复制品,并通过3D打印的iPhone支架进行增强,此外,iPhone Pro(版本12或更新)配备的摄像头设置和内部陀螺仪能够以每秒30帧的速度获取RGB图像、深度数据以及6D位置信息(包括平移和旋转)

使用已安装在iPhone上的Record3D来捕获演示数据,该应用程序能够保存
- 从相机记录的1280×720像素的RGB数据
- 激光雷达传感器记录的256×192像素的深度数据(注意,如paper第21页最后所说,adding depth perception to the model helps it perform much better than the model with RGB-only input)
不过,最终模型训练时,上面这两块数据会被缩放到256×256像素 - 以及iPhone内部的里程表(odometry)和陀螺仪记录的手柄运动(6D的平移和旋转数据)
然后以30 FPS速率将这些数据记录到手机中,并进行导出和处理
所有的系统都部署在Hello Robot Stretch上,这是一款单臂移动机械手机器人,已经可以在公开市场上购买。我们在所有实验中使用Stretch RE1版本,其灵巧的手腕附件赋予了机器人6D运动能力。它成本低廉、便携轻便(仅重51磅/23公斤),并且可以通过电池供电长达两个小时。此外,Stretch RE1还配备了Intel NUC计算机,可以以30 Hz的频率运行学习策略
1.1.2 对预训练数据集(Pretraining Dataset)的大量收集
凭借上面的硬件设置,只需将手柄带回家,将iPhone连接到手柄上,并使用Record3D应用程序记录时进行任何演示者想要展示的操作,最终在一些志愿者的协助下收集了一个名为纽约之家(HoNY)的家庭任务数据集
- 该数据集由22个不同家庭中志愿者共同创建,在总计13小时录制时间内包含5620个演示视频,总计近150万帧图像
- 志愿者专注于八个广泛定义好的任务类别:开关按钮、开门、关门、抽屉打开、抽屉关闭、拣选和放置物品、手柄抓取以及游戏数据。对于游戏数据,我们要求志愿者记录他们使用手柄在家中进行任意活动时产生的相关数据。这种有趣行为过去已被证明对表示学习目标具有潜力[21, 24]
- 指导志愿者花费约10分钟来记录他们所处环境或场景中每个演示视频。最初选择的演示任务是多样化且具有一定挑战性,但对机器人而言仍然可行
尽管iPhone可以提供末端执行器的姿态数据(the pose of the end-effector),但无法直接获取夹持器本身的开启或关闭状态。为了解决这一问题,我们训练了一个模型来追踪夹持器尖端
- 从数据集中选取了500个随机帧,并在这些帧上使用像素坐标标记了两个夹持器尖端的位置
- 然后,利用该数据集对一个由三层ConvNet构成的夹持器模型进行训练,该模型试图将夹持器尖端之间的距离预测为0到1之间的标准化数值,该模型在heldout评估集上获得了0.035的MSE验证误差(以0-1尺度表示)
We trained a gripper model on that dataset, which is a3-layer ConvNet that tries to predict the distance between the gripper tips as a normalized number between 0 and 1随后被用于标记数据集中其余帧中夹持器的值(介于0到1之间)
1.1.3 Policy Learning with Home Pretrained Representations
拥有多样化的家庭数据集之后,下一步的任务是训练一个基础的视觉模仿模型,以便在家中进行轻松地修改和部署。他们的策略由两个简单组件构成:一个视觉编码器和一个策略头
- ResNet34足够小,可以在机器人的机载计算机上运行
使用MoCo-v3自监督学习算法在我们收集的数据集上对视觉编码器进行60个epochs的预训练,称这个模型为家庭预训练表示(HPR)模型,部署的所有策略都是基于这个模型训练的
We pretrainour visual encoder on our collected dataset with the MoCo-v3 self-supervised learning algorithm for60 epochs. We call this model the Home Pretrained Representation (HPR) model, based on which allof our deployed policies are trained.且比较了使用我们自己的视觉编码器与在不同数据集和算法上训练的视觉编码器(如R3M [8]、VC1 [9]和MVP [7])甚至只是在ImageNet-1K [59]上进行预训练后效果之间 的差异
We compare the effects of using our own visual encoder vs. apretrained visual encoder trained on different datasets and algorithms, such as R3M [8], VC1 [9], andMVP [7], or even only pretraining on ImageNet-1K [59], in Section 3.4.1. - 下游策略学习方面,在每个新任务中,根据所捕获到深度值和视觉编码器进行简单操纵策略学习。该策略输入空间为256×256像素大小RGB-D图像(4通道),输出空间为一个7维向量,其中前三个维度表示相对平移,接下来三个维度表示相对旋转(轴角表示),最后一个维度表示夹持器值范围介于0到1之间
Downstream Policy Learning On every new task, we learn a simple manipulation policy based onour visual encoder and the captured depth values. For the policy, the input space is an RGB-D image(4 channels) with shape 256×256 pixels, and the output space is a 7-dimensional vector, where thefirst 3 dimensions are relative translations, next 3 dimensions are relative rotations (in axis anglerepresentation), and the final dimension is a gripper value between 0 and 1.
具体而言,我们设计了一个简单结构用于实现该策略:首先应用于RGB通道的图像表达模型,并通过中位池化操作应用于深度通道;然后经过两层全连接层将512 维图像表达和512 维深度值投影到7 维动作空间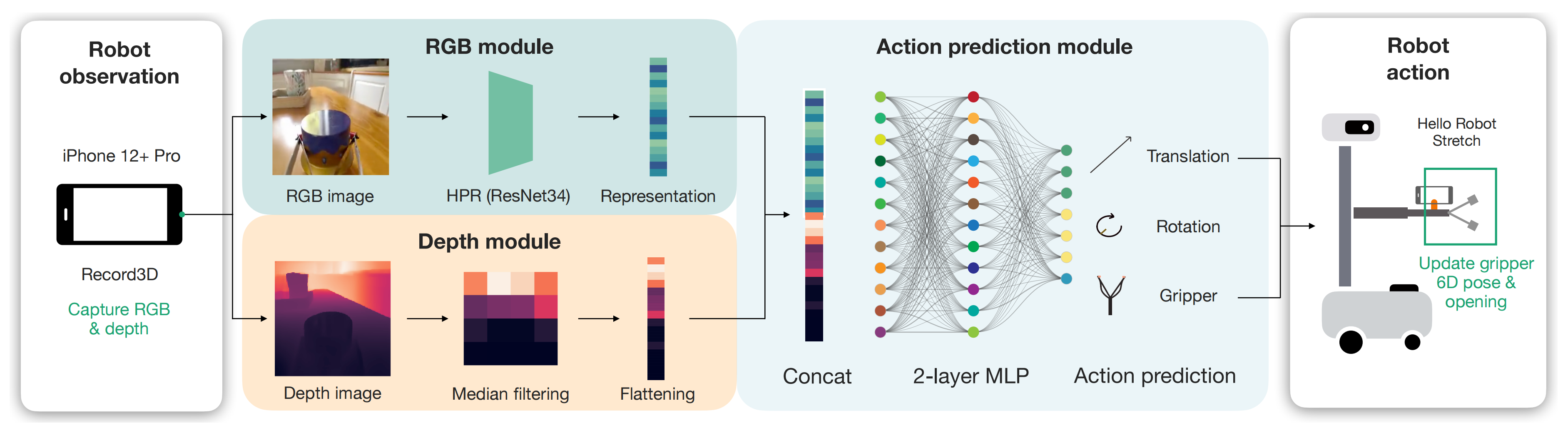
Our policy is learned topredict an action at 3.75 Hz, since that is the frequency with which we subsample our trajectories. The policy architecture simply consists of our visual representation model applied to the RGB channelsin parallel to a median-pooling applied on the depth channel, followed by two fully connected layersthat project the 512 dimensional image representation and 512 dimensional depth values down to 7dimensional actions.在监督训练期间, 网络从观察到动作映射进行学习, 并未冻结任何参数, 学习速率设置为 3×10^−5 进行50次迭代更新(During this supervised training period where the network learns to map fromobservation to actions, we do not freeze any of the parameters, and train them for 50 epochs with alearning rate of 3×10 −5)
网络采用均方误差(MSE)损失函数进行训练,在计算损失之前将每个轴上动作标准化为零均值和单位标准差 (We train our network with a mean-squared error (MSE) loss, and normalizethe actions per axis to have zero mean and unit standard deviation before calculating the loss)
1.1.4 部署到一个新的家庭
为了解决新任务,首先简要收集一些任务示范。通常会收集24个新示范作为经验数据,对于简单的5秒任务来说这是足够的。在实际操作中,收集这些示范大约需要5分钟时间。然而,在某些环境下重置所需时间更长,在这种情况下,收集示范可能需要更多时间
- 为了使机器人策略具备一定的空间泛化能力,我们通常从任务设置前各种位置开始收集数据,并且通常在一个小型4×6或5×5网格中进行

- 一旦数据收集完成,将R3D文件中的数据转换为数据集格式需要约5分钟。接着,在GPU RTX A4000上进行50次训练平均需时约20分钟。因此,从开始数据收集到获得可在机器人上部署的策略,平均时间为30分钟
- 然后使用安装在手臂上的iPhone和Record3D应用程序,通过USB将RGB-D图像流传输到机器人计算机上。为了获得预测动作,我们对输入图像和深度进行处理。利用基于PyKDL的逆运动学求解器,在机器人末端执行器上执行预测的相对动作
We use the iPhone mounted on the arm and the Record3D app to stream RGB-Dimages via USB to the robot computer. We run our policy on the input images and depth to get the predicted action. We use a PyKDL based inverse kinematics solver to execute the predicted relative action on the robot end-effector.由于模型预测摄像头帧中的运动,我们在机器人URDF中添加了一个关节来连接额外摄像头,从而可以直接执行预测动作,无需精确计算从摄像头帧到机器人末端执行器帧之间的转换
Since the model predicts the motion in the camera frame, we addeda joint in the robot’s URDF for the attached camera, and so we can directly execute the predicted action without exactly calculating the transform from the camera frame to the robot end-effectorframe对于夹持关闭操作,采用二进制方式根据任务变化应用阈值来预测夹持状态。通过接收观察并命令机器人执行策略预测的动作,并等待其完成以接收下一个观察,在机器人上同步运行策略
For the gripper closing, we binarize the predicted gripper value by applying a threshold that can vary between tasks. We run the policy synchronously on the robot by taking in an observation,commanding the robot to execute the policy-predicted action, and waiting until robot completes theaction to take in the next observation. - 针对评估实验,通常每个任务会使用10个不同初始起始位置(如上图b所示),这些起始位置改变了机械臂夹持装置垂直和水平方向上的初始位置。在这10次试验之间,我们会手动重置机械臂和环境
For our evaluation experiments we generally use 10 initialstarting positions for each robot task (Figure 9 (b)). These starting positions vary our robot gripper’s starting position in the vertical and horizontal directions. Between each of these 10 trials, we manuallyreset the robot and the environment.
第二部分 Berkeley Gello
// 待更
第三部分 斯坦福机器人Mobile ALOHA:炒菜、家务全活了
4.1 Mobile ALOHA与其前身ALOHA
4.1.1 Mobile ALOHA:通过示范数据做行为克隆,更结合前身ALOHA的静态数据做协同训练
在机器人技术领域,通过对人类示范进行模仿学习已经取得了令人瞩目的成绩。然而,目前大多数研究结果都集中在桌面操作上,缺乏完成一般任务的移动性和灵活性
近日,斯坦福一研究团队(Zipeng Fu、Tony Z. Zhao、Chelsea Finn)开发了一个系统:Mobile ALOHA
- 项目地址(可总览所有重要信息):https://mobile-aloha.github.io/
- 论文地址:Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- 硬件代码:hardware code之mobile-aloha
- 软件代码:learning code之act-plus-plus,本质就是ACT(关于什么是ACT,详见下节)

- 数据地址:public_mobile_aloha_datasets
- 硬件安装指南:Mobile ALOHA 🏄 Tutorial,该文档中涵盖了安装前身ALOHA的指南链接(简单粗暴理解的话,mobile aloha相当于在其前身aloha的基础上增加了移动底盘,即mobile aloha = aloha + mobile,至于前身ALOHA的更多信息详见下节)

由于其可以做各种家务,比如炒菜、刷碗等等,使得其一经发布便火爆全网
斯坦福家务机器人mobile-aloha
该系统用于模仿需要全身控制的双臂移动操作任务(In this work, we develop a systemfor imitating mobile manipulation tasks that are bi-manual and require whole-body control)

- 首先提出了Mobile ALOHA系统,作为低成本全身远程操作系统来收集数据(通过一个移动底座和一个全身远程操作界面增强了其前身ALOHA 系统)
We first present Mobile ALOHA, a low-cost and whole-body teleoperation system for data collection. It augmentsthe ALOHA system [104] with a mobile base, and a whole-body teleoperation interface. - 之后利用Mobile ALOHA 收集的示范数据(说白了,人类先做示范,然后机器人向人类学习),进行有监督的行为克隆(behavioral cloning),且和其前身ALOHA收集到的静态(示范)数据进行协同训练co-training
Using data col-lected with Mobile ALOHA, we then perform super-vised behavior cloning and find that co-training with existing static ALOHA datasets boosts performance on mobile manipulation tasks. - 对于每个任务,只要用新平台采集的包含50条示范数据,然后结合前身ALOHA的静态示范数据,经过协同训练后成功率可达到90%,使得Mobile ALOHA能够自主完成复杂的移动操作任务,如炒虾、打开双门壁柜存放沉重的烹饪锅、呼叫并进入电梯以及使用厨房水龙头轻轻冲洗用过的平底锅。
With 50 demonstra-tions for each task, co-training can increase successrates by up to 90%, allowing Mobile ALOHA to au-tonomously complete complex mobile manipulation tasks such as sauteing and serving a piece of shrimp,opening a two-door wall cabinet to store heavy cook-ing pots, calling and entering an elevator, and lightlyrinsing a used pan using a kitchen faucet.
4.1.2 Mobile ALOHA的前置工作:ALOHA与ACT
Mobile ALOHA其实是在23年ALOHA的工作基础上迭代优化出来的,不是一蹴而就,以下是关于ALOHA的一系列重要信息
- ALOHA项目地址:https://tonyzhaozh.github.io/aloha/
- 论文地址:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
这是其解读,论文中首次系统阐述了作为“无论是最新系统Mobile ALOHA还是其前身系统ALOHA中的关键技术”:即动作分块算法ACT
- 代码地址:https://github.com/tonyzhaozh/aloha
该代码仓库友情提醒:To build ALOHA, follow the Hardware Assembly Tutorial and the quick start guide below.
To train imitation learning algorithms, you would also need to install ACT.
- 硬件安装指南:ALOHA 🏖️ Tutorial (文档标题为:ALOHA 🏖️: A Low-cost Open-source Hardware for Bimanual Teleoperation)
- 基于动作分块算法ACT的训练代码:https://github.com/tonyzhaozh/act
- 关于ALOHA的更多信息,以及到底什么是ACT,请详见此文:《斯坦福机器人Mobile ALOHA的关键技术:动作分块ACT的算法原理与代码剖析》
4.2 Mobile ALOHA 硬件
4.2.1 Mobile ALOHA 硬件的总体情况
在此之前
- 能够即插即用的全身遥控硬件是比较昂贵的,比如像PR2、TIAGo这样的机器人价格一般超过20万美刀
- 且之前的机器人也没法完成复杂的需要双手互相配合的各种灵活操作,毕竟人类的十指多么灵活
虽然最近的许多研究表明,在细粒度的多模态操作任务中,高表达能力的策略类方法(如扩散模型和Transformer)可以取得良好效果(While many recent works demon-strate that highly expressive policy classes such asdiffusion models and transformers can perform wellon fine-grained),但目前尚不清楚这些方法是否适用于移动操作:随着附加自由度增加,手臂与基础动作之间的相互作用可能变得复杂,微小偏差可能导致手臂末端执行器姿态大幅漂移
而Mobile ALOHA 是一种低成本的移动机械手,可以执行各种家庭任务,其继承了原始 ALOHA 系统的优点,即低成本、灵巧、可维修的双臂远程操作装置,同时将其功能扩展到桌面操作之外,且重点做到了以下4点
- 移动能力:移动速度与人类行走速度相当,约为1.42m/s
- 稳定性:在操作重型家用物品(比如锅和橱柜)时它能保持稳定
- 全身遥控操作:手臂和底盘可以同时运动
- 无线:具有机载电源和计算设备(数据收集和推断期间的所有计算都是在配备了Nvidia 3070 Ti GPU (8GB VRAM)和Intel i7-12800H的消费级笔记本电脑上进行)
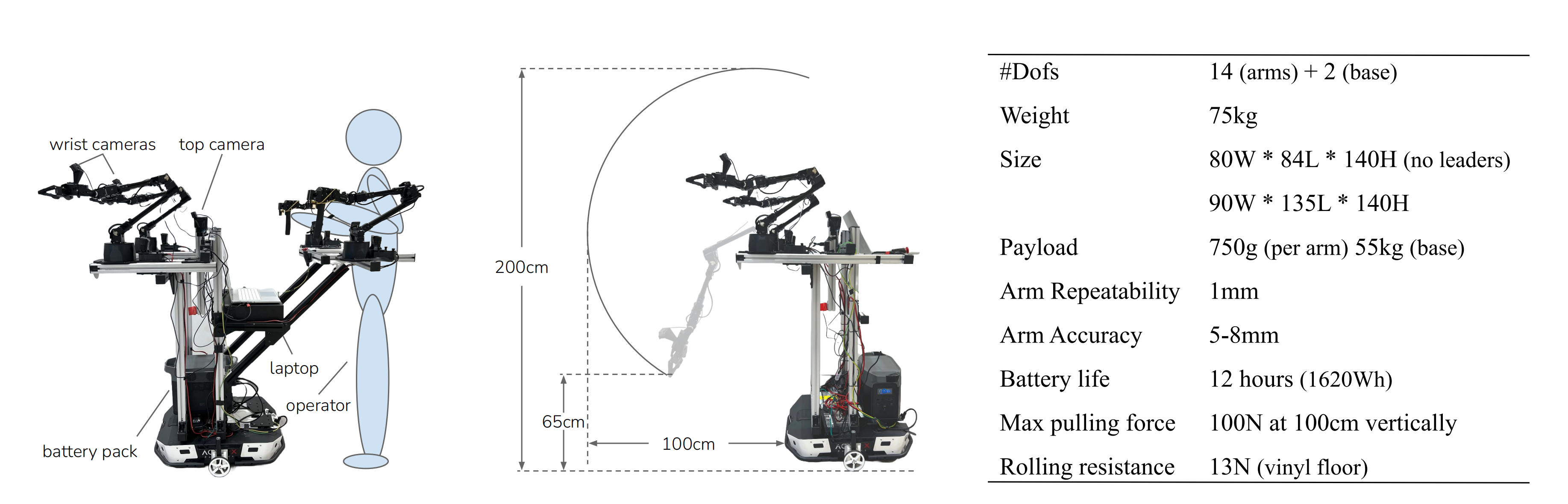
如上图所示
- 上图左侧部分(Mobile ALOHA has two wrist cameras and one top camera, with onboard power and compute)
展示了研究者发现将操作员的腰部与移动底座系在一起的设计是最简单直接的解决方案
- 上图中间部分(Middle: The teleoperation setup can be removed and only two ViperX 300 [3] are used during autonomous execution. Both arms can reach a min/max height of 65cm/200cm, and extends 100cm from the base)中的数据表明
机械手相对于地面的垂直高度为 65 厘米至 200 厘米,可伸出底座 100 厘米,可举起 1.5 千克重的物体,并可在 1.5 米高处施加 100 牛的拉力
这样的设计让 Mobile ALOHA 可以完成很多任务,包括实物烹饪、家务管理、人机互动等
- 上图右侧部分中列出了 Mobile ALOHA 的更多技术规格
除了现成的机器人外,研究者还开源了所有的软件和硬件部件,并提供了详细的教程,包括三维打印、组装和软件安装
4.2.2 硬件材料清单与硬件制作步骤
首先,准备一系列硬件材料,比如
- 三个罗技C922x RGB的网络摄像头,分辨率为480 × 640,频率为50Hz(两个摄像头安装在跟随者机器人的手腕上,第三个摄像头面向前方)
- 笔记本电脑还通过USB串行端口接收来自所有4个手臂的本体感觉流,通过CAN总线接收来自移动的轮式底盘Tracer的本体感觉流
4.2.2.1 硬件材料清单Bill of Materials
Part
Quantity
Link
Price
(per unit)
Robots
从动臂ViperX 300 Robot Arm 6DOF
2
ViperX 300 Robot Arm 6DOF
$5,695.95
主动臂WidowX 250 Robot Arm 6DOF
2
WidowX 250 Robot Arm 6DOF - X-Series Robotic Arm
$3,295.95
移动的轮式底盘Tracer AGV
1
AgileX Tracer AGV
$8,999.95
Onboard Compute
Lambda Labs Tensorbook
1
Deep Learning Laptop - RTX 3080 Max-Q | Razer x Lambda Tensorbook
$2,399.00
Robot Frame
4040 800mm x 8
4
Amazon.com (2 pcs)
$42.29
4040 500mm x 6
2
Amazon.com (4 pcs)
$58.99
4040 400mm x 2
2
Amazon.com (1 pcs)
$22.99
4040 300mm x 7
2
Amazon.com (4 pcs)
$59.99
4040 L-shape connectors x 28
5
Amazon.com (6 pcs)
$32.99
4040 T-shape connectors x 4
1
Amazon.com (6 pcs)
$30.99
4040 45-degree corner connectors
1
Amazon.com
$21.99
4040 Corner Bracket and T-Slot Sliding Nuts
2
Amazon.com
$24.99
4040 caps
2
Amazon.com
$9.81
M6 20mm
(for mounting robot)
1
Amazon.com
$9.99
M6 T nuts for 4040
(for mounting robot)
2
Amazon.com
$14.16
Camera setup
相机Logitech C922x Pro Stream Webcam
4
Amazon.com
$98.35
USB Hub
2
Amazon.com
$19.99
Power
Battery Pack
1
Amazon.com
$699.00
600W DC Supply
1
Amazon.com
$59.00
12V DC Cable
5
Amazon.com
$15.99
Fork Spade Connectors
1
Amazon.com
$13.69
USB-A to Micro USB Cable
4
Amazon.com
$17.87
Wheel Odometry
DYNAMIXEL XL430-W250-T
2
DYNAMIXEL XL430-W250-T - ROBOTIS
$49.90
U2D2
1
U2D2 - ROBOTIS
$32.10
U2D2 Power Hub Board Set
1
U2D2 Power Hub Board Set - ROBOTIS
$19.00
Jumper Wire
1
Amazon.com
$9.99
Weights
1
Amazon.com: ACCRETION 1 Oz Grey Adhesive Backed Wheel Weights (24 Oz Pack) : Automotive
$14.65
Misc
Rubber Band
1
Amazon.com
$9.99
Gripping Tape
1
Amazon.com
$54.14
Common equipments
Allen keys
Hot glue gun
Total
$31,757.8
4.2.2.2 3D Printed Parts
对于人遥控端和机器操作端方面的执行器,请按照ALOHA的教程进行操作:ALOHA 🏖️ Tutorial。关于wheel odometry,以下是所需零件的清单(共6件):
4.2.2.3 硬件安装指南Hardware Guide
硬件材料准备齐全后,按以下步骤一步步执行
- Install ALOHA end-effectors
通过6个步骤打造ALOHA:ALOHA 🏖️ Tutorial,单纯打造这个还不具备移动功能的ALOHA便得花费3万刀中的1.9万刀
- Build the robot frame
- Mount the robots and the cameras
- Cable connections
4.3 增加静态ALOHA 数据进行Co-training
4.3.1 静态ALOHA 数据的组成情况
对于机器人的训练,数据是一个很大的问题
- 使用模仿学习(imitation learning)来解决现实世界机器人任务的典型方法依赖于在特定机器人硬件平台上收集的目标任务数据集。然而,这种方法虽够但数据本身收集的过程过于冗长,因为在特定机器人硬件平台上,人类操作员需要从头开始为每个任务收集演示数据
The typical approach for using imitation learning to solve real-world robotics tasks relies on using thedatasets that are collected on a specific robot hard-ware platform for a targeted task. This straightfor-ward approach, however, suffers from lengthy datacollection processes where human operators collect demonstration data from scratch for every task onthe a specific robot hardware platform.且由于这些专门数据集中视觉差异有限,在这些数据集上训练得到的策略通常对感知干扰(如干扰和照明变化)不够鲁棒
The policie strained on these specialized datasets are often not ro-bust to the perceptual perturbations (e.g. distractorsand lighting changes) due to the limited visual diver-sity in these datasets [95] - 好在最近,在从不同但类似类型的机器人收集的各种真实数据集上进行co-training,在单臂操作和导航方面已经显示出了有希望的结果
Recently, co-training ondiverse real-world datasets collected from different but similar types of robots have shown promising results on single-arm manipulation [11, 20, 31, 61],and on navigation [79].
斯坦福的研究者在这项工作中便使用的Co-training,且利用现有的静态ALOHA 数据集来提高移动操作的模仿学习性能,尤其是双臂动作
- 不含移动底盘的前身ALOHA收集到的静态数据集总共有 825 个示范动作,任务包括密封密封袋、拿起叉子、包装糖果、撕纸巾、打开带盖塑料瓶、玩乒乓球、分发胶带、使用咖啡机、交接铅笔和操作螺丝刀等
需要注意的是,静态ALOHA 数据都是在黑色桌面上收集的,主动臂和从动臂都是固定在桌面上朝着对方(更多详见此文《斯坦福Mobile ALOHA背后的关键技术:动作分块算法ACT的原理解析》)
这种设置与移动 ALOHA 不同,移动 ALOHA 的背景会随着移动底盘的变化而变化,主动臂和从动臂的两臂均平行朝着前方
- 在Co-training中,研究者没有对静态ALOHA 数据中的 RGB 观察结果或双臂动作使用任何特殊的数据处理技术
4.3.2 基于两套数据(静态ALOHA示范数据和移动ALOHA示范数据)训练损失函数
任务
的移动操作策略
的训练目标是最小化模拟损失函数
其中
表示观察结果,包括两个手腕摄像头RGB(two wrist camera RGB observations)的、一个安装在手臂和手臂关节之间、以自我为中心的顶部摄像头RGB观察(top camera RGB observation mounted,其固定不动),和14维的从臂关节位置,如下图左上角所示
我们以相同概率从静态ALOHA数据
和移动ALOHA数据
中进行抽样(两者占比其实影响不大,比如
- 由于静态ALOHA数据没有移动基本动作,我们对动作标签进行零填充处理(zero-padding),使得来自两个数据集的动作具有相同维度,我们还忽略了静态ALOHA数据中的前置摄像头(front camera),因此两个数据集都有3个摄像头:2个wrist camera、1个top camera
Since static ALOHA datapoints have no mobile base actions, we zero-pad the action labels so actions from both datasets have the same dimension.We also ignore the front camera in the static ALOHA data so that both datasets have 3 cameras.怎么定位这个前置摄像头(front camera)呢,好在ALOHA的论文原文中标记了具体哪个是前置摄像头,详见
此文《斯坦福Mobile ALOHA背后的关键技术:动作分块算法ACT的原理解析》的1.2节)
- 同时,我们仅根据移动ALOHA数据集
We normalize every action based on the statistics of the Mobile ALOHA dataset Dm mobile alone - 在实验中,我们将这种协同训练方法与多种基本模仿学习方法(如ACT [Learning fine-grained bimanual manipulation with low-cost hardware]、扩散策略[Diffusion policy: Visuomotor policy learning via action diffusion]和VINN [The surprising effectiveness of representation learning for visual imitation])结合使用 In our experiments, we combine this co-training recipe with multiple base imitation learning approaches, including ACT [104], Diffusion Policy [18], and VINN [63]
再次提醒,关于ACT的技术细节包括其代码实现,详见此文《斯坦福Mobile ALOHA背后的关键技术:动作分块算法ACT的原理解析》,讲得非常细致
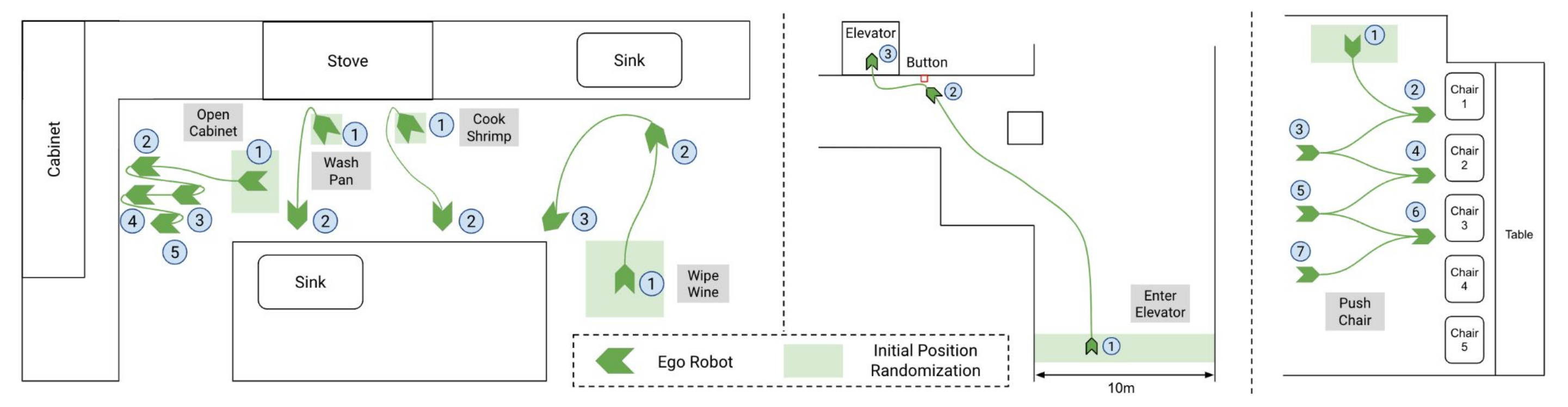
最终该团队选择了 7 个任务,它们涵盖了现实应用中可能出现的各种功能、对象和交互,分别是擦拭葡萄酒、煮虾、冲洗锅、使用橱柜、呼叫电梯、推椅子和击掌

下图则是机器人在执行任务时的导航移动轨迹
4.4 实验:协同训练是否有效提升ACT性能,且适合兼容多种模仿学习方法
在实验中回答两个核心问题:
- 移动ALOHA是否能够通过协同训练co-training和少量移动操作数据来获得复杂的移动操作技能?
Can Mobile ALOHA acquire complex mobile manipulation skills with co-training and a small amount of mobile manipulation data? - 移动ALOHA是否能够与不同类型的模仿学习方法一起工作,包括ACT、扩散策略和基于检索的VINN?
Can Mobile ALOHA work with different types of imita-tion learning methods, including ACT [104], Diffu-sion Policy [18], and retrieval-based VINN [63]?
作为初步研究,我们将使用“动作分块”[action chunking]这种方法,在该方法中一个策略预测未来一系列动作,而不是每个时间步只预测一个动作。这种方法已经被应用于ACT和扩散策略,并且可以简单地添加到VINN中(As a preliminary, all methods we will examine em-ploy “action chunking” [104], where a policy predictsa sequence of future actions instead of one action ateach time step)
- 采用动作分块对于操作至关重要,它提高了生成轨迹的一致性,并减少了逐步策略推断所带来的延迟
We found action chunking to be crucial formanipulation, improving the coherence of generated trajectory and reducing the latency from per-steppolicy inference. - 我们观察到移动基座目标速度与实际速度之间存在延迟,而位置控制手臂则具有更小的延迟。为了解释移动基座d步骤上出现的延迟情况,我们使机器人执行长度为k-d 的第一个k-d 手臂行为以及最后一个k-d 基座行为
We observe a delay between target and actual veloc-ities of our mobile base, while the delay for position-controlled arms is much smaller. To account for adelay of d steps of the mobile base, our robot exe-cutes the first k −d arm actions and last k −d baseactions of an action chunk of length k.
4.4.1 协同训练提高了性能且比预训练效果更好
研究发现,Co-training可以提高ACT性能。在7项具有挑战性的移动操作任务中,与静态ALOHA数据集进行Co-training可持续提高ACT的成功率
- 比如协同训练在擦拭酒的任务中的表现,成功率95%,大大优于预训练的成功率40%
在预训练过程中,作者首先用static ALOHA的数据训练了10k步,然后用mobile ALOHA的数据继续训练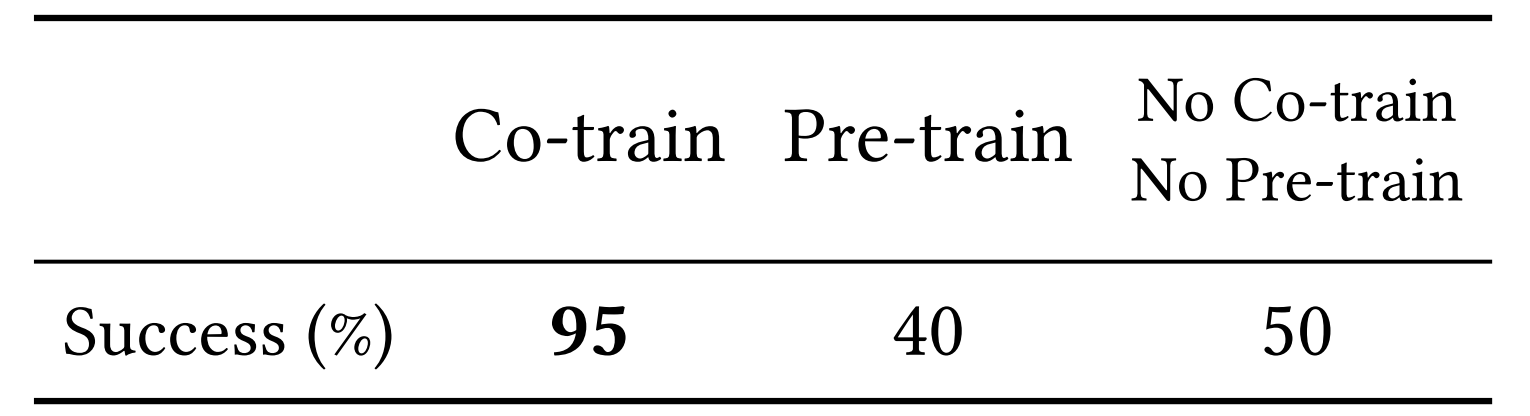
作者发现预训练的方式并没有提高模型的表现,猜测模型可能在使用mobile ALOHA数据进行微调的阶段已经忘记了在static ALOHA上学到的知识
- 那为何协同训练可以提高效果呢?作者认为,static ALOHA数据中关于抓取和接近物体的运动先验知识对训练mobile ALOHA的模型有很大帮助,尤其是其中腕部视角是具有不变性的,对场景的变换有较强的抗干扰能力
4.4.2 兼容ACT、扩散策略和VINN
除了ACT,还使用Mobile ALOHA训练了两种最新的模仿学习方法,即扩散策略[18]和VINN[63](We train two recent imitation learning methods,Diffusion Policy [18] and VINN [63], with Mobile ALOHA in addition to ACT.)
- 扩散策略通过逐步细化动作预测来训练神经网络。为提高推理速度,采用DDIM调度器并对图像观测应用数据增强以防止过拟合。co-training数据管道与ACT相同,在附录A中有更多的训练细节可供参考
Diffusion policy trains aneural network to gradually refine the action predic-tion. We use the DDIM scheduler [85] to improve in-ference speed, and apply data augmentation to image observations to prevent overfitting. The co-training data pipeline is the same as ACT, and we includemore training details in the Appendix A.3. - VINN利用BYOL[Bootstrap your own latenta new approach to self-supervised learning]训练一个视觉表示模型(简单地用移动和静态数据的组合对BYOL编码器进行co-training),并使用该模型从具有最近邻演示数据集中检索动作。且采用本体感知特征增强VINN检索,并调整相对权重以平衡视觉和本体感知特征的重要性
VINN trains a visual representation model, BYOL [37] anduses it to retrieve actions from the demonstrationdataset with nearest neighbors. We augment VINNretrieval with proprioception features and tune therelative weight to balance visual and proprioceptionfeature importance此外,进行了动作块的检索而非单个动作,并发现类似于Zhao等人的显著性能改进
We also retrieve an action chunkinstead of a single action and find significant per-formance improvement similar to Zhao et al.. For
总之,带分块的VINN、扩散策略和ACT在Mobile ALOHA上都取得了良好的性能,并且受益于与静态ALOHA的协同训练Co-training
当然,在协同训练Co-training的过程中
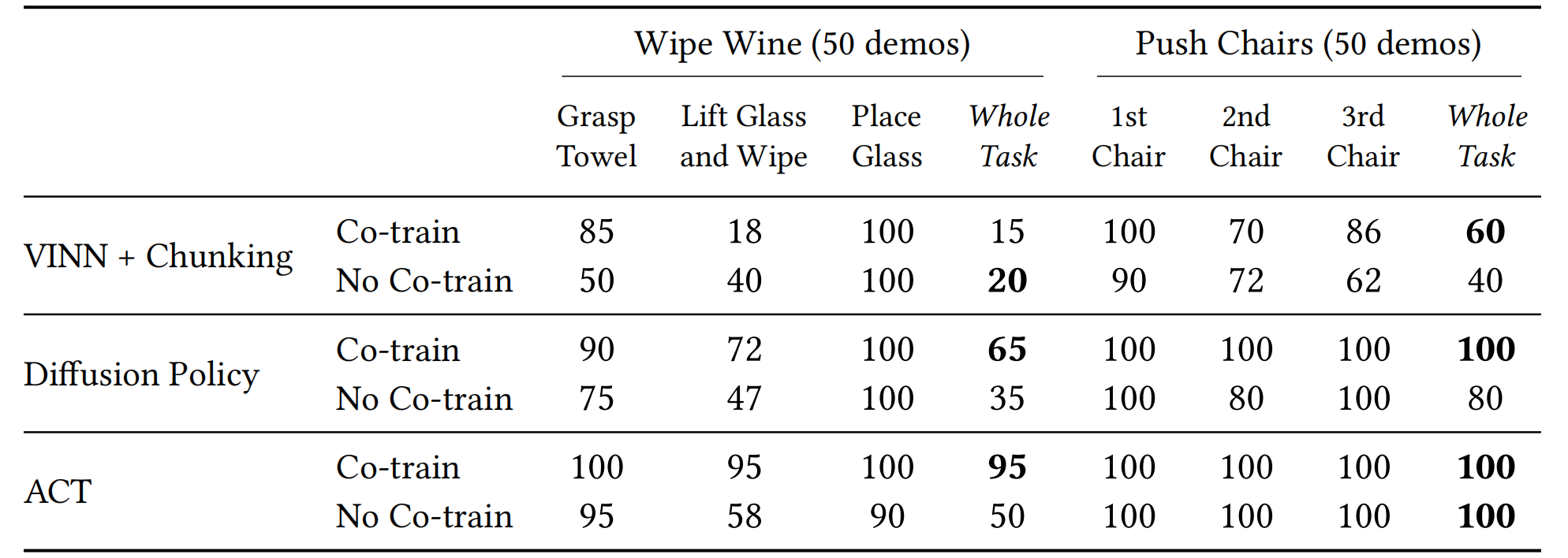
- ACT的表现最好
- diffusion policy略差
虽然它的模型表达能力比较强,但作者认为,50条的示教数据量可能不够
- VINN最差
比如对于VINN+擦红酒任务,Co-training的表现比起单独训练反而变差了,作者认为,这是由于VINN算法本身没有办法利用测试(应用)场景分布之外的数据(一种在测试时寻找训练集中nearest neighbour的方法),static ALOHA的数据对于VINN来讲就可能没那么有效
最终,仅用32000美元的预算,通过静态ALOHA数据Co-training的模仿学习,Mobile ALOHA只需要20-50个演示就能学会各种复杂的任务
斯坦福Mobile ALOHA向所有人展示了机器人在各种应用场景的潜力,甚至机器人开源实现了人人可复刻
第四部分 Google家务机器人
// 待更
第五部分 伯克利开源通用机器人学习的操控基准
7.1 Functional Manipulation Benchmark for Generalizable Robotic Learning
24年1月下旬,加州大学伯克利分校智能机器人实验室(RAIL)的研究团队提出了FMB(Functional Manipulation Benchmark for Generalizable Robotic Learning)
- 项目主页:https://functional-manipulation-benchmark.github.io/
- 论文地址:FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
- 共同第一作者主页:https://people.eecs.berkeley.edu/~jianlanluo/
- https://charlesxu0124.github.io/
7.1.1 物体和任务
FMB 中的任务大致分为两类:单物体多步骤操控任务和多物体多步骤操控任务。这些任务旨在测试机器人的基本技能,如抓取、重新定位和装配等,这些都是完成整个任务所必需的技能。FMB 中的任务要求机器人不仅能完成单一的操控技能,还要求机器人能够将这些技能组合起来,完成更为复杂的多步骤任务。
FMB 的任务设计灵活多变,研究人员可以根据需要选择专注于单一技能,深入研究机器人的操控能力,也可以研究完整的多步骤任务,这需要机器人进行长期规划并具备从失败中恢复的能力。由于涉及选择合适的物体并推理操控物体的顺序,更为复杂的多步骤任务要求机器人能够做出复杂的实时决策


7.1.2 大型数据集
为了使机器人更好地理解和掌握复杂的任务
- 研究团队收集了一个涵盖上述任务的大规模专家人类示范数据集,包含超过22550个操作轨迹
研究团队采用了4个不同的摄像机记录这些示范数据,其中两个摄像机安装在机器人的末端执行器上,另外两个安装在箱子两侧以提供全局视角(we have four Intel RealSense D405cameras, two of which are mounted on the robot end-effector, and the rest are placed on each side of the bin to provide a complementary view of objects inthe bin)
这些摄像机捕捉了对于机器人学习解决任务至关重要的 RGB 彩色图像信息、深度信息等数据,且提供了可做校准的相机内联功能,这种校准可以在必要时将深度图像转换为点云(We simultaneously capture RGB and depthimages from these cameras, and we also provide calibrated camera intrinsics. This calibration allows for the conversion of depth images into point clouds when necessary)

- 此外,数据集还记录了机器人末端执行器的力 / 扭矩信息,这对于像装配这样需要接触大量物体的的任务非常重要
通过这些丰富的数据,机器人能够深入理解任务的每个细节,更加精确地模仿人类的操作技巧。正是由于数据的深度和广度,为机器人学习提供了坚实的基础。这使得机器人在执行复杂任务时,能够更加人性化和更灵巧地对任务作出响应
7.2 FMB的模仿学习系统
7.2.1 基于 Transformer 和 ResNet 的两种策略模型
简而言之,基于 Transformer 和 ResNet 的两种模型都使用了共享权重的ResNet 编码器,让其对每个图像视图进行编码,然后与本体感知信息、可选的物体、以及相应的机器人技能编码特征结合,以预测 7 自由度的动作,具体而言
在下图左侧所示的基于Transformer的策略中,他们提出了一个仅解码器Transformer架构(最近的研究表明,在机器人控制中,Transformer的主要优势在于处理多模态输入和利用大规模、多样化数据集进行扩展)
且为了对来自多个摄像机视角的图像进行标记,他们采用了共享权重的ResNet-34编码器(We use weight-shared ResNet-34 encoders to tokenize images from multiple camera views)
- 但为了满足策略输入的需要,还在输入侧添加了FiLM层来对object ID或primitive ID进行条件处理
We additionally add FiLM (Perez et al., 2018) layers to condition on the object ID or primitive ID if they are required as part of the inputs to the policies. - 机器人本体信息通过MLP单独标记,并与正弦位置嵌入连接后通过具有4个注意力头和4个MLP层的自注意力层进行处理
Robot proprioceptive information is tokenized via an MLP separately. These tokens, after being concatenated together with sinusoidal position embeddings, are then processed through self-attention layers with four attention heads and four MLP layers. - 训练期间使用高斯量化器将连续6D机器人动作空间每个维度离散化为256个箱子,运行时向机器人发送命令时会将离散化动作空间转换回连续值
Each dimension of the continuous 6D robot actionspace is discretized into 256 bins during training byusing a Gaussian quantizer. The discretized actionspace is converted back into continuous values whensending commands to the robot at runtime.
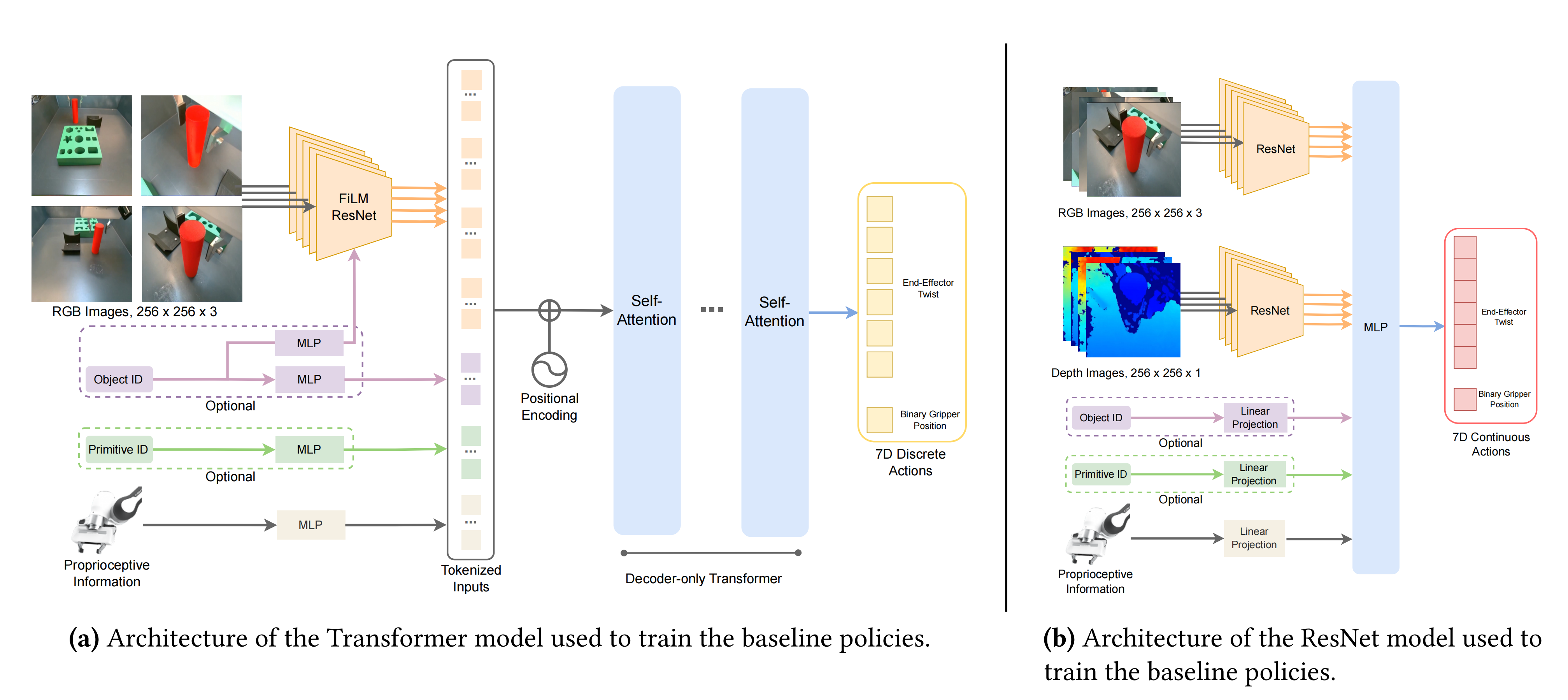
而在上图右侧所示的基于ResNet的策略中,该结构由ResNet-34视觉骨干和一个MLP作为策略头组成(It is composed of ResNet-34 vision backbones and an MLP as the policy head),且在所有任务中都采用这个通用结构,只对每个任务的特定输入进行调整
- 首先,对多张RGB图像和深度图像(且如paper 第11页右上角所述,同时使用深度和RGB信息训练的ResNet策略,始终优于使用相同数据数量训练的仅使用RGB的策略),使用共享权重的ResNets进行编码,然后再连接特征(It takes multiple RGB and depth images and encodes them separately with weight-shared ResNets before concatenating the features)
- 然后,如上图右侧的左下角所示,系统还融合了机器人本体感知信息(如末端执行器姿态、扭转或力/扭矩测量),在进行线性投影之后进入MLP层
It also takes the robot’s proprioceptive information, such as end-effector pose, twist, or force/torque measurements, then performs linear projection before being fed into the MLP且系统还能够调节object ID和manipulation skill ID,并以one-hot向量形式表示(这种机制对于处理长时间、多阶段任务非常重要),同样的,在进行线性投影之后进入MLP层
the system iscapable of conditioning on both the object ID and manipulation skill ID, which are represented as one-hot vectors,This mechanism is crucial for employing a hi-erarchical approach to effectively address long-horizon,multi-stage tasks. - 最终的输出结果包括6D末端执行器扭转和一个二进制变量,指示夹子是否应该打开或关闭(The output is a 6D end-effector twist as well as a binary variable that indicates whether the gripper should open or close)
7.2.2 多步骤任务的解决:分级控制 (hierarchical control)
对于一些简单任务,他们tested the performance of ResNet policies with and without action chunking(这个动作分块算法即斯坦福一研究团队提出的ACT),along with a Transformer-based policy without action chunking on seen and unseen objects.
- 在已见和未见物体上,ResNet策略没有动作分块时在旋转技能方面表现优于“有动作分块的ResNet策略”,和Transformer
The ResNetpolicy without action chunking outperforms its coun-terpart with action chunking and Transformer on therotate skill. - 然而,在夹具放置和重新抓取技能方面,相比有或没有动作分块的ResNet策略,Transformer策略表现更佳
In contrast, the Transformer policies out-perform ResNet policies with or without action chunk-ing for the place on fixture and regrasp skills但对于多步骤任务,传统的 ResNet、Transformer 和 Diffusion 方法均未能奏效,好在该论文中提出的分级控制 (hierarchical control) 方法显示出了潜力
具体而言
- 复杂任务要求机器人能够像人类一样连续完成多个步骤。此前的方法是让机器人学习整个过程,但这种方法容易因为单一环节的错误而不断累计误差,最后导致整个任务失败
无论是在单物体还是多物体操控任务中,这种方法的成功率均为 0/10
- 针对累积误差问题,研究团队采用了分层控制策略
分层策略通过将任务分解成若干小块,每完成一块便相当于通过一个决策点,即使出现错误也能迅速纠正,避免影响后续环节
例如,如果机器人在抓取过程中未能稳固抓住物体,human oracle会持续让机器人尝试直至成功(The hierarchical policiesuse a human oracle as the high-level policy)

虽说有人类的高级策略赋予一定的先验知识了,但到底用什么样的策略可以做更好呢
如下图所示,对于Multi-Object Multi-Stage Manipulation任务而言,分层策略采用人类预测作为高级策略,依次触发具有每个阶段适当的原始和对象ID的低级策略(sequentially triggering a low-level policy with the appropriate primitive and object IDs for each stage)
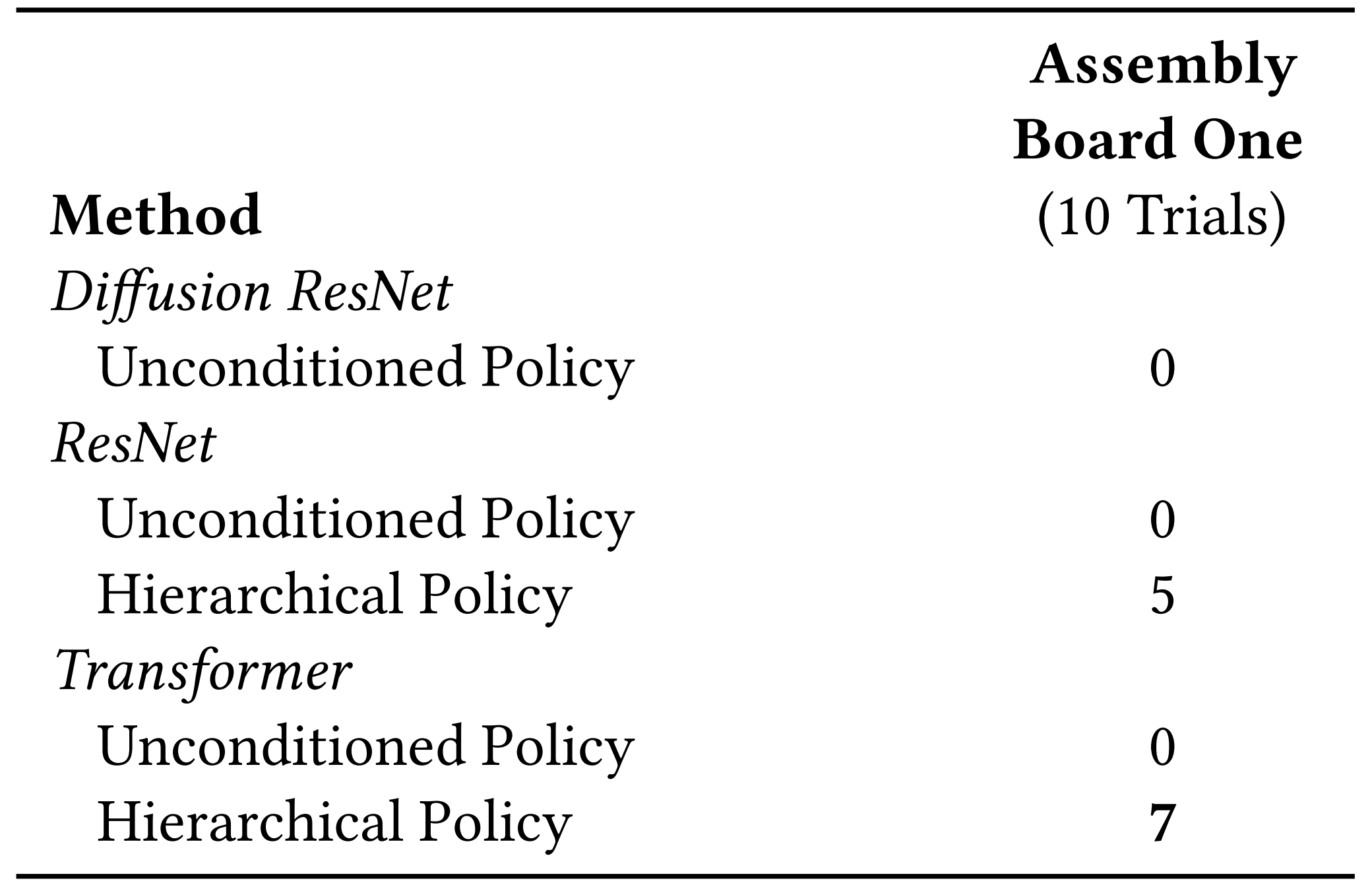
- 与单一对象聚类任务相似,所有无条件策略均未能成功。值得注意的是,基于Transformer的策略表现出色,成功率达到7/10(Similar to single-object ma-nipulation tasks, all unconditioned policies achieved zerosuccess. Remarkably, the Transformer-based policy outper-formed others, achieving a success rate of 7/10)
- 之所以如此,与基于ResNet的策略相比,基于Transformer的策略能够有效地排除与任务无关的模态,例如在任务中不必要地插入第4个摄像机
这一属性在FMB任务的多阶段、多任务模仿学习环境中特别有益
In contrast to the ResNet-basedpolicies, the Transformer-based policies learned to ef-fectively ignore task-irrelevant modalities, such as thenon-essential fourth camera in the insertion task.Thisattribute is particularly beneficial in the multi-stage,multi-task imitation learning settings characteristic of FMB tasks.
最终,机器人在学习后能够自主进行功能操控

第六部分 DexCap:可扩展和便携的动作捕捉数据收集系统
2.1 项目背景:遇到的问题与解决方案
2.1.1 以前系统的问题
通过本博客内之前介绍过的斯坦福mobile aloha/UMI可知,模仿学习最近在机器人领域取得了相当大的进展,特别是通过使用人类示范数据进行监督训练
- 常用的一种收集数据的方法是通过远程操作机器人手执行任务 比如mobile aloha。 然而,由于需要真实的机器人系统和缓慢的机器人运动,这种方法在扩展上是昂贵的
- 另一种方法是在操作过程中直接跟踪人手的运动而不控制机器人。 当前系统主要是基于视觉的,使用单视角摄像头。 然而,除了跟踪算法能否提供关键的准确的三维信息以供机器人策略学习之外,这些系统还容易受到在手-物体交互过程中经常发生的视觉遮挡的影响
对于收集灵巧操纵数据,运动捕捉(mo-cap)是一种比基于视觉的方法更好的选择。 运动捕捉系统提供准确的三维信息,并且对视觉遮挡具有鲁棒性。 因此,人类操作员可以直接用双手与环境进行交互,这样做快速且更容易扩展,因为不需要机器人硬件
为了将手部运动捕捉系统扩展到机器人学习的日常任务和环境中进行数据收集,一个合适的系统应该具备便携性和长时间捕捉的鲁棒性,能够提供准确的手指和腕关节姿态,以及三维环境信息
- 大多数手部运动捕捉系统不具备便携性,依赖于校准良好的第三视角摄像头,虽然电磁场(EMF)手套解决了这个问题,但无法跟踪世界坐标系中的六自由度腕关节姿态,这对于末端执行器(比如手指)的策略学习很重要
- 像基于IMU(Inertial Measurement Unit,惯性测量单元,主要用来检测和测量加速度与旋转运动的传感器)的全身套装这样的设备可以监测腕关节位置,但容易随时间漂移
除了硬件挑战外,还存在算法挑战,用于机器人模仿学习的动作捕捉数据。 尽管灵巧的机器人手使得直接从人类手部数据中学习成为可能,但机器人手和人类手之间的尺寸、比例和运动结构的固有差异需要创新算法
2.1.2 DEXCAP如何解决:便捷式动作捕捉、学习算法DEXIL、人机交互校正
为了解决这些挑战,他们同时引入了一种新的便携式手部动作捕捉系统DEXCAP和一种模仿算法。
DEXIL作为便携式手部动作捕捉系统,允许机器人直接从人类手部动作捕捉数据中学习灵巧操纵策略,比如实时跟踪手腕和手指运动的6自由度姿态(60Hz)
该系统包括一个动作捕捉手套用于跟踪手指关节,每个手套上方安装一个相机用于通过SLAM跟踪手腕的6自由度姿态,并在胸部安装一个RGB-D LiDAR相机观察3D环境(注意,手部动作的精确3D信息,例如,6自由度手部姿态、3D手指定位等很重要)

为了利用DEXCAP收集的数据来学习灵巧机器人策略,我们提出了基于动作捕捉数据的模仿学习方法DEXIL,它包括两个主要步骤——数据重定位和基于点云输入的生成式行为克隆策略训练(data retargeting and training generative-based behavior cloning policy with point cloud inputs),还可以选择性地进行人机交互式运动校正
- 在重定位过程中,我们使用逆运动学(inverse kinematics,简称IK)将机器人手指尖重定位到与人类手指尖相同的3D位置
手腕的6自由度姿态用于初始化IK,以确保人类和机器人之间的手腕运动相同
- 然后,我们将RGB-D观测转换为基于点云的表示,继而使用基于点云的行为克隆算法,基于扩散策略[13]
- 在更具挑战性的任务中,当IK无法填补人类手和机器人手之间的体现差距时,我们提出了一种人机交互式运动校正机制,即在策略执行过程中,当出现意外行为时,人类可以佩戴DEXCAP并中断机器人的运动,这样的中断数据可以进一步用于策略微调
总之,不同于以下这些
- DIME [3] 使用虚拟现实技术来远程操作灵巧手进行数据收集
- Qin等人 [60] 使用单个RGB摄像头来跟踪手部姿态进行远程操作
- DexMV [61]、DexVIP [45] 和 VideoDex [69]利用人类视频数据来学习运动先验知识,但通常需要在仿真或真实机器人远程操作数据上进行额外训练
DEXCAP专注于灵巧模仿学习,依赖于 DEXCAP 来收集基于三维点云观测的高质量手部动作捕捉数据,这些数据可以直接用于训练单手或双手机器人的低级位置控制
2.2 硬件设备:数据捕捉设备和机器人的设计
DexCap为了捕捉适合训练灵巧机器人策略的细粒度手部动作数据,DexCap的设计考虑了四个关键目标:
- 详细的手指运动跟踪
- 准确的6自由度手腕姿态估计
- 以统一坐标框架记录对齐的3D观察数据
- 在各种真实环境中具有出色的便携性以进行数据收集
2.2.1 追踪手指运动:使用Rokoko动作捕捉手套
系统使用电磁场手套,相比于基于视觉的手指追踪系统,在手物交互中对视觉遮挡的鲁棒性方面具有显著优势(论文中对电磁场手套系统和最先进的基于视觉的手部追踪方法在不同操纵场景下进行了定性比较)
在我们的系统中,手指运动使用Rokoko动作捕捉手套进行跟踪,如下图所示
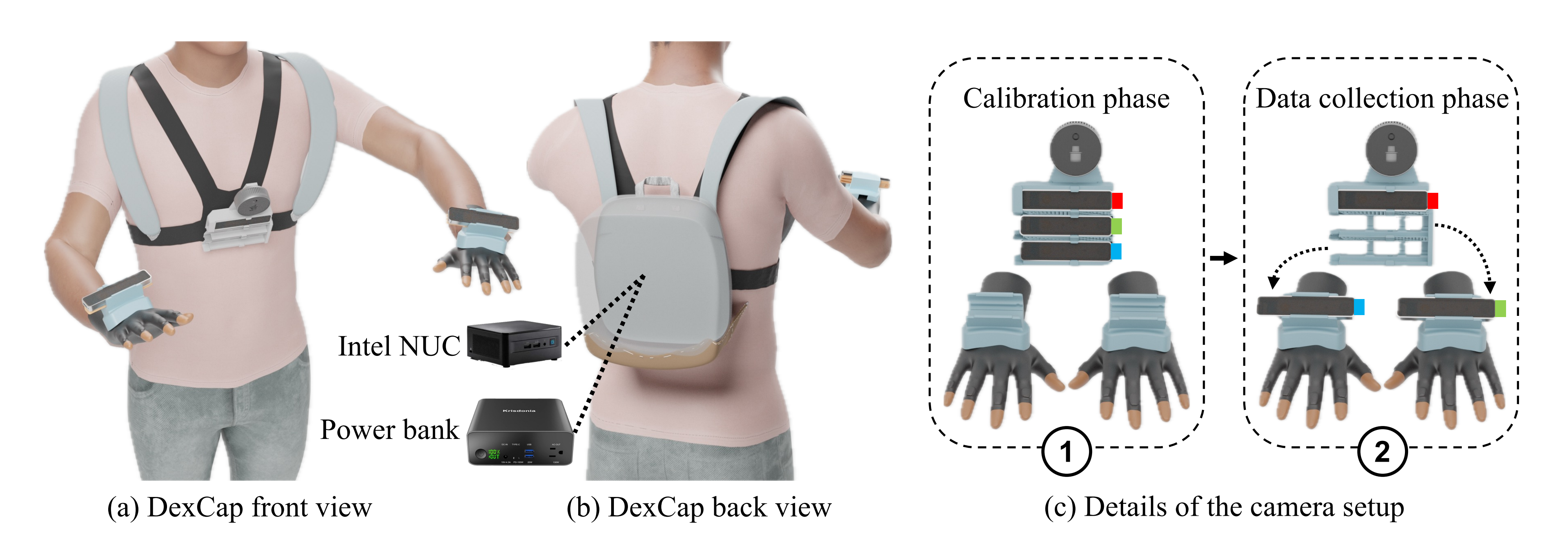
- 每个手套的指尖都嵌入了一个微小的磁传感器(Each glove’s fingertip is embedded with a tiny magnetic sensor)
- 而信号接收器则放置在手套的背面(while a signal receiver hub is placed on the glove’s dorsal side)
- 每个指尖的三维位置是从接收器到传感器的相对三维位移来测量的(The 3D location of each fingertip is measured as the relative 3D translation from the hub to the sensors)
2.2.2 追踪6自由度手腕姿态:2个T265追踪相机和一个IMU传感器
除了手指运动外,了解机器人末端执行器在三维空间中的精确位置对于机器人操控至关重要。这需要DEXCAP用于估计和记录人手在数据收集过程中的6自由度姿态轨迹。 虽然基于相机和基于IMU的方法通常被使用,但每种方法都有其局限性。 基于相机的系统通常不便携且在估计手腕方向能力上有限,不太适合..
用于操纵任务的数据收集。 基于IMU的系统,虽然可穿戴,但在长时间记录会话中容易出现位置漂移。 为了解决这些挑战,故开发了一种基于SLAM算法的6自由度手腕跟踪系统,如上图(c)所示
该系统通过
- 安装在每个手套背面的Intel Realsense T265相机「即两个鱼眼相机的图像(一篮、一绿)」
- IMU传感器信号(IMU传感器提供了训练机器人策略所需的关键手腕方向信息)
- SLAM算法构建环境地图
以实现对手腕6自由度姿态的一致跟踪
2.2.3 记录3D观察和校准:一个RGB-D LiDAR摄像机和一个T265跟踪相机
捕捉训练机器人策略所需的数据不仅需要跟踪手部运动,还需要记录3D环境的观察作为策略输入
为此,我们设计了一个装载摄像机的背包「如上图(a)、(b)所示」
- 在正前面,它通过摄像机支架集成了一台Intel Realsense L515 RGB-D LiDAR摄像机,和三个Realsense T265跟踪相机(分别为红、绿、蓝),用于在人类数据收集过程中捕捉观察结果
胸部相机支架上配备了4个插槽,顶部是L515 RGB-D LiDAR相机,下面是三个T265鱼眼SLAM跟踪相机
LiDAR相机和最上面的T265相机(红色)固定在相机支架上,而两个较低的(即绿色、蓝色)T265相机设计为可拆卸的,并可以固定在手套的背部进行手部6自由度姿态跟踪
- 在正背面,一个Intel NUC(Intel NUC 13 Pro,相当于就是一台带有64GB RAM和2TB SSD的迷你电脑),和一个40000mAh的移动电源放在背包中,支持长达40分钟的连续数据收集
接下来的关键问题是如何有效地将跟踪的手部运动数据与3D观察结果进行整合
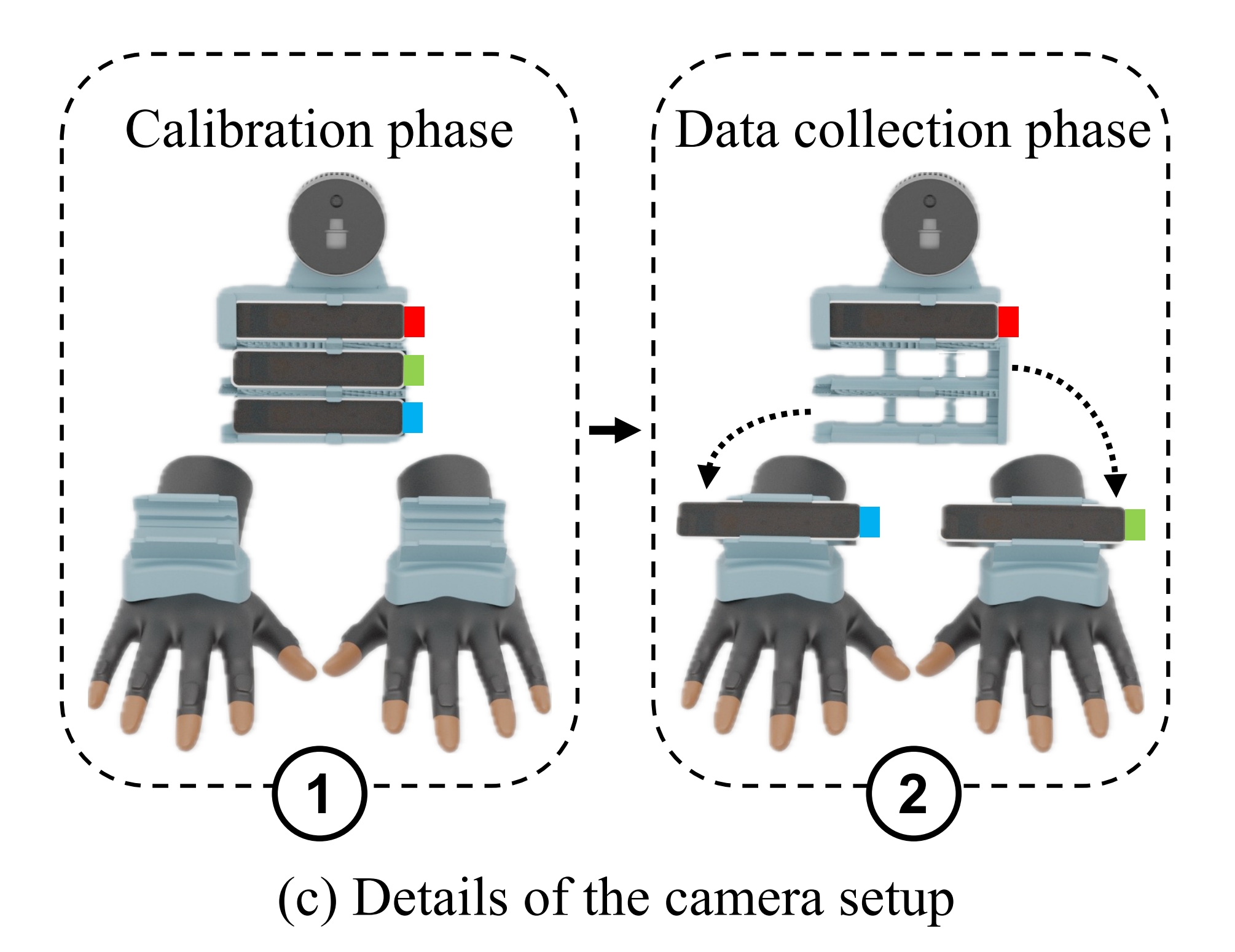
- 在数据收集开始时,所有跟踪摄像机都放置在支架槽中(即一开始时,所有摄像头都安装在胸前。 在启动程序后,参与者在环境中移动几秒钟,使SLAM算法构建周围环境的地图),以确保相机框架之间的恒定变换(如上图左侧所示)
- 然后,我们将跟踪摄像机从支架上取下(一绿、一蓝),并插入到每个手套上的相机插槽中(如上图右侧所示)
此外,为了在人体运动中确保稳定的观察结果,LiDAR摄像机下方安装了另一个鱼眼跟踪摄像机「在上图中标为红色」
当然,DexCap的硬件设计模块化且成本低廉,不限制相机、动作捕捉手套和迷你PC的品牌或型号,总成本控制在4000美元的预算范围内
2.2.4 双手灵巧机器人的设计:双机械臂、双LEAP机器手
为了验证通过数据训练的机器人策略是否OK,接下来建立一个双手灵巧的机器人系统
该系统由两个Franka Emika机器人臂组成,每个臂上配备有一个LEAP灵巧机器人手(一个有16个关节的四指手),如图(b)所示

为了进行策略评估,人类数据收集中使用的胸部LiDAR相机被从背心上取下,并安装在机器人臂之间的支架上(对于机器人系统,只使用LiDAR相机,不需要手腕相机。 机器人臂和LEAP手都以20Hz的控制频率运行,同时使用末端执行器位置控制和关节位置控制来控制两只机械臂和两只LEAP手,即use end-effector position control for both robot arms and joint position control for both LEAP hand)
2.3 学习算法DEXIL:数据的重定向与基于点云数据的策略预测
接下来,使用DexCap记录的人手动作捕捉数据来训练灵巧机器人策略,然后,我们会遇到这几个问题
- 我们如何将人手动作重新定位到机器人手上?
- 在双手设置中,当动作空间是高维的时候,什么算法可以学习灵巧策略?
- 此外,我们还希望研究直接从人手动作捕捉数据中学习的失败案例及其潜在解决方案
为了解决这些挑战,我们引入了DEXIL,这是一个使用人手动作捕捉数据训练灵巧机器人的三步框架
- 第一步是将DexCap数据重新定位到机器人的动作和观察空间中
- 第二步使用重新定位的数据训练(基于点云的扩散策略)
- 最后一步是一个可选的human-in-the-loop correction机制,旨在解决策略执行过程中出现的意外行为
2.3.1 数据和动作重定向:人手的动作重定向到机器手上
动作重定向。如上图(a)所示,由于人手和LEAP手的尺寸差异很大,而这种尺寸差异使得不好直接将手指运动转移到机器人硬件上,故需要先将人手动作捕捉数据重新定向到机器人实体上,这需要使用逆运动学(IK)将手指位置和6自由度手掌姿态进行映射
先前研究中的一个关键发现是,在与物体互动时,手指尖是手上最常接触的区域(如HO-3D [25]、GRAB [76]、ARCTIC [16]等研究所证明的)。 受此启发,我们通过使用逆运动学(IK)来匹配手指尖位置,重新定向手指运动
具体而言,我们使用一种能够实时生成平滑准确的手指尖运动的IK算法[63, 64, 79],以确定机器人手的16维关节位置。 这确保了机器人手指尖与人手指尖的对齐
- 考虑到LEAP手和人手不一样,其只有4个手指,故在人手到机器手的IK计算过程中排除了人手中小指的信息
此外,在动作捕捉数据中捕捉到的6自由度手腕姿态作为IK算法中手腕姿态的初始参考
首先,把手腕的6自由度姿态
和LEAP手的手指关节位置
,共同被用作机器人的本体感知状态
「We use position control in our setup and the robot’s action labels are defined as next future states at = st+1」
- 观察和状态表示的选择对于训练机器人策略至关重要
最终,他们将LiDAR相机捕捉到的RGB-D图像转换为3D点云(We convert the RGB-D images captured by the LiDAR camera in the DEXCAP data into point clouds using the camera parameter)
如下图所示, 初始列显示原始点云场景。 第2-7列提供右、中、左三组视图(两个视图一组),且三组视图中每一组视图中的蓝色背景列显示人体数据,黄色背景列显示机器人手部重定位
与RGB-D输入相比,这种额外的转换有两个重要的好处
但通过将点云观测转换为一致的世界坐标系(在mocap开始时,红色主SLAM相机的坐标系定义为世界坐标系),便可隔离并消除了躯干运动,从而得到稳定的机器人观测
考虑到在野外捕捉到的一些动作可能超出机器人的可达范围,调整点云观测和运动轨迹的位置可以确保它们在机器人的操作范围内可行
故,最终基于以上这些发现,将mocap数据中的所有RGB-D帧处理为与机器人空间对齐的点云,并排除与任务无关的元素(例如桌面上的点)
因此,这些经过精细处理的点云数据成为输入到机器人策略π的观测输入
2.3.2 基于点云的扩散策略
通过转换后的机器人状态
、动作
和相应的三维点云观测
,我们将机器人策略学习过程形式化为轨迹生成任务
- 对于策略模型π,通过处理点云观测
「an policy model π, processes the point cloud observations ot and the robot’s current proprioception state st into an action trajectory (at, at+1, . . . , at+d) 」

- 在
中给定具有N 个点的点云观测
(Given point cloud observation with N points ot in RN ×3, we uniformly down-sample it into K points and concatenate the RGB pixel color corresponding to each point into the final policy input in RK×6)
- 为了弥合人手和机器人手之间的视觉差距,使用正向运动学将机器人模型的链接与本体感知状态
学习灵巧机器人策略的一个挑战,特别是对于双手灵巧机器人,是处理大维度的动作输出
- 在我们的设置中,动作输出包括两个7自由度机器人臂和两个16自由度灵巧手在d个步骤中的动作,形成了一个高维回归问题(which forms a high-dimensional regression problem)
类似的挑战也在图像生成任务中进行了研究,该任务旨在回归高分辨率帧中的所有像素值(which aim to regress all pixel values in a high-resolution frame)
- 最近,扩散模型通过其逐步扩散过程,在建模具有高维数据的复杂数据分布方面取得了成功,比如AI绘画
对于机器人技术,扩散策略「详见此文《斯坦福刷盘机器人UMI:从手持夹持器到动作预测Diffusion Policy(含代码解读)》的第三部分」遵循相同的思路
从而将控制问题形式化为动作生成任务(For robotics, Diffusion Policy [ Diffusion policy: Visuomotor policy learning via action diffusion] follows the same idea and formalizes the control problem into an action generation task)
总之,使用扩散策略作为动作解码器,经验证它在学习灵巧机器人策略方面优于传统的基于MLP的架构
至于图像输入方法,使用ResNet-18 [29]作为图像编码器。 对于基于扩散策略的模型,则使用去噪扩散隐式模型DDIM进行去噪迭代,至于其他模型的选择及其他参数详见下图

在每次机器人动作之后,我们计算机器人当前自我感知与目标姿态之间的距离。 如果它们之间的距离小于一个阈值,认为机器人已经达到了目标位置,并将查询策略获取下一个动作
为了防止机器人变得空闲,如果它在规定的步数内未能达到目标姿态,将重新查询策略获取后续动作,一般在实验中将步数设定为10
2.3.3 人机协同校正
通过上述设计,DEXIL可以直接从DEXCAP数据中学习具有挑战性的灵巧操控技能(例如,拾取和放置以及双手协调),而无需使用机器人数据
然而,我们的简单重定位,该方法并未解决人机融合差距的所有方面。例如,使用剪刀时,稳定地握住剪刀需要将手指深入握柄。 由于机器手指与人手之间长度比例的差异,直接匹配指尖和关节运动并不能保证对剪刀施加相同的力
为了解决这个问题,我们提供了一种人在环路中的运动校正机制,包括两种模式-残差校正和远程操作。在策略执行过程中,我们允许人们通过佩戴DEXCAP实时向机器人提供校正动作(其中人类对策略生成的动作应用残差动作来纠正机器人行为。 纠正动作被存储在一个新的数据集中,并与原始数据集均匀采样,用于对机器人策略进行微调)
- 在残差模式下,DEX-CAP测量人手相对于初始状态
在策略展开开始时的位置变化
位置变化被应用为残差动作
到机器人策略动作
,通过
和
进行缩放
然后可以将校正后的机器人动作形式化为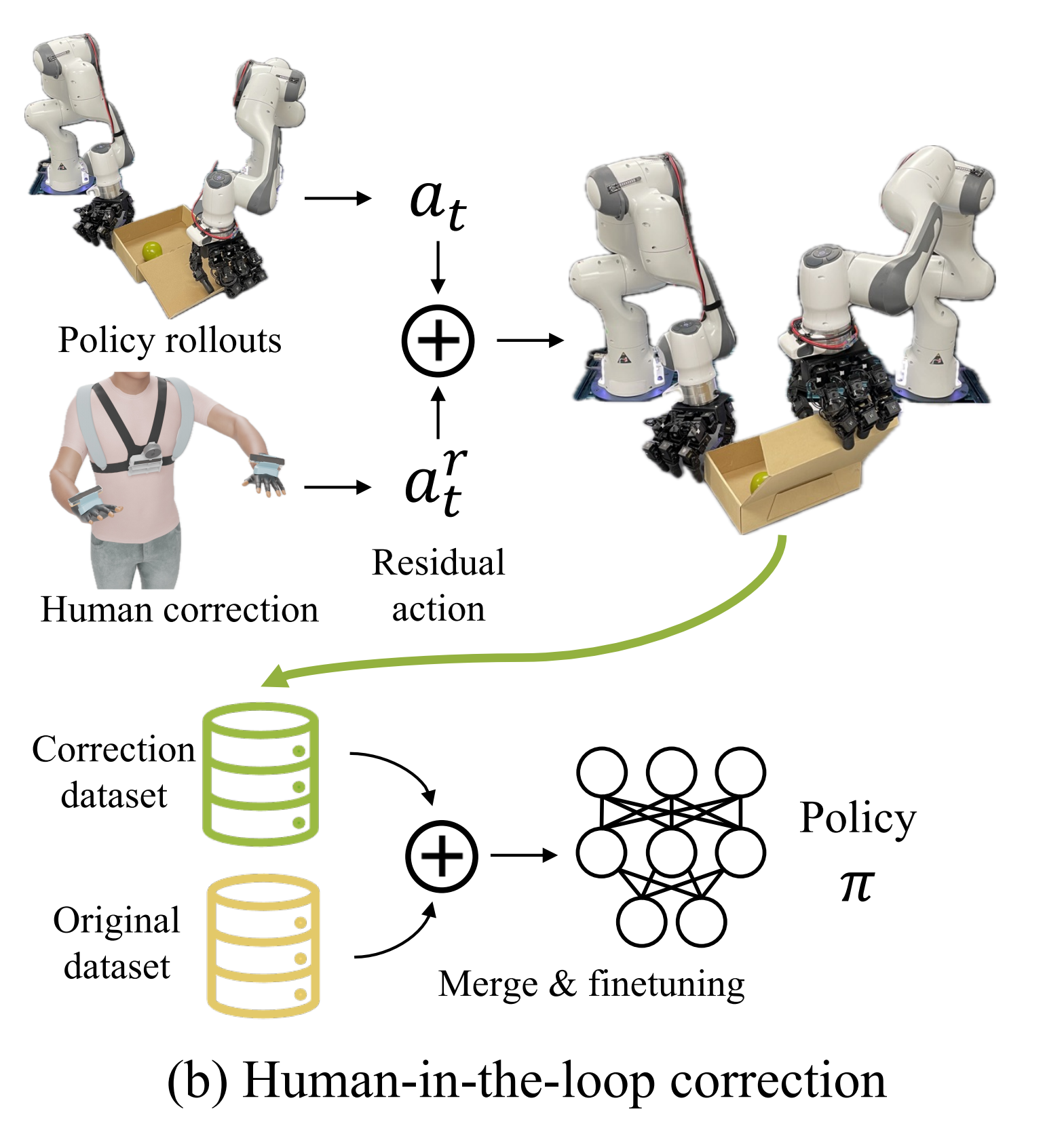
且经验性地发现,设置小尺度的 β(
- 在需要大幅度位置变化时,踩下脚踏板将切换系统到遥操作模式。 DEXCAP现在忽略策略展开,并直接将人类手腕变化应用于机器人手腕姿态。 机器人指尖现在直接跟随人类指尖
换句话说,机器人指尖将在各自的手腕坐标系中通过逆运动学追踪人类指尖。用户还可以通过再次踩下脚踏板来在纠正机器人错误后切换回剩余模式
由于机器人已经学习了初始策略,还可以在一小部分回滚中进行校正,从而大大减少人力投入。 校正后的动作和观察结果存储在一个新的数据集
中。 训练数据是从
中以等概率抽样的方式进行的,以微调策略模型,类似于IWR [Human-in the-loop imitation learning using remote teleoperation]
2.4 数据
最终,我们使用三种数据类型(分别得到了201、129和82个演示):
- DEXCAP数据捕捉机器人操作空间内的人手动作
比如剪刀剪裁和泡茶任务分别获得了一个小时的DEXCAP数据,分别产生了104和55个演示
- 野外DEXCAP数据来自实验室外环境
比如一个小时的野外DEXCAP数据提供了96个演示
- 使用脚踏板收集human-in-the-loop correction data,用于调整机器人动作或启用远程操作以纠正错误
human-in-the-loop correction data for adjusting robot actions or enabling teleoperation to correct errors, col-lected using a foot pedal
数据最初以60Hz记录,然后降采样到20Hz以匹配机器人的控制速度,纠错数据直接以20Hz收集
参考文献与推荐阅读
- 李飞飞「具身智能」新成果!机器人接入大模型直接听懂人话,0预训练就能完成复杂指令
VoxPoser论文一作在Twitter上发的关于VoxPoser的视频:https://twitter.com/wenlong_huang/status/1677375515811016704
- 谷歌AGI机器人大招!54人天团憋7个月,强泛化强推理,DeepMind和谷歌大脑合并后新成果
- 斯坦福炒虾机器人爆火全网!华人团队成本22万元,能做满汉全席还会洗碗,新智元发的新闻稿
- 斯坦福开源的机器人厨子,今天又接手了所有家务,机器之心发的新闻稿
- 关于Google家务机器人的报道
谷歌DeepMind机器人成果三连发!两大能力全提升,数据收集系统可同时管理20个机器人,量子位
谷歌家务机器人单挑斯坦福炒虾机器人!端茶倒水逗猫,连甩三连弹开打,新智元
大模型正在重构机器人,谷歌Deepmind这样定义具身智能的未来,机器之心 - ALOHA续作:Mobile ALOHA阅读笔记
- 从机器人模型 RT-2 看多模态、Agent、3D视频生成以及自动驾驶
- ..
- DEXCAP数据捕捉机器人操作空间内的人手动作
- 在残差模式下,DEX-CAP测量人手相对于初始状态
- 复杂任务要求机器人能够像人类一样连续完成多个步骤。此前的方法是让机器人学习整个过程,但这种方法容易因为单一环节的错误而不断累计误差,最后导致整个任务失败
- 但为了满足策略输入的需要,还在输入侧添加了FiLM层来对object ID或primitive ID进行条件处理
- 研究团队收集了一个涵盖上述任务的大规模专家人类示范数据集,包含超过22550个操作轨迹
- 扩散策略通过逐步细化动作预测来训练神经网络。为提高推理速度,采用DDIM调度器并对图像观测应用数据增强以防止过拟合。co-training数据管道与ACT相同,在附录A中有更多的训练细节可供参考
- Install ALOHA end-effectors
- 首先提出了Mobile ALOHA系统,作为低成本全身远程操作系统来收集数据(通过一个移动底座和一个全身远程操作界面增强了其前身ALOHA 系统)
- 为了使机器人策略具备一定的空间泛化能力,我们通常从任务设置前各种位置开始收集数据,并且通常在一个小型4×6或5×5网格中进行
- 简单方法的惊人效果:Dob-E采用了视觉模仿学习的简单行为克隆配方,利用ResNet模型[Deep residual learning for image recognition]进行视觉表示提取,并使用双层神经网络[The perceptron: a probabilistic model for information storage and organization in the brain,这竟然是1958年的一篇老论文,我是没想到的,^_^ ]进行动作预测







